
Data Structure
자료 구조는 프로그램에서 사용하기 위한 자료를 기억장치의 공간 내에 저장하는 방법과 저장된 그룹 내에 존재하는 자료 간의 관계, 처리 방법 등을 연구 분석하는 것을 말한다.
- Linear Structure(선형 구조) : Array(배열), Linear List(선형 리스트) - (연속 리스트, 연결 리스트), Stack(스택), Queue(큐), Deque(데크)
- Non-Linear Structure(비선형 구조) : Tree(트리), Graph(그래프)
Linear List
- Contiguous List(연속 리스트) : 배열을 이용
- Linked List(연결 리스트) : 포인터를 이용
Stack
스택은 리스트의 한쪽 끝으로만 자료의 삽입, 삭제 작업이 이루어지는 자료구조이다.
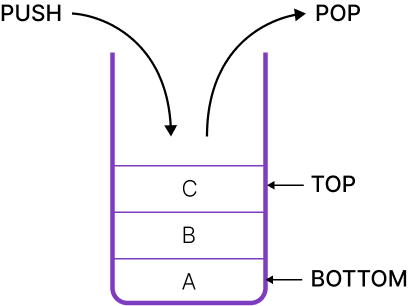
- 가장 나중에 삽입된 자료가 가장 먼제 삭제되는 LIFO(Last In First Out, 후입선출) 방식으로 자료를 처리
- 저장할 기억 공간이 없는 상태에서 데이타가 삽입되면 오버플로우overflow)가 발생
- 더 이상 삭제할 데이터가 없는 상태에서 데이터를 삭제하면 언더플로우(underflow)가 발생
Queue
큐는 리스트의 한쪽에서는 삽입 작업이 이루어지고 다른 한쪽에서는 삭제 잡업이 이루어지는 자료구조이다.

- FIFO(First In First Out, 선입선출) 방식으로 처리
- 시작을 표시하는 프론트 포인터(Front Pointer)와 끝을 표시하는 리어 포인터(Rear Pointer)가 있음
Graph
- 방향 그래프의 최대 간선 수 : n(n-1)
- 무방향 그래프의 최대 간선 수 : n(n-1)/2
*n은 정접의 개수

위의 무방향 그래프의 최대 간선 수 : 5 × (5-1) / 2 = 10
Tree
트리는 노드(Node, 정점)와 가지(Branch, 선분)를 이용하여 사이클을 이루지 않도록 구성한 그래프의 특수한 형태이다.

- Node : 트리의 기본 요소로서 자료 항모과 다른 항목에 대한 가지(Branch)를 합친 것
- Degree : 차수로, 각 노드에서 뻗어나온 가지의 수
ex)A=3 - Leaf Node = Terminal Node : 자식이 하나도 없는 노드, 즉 Degree가 0인 노드
ex)E, F, G, I, J - Level : 근 노드의 Level을 1로 가정한 수 어떤 Level이 L이면 자식 노드는 L+1
- Depth, Height : Tree에서 노드가 가질 수 있는 최대의 레벨
ex)4 - Forest : 여러 개의 트리가 모여 있는 것
ex) 근 노드 A를 제거하면 B, D를 근 노드로 하는 두 개의 트리가 있는 숲이 생김 - 트리의 차수 : 노드들의 디그리 중에서 가장 많은 수
ex) 노드 A나 B가 세 개의 차수를 가지므로 위 트리의 차수는 3
Preorder 운행법 : Root → Left → Right
Inodrer 운행법 : Left → Root → Right
Postorder 운행법 : Left → Right → Root
Sort
Insertion Sort(삽입 정렬)
삽입 정렬은 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방식이다.
- 시간 복잡도 O(n의 2제곱)
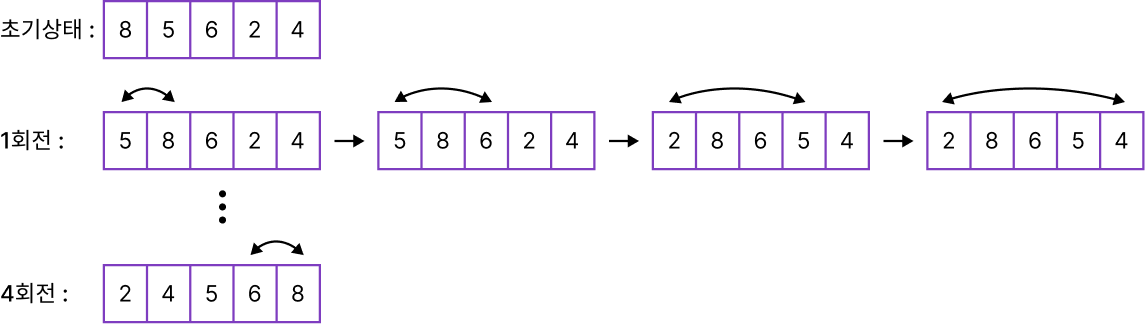
초기 : 8,5,6,2,4
1회전 : 8,5,6,2,4 → 5,8,6,2,4
2회전 : 5,8,6,2,4 → 5,6,8,2,4
3회전 : 5,6,8,2,4 → 2,5,6,8,4 // 넷 번째 값 '2'를 처음부터 비교하여 맨 처음에 삽입하고 나머지는 한 칸씩 뒤로 이동
4회전 : 2,5,6,8,4 → 2,4,5,6,8 // 다섯 번째 값 '4'를 처음부터 비교하여 숫자'5'자리에 삽입하고 나머지를 한 칸씩 뒤로 이동Selection Sort(선택 정렬)
선택 정렬은 n개의 레고드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식이다.
- 시간 복잡도 O(n의 2제곱)
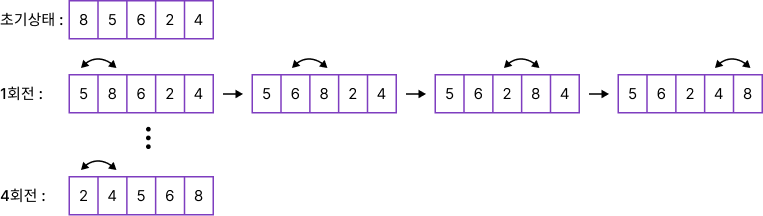
Bubble Sort(버블 정렬)
버블 정렬은 인접한 두개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식이다.
- 시간 복잡도 O(n의 2제곱)
Quick Sort(퀵 정렬)
퀵 정렬은 키를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 서브 파일에 분해시키는 과정을 반복하는 정렬 방식이다.
- 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬
- 평균 수행 시간 복잡도 O(nlog2n), 최악의 수행 시간 복잡도 O(n의 2제곱)

Heap Sort(힙 정렬)
힙 정렬은 정렬할 입력 레코드들로 힙을 구성하고 가장 큰 키 값을 갖는 루크 노드를 제거하는 과정을 반복하는 정렬 방식이다.
- 구성된 Complete Binary Tree(전이진 트리)를 Heap Tree로 변환하여 정렬
- 시간 복잡도 O(nlog2n)
- 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법으로,
내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 됨
2-Way Merge Sort(2-Way 합병 정렬)
2-Way 합병 정렬은 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식이다.
- 시간 복잡도 O(nlog2n)
참고,
길벗알앤디. 『정보처리기사 실기 단기완성』. 길벗. 2023.
quick sort : https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
heap sort : https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
