
6주차 정리
지난 "W06 웹서버 만들기"에 대한 짧은 정리를 하고 시작하려고 합니다.
그때 저는 "지금 우리는 뭘 배우고, 뭘 하는 것인가?"이 명확하지 않았고, 일주일간 개고생한 끝에 그 답과 네트워크의 정수(精髓)을 깨달아버렸습니다.
결론은 " ~ 프로토콜을 구현하기 위해 ~계층에서 이루어지는 ~를 직접 구현하는 것"입니다.
원래 두괄식으로 결론을 내고 글을 쓰려고 했는데, 제가 했던 고생이 아까우니 여러분은 아래의 20줄 가량의 글을 읽어주셔야겠습니다.
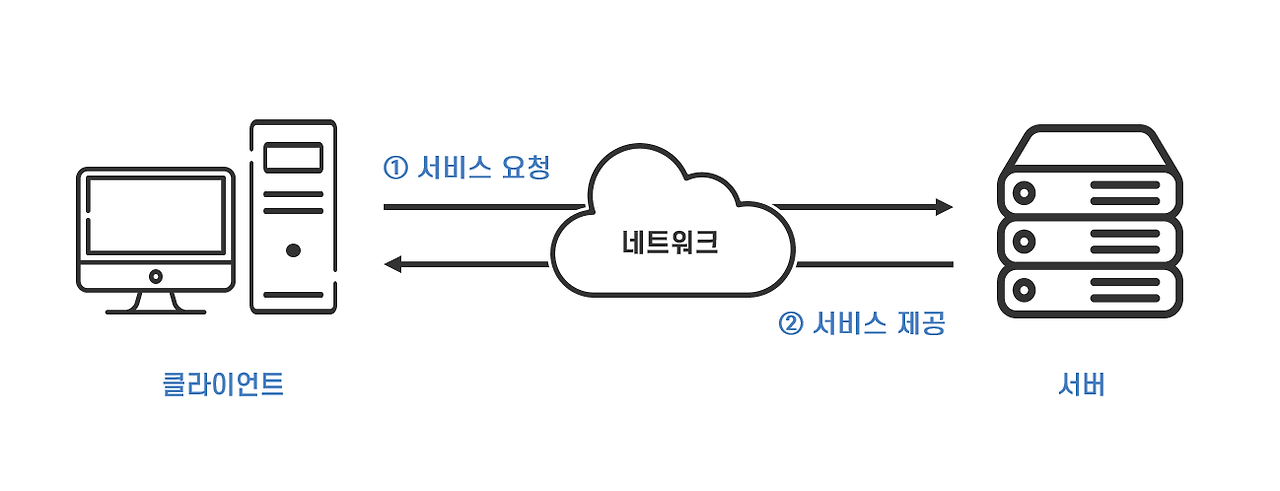
오늘날의 모든 인터넷 네트워크는
클라이언트-서버 모델기반입니다. 여기서 '모델'이란 이론이기 때문에 이러한 개념을 바탕으로 실세계에 적용하기 위한 '기술'을 토대로 뒤에 서술할규약(프로토콜, protocol)이 만들어집니다.
이러한 클라이언트-서버 모델에 의해 한 개의 서버와 한 개 이상의 클라이언트가 통신하게 됩니다. 이러한 통신의 규모는 점점 커져서
인터넷이라고 하는 글로벌 네트워크가 이루어집니다. 어떠한 규약 덕분에 전세계 통신 장비들이 각기 달라도 서로 통신할 수 있습니다. 이 규약이TCP/IP 프로토콜입니다. (웹은HTTP 프로토콜)
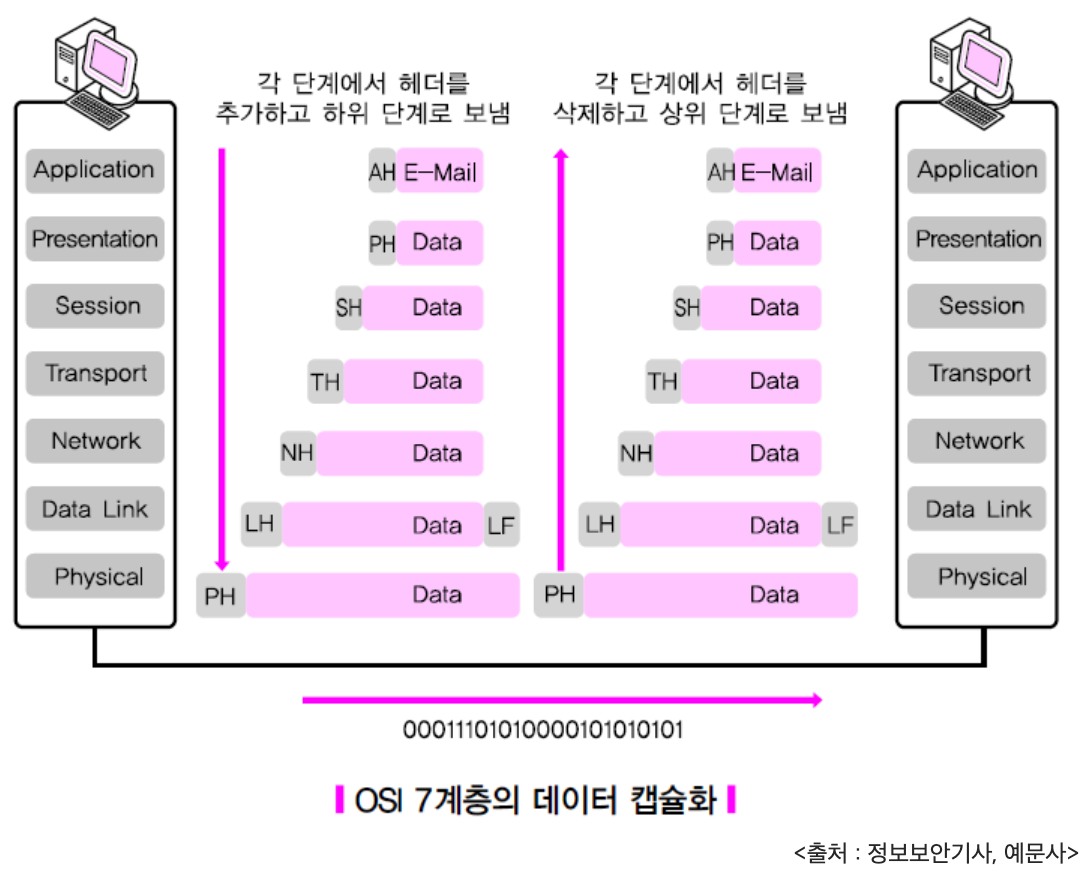
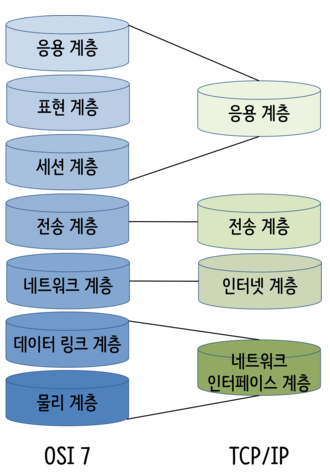
이러한 프로토콜을 구현하기 위해,
7계층에서 사용자(client)가 보내고자하는data에
4계층의Port 주소-> 3계층의IP 주소-> 2계층의MAC 주소를 데이터에 붙여패킷화시키고 -> 1계층에서bit(비트, 0과 1)로 전송합니다.
그러면 패킷 내의 MAC, IP, Port를 활용하여허브,브릿지,라우터등의 네트워크 장비들이목적지(server)의 7계층(application)에 data를 전달할 수 있습니다. 이를 프로그래밍으로 구현하는 것이소켓 인터페이스입니다.
그러므로 결론은 저희는 "
TCP/IP 프로토콜을 구현하기 위해사용자 단계(app 계층)에서 이루어지는소켓 인터페이스를 직접 구현한 것"입니다.
글이 짧고 압축적이기 때문에 여러분은 이해 못하셨을 수도 있습니다. 그건 참으로 유감입니다만, 저는 완벽히 이해했습니다. 이제
pintOS에 올인해야 하기 때문에 더 들일 시간이 없어 상세하게 적을 시간이 없어 아쉽습니다.
그럼 20000
짧은 글쓰기
담배를 피는데 주변에서 이론 공부가 재미없다는 소리가 들린다. 이 소리는 매주 목요일만 되면 들려오는 소리로, 벌써 한 주가 끝나고 새로운 한 주가 시작됨을 알리는 푸념이다. 지난 일주일과 새로운 일주일의 경계에서, 지난 6주차에 대한 소견을 적어보고자 한다.
한번의 성공과 한번의 실패를 겪었다. 한번의 성공은 정글 커리큘럼에서의 의도를 어느정도 파악했다는 것, 한번의 실패는 또 이론을 파다가 구현을 다 끝내지 못했다는 것. 한번의 성공은 위에 적어놓았으니 실패에 대해 적고자 한다.
내가 예상하기로 2일 정도의 시간이 부족했다. 내가 이론을 깊게 공부한 이유는 나의 고집 때문이었다. 나는 프로그래머란 "생각하는 것을 구현하는 사람"이라고 생각했고, 생각하기 위해서는 어느정도 아는 것이 있어야 생각을 할 수 있으므로 남들에게 '설명할 수 있을 정도로' 공부를 한 것이 지난 실패의 주 요인이라 할 수 있다.
사실 위 생각은 크게 문제될 것은 없지만, 시간이 한정된 정글에서는 위험한 생각이다. 또한 구현에서의 도피로 이론에 집착하게 된 것일 수도 있다. 왜냐하면 나는 구현하는 역량이 부족했고, 구현에 더 치우쳐야함을 3주차부터 알았기 때문에 처음 말했던 누군가의 반복되는 푸념처럼 나도 6주 동안 고집을 부려 "구현을 끝내지 못하는" 실패를 반복하고 있었던 것이다. 학습에 많은 도움을 주신 백코치님 뵙기가 민망하고 부끄럽다..
이제는 어느정도까지만 알고 바로 구현을 시작한 뒤 "완성을 시키고 나서" 남들에게 설명할 수 있을 정도로 이해해보려고 한다. 지난 주의 끝은 씁쓸했지만, 다음 주의 시작은 달콤하다. 목표가 분명하니까.
Project 1. Thread
Synchronization(동시성)
CSAPP chpt 12. 동시성 프로그래밍
쓰레드는 프로세스에 기반을 둔 흐름들과 같이, 커널에 의해 자동으로 스케줄됩니다. 또한 단일 프로세스의 컨텍스트 내에서 돌아가며, 그러므로 데이터를 빠르고 쉽게 공유할 수 있습니다.
동시성 메커니즘에 관계없이 공유 데이터로의 동시성 접근을 동기화하는 것은 어려운 문제입니다. 세마포어의 P와 V는 이러한 문제를 해결하기 위해 개발되었습니다. 세마포어 연산은 생산자-소비자 시스템에서 제한된 버퍼, readers-writers 시스템에서 공유 객체 같은 자원들의 접근을 스케줄링할 뿐만 아니라, 공유 데이터로 상호 배타적인 접근을 제공하기 위해서 이용될 수 있습니다.
동시성은 또 다른 어려운 이슈들을 야기합니다. 쓰레드가 호출한 함수들은 쓰레드-안전성이라고 하는 특성을 가져야 합니다. 네 가지 클래스의 쓰레드-위험한 함수들을 구별할 수 있으며, 이들을 쓰레드-안전하게 만들기 위한 방법도 존재합니다. 재진입 가능한 함수라고 하는 쓰레드-안전 함수들은 종종 재진입 가능하지 않은 함수들보다 더 효율적이며, 그 이유는 이들은 동기화 장치들을 전혀 필요로 하지 않기 때문입니다. 동시성 프로그램에서 일어나는 일부 다른 어려운 이슈들은 경쟁과 교착상태가 있습니다.
쓰레드
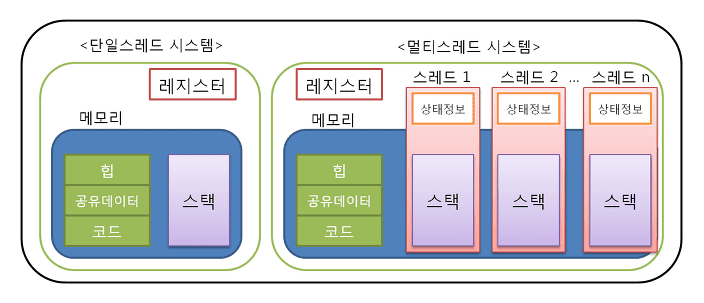
쓰레드는 프로세스의 컨텍스트 내에서 돌아가는 논리흐름입니다. 각 쓰레드는 고유의 정수 쓰레드ID(TID), 스택, 스택 포인터, 프로그램 카운터, 범용 레지스터, 조건 코드를 포함하는 자신만의 쓰레드 컨텍스트를 가집니다. 한 개의 프로세스에서 돌고 있는 모든 쓰레드는 이 프로세스의 전체 가상주소를 공유합니다.
쓰레드에 기초한 논리흐름은 프로세스와 I/O 다중화에 기초한 흐름의 품질을 결합합니다. 프로세스와 같이 쓰레드는 커널에 의해 자동으로 스케줄되고, 커널에 정수 ID로 알려집니다. 프로세스 가상 주소공간의 전체 내용을 공유하므로, 코드, 데이터, 힙, 공유 라이브러리, 오픈한 파일들이 포함됩니다.
세마포어
어떤 변수가 공유한다는 것의 의미와 어떻게 동작하는 지에 대해 알아봅시다.
1. 쓰레드의 그림과 같이 동시성 쓰레드의 풀은 한 개의 프로세스의 컨텍스트에서 돌아갑니다. 각각의 쓰레드는 자신만의 별도의 컨텍스트를 가집니다. 그리고 전체 사용자 가상 주소공간과 오픈된 파일 등 나머지 프로세스 컨텍스트를 다른 쓰레드와 공유합니다.
동작하는 측면에서 레지스터들은 절대 공유되지 않지만, 가상메모리는 항상 공유됩니다. 서로 다른 쓰레드 스택이 다른 쓰레드로부터 보호되지 않는다는 것을 주의해야 합니다.
어떤 변수 v는 자신의 인스턴스 중의 한 개가 하나 이상의 쓰레드에 의해 참조되는 경우에만 공유되어 있다고 말합니다. 이러한 공유 변수들은 편리하지만 심각한 동기화 오류를 가져올 수 있습니다: 일반적으로, 운영체제가 쓰레드를 위해서 정확한 순서를 선택하게 될지를 사용자는 예측할 수 없습니다.
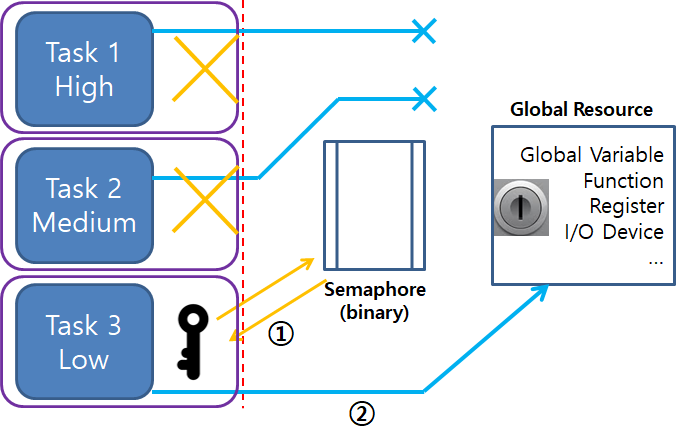
재진입(Reentrancy) 가능한 함수라고 하는 쓰레드-안전 함수의 중요한 클래스가 있습니다. 이들은 다수의 쓰레드에 의해 호출될 때 공유 데이터는 전혀 참조하지 않는 특성으로 규정됩니다. 재진입 가능이라는 용어는 명시적이고 묵시적인 재진입 가능한 함수들 모두를 포함하기 위해서 항상 사용합니다.
공부방법 변경으로 인한 중단
벨로그에 글쓰는 방법은 집중하기에는 좋지만 시간이 2배 이상 걸리므로 공부방법을 화이드 보드를 활용한 추상화를 그려보는 방법으로 변경했습니다.
