Redis의 메모리 오버헤드에 대해서 (1)
MEMORY STATS 의 결과 중, dbXXX 메트릭에는 main과 expires 해시 테이블의 오버헤드가 계산되어 표시된다. 과연 오버헤드 메트릭은 어떻게 계산이 될까?
물론, 키스페이스(dbXXX)이외의 오버헤드 또한 계산이 되며,
overhead.total항목에 합산이 되어 표기된다.
- startup.allocated
- replication.backlog
- clients.slaves
- clients.normal
- aof.buffer
주요 구조체
오버헤드를 이해하기에 앞서, 우선은 주요 구조체에 알아볼 필요가 있다.
redisDb
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;레디스의 database. 논리적인 데이터 공간. redis.conf의 databases 변수에 의해 공간의 개수를 정할 수 있는데, 기본값은 16이다.
dict
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;해시테이블을 보유하는 구조체. 기본적으로 키를 관리하기 위해 사용되나, ttl이 지정된 키, blocking key등등 다양한 종류의 키를 관리하는데 사용된다.
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;dictht: 해시테이블로 버킷을 관리한다. 각각의 버킷은 dictEntry와 연결된다.
dictEntry
// 24 bytes
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 공용체
struct dictEntry *next;
} dictEntry;키와 값의 포인터를 저장하며, 버킷에 연결된 dictEntry는 싱글 링크드 리스트로 연결된다.
robj
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
// #define LRU_BITS 24값(value)을 저장하기 위한 구조체. 참고로 클라이언트로부터 전달받아 아직 가공되기 이전의 문자열도 robj로 표현된다.
sds
struct sdshdr {
long len;
long free;
char buf[];
};바이너리 문자열을 처리하기 위해 고안된 구조체. Simple Dynamic Strings
참고: https://github.com/antirez/sds
키스페이스(redisDb)내의 오버헤드 계산
이전 섹션에서 언급한 구조체들을 아래의 그림과 같이 사용된다. 서두에 언급한 것처럼 오버헤드란 키/값을 저장하고 관리하는 해시테이블을 유지하는데 필요한 메모리이며, 순수하게 키/값을 저장하는 공간은 이 계산에서 제외된다.
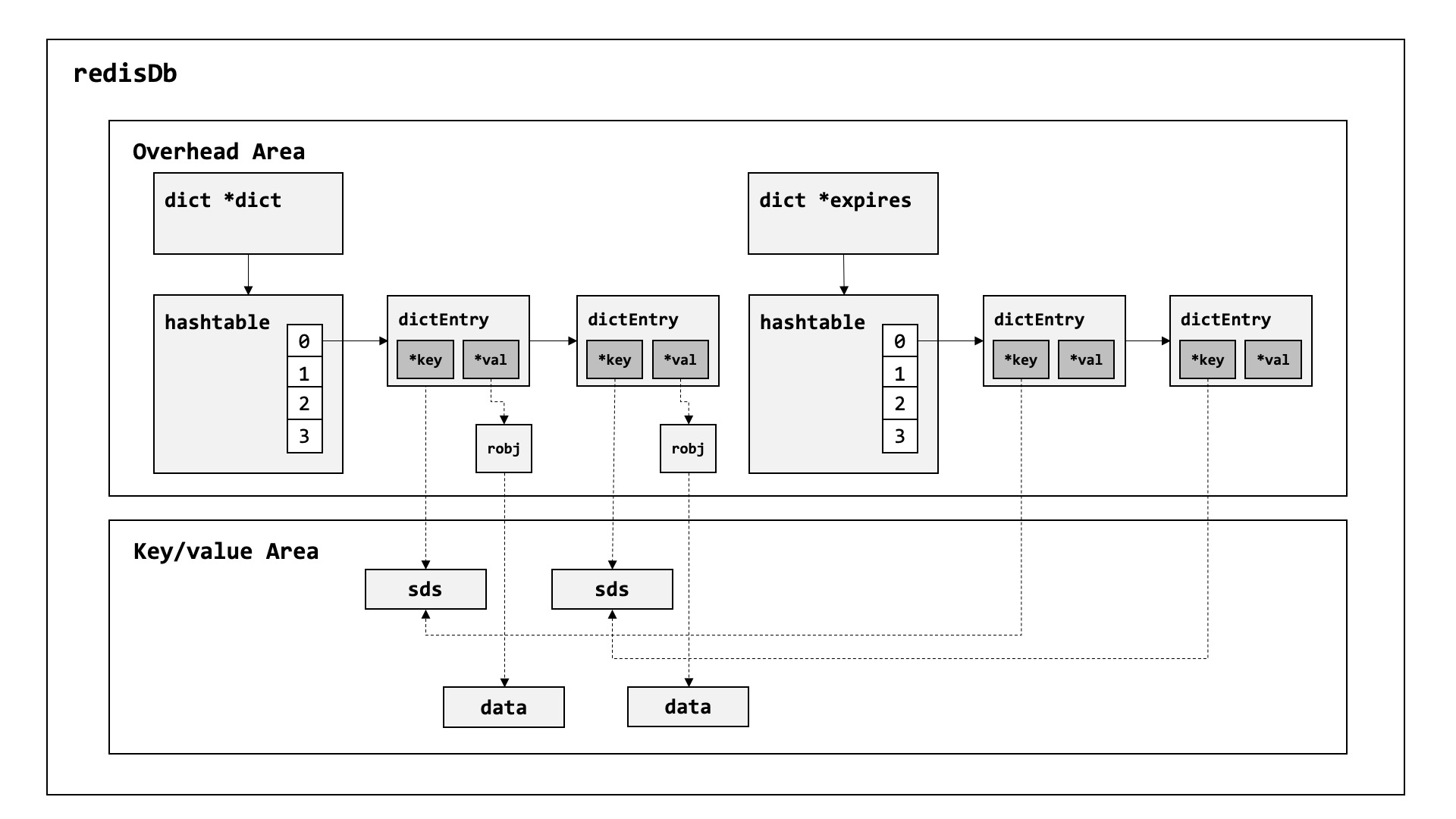
/*
* #define dictSlots(d) ((d)->ht[0].size+(d)->ht[1].size)
* #define dictSize(d) ((d)->ht[0].used+(d)->ht[1].used)
*/
mem = dictSize(db->dict) * sizeof(dictEntry) +
dictSlots(db->dict) * sizeof(dictEntry*) +
dictSize(db->dict) * sizeof(robj);
mh->db[mh->num_dbs].overhead_ht_main = mem;
mem_total+=mem;
mem = dictSize(db->expires) * sizeof(dictEntry) +
dictSlots(db->expires) * sizeof(dictEntry*);
mh->db[mh->num_dbs].overhead_ht_expires = mem;
mem_total+=mem;소스 코드 내의 (키스페이스의) 오버헤드 계산식은 메인 해시테이블과 만료 시간을 관리하는 해시 테이블로 나눠 계산되며, 각각의 세부 내용은 아래와 같다.
overhead_ht_main
- 다음의 각 항목을 계산 후, 합한 값이 오버헤드의 값이 된다.
- [해시테이블의 used (실제 키의 수)] x [dictEntry의 사이즈, 24바이트]
- [해시테이블의 used (실제 키의 수)] x [robj의 사이즈, 16바이트]
- [해시테이블의 size (버킷<또는 슬롯>의 수)] x [dictEntry의 포인터, 8바이트]
overhead_ht_expires
- 다음의 각 항목을 계산 후, 합한 값이 오버헤드의 값이 된다.
- [해시테이블의 used (ttl 설정된 키의 수)] x [dictEntry의 사이즈, 24바이트]
- [해시테이블의 size (버킷<또는 슬롯>의 수)] x [dictEntry의 포인터, 16바이트]
overhead_ht_main와 overhead_ht_expires의 계산에는 2가지 차이가 있다. 먼저 value를 관리하는 robj에 대한 계산인데, expires는 결국 만료된 키를 삭제하기 위해 관리되는 것으로, 굳이 값을 따로 관리할 필요는 그리고 두번째로 키와 슬롯(버킷)의 수가 다른데, expires에는 만료 시간(ttl) 이 설정되지 않는 키는 관리되지 않기 때문이다.
결론
위와 같이, 오버헤드 계산식을 통해서 다음과 같은 2가지 사실을 알 수가 있다.
- 오버헤드는 키/값의 길이 또는 크기와는 상관없이 오직 키의 개수에 의해서만 영향을 받는다.
- 만료 시간이 설정되는 키는 expires 해시테이블에 별도로 관리되므로, 이 역시 오버헤드를 증가시킨다.
Appendix: MEMORY USAGE 가 메모리를 계산하는 방법
MEMORY USAGE 는 데이터 타입별, 인코딩별로 값(value)의 크기를 계산하고, 키의 길이를 또한 계산한다. 그리고 이러한 키/값을 관리하는 dictEntry자체의 크기도 합산하여 계산한다.
- objectComputeSize: 인코딩별 값(value)의 크기 계산
- 키의 데이터 타입, 인코딩에 따라서 용량을 계산한다.
- 가량 string의 경우에는
- OBJ_ENCODING_INT: robj 크기를 그대로 반환
- OBJ_ENCODING_RAW: robj->ptr의 영역의 크기와 robj 크기를 더한 값을 반환
- OBJ_ENCODING_EMBSTR: robj->ptr이 가리키는 문자열의 크기와 robj 크기를 더한 값을 반환
- sdsAllocSize: 키의 길이 계산
- 키의 길이에 대한 메모리 할당량을 반환
- sizeof(dictEntry): 키/값을 관리하는 dictEntry
- 키/값을 저장하는 dictEntry의 크기를 반환
그런데 오버헤드의 계산에는 역시 dictEntry의 계산이 포함되므로, MEMORY USAGE의 결과를 이용해서 메모리 사용량을 직접 계산할 때(주로 데모/개발간에 생성된 키/값, 그리고 예상되는 키의 개수를 통해서 레디스의 메모리 사용량을 미리 예측하고자 하는 경우 등)에는 dictEntry가 중복되어 계산이 될 수도 있음에 주의해야 한다. 그리고 MEMORY USAGE에는 SAMPLES라는 옵션이 존재하는데,해시나 정렬된 셋(Sorted set)처럼 엘리먼트를 가지는 데이터 타입에 대해서 SAMPLES에 지정된 수 (기본값은 5)만큼의 엘리먼트를 검사하여 평균값을 도출하고, 엘리먼트의 수만큼 곱하여 대략적인 메모리 사용량을 계산한다. 만약 엘리먼트의 수가 매우 많을 때에는 모든 엘리먼트를 순회하면서 메모리를 계산하는 것은 매우 시간이 많이 걸리는 일이 될 것이고, 상황에 따라서는 다른 명령의 처리까지 지연시켜버릴 수 있기 때문에, 정확도는 다소 희생하더라도 계산 비용을 줄이게 위해서 SAMPLES를 이용해서 계산하는 것이다. 정확한 메모리 계산이 필요하다면 SAMPLES를 0으로 지정하여, 강제로 모든 엘리먼트를 순회하며 계산하게 할 수도 있다.
