https://arxiv.org/pdf/2307.14331.pdf
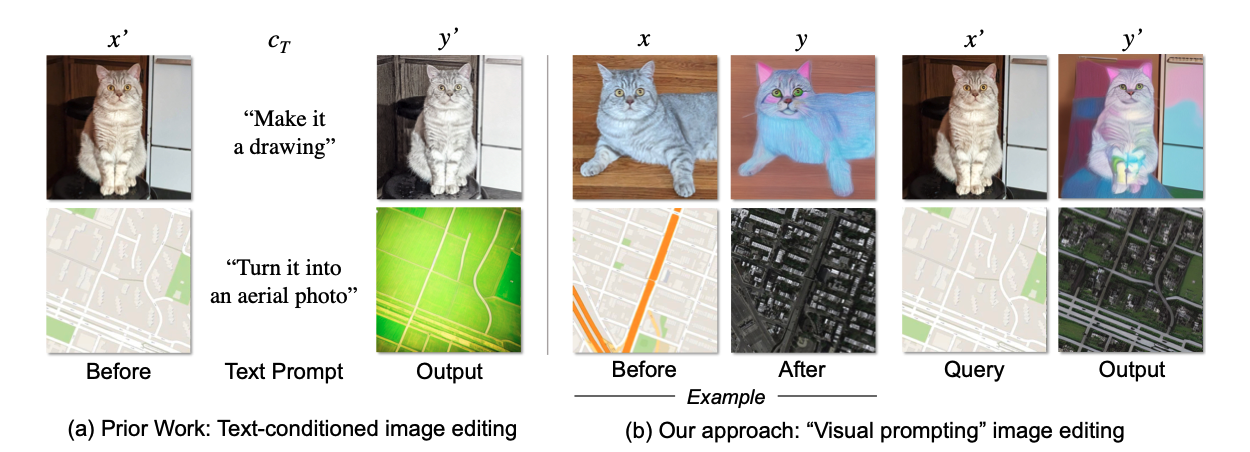
이 논문은 일반적으로 diffusion generation과정에서 text를 condition으로 주는 과정의 언어의 모호함과 비효율성이 있음을 지적하며 구체적인 이미지를 통한 prompting 방법을 제안합니다. (근데 결국 image를 direct하게 prompting을 하는것은 아닌 것 같고 text condition이 image의 차이를 학습해서 text condition하는 것 같음)
좀 더 구체적으로 논문에서는 InstructPix2Pix가 배운 textual instruction space를 사용한다고 합니다(pre-trained).
여기서 InstructPix2Pix는 pre-trained된 Stable Diffusion model의 생성능력(edit 능력도 포함(?))을 형성하는 작업으로, (text instruction, before image, after image) triplet으로 구성된 450,000개의 데이터를 fine-tuning하는 작업을 통해 형성
- 제가 직관적으로 이해했을 때는, 원래 Stable Diffusion이 가지는 생성능력을 ImageToImage fine-tuning을 통해, 이미지 두개가 주어졌을 때 그 둘을 이어주는(prompting의 형태로) prompt (c_T) 능력을 학습하겠다는 의미로 이해했습니다.
구체적으로 다음과 같은 방법으로 InstructPix2Pix가 fine-tuning을 진행
[image editing을 위한 학습방법론으로 이해 (image x를 y형태로 edit하기 위한 방법)]
- input image를 denoising network에 추가
- Input image x를 encoding 시킨 cI를 denoising 과정에서 latent image z{y_t}와 concatenate함
- 이를 통해 text prompt c_T와 editing process에 jointly guiding을 진행
위 아이디어를 기반으로 text-to-image diffusion model을 supervised way로 fine-tuning,
objective function에서 noisy version of y를 denoise하는 objective로 변경함으로써 x -> y 에 대한 image-to-image translation 능력 획득.

이 과정에서 저자들은 InstructionPix2Pix의 instruction space가 여러 image-to-image translation에 대한 능력을 가질 것이라고 주장.
최종적으로 논문에서 제안하는 framework는 다음과 같습니다.
논문의 최종 목적은 {x, y}라는 befor image(x)와 after image(y) pair가 주어졌을 때, text기반의 c_T가 x->y로의 editing direction을 잘 알려주길 바랄 것입니다. c_T를 이미지로 어떻게 잘 만들어 낼 것인지가 관건
- Instruction Optimization을 진행
a. InstructionPix2Pix와 마찬가지로 reconstruct image loss를 사용해서 c_T를 잘 형성 - Editing Direction
a. CLIP이 좋은 editing direction에 대한 indicator로 작용할 수 있음
b. cosine distance를 통해 {x,y}의 CLIP embedding간 차이(x, y의 edit 정보)와 c_T를 가까워 지도록 학습 - Inference
a. 잘 형성된 c_T를 InstructPix2Pix에 사용함으로써, Test Image를 Image를 통한 Prompting을 진행

Visual Prompting이라 해서, image 정보를 직접적으로 diffusion model에 conditioning하는 전략을 사용하는 논문으로 생각하고 읽어봤는데, 실제로는 visual정보를 학습한 text condition을 사용해 주는 방법이였습니다.
어제 공유드린 논문에서도 그렇고 text class token에 가깝게 image embedding을 형성시키는 전략을 사용했는데, visual embedding을 직접적으로 생성에 사용하는 방법이 상당히 어려운 작업이라 그런가 이런 방식을 많이 사용하는 것 같네요.
