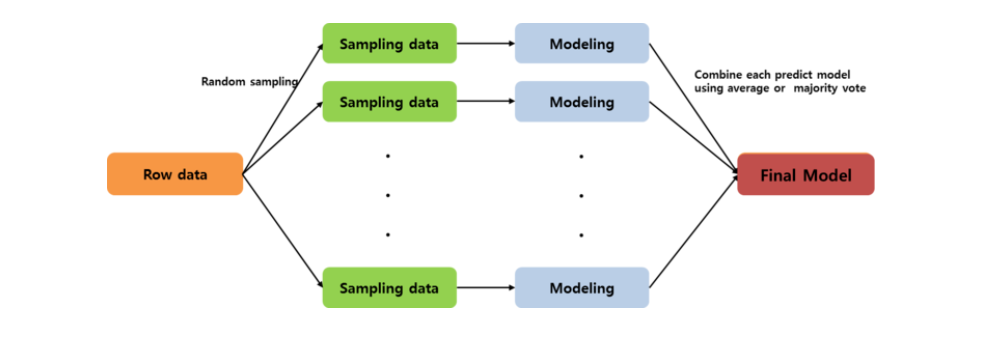
bagging = Bootstrap Aggregating
즉, random sampling한 subset들에 대해 여러 모델을 학습하고, 각 예측을 합쳐서 최종 결과를 만든다.
sklearn.ensemble.BaggingClassifier
BaggingClassifier(KNeighborsClassifier(), max_samples, max_features, bootstrap, bootstrap_features)
이렇게 base estimator와 조건 파라미터를 넣고 사용하면 된다.
특히, decision tree를 base estimator로 bagging한 모델 :
Random Forest
sklearn.ensemble.RandomForestClassifier
n_estimatorsdecision tree 개수 (default 100)criterionsplit quality measure ("gini") "entropy" "log_loss"max_depth(None (until all pure))max_featuresnode를 split할 때 고려할 feature의 수
bootstrap(True)max_samples각 base estimator에서 사용할 data 수 (None (use all))

- training set에서 random sampling
- tree의 best split을 찾을 때 고려할 feature subset도 random
이렇게 randomness를 부여함으로써, variance가 감소된다.
-> Prevent overfitting.
Extra Trees
sklearn.ensemble.ExtraTreesClassifier
"Extremely Randomized Trees"
이름에서 알 수 있듯이, randomness가 더 강화된 모델이다.
Random Forest vs. Extra Trees
-
replacement (복원추출) 이 아닌, 비복원 추출을 한다.
e.g. sklearn의 경우,
RandomForest >>bootstrap=True(default)
ExtraTrees >>bootstrap=False(default)
"using the whole original sample"
-> bias 감소 -
feature subset의 모든 feature에 대한 information gain을 계산해서 optimum split feature를 찾는 random forest와 달리, split feature를 무작위로 선택한다.
RandomForest >>splitter='best'(default)
ExtraTrees >>splitter='random'(default)
-> computing time 감소, variance 감소
두 모델의 성능은 비슷하지만, split feature를 계산하는 시간이 줄어들기 떄문에 ExtraTree가 Random Forest보다 computing time 면에서 뛰어나다고 한다.
ref
https://scikit-learn-org
https://quantdare.com/what-is-the-difference-between-extra-trees-and-random-forest/
