
샤딩이란
데이터베이스 샤딩은 대규모 데이터베이스를 여러 샤드(shard)로 분할해 성능과 확장성을 높이는 기술이다.
모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
샤딩이 필요한 이유
샤딩은 보통 데이터 양이 급증하거나, 단일 서버로 처리하기 어려운 상황에서 여러 서버를 추가함으로써 성능을 유지할 수 있다.
또한 한 서버에 장애가 생겨도 다른 샤드에 데이터가 있기 때문에 전체 시스템 장애를 방지할 수 있다.
데이터베이스의 규모 확장
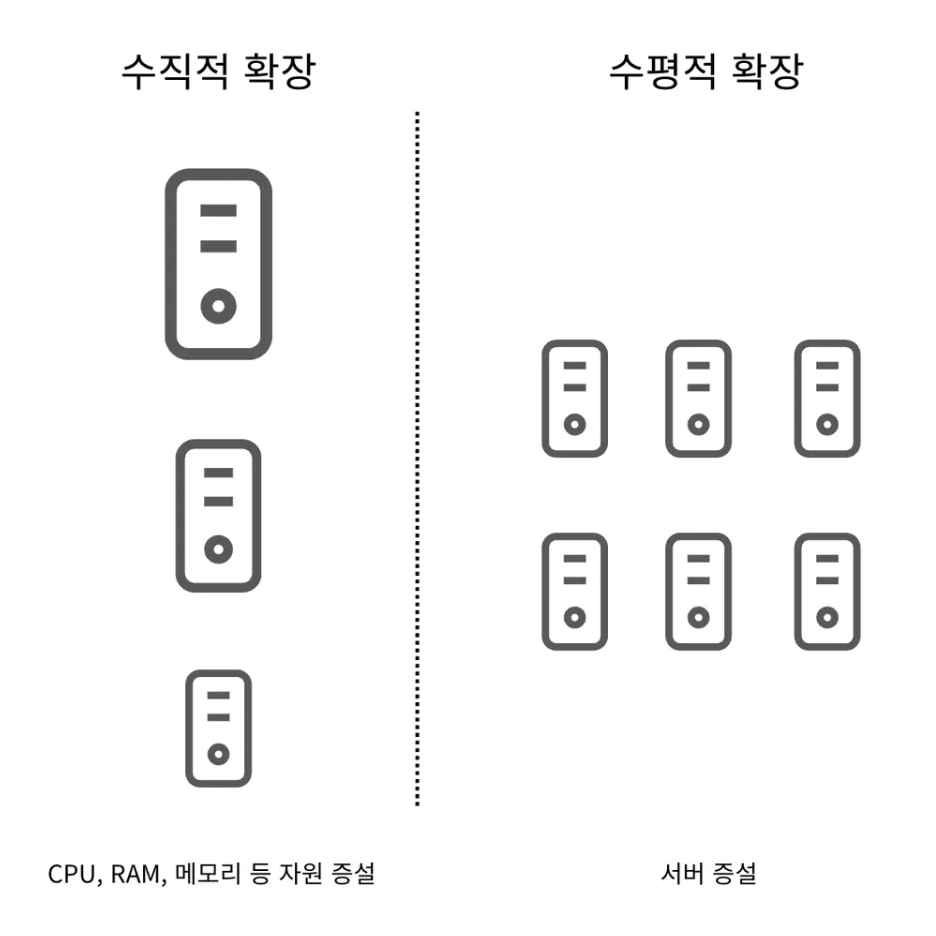
데이터베이스 규모 확장을 위해 두 가지 접근법이 존재한다.
수직적 확장
스케일 업(Scale-up)이라 불리는 수직적 확장은 서버 컴퓨터를 고성능의 자원으로 증설하는 방법이다.
이러한 수직접 접근법에는 몇 가지 약점이 있다.
- 하드웨어의 한계
- 단일 장애 지점(SPOF) 문제
- 비용이 많이 드는 문제
SPOF (Single Point of Failure)
시스템 구성 요소 중에서, 동작하지 않으면 전체 시스템이 중단되는 요소
수평적 확장
데이터베이스의 수평적 확장은 샤딩(sharding)이라고 부르는데, 더 많은 서버를 추가함으로 성능을 향상시킬 수 있도록 한다.
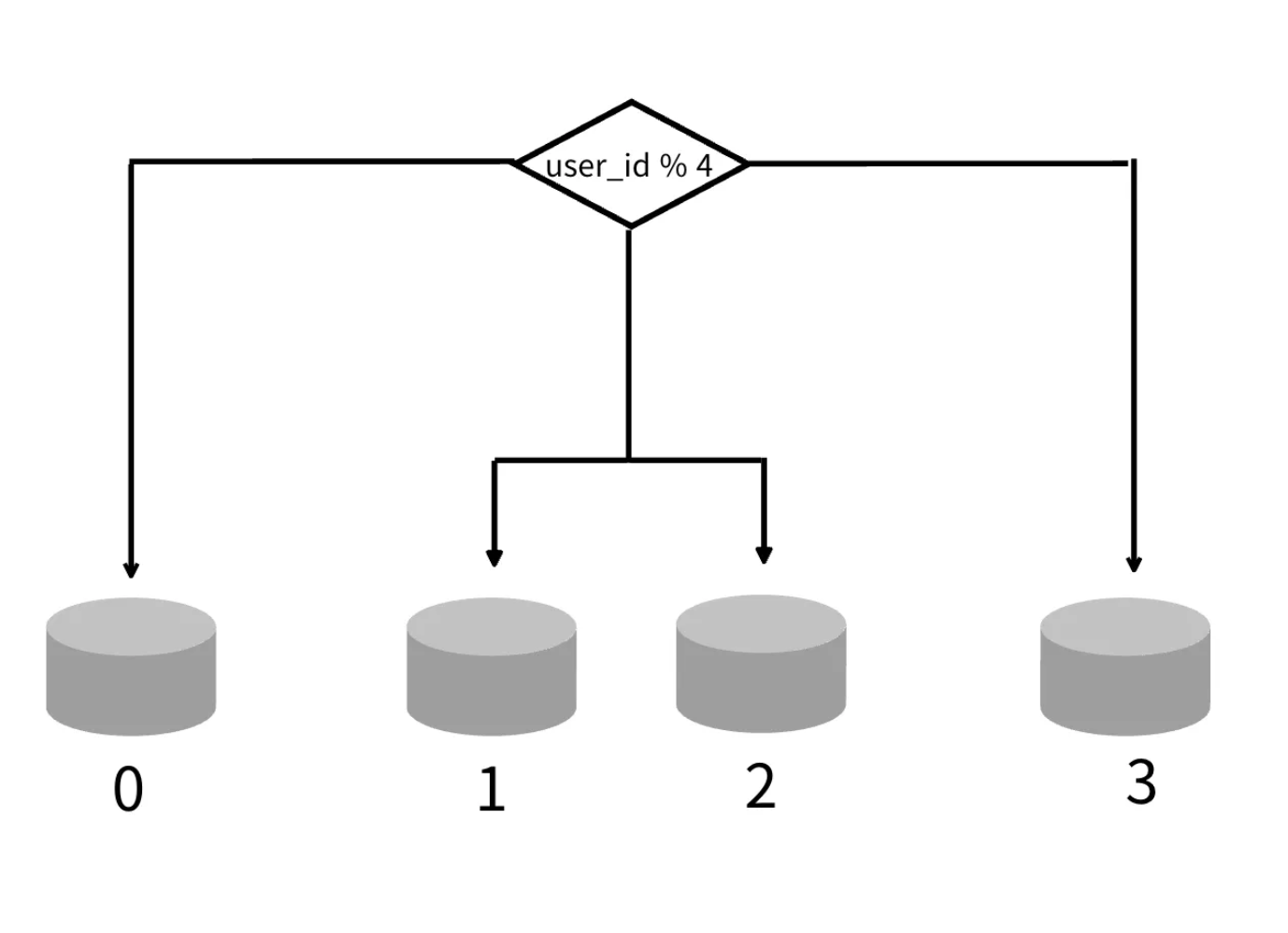
사용자 데이터를 어느 샤드에 넣을지를 사용자ID에 따라 정한다. 모듈러 연산(user_id % 4)을 통해 사용자 데이터가 보관되는 샤드를 정한다.
샤딩의 종류
-
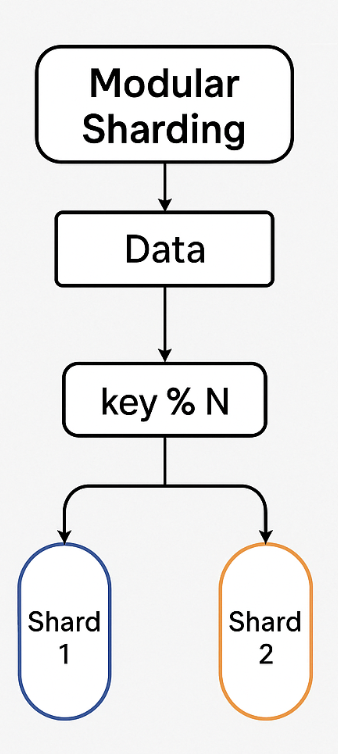
해시 샤딩(Hash Sharding)
앞서 설명하듯이 특정 키(예: 사용자 ID)를 해시 함수로 변환해 서버에 할당한다. 데이터 분포가 균등하지만, 샤드 추가/제거 시 데이터 이동이 필요하다.
-
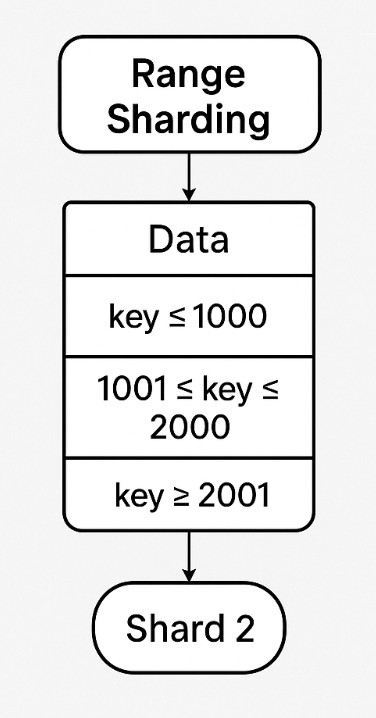
범위 샤딩(Range Sharding)
레인지 샤딩은 PK의 범위를 기준으로 DB를 특정하는 방식이다.
예를 들어, 사용자 ID 1000은 샤드 A, 2000은 샤드 B와 같이 저장하는 방식이다. 하지만 일부 DB에 데이터가 몰릴 수 있다는 단점이 있다.
-
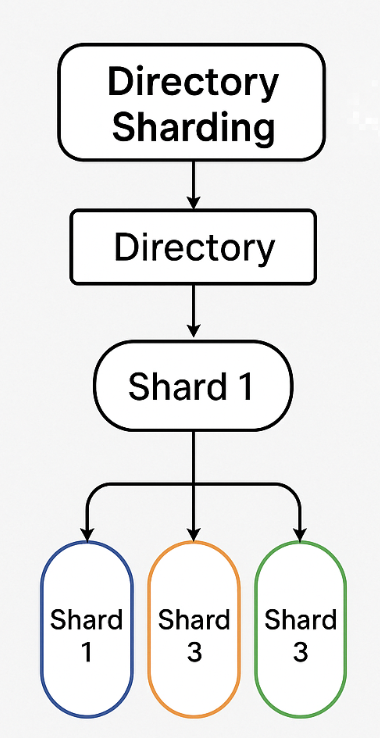
디렉토리 기반 샤딩(Directory-Based Sharding)
별도의 매핑 테이블(디렉터리)을 두고, 각 데이터가 어느 샤드에 있는지 관리한다. 샤드 추가/제거 시에도 기존 데이터에 영향이 적어 유연하다. 중앙 디렉토리 관리가 필요하고, 단일 장애 지점 문제가 있다.
샤딩 도입 시 고려해야할 문제
- 데이터의 재 샤딩
- 데이터가 너무 많아져서 하나의 샤드로는 더 이상 감당하기 어려울 때, 샤드 간 데이터 분포가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 빨리 진행될 때, 샤드 소진이라고도 부르는 현상이 발생하면 샤드 키를 계산하는 함수를 변경하고 데이터를 재 배치하여야 한다. ex) 안정 해시 기법
- 유명인사
- 핫스팟 키(hospot key) 문제라고도 부르는데, 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제이다.
- BTS, 싸이, 블랙핑크 같은 유명인사가 전부 같은 샤드에 저장되는 데이터베이스가 있다고 해보자.
위 유명인사가 같은 샤드에 보관될 경우 특정 샤드만 자주 조회되어 과부하가 걸릴 수 있다.
- 조인과 비정규화
- 하나의 데이터베이스를 여러 샤드 서버로 쪼개고 나면, 여러 샤드에 걸친 데이터를 조인하기가 힘들어진다.
- 이를 해결하기 위해 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 하는 것이다.
DB분산처리를 위한 sharding
데이터베이스 샤딩이란 무엇인가요?
Database - 샤딩이란 무엇인가?! (+ 샤딩의 다양한 기법, 각 기법 비교)
가상 면접 사례로 배우는 대규모 시스템 설계 기초
