Dreamhack - rev-basic-4
이번엔 rev-basic 4번에 대해서 풀어볼려고 한다.
basic 3번과는 어떤 차이가 있을지 알아이보자
basic 3번과는 동작 구조는 비슷한거 같다.
IDA 기능에 디컴파일을 사용해서 코드 구조를 보자
basic 3번 문제와는 다르게 인덱스 기반의 XOR + 가감 연산이였다면
basic 4번 문제는 Nibble 스왑 비트 연산만으로 플래그 생성인거 같다.
코드를 분석을 해보자면
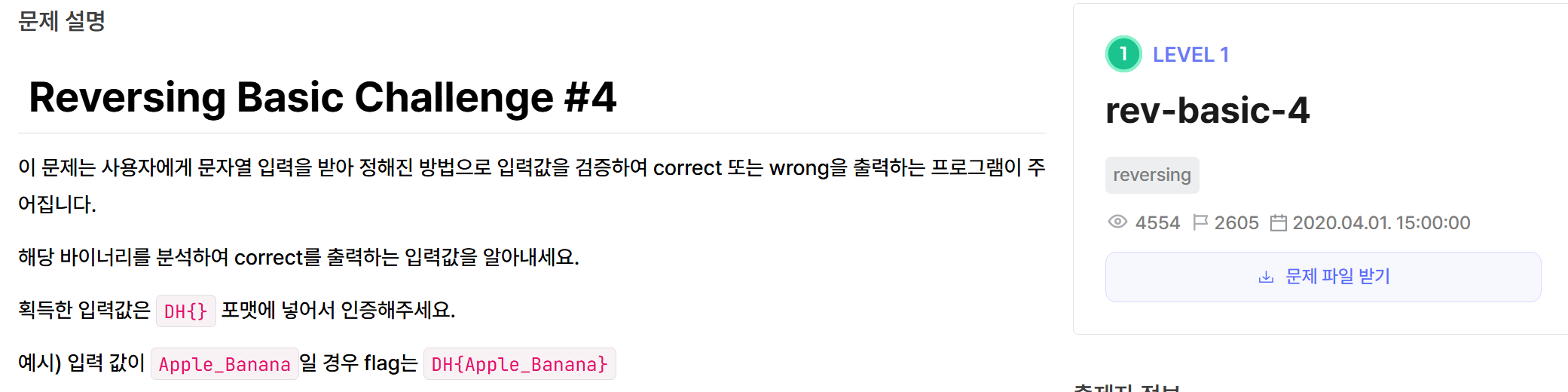
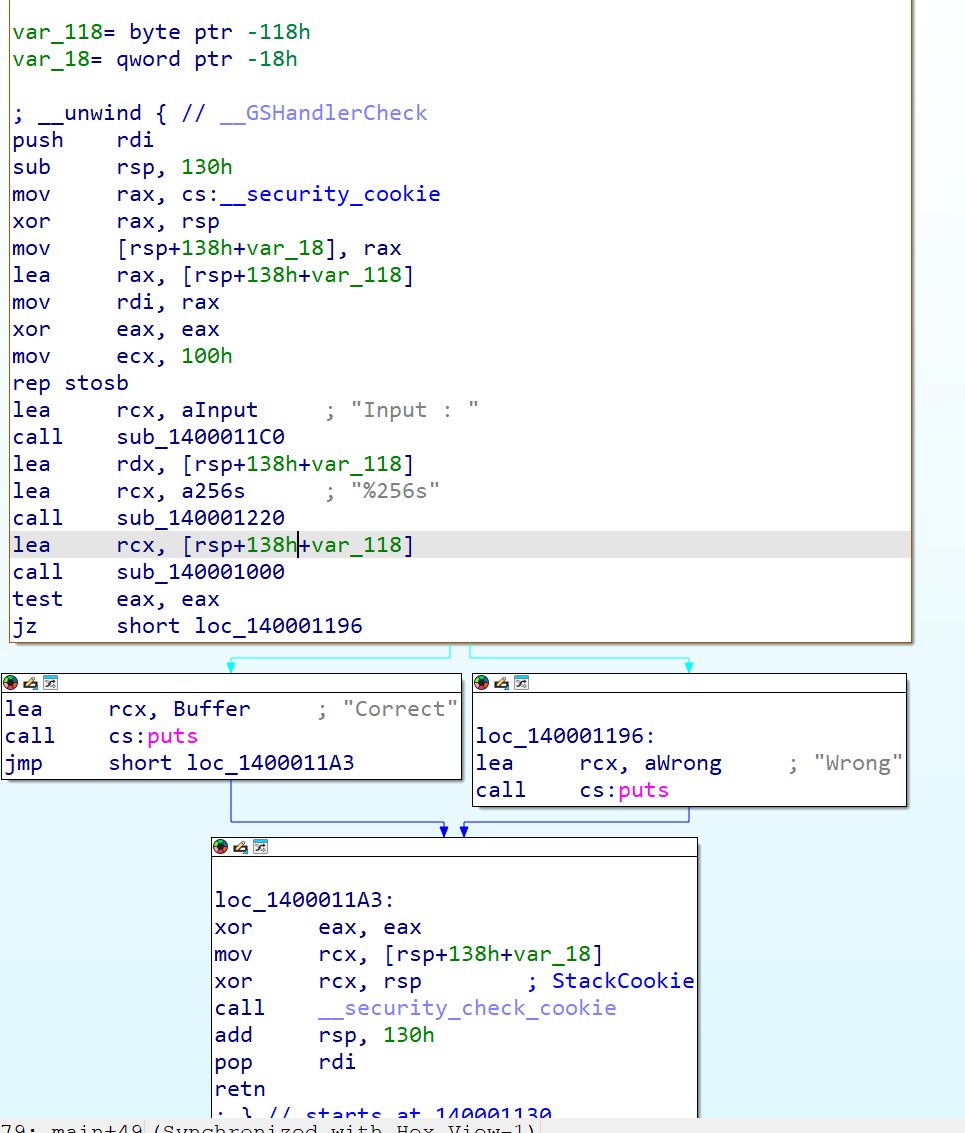
main 함수에서 입력값을 읽은 뒤 sub_140001000에 전달하여 결과(0 또는 1)에 따라 Correct/Wrong을 출력을 하는 방식같다.
그래서 sub_140001000에 들어가보면 아래와 같이 코드가 나온다.
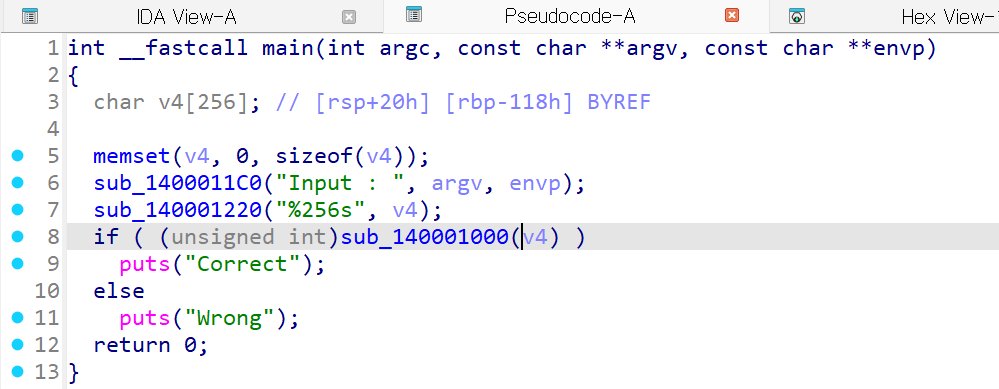
for (i = 0; i < 0x1C; ++i) {
if ( ((uint8_t)(16 * a1[i]) | (a1[i] >> 4)) != byte_array[i] )
return 0;
}
return 1;간단하게 분석을 해보자면 왼쪽 쉬프트 (<< 4)와 오른쪽 쉬프트 (>> 4)를 수행한 뒤, 두 결과를 bitwise OR 하고 결과가 byte_array[i]와 같지 않으면 Wrong이 출력된다고 한다.
역공학적으로 접근을 해보면 연산 우선 순위가 있습니다.
a1[i] << 4는 상위 4비트를 하위로,
a1[i] >> 4는 하위 4비트를 상위로 밀어넣어지는데
비트 OR 작업을 통해 원래 바이트의 하위/상위 4비트가 교환된 형태가 됩니다.
즉, byte_array[i] = swap_nibbles(a1[i])을 바꾸면
a1[i] = swap_nibbles(byte_array[i]) 형태가 된다.
정리를하자면
original = ((byte & 0x0F) << 4) | ((byte & 0xF0) >> 4)
상위 4비트를 오른쪽으로, 하위 4비트를 왼쪽으로 이동 후 OR
이걸 이제 코드로 구현을 해보면
arr = [
0x24, 0x27, 0x13, 0xC6, 0xC6, 0x13, 0x16, 0xE6,
0x47, 0xF5, 0x26, 0x96, 0x47, 0xF5, 0x46, 0x27,
0x13, 0x26, 0x26, 0xC6, 0x56, 0xF5, 0xC3, 0xC3,
0xF5, 0xE3, 0xE3, 0x00
]
flag = ''
for b in arr:
ch = ((b & 0x0F) << 4) | ((b & 0xF0) >> 4)
flag += chr(ch)
print(flag)Br1ll1antbit_dr1bble<<_>> 라는 결과값이 나온다
