
제목은 저의 취미 생활로, 그저 어그로일뿐입니다.
짧은 글쓰기
오늘의 반성문.
- 계획은 변수를 고려해서 언제나 더 여유롭게 짜야 한다. 오늘 만난 친구와의 약속에 20분이 늦었는데, 버스의 좌석을 확인하지 못했고 만일의 상황을 대비하지 못했다. "만일 면접이 있더라면 너가 늦었겠냐"라는 친구의 말처럼 안일했던 것이다. 평상시에 친구를 만나더라도 더 계획적으로 치밀하게 계획하고 행동하자.
- 주머니의 돈은 쉽게 빠져나간다. 친구가 회사를 때려치고 나왔다길래 오랜만에 비싼 밥을 샀다. 여유가 없는 상황에서 최근 돈이 생기기도 해 기분을 내려고 했던 것이다. 나중에 돈을 모아도 이렇게 무계획하게 돈을 소비한다면 그 돈을 유지할 수 없을 것이란 생각이 들었다. 오해하지 마시라. 친구에게 사준 돈이 아까운 것이 아니라, 여건을 고려하지 않고 기분 내기위해 비싼 메뉴를 고른 것이 아쉬웠을 뿐이다.. 내일 점심은 라면먹어야겠다
Chapt.8 예외적인 제어흐름
Intro
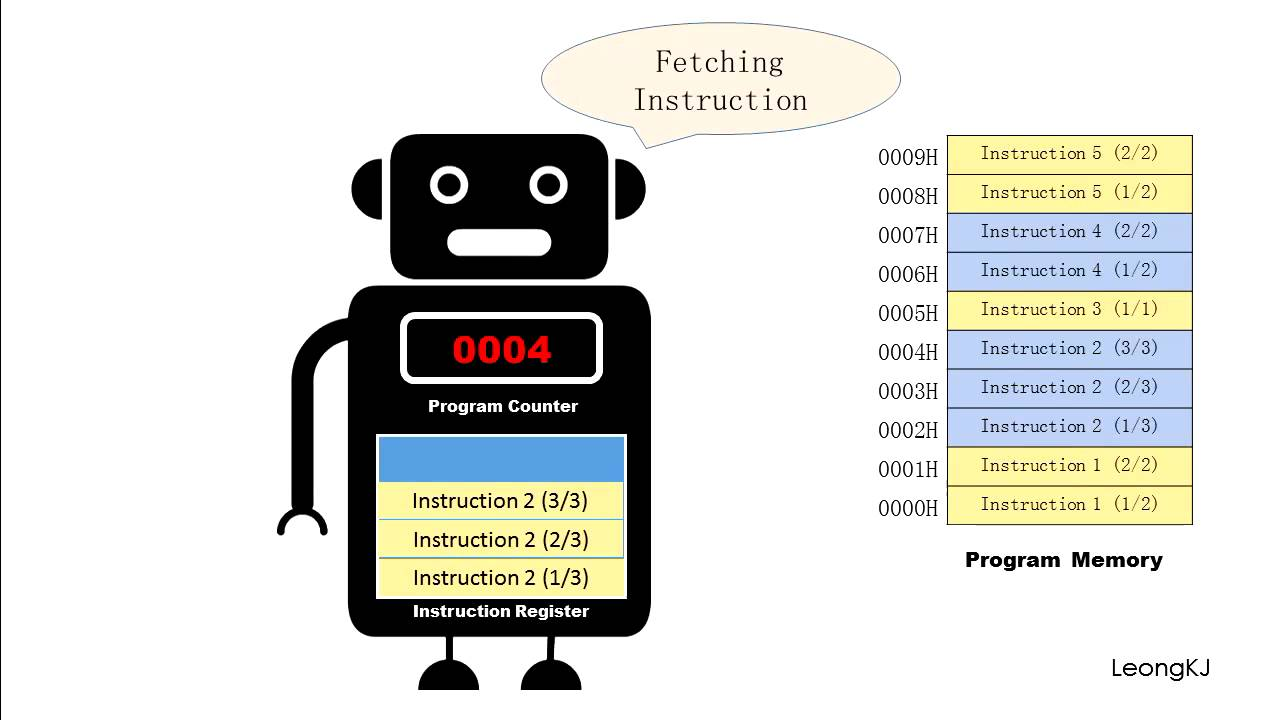
프로세서에 전원을 처음 공급하는 시점부터 전원을 끌 때까지 프로그램 카운터는 연속된 값들을 가정합니다.
이때 인스트럭션 I(k)에 대응되는 주소(메모리 주소)는 a(k)입니다. a(k)에서 a(k+1)로의 전환은제어이동이라고 부릅니다.
I(k+1)이 I(k)와 인접해 있지 않는 경우는
jump,call리턴 같은 친숙한 프로그램 인스트럭션에 의해 발생합니다.
예외적인 제어 흐름(ECF, Exceptional control flow)은 현대의 시스템들은 제어흐름의 갑작스런 변화를 만드는 방법입니다. 예외적인 제어흐름은 컴퓨터 시스템의 모든 수준에서 발생합니다.
(부정의 늬앙스가 아닌, 점진적인 흐름에서 벗어나도록 하는 방법이 ECF라고 받아들이시면 됩니다.)
- ECF를 이해해야 하는 이유
- 중요한 시스템 개념을 이해하는데 도움이 됩니다. ECF는 운영체제가 입출력, 프로세스, 가상메모리를 구현하기 위해 사용하는 기본 메커니즘입니다.
- ECF를 이해하면 어떻게 응용들이 운영체제와 상호작용하는지를 이해하는 데 도움이 됩니다. 응용은
트랩(trap) 또는시스템 콜(system call)이라고 알려진 ECF의 한 가지 형태를 사용해서 운영체제로부터 서비스를 요청합니다.- ECF를 이해하면 재미있는 새로운 응용프로그램 작성에 도움이 됩니다. 운영체제는 새로운 프로세스를 만들거나, 프로세스가 종료하기를 기다리거나, 다른 프로세서에게 시스템 내의 예외 이벤트를 알리거나, 이러한 이벤트를 감지하고 반응하는 등의 작업을 위한 강력한 ECF 메커니즘을 응용프로그램들에 제공합니다.
- ECF를 이해하면
동시성을 이해하는 데 도움이 됩니다. ECF는 컴퓨터 시스템에서 동시성을 구현하는 기본 메커니즘입니다.- ECF를 이해하면 소프트웨어적인 예외상황이 어떻게 동작하는지 이해하는 데 도움이 됩니다. C++이나 자바 같은 언어는
try,catch,throw문장을 통해서 소프트웨어 예외 메커니즘을 제공합니다. C에서는setjmp,longjmp함수로 제공됩니다.
이 장은 응용이 운영체제와 어떻게 상호작용하는지 배우기 시작하게 되는 전환점이라고 볼 수 있습니다. 이러한 상호작용들은 모두 ECF를 중심으로 돌아갑니다.
컴퓨터 시스템의 모든 수준에서 존재하는 ECF의 다양한 형태를 설명하기 위해
1. 하드웨어와 운영체제의 교차점에 놓인 예외들로 시작합니다.
2. 응용(APP)에게 운영체제 내부로 엔트리 포인트를 제공하는 예외인 시스템 콜에 대해서도 논합니다.
3. 그 후 응용과 운영체제의 교차점에 위치한 프로세스와 시그널을 설명합니다.
4. 마지막으로 비지역성 점프에 대해 설명합니다.
8.1 예외상황
- 하드웨어와 운영체제의 교차점에 놓인 예외로 시작합니다
예외상황은 부분적으로는 하드웨어와 운영체제에 의해서 구현된 예외적인 제어흐름의 한가지 형태입니다.
예외상황과 예외처리에 대한 일반적인 상황을 이해하고, 현대 컴퓨터 시스템에서 종종 혼동되는 측면을 이해해봅시다.
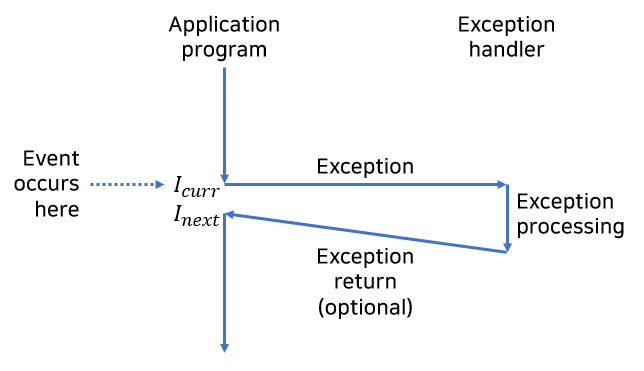
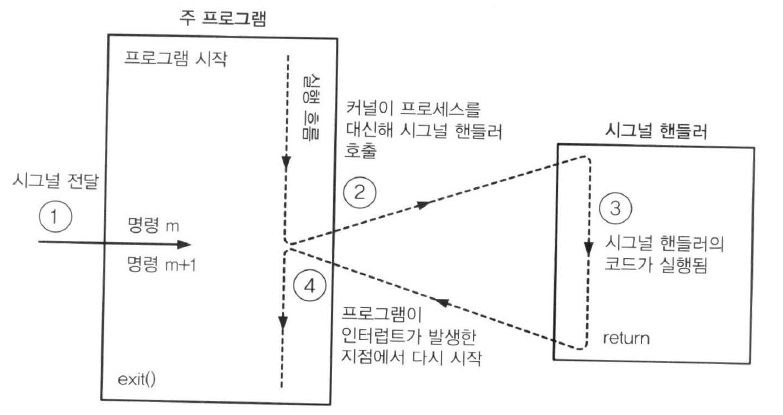
예외상황은 어떤 프로세서 상태의 변화에 대한 대응으로, 제어흐름의 갑작스런 변화입니다.
그림에서 프로세서는 현재 어떤 명령어I(curr)를 실행하고 있을 때 프로세서 상태에 중요한 변화(이벤트)가 일어나는 상황입니다.
프로세서가 이벤트가 발생했다는 것을 감지하면
예외 테이블이라고 하는 점프 테이블을 통해서 이 특정 종류의 이벤트를 처리하기 위해 특별히 설계된 운영체제 서브루틴(예외처리 핸들러)으로 간접 프로시저 콜을 하게 됩니다.
예외처리 핸들러가 처리를 마치면, 이벤트의 종류에 따라 세 가지 중의 한 가지 일이 발생합니다.
1. 핸들러는 제어를 현재 인스트럭션(I(curr))으로 돌려줍니다.
2. 핸들러는 제어I(next)로 돌려줍니다. 이는 예외상황이 발생하지 않았더라면 다음에 실행되었을 인스트럭션입니다.
3. 핸들러는 중단된 프로그램을 종료합니다.
8.1.1 예외처리
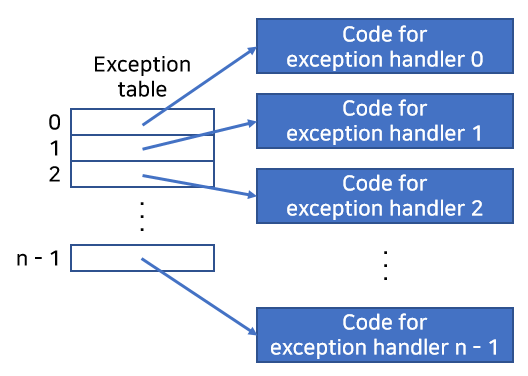
예외번호는 한 시스템 내에서 가능한 예외상황의 종류마다 중복되지 않는 양의 정수를 예외번호로 할당합니다.
예외번호는 예외 테이블에서 인덱스이며, 이 테이블의 시작주소는예외 테이블 베이스 레지스터라는 특별한 CPU 레지스터에 저장되어 있습니다.
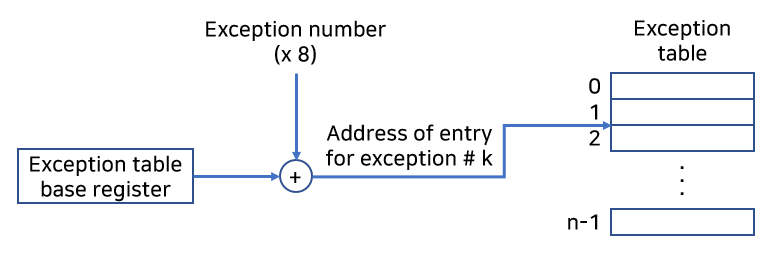
예외상황은 프로시저 콜과 유사하지만 중요한
차이점이 있습니다.
- 프로세서는 프로시저 콜을 사용해서 핸들러로 분기하기 전에 스택에 리턴주소를 푸시합니다. 반면에 예외는 종류에 따라 리턴주소는 현재 인스트럭션이거나 다음 인스트럭션이 됩니다.
- 프로세서는 핸들러가 리턴할 때 중단된 프로그램을 다시 시작하기 위해, 필요하게 될 스택 상에 추가적인 프로세서 상태를
푸시합니다.- 제어가 사용자 프로그램에서 커널로 전환하고 있을 때, 이 모든 아이템들은 사용자 스택 위가 아니라 커널 스택상에 푸시됩니다.
예외 핸들러가커널 모드에서 돌아가는데, 이것은 이들이 모든 시스템 자원에 완전히 접근할 수 있는 것을 의미합니다.
8.1.2 예외의 종류
- 인터럽트
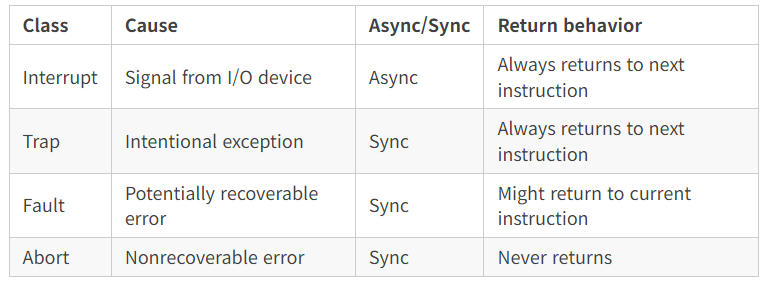
인터럽트는 프로세서 외부에 있는 입출력 디바이스로부터의 시그널의 결과로 비동기적으로 발생합니다.인터럽트 핸들러라고도 불립니다.
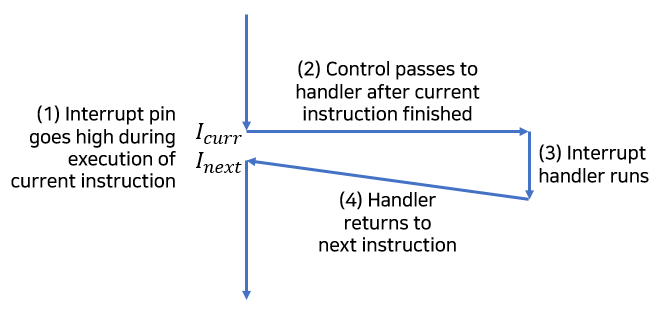
- 현재의 인터럭션이 실행을 완료한 후
- 프로세서는 인터럽트 핀이 high로 올라갔다는 것을 발견하고 시스템 버스에서 예외번호를 읽으며 적절한 인터럽트 핸들러를 호출합니다.
- 핸들러가 리턴할 때 제어를 다음 인스트럭션으로 돌려줍니다.
나머지의 예외 종류들(
트랩,오류,중단)은 지금의 인스트럭션을 실행한 결과로 동기적으로 일어납니다. 이것을오류 인스트럭션(faulting instruction)이라고 부릅니다.
- 트랩과 시스템 콜
트랩은 의도적인 예외상황으로, 어떤 인스트럭션을 실행한 결과로 발생합니다. 트랩의 가장 중요한 사용은 시스템 콜이라고 알려진 사용자 프로그램과 커널 사이의 프로시저와 유사한 인터페이스를 제공하는 것입니다.
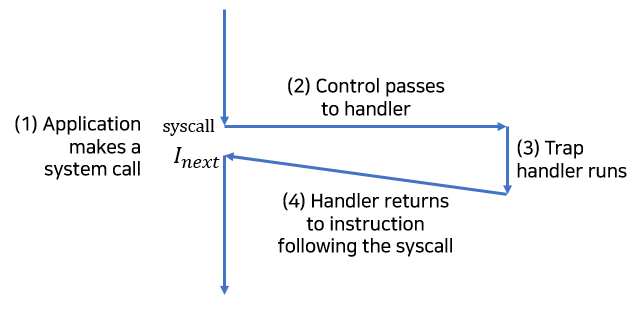
syscall인스트럭션을 실행하면 트랩이 인자들을 해독하고 적절한 커널 루틴을 호출하는 예외 핸들러로 가게 합니다.
트랩 핸들러는 응용 프로그램의 제어흐름에서 제어를 다음 인스트럭션으로 돌려줍니다.
- 오류(fault)
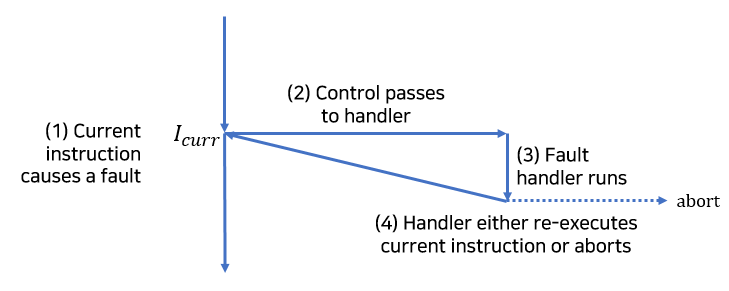
오류는 핸들러가 정정할 수 있을 가능성이 있는 에러 조건으로부터 발생합니다. 오류가 발생하면 프로세서는 제어를 오류 핸들러로 이동해줍니다.
만일 핸들러가 에러 조건을 정정할 수 있다면, 제어를 오류를 발생시킨 인스트럭션으로 돌려주어서 거기서부터 재실행합니다.
그렇지 않다면, 핸들러는 커널 내부의abort루틴으로 리턴해서 오류를 발생시킨 응용프로그램을 종료시킵니다.
- 중단
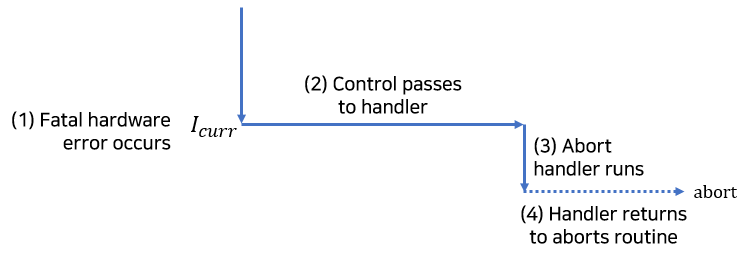
중단은 대개 DRAM이나 SRAM이 고장날 때 발생하는 패리티 에러와 하드웨어 같은 복구할 수 없는 치명적인 에러에서 발생합니다.
중단 핸들러는 절대로 응용프로그램으로 제어를 리턴하지 않습니다.

심각한 문제로 인해 가 종료되거나 예기치 않게 다시 시작되는 경우 블루 스크린 오류(블랙 스크린 오류 또는 중지 코드 오류라고도 함)가 발생할 수 있습니다. -Microsoft
8.1.3 리눅스/x86-64 시스템에서의 예외상황
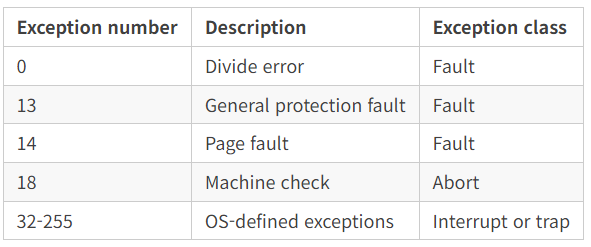
x86-64 시스템에서는 모두 256개의 서로 다른 예외 종류들이 있습니다. 32에서 255까지의 숫자들은 운영체제에서 정의된 인터럽트와 트랩에 대응됩니다.
나누기 에러(0). 응용이 0으로 나누려고 할 때, 또는 나눗셈 인스트럭션의 결과가 목적지 오퍼랜드에 비해 너무 큰 경우에 발생합니다.일반 보호 오류(13). 이 악명 높은 일반 보호 오류는 대개 프로그램이 가상 메모리의 정의되지 않은 영역을 참조하거나, 프로그램이 red-only 텍스트 세그먼트에 쓰려고 하기 때문입니다.페이지 오류(14). 오류 발생 인스트럭션이 재시작하는 예외의 예입니다.머신 체크(18). 오류 인스트럭션을 실행하는 동안에 검출된 치명적인 하드웨어의 결과로 발생합니다.
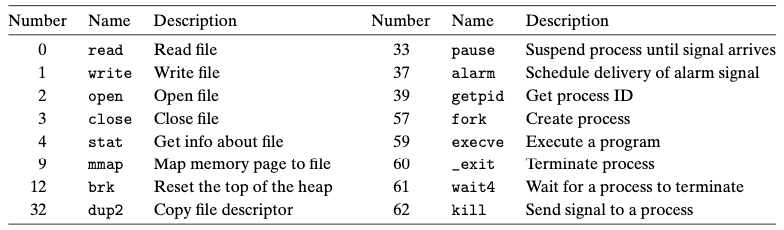
리눅스는 수백 개의 시스템 콜을 제공합니다. 각
시스템 콜은 커널 점프 테이블의 오프셋에 대응되는 유일한 정수를 갖습니다.
C 프로그램은 syscall 함수를 사용해서 직접 시스템 콜을 호출할 수 있습니다. 또한 표준 C 라이브러리는 대부분의 시스템 콜에 대해서 편리한 래퍼(wrapper) 함수들을 제공합니다.
또한 모든 인자들은 스택보다는 범용 레지스터를 통해서 이뤄집니다.
8.2 프로세스
그 후 응용과 운영체제의 교차점에 위치한
프로세스와 시그널을 설명합니다.
예외상황은 컴퓨터공학 분야에서 가장 심오하고 성공적인 개념 중의 하나인프로세스개념을 운영체제 커널이 제공할 수 있게 하는 기본 구성 블록입니다.
프로세스의 고전적인 정의는 실행 프로그램의 인스턴스입니다. 시스템 내의 각 프로그램은 어떤 프로세스의문맥(context)에서 돌아갑니다. 문맥은 프로그램이 정확하게 돌아가기 위해서 필요한 상태로 구성됩니다.
프로세스가 응용에 제공하는 주요 추상화는 다음과 같습니다.
- 프로그램이 프로세서를 혼자서 사용한다는 착각을 제공하는 독립적 논리 제어 흐름.
- 프로그램이 혼자서 메모리 시스템을 가진다는 착각을 제공하는 사적 주소공간.
8.2.1 논리적인 제어흐름
프로세스는 시스템에 서로 다른 여러 프로그램들이 함께 동작하고 있지만, 프로세서를 혼자서 사용한다는 착각을 느끼게 합니다.
예를 들어, 프로그램를 디버깅하기 위해디버거를 사용한다면, 실행 목적 파일 내에 있거나 프로그램과 동적으로 런타임에 링크된 공유 객체 내의 인스트럭션들에게 일련의 프로그램 카운터 PC 값들이 대응됩니다.
(요약하자면, 디버깅을 통해 여러 프로세스 중 보고자 하는 프로세스의 PC 값들만을 볼 수 있습니다.)
이러한 PC 값들의 배열을논리적 제어흐름또는논리흐름이라고 부릅니다.
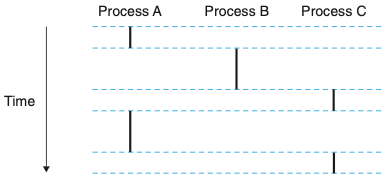
위 그림의 요점은 하나의 프로세서를 사용해서 여러 프로세스들이 교대로 돌아간다는 점입니다.
각 프로세스는 자신의 흐름의 일부분을 실행하고 나서 다른 프로세스들로 순서를 바꾸어 실행하는 동안선점됩니다.
8.2.2 동시성 흐름
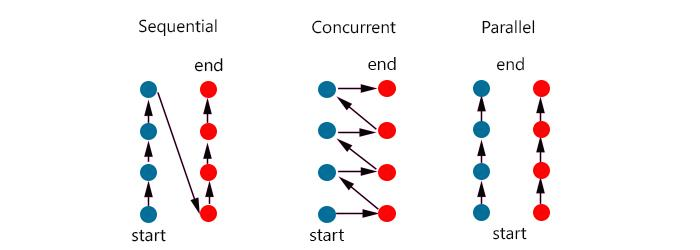
논리흐름은 컴퓨터 시스템 내에서 여러 가지 다른 형태를 갖습니다.
자신의 실행시간이 다른 흐름과 겹치는 논리흐름을동시성 흐름이라고 부르며, 이 두 흐름은 동시에 실행한다고 말합니다. 더 엄밀히 말하자면, Y가 시작해서 종료하기 전에 X가 시작하거나, X가 시작해서 종료하기 전에 Y가 시작할 때에만 흐름 X와 Y는 서로에 대해 동시적입니다.
공동으로 실행되는 흐름의 일반적인 현상이
동시성입니다.
프로세스가 다른 프로세스들과 교대로 실행된다는 개념은멀티태스킹입니다. 한 프로세스가 자신의 흐름 일부를 실행하는 매 시간 주기를타임 슬라이스라고 부릅니다. 그래서 멀티태스킹은타임 슬라이싱이라고도 부릅니다.
8.2.3 사적 주소 공간
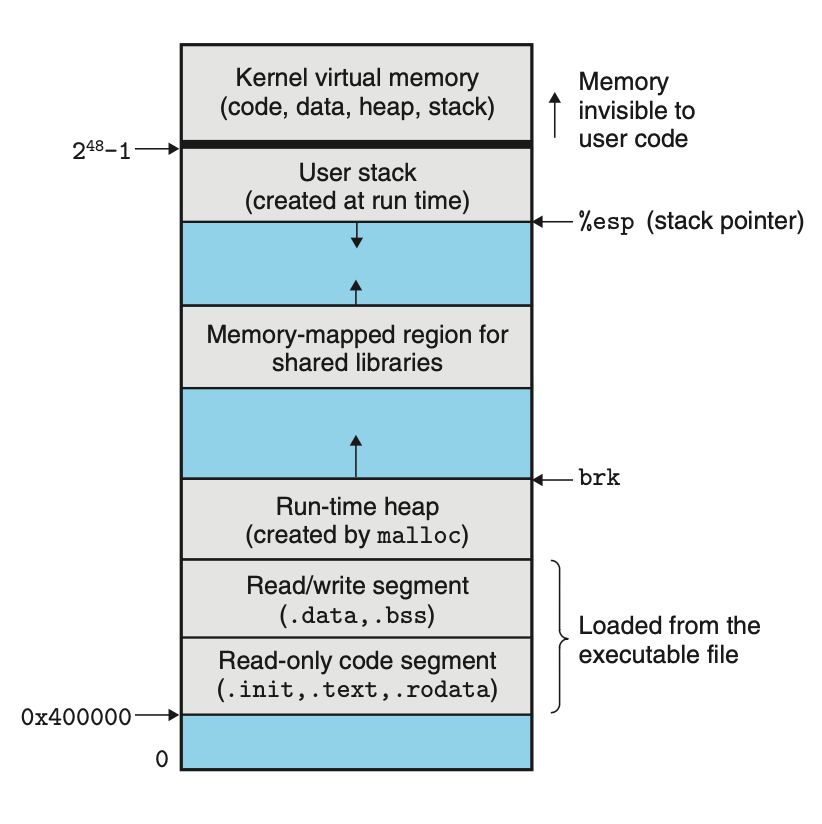
n비트 주소를 갖는 머신에서 주소공간은 2^n의 가능한 주소들로 0,1 ... , 2^n-1의 자신만의
사적 주소공간을 갖습니다. 이 공간은 일반적으로 다른 프로세스에 의해서 읽히거나 쓰일 수 없다는 의미로 이 공간은 사적입니다.
이로써 프로세스는 자신이 시스템의 주소공간을 혼자서 사용한다는 착각을 불러일으킵니다.
8.2.4 사용자 및 커널 모드
운영체제가 완벽한 프로세스 추상화를 제공하기 위해선 주소공간뿐 아니라, 응용프로그램이 실행할 수 있는 인스트럭션들을 제한하는 메커니즘을 제공해야 합니다.
프로세서는 이러한 작업을 지원하기 위해서 프로세스가 현재 가지고 있는 특권을 저장하는 일부 제어 레지스터로
모드 비트를 제공합니다. 모드 비트를 통해 프로세스는커널 모드(슈퍼바이저 모드)로 동작합니다. 커널 모드에서 돌고 있는 프로세스는 인스트럭션 집합의 어떤 인스트럭션도 실행할 수 있으며, 시스템 내의 어떤 메모리 위치도 접근할 수 있습니다.
모드 비트가 세트되지 않을 때는 프로세스는
사용자 모드에서 돌고 있는 상태입니다. 사용자 모드에서는 특수 인스트럭션(프로세서를 멈추거나, 모드 비트를 변경하거나, 입출력 연산을 초기화)을 실행할 수 없습니다. 또한 주소공간의 커널 영역에 있는 코드나 데이터를 직접 참조할 수도 없습니다.
대신 사용자 프로그램은 아래 설명할 시스템 콜을 통해 커널 코드와 데이터에 간접적으로 접근해야 합니다.
프로세스가 커널 모드로 진입하는 유일한 방법은 인터럽트, 오류, 트랩 시스템 콜과 같은 예외를 통해야 합니다.
예외를 발생해서 제어가 예외 핸들러로 넘어가면
1. 프로세서는 사용자 모드에서 커널 모드로 변경합니다.
2. 핸들러는 커널 모드에서 돌아갑니다.
3. 제어가 응용 코드로 돌아오면 프로세서는 모드를 커널 모드에서 다시 사용자 모드로 변경합니다.
8.2.5 문맥 전환
운영체제의
커널은문맥 전환(context switch)라고 알려진 예외적인 제어 흐름의 상위수준 형태를 사용해서 멀티태스킹을 구현합니다.
커널은 각 프로세스마다 커널이 선점된 프로세스를 다시 시작하기 위해서 필요로 하는 상태인 컨텍스트를 유지합니다.
컨텍스트에는 범용 레지스터, 부동소수점 레지스터, 프로그램 카운터, 사용자 스택, 여러 가지 커널 자료구조 같은 객체들의 값으로 구성됩니다.
커널은 프로세스가 실행되는 동안의 어떤 시점에 현재 프로세스를선점(일시적으로 정지)하고 이전에 선점된 프로세스를 다시 시작할 것을 결정할 수 있습니다. 이 결정은스케줄링이라고 알려져 있으며,스케줄러라고 불리는 커널 내부의 코드에 의해 처리됩니다. 커널이 실행할 새 프로세스를 스케줄한 후에 현재 프로세스를 선점(일시 정지)하는 것을 문맥 전환이라고 하며, 이 메커니즘을 사용해서 새로운 프로세스로 제어를 이동합니다.
문맥 전환은
1. 현재 프로세스의 컨텍스트를 저장합니다.
2. 이전에 선점된(일시 정지된) 프로세스의 저장된 컨텍스트를 복원합니다.
3. 제어를 이 새롭게 복원된 프로세스로 전달합니다.
문맥 전환은 커널이 사용자를 대신해서 시스템 콜을 실행하고 있을 때 일어날 수 있습니다. 만일 시스템 콜이 어떤 이벤트의 발생을 기다리기 때문에 블록된다면 커널은 현재 프로세스를 sleep시키고 다른 프로세스로 전환합니다.
또한 인터럽트의 결과로 발생할 수 있습니다.
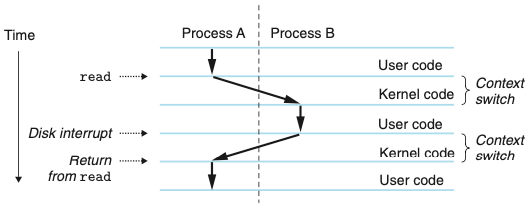
위 그림에서 프로세스 A는
read 시스템 콜을 실행해서 커널에 트랩을 걸 때까지는사용자 모드로 돌고 있습니다.
1. 커널의트랩 핸들러는 디스크 컨트롤러에게DMA전송을 요청합니다. 디스크 컨트롤러가 데이터를 디스크에서 메모리로 전송을 완료한 후에 프로세서에 인터럽트를 걸도록 디스크를 제어합니다.
2. 디스크는 데이터를 선입하는 데 비교적 긴 시간이 걸립니다. 그래서 중간에 커널은 프로세스 A에서 B로 문맥 전환을 수행합니다.
(전환하기 전 커널은 프로세스 A를 대신해서 사용자 모드에서 인스트럭션들을 실행하고 있었다는 것을 잊지 마세요)
3. 커널은 프로세스 A를 대신해서 커널 모드에서 인스트럭션을 수행하고 있습니다.
4. 그 후 프로세스 B를 대신해서 인스트럭션의 실행을 시작합니다. 전환 후에 커널은 프로세스 B를 대신해서 사용자 모드에서 인스트럭션들을 실행합니다.
5. 프로세스 B는 그 후에 디스크가인터럽트를 보내서 데이터가 디스크에서 메모리로 전송되었다고 알려줄 때까지 사용자 모드에서 잠시 동안 동작합니다.
6. 커널은 프로세스 B에서 A로, 프로세스 A의 제어를 read 시스템 콜 이후에 나오는 인스트럭션 위치로 리턴하는 문맥 전환을 수행합니다.
7. 프로세스는 다음 예외가 발생할 때까지 계속 도는 이 방식이 계속됩니다.
8.3 시스템 콜의 에러 처리
Unix 시스템 수준 함수가 에러를 만날 때 이들은 대개 -1을 리턴하고, 전역 정수 변수인
errno을 세팅해서 무엇이 잘못되었는지를 나타냅니다.
pid_t Fork(void){
pid_t pid;
if ((pid = fork()) < 0)
unix_error("Fork error");
return pid;
}
// 이 래퍼가 주어질 때 fork로 호출하는 것이 하나의 압축된 라인으로 줄어듭니다.
pid = Fork();이러한 에러 핸들링 래퍼를 사용하면 에러 체크를 무시해도 된다는 잘못된 인상을 주지 않으면서도 코드가 간략해집니다. 대문자는 래퍼를 나타내고, 소문자는 항상 기본 이름을 나타낸다는 점을 주목하세요!
8.4 프로세스의 제어
Unix는 C 프로그램으로부터 프로세스를 제어하기 위한 많은 시스템 콜을 제공합니다.
8.4.1 프로세스 ID 가져오기
각각의 프로세스는 고유의 양수 프로세스 ID를 가집니다.
getpid()함수는 호출하는 함수의 PID를 리턴합니다.
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
Return: PID of either the caller or the parent8.4.2 프로세스의 생성과 종료
프로그래머의 관점에서 프로세스는 다음 세 가지 상태 중 하나로 생각할 수 있습니다.
running. 프로세스는 CPU를 실행하거나 실행을 기다리고 있으며, 궁극적으로 커널에 의해서 스케줄될 것입니다.Stopped. 프로세스의 실행은 정지한 상태이고 스케줄되지 않습니다.Terminalated. 프로세스는 다음의 세 가지 이유 중 하나로 영구적으로 정지됩니다.
- 프로세스를 종료하는 시그널을 받았을 때
- 메인 루틴에서 리턴할 때
- exit 함수를 리턴할 때
#include <stdlib.h>
void exit(int status);
This function does not return부모 프로세스는
fork함수를 불러서 자식 프로세스를 생성합니다.
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
Returns: 0 to child, PID of child to parent, -1 on error새롭게 생성된
자식 프로세스는 부모와 거의 동일합니다.
자식은 코드, 데이터 세그먼트, 힙, 공유된 라이브러리, 사용자 스택을 포함하는 부모의 사용자수준 가상 주소공간과 동일한(그러나 분리된) 복사본을 갖습니다. 부모가 fork를 호출했을 때 자식은 부모가 오픈한 파일을 모두 읽고 쓸 수 있습니다.
부모와 자식 간의 가장 중요한 차이는 서로 다른 PID를 가진다는 것입니다.
fork함수는 한 번 호출되지만 두 번 리턴합니다. 한번은 호출한 프로세스에서(부모), 다른 한 번은 새롭게 생성된 자식 프로세스에서 리턴합니다. 부모에서 fork는 자식의 PID를 리턴합니다.
8.4.3 자식 프로세스의 청소
프로세스가 어떤 이유로 종료될 때, 커널은 시스템에서 즉시 제거되지 않습니다. 그 대신 프로세스는 부모가 청소할 때까지 종료된 상태로 남아 있습니다. 종료되었지만 아직 청소되지 않은 프로세스를
좀비(zombie)라고 부릅니다.
부모 프로세스가 종료될 때, 커널은 init 프로세스로 하여금 모든 고아가 된 자식들의 입양된 부모가 되도록 합니다.
이init프로세스는 PID 1번이며, 시스템의 초기화 과정에서 커널에 의해 생성되고, 결코 종료되지 않으며, 모든 프로세스의 조상입니다.
쉘과 서버와 같이 오랫동안 실행하는 프로그램들 또한 항상 자신의 좀비들을 소거해야 합니다. 프로세스는
waitpid함수를 호출해서 자신의 자식들이 종료되거나 정지되기를 기다립니다.
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pit_t pid, int *statusp, int options);
Returns: PID of child if OK, 0 (if WNOHANG), or -1 on error8.4.4 프로세스 재우기
sleep함수는 일정 기간 동안 프로세스를 정지시킵니다.#include <unistd.h> unsinged int sleep(unsigned int secs); Return: seconds left to sleepsleep은 요청한 시간이 경과하면
0을 리턴하고, 그렇지 않은 경우에는 남은 시간 동안 잠을 잡니다.
또 다른 유용한 함수는
pause함수로, 호출하는 함수를 시그널이 프로세스에 의해서 수신될 때까지 잠을 재우는 함수입니다.#include <unistd.h> int pause(void); Always returns -1
8.4.5 프로그램의 로딩과 실행
execve함수는 현재 프로그램의 컨텍스트 내에서 새로운 프로그램을 로드하고 실행합니다.
#include <unistd.h>
int execve(const char *filename, const char *argv[], const char *envp[]);
Does not return if OK; returns -1 on error
execv함수는 실행가능 목적파일이 filename과 인자 리스트 argv, 환경변수 리스트 envp를 사용해서 로드하고 실행합니다. execve는 파일 이름을 찾을 수 없는 에러가 있는 경우에만 호출하는 프로그램으로 리턴합니다.
그래서 한 번 호출되고 두번 리턴하는fork와는 달리,execve는 한 번 호출되고 절대로 리턴하지 않습니다.
8.4.6 프로그램을 실행하기 위해 fork와 execve 사용하기
Unix 쉘과 웹 서버 같은 프로그램들은 fork와 execve 함수를 많이 사용합니다.
쉘은 사용자를 대신해서 다른 프로그램을 실행해주는 상호작용인 응용수준 프로그램입니다.
프로그램 vs 프로세스
잠깐!
프로그램과프로세스의 차이를 이해하고 계신가요?
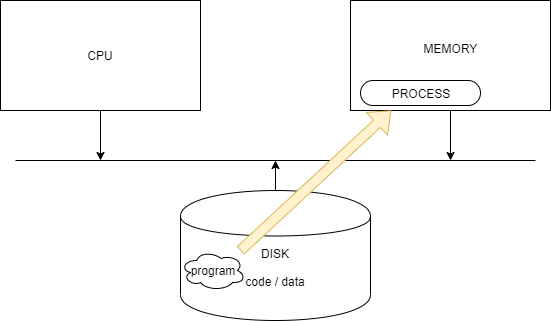
프로그램은 코드와 데이터가 합쳐진 것입니다. 프로그램은 디스크 상에 목적파일이나 주소공간에 세그먼트로 존재할 수 있습니다.
프로세스는 실행 중에 있는 프로그램의 특정 사례입니다. 프로그램은 항상 어떤 프로세스의 컨텍스트 내에서 실행됩니다.
이러한 차이를 바탕으로 fork와 execve 함수를 이해해봅시다.
fork함수는 부모의 복제인 새로운 자식 프로세스에서 동일한 프로그램을 실행시킵니다.
execve함수는 새 프로그램을 현재 프로세스의 컨텍스트 내에서 로드하고 실행합니다. 현재 프로세스의 주소공간을 덮어쓰지만 새 프로세스는 만들지 않습니다. 새 프로그램은 여전히 같은 PID를 가지며, execve 함수를 호출할 때 열려 있던 모든 파일 식별자를 물려받습니다.
8.5 시그널
여기까지
예외 메커니즘을 제공하기 위해서 하드웨어와 소프트웨어가 어떻게 협력하는지를 살펴봤습니다. 그리고 운영체제가 예외를 사용해서 프로세스문맥 전환이라고 알려진 일종의예외적인 제어흐름을 어떻게 지원하는지도 알게 되었습니다.
이제 리눅스 시그널이라는 상위 수준의 소프트웨어 형태의 예외적 제어흐름을 배웁니다. 이 시그널은 프로세스와 커널이 다른 프로세스를 중단하도록 합니다.
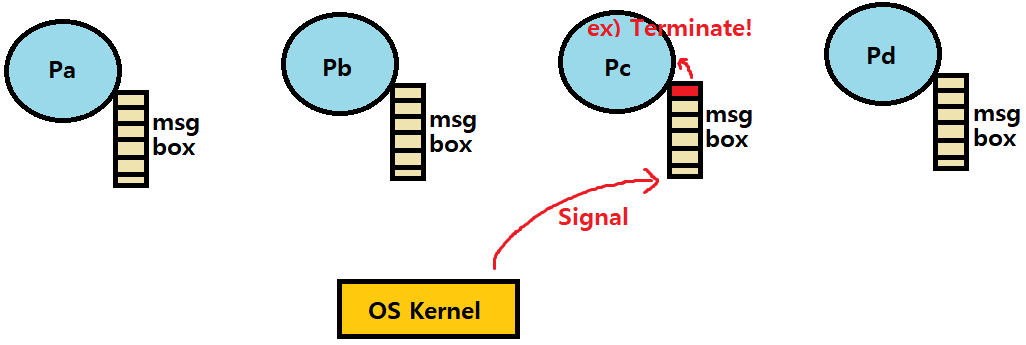
시그널은 작은 메시지 형태로, 프로세스에서 시스템 내에서 어떤 종류의 이벤트가 일어났다는 것을 알려줍니다.
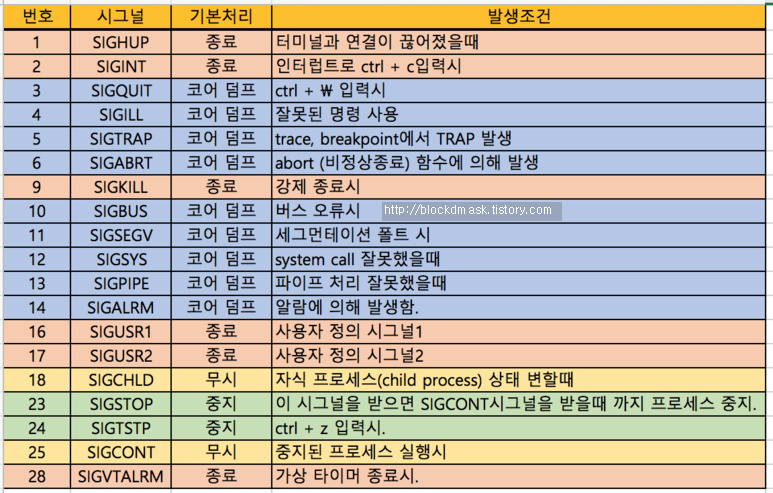
리눅스 시스템에서 지원되는 30개의 서로 다른 종류의 시그널의 타입은 특정 종류의
시스템 이벤트에 대응됩니다.
하위 수준 하드웨어 예외는 커널의예외 핸들러에 의해 처리되며, 정상적으로는 사용자 프로세스에서는 볼 수 없습니다. 시그널은 이러한 예외들을 사용자 프로세스에 노출해주는 메커니즘을 제공합니다.
예를 들어, 어떤 프로세스가 0으로 나누려고 한다면, 커널은
SIGFPE신호(8)을 프로세스에 보내줍니다.
만일 어떤 프로세스가 잘못된 인스트럭션을 실행하려 한다면, 커널은SIGILL시그널(4번)을 보냅니다.
어떤 프로세스가 잘못된 메모리를 참조한다면, 커널은SIGEGV시그널(11)번을 보냅니다.
다른 시그널들은 커널 내 또는 다른 사용자 프로세스 내부의 상위 수준 소프트웨어 이벤트에 대응됩니다.
예를 들어, 어떤 프로세스가 포그라운드에서 돌아가고 있을 때 Ctrl+C를 입력하면 커널은SIGINT(2)를포그라운드 프로세스 그룹에 속한 각 프로세스들에게 보냅니다.
어떤 프로세스는 다른 프로세스에SIGKILL시그널(9)을 보내서 강제로 종료할 수 있습니다.
8.5.1 시그널 용어
시그널을 목적지 프로세스로 전달하는 것은
두 단계로 이루어집니다.
시그널 보내기. 커널은 목적지 프로세스의 컨텍스트 내에 있는 일부 상태를 갱신해서 시그널을 목적지 프로세스로 보냅니다.
시그널은 다음 두 가지 이유 중 하나로 보내집니다.
- 커널이 0으로 나누기나 자식 프로세스의 종료 같은 시스템 이벤트를 감지한 경우
- 어떤 프로세스가 커널에 명시적으로 시그널을 목적지 프로세스에 보낼 것을 요구하기 위해 kill 함수를 호출한 경우
프로세스는 시그널을 자기 자신에게 보낼 수 있습니다.
시그널 받기. 목적지 프로세스는 배달된 신호에 대해서 커널이 어떤 방식으로 반응해야 할 때 목적지 프로세스는 배달된 신호에 대해서 커널이 어떠한 방식으로 반응해야 할 때 시그널을 받습니다.
프로세스는 시그널 핸들러라고 부르는 사용자수준 함수를 실행해서 시그널을 무시하거나, 종료하거나, 획득할 수 있습니다.
보내졌지만 아직 받지 않은 시그널은
펜딩 시그널이라고 부릅니다. 어떤 시점에서 특정 타입에 대해 최대 한 개의 펜딩 시그널이 존재할 수 있습니다. 각 프로세스에 대해 커널은pending 비트 벡터(시그널 마스크, signal mask) 내에 펜딩하고 있는 시그널의 집합을 관리하며,blocked 비트 벡터내에서 블록된 시그널의 집합을 관리합니다.
8.5.2 시그널 보내기
Unix 시스템은 시그널을 프로세스에 보내는 여러 메커니즘을 제공하는데, 모든 메커니즘은
프로세스 그룹개념을 사용합니다.
- 프로세스 그룹
모든 프로세스는 정확히 한 개의 프로세스 그룹에 속하며, 이를 양수 process group ID로 식별합니다.
getpgrp함수는 현재 프로세스의 프로세스 그룹 ID를 리턴합니다.#include <unistd.h> pid_t getpgrp(void); Return Process group ID of calling process
기본적으로,
자식 프로세스는 자신의 부모와 동일한 프로세스 그룹에 속합니다. 프로세스는 자신의 프로세스 그룹 또는 다른 프로세스의 그룹을setpgid함수를 사용해서 변경할 수 있습니다.#include <unistd.h> int setpgid(pid_t pid, pid_t pgid); Return 0 on success, -1 on error
setpgid함수는 프로세스 pid의 프로세스 그룹을 pgid로 변경합니다.
- 시그널을
/bin/kill프로그램을 사용해서 보내기
/bin/kill 프로그램은 다른 프로세스로 임의의 시그널을 보냅니다. 예를 들어, 다음의 명령은 시그널 9번(SIGKILL)을 프로세스 15213에 보냅니다.
linux> /bin/kil -9 15213/bin/kill과 같이 완전한 경로를 사용하고 있다는 점으로 일부 unix 쉘이 자신만의 내장
kill명령어를 가지고 있다는 것을 알 수 있습니다.
- 키보드에서 시그널 보내기
Unix 쉘은 작업의 추상화를 사용해서 한 개의 명령줄을 해석한 결과로 만들어진 프로세스에 반영합니다. 언제나 최대 한 개의 포그라운드 작업과 0 또는 그 이상의 백그라운드 작업이 존재합니다.
다음과 같이 입력하면 두 개의 프로세스가 Unix 파이프로 연결된 포그라운드 작업을 만듭니다.linux> ls | sort하나는 ls 프로그램을 실행하고, 다른 하나는 sort 프로그램을 실행합니다.
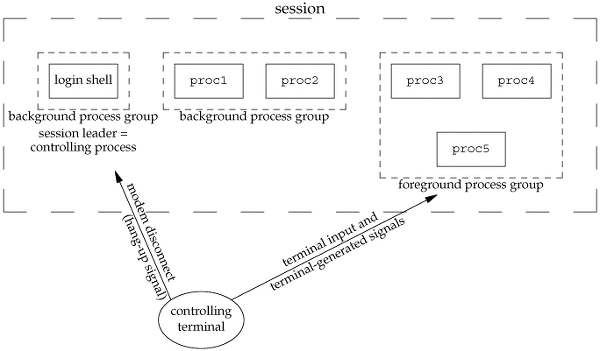
쉘은 각 작업마다 별도의 프로세스 그룹을 만듭니다. 일반적으로 프로세스 그룹 ID는 작업 내에 부모 프로세스들 중의 하나에서 가져옵니다.
- kill 함수로 시그널 보내기
프로세스는
kill함수를 호출해서 시그널을 다른 프로세스로 보냅니다.#include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig); Returns 0 if OK, -1 on error
- alarm 함수로 시그널을 보내기
프로세스는
SIGNALRM시그널을 alarm 함수를 호출해서 자기 자신에게 보낼 수 있다.#inclue <unistd.h> unsigned int alarm(unsigned int secs); Returns remaining seconds of previous alarm, or 0 if no previous alarm
8.5.3 시그널의 수신
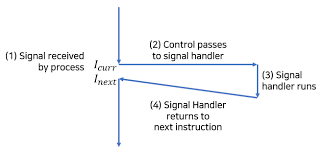
커널이 프로세스 p를 커널 모드에서 사용자 모드로 전환 할 때(예를 들어, 시스템 콜에서 리턴하거나 문맥 전환을 끝마치는 것과 같은), 커널은 프로세스 p에 대한 블록되지 않은펜딩 시그널(pending & ~blocked)의 집합을 체크합니다.
만일 이 집합이 비어 있다면 커널은 제어를 p의 논리 제어 흐름 내의 다음인스트럭션 I(next)로 전달합니다.
이 집합이 비어 있지 않다면, 커널은 집합 내 어떤 시그널 k를 선택해서(대개 가장 작은 k) p가시그널 k를 수신하도록 합니다.
시그널을 수신하면 프로세스는 동작을 개시하는데, 이 동작이 완료되면 제어는 p의 논리 제어 흐름 내의 다음
인스트럭션 I(next)로 돌아갑니다.
각 시그널 타입은 사전에 정의된 기본 동작을 가지며(8.5 그림의), 이들은 다음 동작 중의 하나입니다.
- 프로세스가 종료
- 프로세스는 종료하고 코어를 덤프
- 프로세스는 SIGCONT 시그널에 의해 재시작될 때까지 정지
- 프로세스는 시그널을 무시
프로세스는 시그널과 연결된 기본 동작을
signal함수를 사용해서 수정할 수 있습니다. 예외가 되는 것은SIGSTOP과SIGKILL이며, 이들의 기본 동작은 변경될 수 없습니다.#incldue <signal.h> typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler); Returns Pointer to previous handler if OK, SIG_ERR on error(does not set errno)
signal함수는 시그널signum과 연결된 동작을 다음의 세 가지 방법 중의 하나로 바꿀 수 있습니다.
- 핸들러가
SIG_IGN이면, signum 타입의 시그널은 무시됩니다.- 핸들러가
SIG_DFL이면, signum 타입의 시그널에 대한 동작은 기본 동작으로 돌아갑니다.- 그 외의 경우에, 핸들러는 사용자가 정의한 함수의 시그널 핸들러라고 부르는 주소가 되며, 이것은 프로세스가 ginum 타입의 시그널을 수신할 때마다 호출될 것입니다.
핸들러 설치(installing)는 핸들러의 주소를 signal 함수로 넘겨주는 방법은 기본 동작을 변경하는 것입니다.시그널을 잡는다(catching the signal)은 핸들러를 호출하는 것입니다.시그널을 처리한다(handling the signal)은 핸들러의 실행을 말합니다.
어떤 프로세스가 타입 k의 시그널을 잡을 때, 시그널 k를 위해 핸들러는 k에 설정된 한 개의 정수 인자를 사용해서 호출합니다. 이 인자는 동일한 핸들러 함수가 서로 다른 종류의 시그널을 잡을 수 있도록 해줍니다.
핸들러가 return 문장을 실행할 때,제어는 프로세스가 시그널의 수신으로 중단되었던 제어흐름 내 인스트럭션으로 다시 전달됩니다. 만일 일부 시스템에서 중단된 시스템 콜들이 에러가 발생하면 즉시 리턴하기도 합니다.
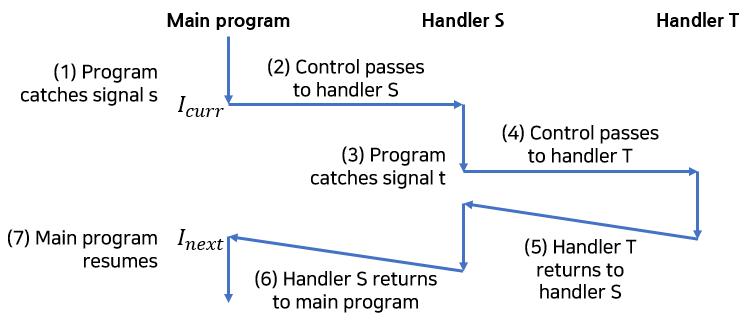
시그널 핸들러는 그림에 나타난 것처럼 다른 핸들러에 의해 중단될 수 있습니다. 이 예제에서
1. 메인 프로그램은 메인 프로그램을 중단하고, 제어를 핸들러 S로 전달하는 시그널 s를 붙잡습니다.
2. S가 돌고 있는 동안 시그널 t!=s인 t를 붙잡으며 S를 중단하고 제어를 핸들러 T로 전송합니다.
3. T가 리턴할 때 S는 중단되었던 위치에서 다시 실행을 이어나갑니다.
4. 결국 S는 리턴하고 제어를 다시 메인 프로그램으로 전달하며, 처음에 떠난 자리에서 실행을 다시 하게 됩니다.
8.5.4 시그널 블록하기와 블록 해제하기
리눅스는 묵시적 혹은 명시적인 방법으로 시그널을
블록하는 방법을 제공합니다.
묵시적 블록 방법. 기본적으로 커널은 핸들러에 의해 처리되고 있는 유형의 모든 대기 시그널들의 처리를 막습니다.
한마디로 한 시그널 핸들러가 실행되고 있다면, 다른 시그널은 현재의 핸들러가 리턴하기 전까지는 수신할 수 없습니다.명시적 블록 방법. 응용 프로그램들은sigprocmask함수와 이들의 도움함수를 이용해서 시그널들을 명시적으로 블록하거나 블록 해제할 수 있습니다.#include <signal.h> int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); int sigemptyset(sigset_t *set); int sigfillset(sigset_t *set); int sigaddset(sigset_t *set, int signum); int sigdelset(sigset_t *set, int signum); Return 0 if OK, -1 on error int sigsmember(const sigset_t *set, int signum); Return 1 if memeber, 0 if not, -1 on error
sigprocmask함수는 현재 블록된 시그널의 집합(blocked 비트 벡터)를 변경합니다. 특정 동작은 how 값에 따라 달라집니다.
SIG_BLOCK. set에 있는 시그널들을 blocked에 추가합니다. (blocked = blocked|set)SIG_UNBLOCK. set에 있는 시그널들을 blocked에서 제거합니다.(blocked = blocked & ~set)SIG_SETMASK. blocked = set
8.5.5 시그널 핸들러 작성하기
시그널의 처리는 리눅스 시스템 수준 프로그래밍에서 가장 까다로운 부분입니다. 핸들러는 이해하기 어려운 몇 가지 특성을 가집니다.
1. 핸들러는 메인 프로그램과동시적으로 돌아가고, 같은 전역변수를 공유하기 때문에 메인 프로그램과 다른 핸들러들은 뒤섞일 수 있습니다.
2. 언제, 어떻게 시그널들이 수신될 수 있을지는 직관적이지 않습니다.
3. 다른 시스템들은 다른 시그널 처리 방식을 갖습니다.
이러한 이유로 우리는 안전하고, 정확하고, 이식성이 높은 시그널 핸들러를 작성하는 기본 지침을 배워야 합니다.
- 안전한 시그널의 처리
시그널 핸들러는 메인 프로그램과 다른 핸들러들과 함께 돌아갈 수 있기 때문에 까다롭습니다. 만일 핸들러와 메인 프로그램이 동시에 같은 전역 데이터구조에 접근하려고 한다면, 결과는 예측 불가능하고 종종 치명적인 결과를 낳습니다.
- 핸들러는 가능한 한 작고 간단하게 유지해야 합니다.
- 핸들러에서 비동기성-시그널-안전한 함수만 호출해야 합니다. 안전한 함수는 그것이 재진입 가능하거나, 어떤 시그널 핸들러에 의해 중단될 수 없기 때문에 어떤 시그널 핸들러로부터 안전하게 호출할 수 있습니다. 시그널 핸들러에서 출력을 생성하는 유일한 안전한 방법은
write함수를 사용하는 것입니다.(printf나 sprintf는 안전하지 못합니다.)
이러한 제한사항을 극복하기 위해SIO 패키지(Safe I/O)라는 안전한 함수를 개발했고, 간단한 메시지를 출력하기 위해 이용할 수 있습니다.#include "scapp.h" size_t sio_putl(long v); size_t sio_puts(char s[]); Returns number of bytes transferred if OK, -1 on error void sio_error(char s[]); Returns nothing
sio_putl과sio_puts함수는 long과 스트링을 각각 표준 출력장치에 출력합니다.sio_error함수는 에러 메시지를 출력하고 종료합니다.
- eeror를 저장하고 복원해야 합니다. 많은 리눅스 비동기-시그널-안전한 함수들은 이들이 에러를 가지고 리턴할 때
errno를 설정합니다. errorno를 핸들러에 진입할 때 지역변수에 저장하고 해들러가 리턴하기 전에 복원하면 됩니다.
- 모든 시그널을 블록시켜서 공유된 전역 자료들로의 접근을 보호해야 합니다. 핸들러가 메인 프로그램이나 다른 핸들러와 전역 자료구조를 공유한다면, 현재 진행 중인 핸들러와 메인 프로그램은 이 자료구조에 접근하는 동안(
write,read) 일시적으로 모든 시그널들을 블록시켜야 합니다. 자료구조에 접근하는 동안 시그널들을 일시적으로 블록시키면 어떤 핸들러가 이 인스트럭션들을 중단하지 않음을 보장하게 됩니다.
- 전역변수들을
volatile로 선언해야 합니다. 어떤 핸들러와 main 루틴이 전역변수 g를 공유하는 상황을 가정해봅시다.
핸들러가 g를 갱신한다면, main은 주기적으로 g를 읽을 것입니다.최적화 컴파일러는 main의 g값이 전혀 바뀌지 않은 것으로 보일 것입니다. 컴파일러는 g에 대한 모든 참조를 만족시키기 위해 레지스터에 캐시되어 있는 g 값의 사본을 사용해도 안전하다고 생각하게 될 것입니다. 이 경우 main 함수는 핸들러에 의해 갱신된 값들을 전혀 알 수 없습니다.
우리는 vlatile 형의 지시자로 캐시에 넣지 말도록 컴파일러에게 지시할 수 있습니다.
volatile int g와 같은 형식은 이 코드에서 매번 참조할 때 메모리에서 g 값을 읽어오도록 강요합니다.
sig_atomic_t로 플래그들을 선언해야 합니다. 보편적인 핸들러는 시그널의 수신을 전역 플래그에 써서 기록합니다. main 프로그램은 주기적으로 이 플래그를 읽고, 시그널에 반응하고, 플래그를 지웁니다. C는 정수형 잘형 sig_atomic_t를 제공해서 이 자료형에 대해 이들이 한 개의 인스트럭션이 구현될 수 있기 때문에 읽기와 쓰기가원자형(atomic, 중단 불가)인 것이 보장됩니다. 중단될 수 없기 때문에 일시적으로 시그널을 블록시키지 않고도 안전합니다.
하지만 원자성에 대한 보장은 개별적인 읽기와 쓰기에만 적용된다는 것을 유의해주세요. flag++이나 flag = flag+10과 같은 다수의 인스트럭션을 필요로 하는 갱신의 경우에는 적용되지 않습니다.
하지만 이러한 지침은 항상, 반드시 필요한 것이 아닙니다. 우리가 사용하는 핸들러가 절대로 errno를 변경하지 않는다는 것을 안다면, 우리는 errno를 저장하고 복원할 필요가 없습니다. 공유된 전역 자료구조에 대한 접근의 경우도 마찬가지겠죠.
- 정확한 시그널 처리
pending 비트 벡터의 어떤 특정 유형의 대기 시그널은 최대 한 개만 존재합니다. 만일 목적지 프로세스가 현재 시그널 k에 대한 핸들러를 실행하며 블록시키는 상황을 가정해봅시다. 유형 k의 두 개의 시그널이 목적지 프로세스에 보내진다면, 두 번째 시그널은 그저 버려집니다. 대기하는 시그널의 존재는 그저 최소 한 개의 시그널이 도착했다는 것으로 알 수 있습니다.
- 호환성 있는 시그널 핸들링
유닉스 시그널 핸들링은 서로 다른 시스템에서 다른 시그널 처리 방식을 갖습니다.
- 일부 오래된 유닉스 시스템들은 signal 함수의 의미가 다릅니다. 이런 시스템들에선 핸들러는 signal을 매 실행 때마다 명시적으로 자신을 재설치해야 합니다.
- 시스템 콜들은 중단될 수 있습니다. read, wait, accept와 같이 프로세스를 오랜 시간 잠재적으로 블록할 가능성이 있습니다. 이런 시스템 콜들을
느린 시스템 콜(slow system call)이라고 부릅니다. 일부 오래된 유닉스 버전에서 핸들러는 시그널을 잡을 대 중단된 느린 시스템 콜들은 시그널 핸들러가 리턴할 때 다시 시작하지 않고, 그 대신 에러 조건과 errno를 EINTR로 설정해서 사용자에게 즉시 리턴합니다. 이런 시스템에서는 프로그래머는 수동으로 중단된 시스템 콜들을 재시작하는 코드를 포함해야 합니다.
8.5.6 치명적인 동시성 버그를 피하기 위해서 흐름을 동기화하기
같은 저장장치의 위치에서 읽고 쓰는
동시성 흐름을 프로그래밍하는 방법에서 근본적인 문제는, 어쨌든 동시성 흐름을 동기화해서 각각의 가능한 중첩들이 정확한 답을 만들 수 있는 최대한의 중첩들의 집합을 만드는 것입니다.
이를 위해 예외적 제어흐름에 관한 내용을 활용할 수 있습니다.
747p의 미묘한 동기화 에러를 갖는 쉘 프로그램 예제는 스스로 읽어보세요!
경주(race)라는 고전적인 동기화 에러의 예가 나옵니다.
8.5.7 명시적으로 시그널 대기하기
종종 메인 프로그램은 특정 시그널 핸들러가 동작하기를 명시적으로 기다려야 할 필요가 있습니다. 위 경주(race)의 상황에서
sigsuspend함수를 이용하는 것이 해결책이 될 수 있습니다.
sigsuspend함수는 현재 블록된 집합들을 일시적으로 mask로 교체하고, 자신의 동작이 핸들러를 실행하는 것이나, 프로세스를 종료하는 것인 시그널을 수신할 때까지 이 프로세스를 유예합니다.
만일 시그널의 동작이 종료하는 것이라면, 해당 프로세스는 sigsuspend로부터 리턴하지 않고 종료합니다.
만일 동작이 핸들러를 돌리는 것이라면, sigsuspend는 핸들러가 리턴한 후에 리턴해서 블록된 집합을 sigsuspend가 호출되었을 때의 상태로 복원합니다.
8.6 비지역성 점프
C는
비지역성 점프라고 부르는 사용자 수준의 예외적 제어흐름을 제공하며, 이는 보통의 콜-리턴 순서를 통할 필요 없이 하나의 함수에서 현재 실행하고 있는 다른 함수로 제어를 이동합니다.
비지역성 점프는setjmp와longjmp함수로 제공됩니다.
비지역성 점프는 심하게 중첩된 함수 콜에서, 대개 어떤 에러 조건을 검출한 결과를 즉시 리턴으로 허용하는 경우에 활용 가능합니다. 예를 들어 만일 에러 조건이 중첩된 함수 호출의 깊은 곳에서 발견되면, 콜 스택을 거꾸로 돌아가는 대신 공통의 지역적인 에러 핸들러로 직접 리턴하기 위해 비지역성 점프를 사용할 수 있습니다.
또다른 활용은 시그널의 도착으로 중단되었던 인스트럭션으로 돌아가는 대신 특정 코드 위치로 시그널 핸들러를 벗어나서 분기하는 경우입니다.
8.7 프로세스 조작을 위한 도구
리눅스 시스템을 프로세스를 관찰하여 조작하기 위한 여러 가지 유용한 도구를 제공합니다.
STRACE. 돌고 있는 프로그램과 호출한 각 시스템 콜의 경로를 인쇄합니다. 프로그램을 -static으로 컴파일하면 공유 라이브러리에 관한 많은 출력 없이 좀 더 깔끔한 경로를 얻을 수 있습니다.PS. 현재 시스템 내의 프로세스들(좀비 포함)을 출력합니다.TOP. 현재 프로세스의 자원 사용에 관한 정보를 출력합니다.PMAP. 프로세스의 메모리 맵을 보여줍니다./proc. 여러가지 커널 자료구조의 내용을 사용자 프로그램이 읽을 수 있는 ASCII 문자 현태로 내보내는 가상파일 시스템입니다.
8.8 요약
예외적 제어흐름 ECF는 컴퓨터 시스템의 모든 수준에서 일어나며, 컴퓨터 시스템에 동시성을 제공하는 기본적 메커니즘입니다.
예외는 프로세서에서 이벤트로 유발되는 갑작스런 제어의 변화로 나타납니다.제어흐름은 소프트웨어 핸들러로 이동하며, 이것은 약간의 처리를 수행한 후에 제어를 중단된 제어흐름으로 돌려줍니다.
컴퓨터에는 네 종류의 예외상황이 존재합니다.
인터럽트. 타이머 칩이나 디스크 컨트롤러가 프로세서 칩 상의 인터럽트 핀(PIN)을 설정할 때 비동기적으로 발생합니다.오류와 중단. 인스트럭션 실행의 결과로 동기적으로 발생합니다. 오류 핸들러는 오류 인스트럭션을 재시작하며, 중단 핸들러는 제어를 중단된 흐름으로 절대 리턴하지 않습니다.트랩. 응용프로그램에게 운영체제 시스템 코드 내부로 제어된 엔트리 포인트를 제공하는 시스템 콜을 구현하는 데 사용됩니다.
OS에서 커널은 ECF를 사용해 프로세스의 근본적인 개념을 제공합니다. 프로세스는 응용 프로그램에 두 개의 추상화(착각이 들게끔하는)을 제공합니다.
운영체제와 응용 사이의 인터페이스에서 응용은 자신을 만들고, 자식들이 정지하는 것 또는 종료된 것을 기다리고, 새 프로그램을 실행하고, 다른 프로세스가 보낸 시그널을 잡습니다.
이러한 시그널 핸들러의 의미는 시스템마다 다를 수 있습니다.
마지막으로 응용수준에서 C 프로그램은 정상적인 콜/리턴 스택 방식과 분기를 통과해서 하나의 함수에서 다른 함수로 직접 분기하기 위해 비지역성 점프를 사용할 수 있습니다.
