비선형 자료구조 - 트리, 그래프
비선형 자료구조에 대한 정리를 이 블로그에 담았다.
먼저 비선형 자료 구조가 무엇일까
비선형 자료 구조, 데이터가 일렬로 나열되어 있지 않고 계층적이거나 여러 갈래로 복잡하게 연결된 구조
트리
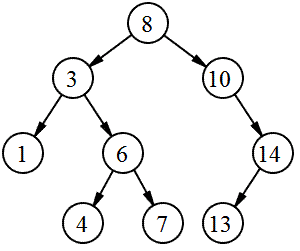
트리란, 하나의 최상위 노드에서 시작해 가지처럼 여러 하위 노드로 뻗어 나가는 순환이 없는 비선형 계층적 자료구조이다
하나의 요소가 여러요소와 연결될 수 있음, 최상위 루트노드가 있고 부모 자식관계가 형성되며 레벨이 나누어짐, 한 노드에서 출발하여 이동했을때 자기 자신에게로 되돌아갈 수 없음 (되돌아갈 수 있다면 그건 그래프)
용어 정리
링크: 노드들을 연결하는 선
노드
: 트리의 기본 구성 요소로, 데이터를 저장하는 단위
- 루트 노드: 트리의 꼭대기에 위치하는 최상위 노드로 부모노드가 없는 노드
- 단말 노드: 자식이 없는 노드 (말단 노드)
- 부모 노드: 자식 노드를 가진 노드
- 자식 노드: 부모 노드를 가진 노드
- 형제 노드: 같은 부모를 가진 노드
이진 트리
: 각각의 노드가 최대 두개의 자식 노드를 가지는 트리
-> 단순하고 효율적 등 여러 장점이 있기에 지금부터 이진트리를 기준으로 얘기하도록 함
- 완전 이진 트리: 왼쪽 자식 노드 부터 순서대로 노드가 채워져 있는 트리
- 포화 이진 트리: 모든 레벨의 노드가 꽉 채워져 있는 트리
- 편향 이진 트리: 최소 개수의 노드 개수를 가지며 왼쪽 혹은 오른 쪽의 서브 트리만을 가진 트리
그리고
- 노드의 깊이: 루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수
- 노드의 레벨: 루트 노드로부터 떨어진 거리
- 노드의 높이: 어떤 노드에서 단말 노드까지 가장 긴 경로의 간선 수
- 노드의 차수: 하위 트리의 개수
순회
탐색 전략에 따라 크게 2가지로 구분
1. DFS:깊이 우선 탐색 (스택)
갈 수 있는 최대 깊이까지 간 후 되돌아가며, 루트 노드를 언제 처리하냐에 따라 이름이 구분됨
-
전위: 루트 -> 왼쪽 서브 트리 -> 오른쪽 서브 트리
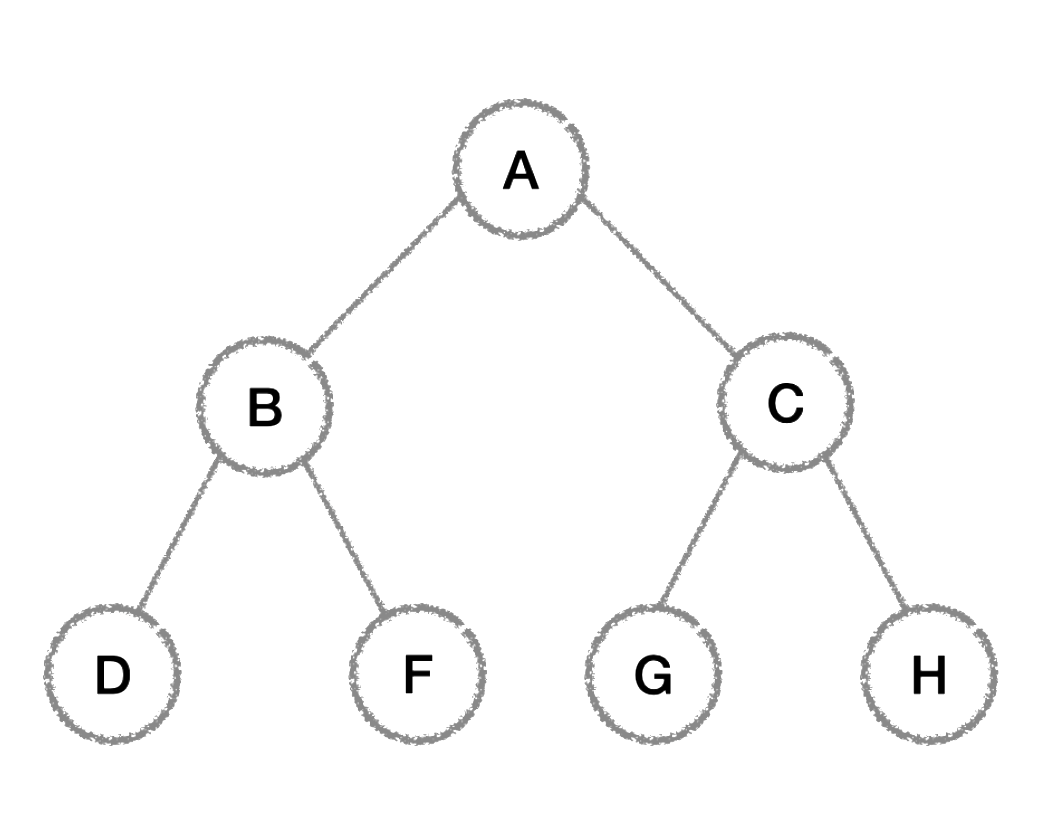
루트를 가장 먼저 방문하기 때문에 트리의 구조를 출력하거나 복제할 때 유용하게 사용- 위 그림에서 전위 순회 결과: A, B, D, F, C, G, H
void pre_order(Node* node) { if (node != NULL) { printf("%d ", node->value); pre_order(node->left); pre_order(node->right); } } -
중위: 왼쪽 서브 트리 -> 루트 -> 오른쪽 서브 트리
이진 탐색 트리에서 중요한 역할을 하며, 노드들을 순서대로 출력하거나 오름차순 정렬할 때 사용- 위 그림에서 중위 순회 결과: D, B, F, A, G, C, H
void in_order(Node* node) { if (node != NULL) { in_order(node->left); printf("%d ", node->value); in_order(node->right); } } -
후위: 왼쪽 서브 트리 -> 오른쪽 서브 트리 -> 루트
자식 노드를 먼저 모두 처리한 후 부모 노드를 처리할 때 사용, 삭제나 메모리 해제와 같은 작업- 위 그림에서 중위 순회 결과: D, F, B, G, H, C, A
void post_order(Node* node) { if (node != NULL) { post_order(node->left); post_order(node->right); printf("%d ", node->value); } }
2. BFS:너비 우선 탐색 (큐)
레벨 순회와 동일한 방식으로, 한 레벨에 있는 노드를 모두 방문한 후 다음 레벨로 내려가 탐색을 계속하는 방식
최단 경로 탐색과 같은 문제 해결에 적합하다
루트 -> 다음 레벨의 노드를 왼쪽에서 오른쪽으로 방문 -> 모든 레벨에 반복
- 위 그림에서 레벨 순회 결과: A, B, C, D, F, G, H
void level_order(Node* root) {
// 루트가 NULL이면 탐색할 트리가 없으므로 종료
if (root == NULL) {
return;
}
// 레벨 순회를 위한 큐 생성
Queue* q = create_queue();
// 첫 번째로 루트 노드를 큐에 삽입
enqueue(q, root);
// 큐가 빌 때까지 반복 → 모든 노드를 순서대로 방문
while (!is_empty(q)) {
// 큐에서 가장 먼저 들어온 노드를 꺼낸다(FIFO)
Node* current = dequeue(q);
// 현재 노드의 값 출력
printf("%d ", current->value);
// 현재 노드의 왼쪽 자식이 존재하면 큐에 삽입
if (current->left != NULL) {
enqueue(q, current->left);
}
// 오른쪽 자식이 존재하면 큐에 삽입
if (current->right != NULL) {
enqueue(q, current->right);
}
}
// 큐 사용이 끝났으므로 메모리 해제
// (큐 내부에서 동적할당한 배열/노드가 있다면 별도 해제가 필요할 수 있음)
free(q);
}
트리의 루트노드를 큐에 넣으며 시작 -> 큐가 빌 때까지 큐의 맨앞 노드를 꺼내 방문처리, 꺼낸 노드에게 자식 노드가 있다면 왼쪽 자식부터 순서대로 큐의 맨뒤에 넣는다 -> 큐가 비면 탐색 완료
- 큐의 선입 선출 방식
노드 개수, 높이 구하기
1. 노드 개수 구하기
트리안의 노드의 개수를 계산, 각각의 서브트리에 대하여 순환 호출한 다음 반환되는 값에 1을 더해 반환한다
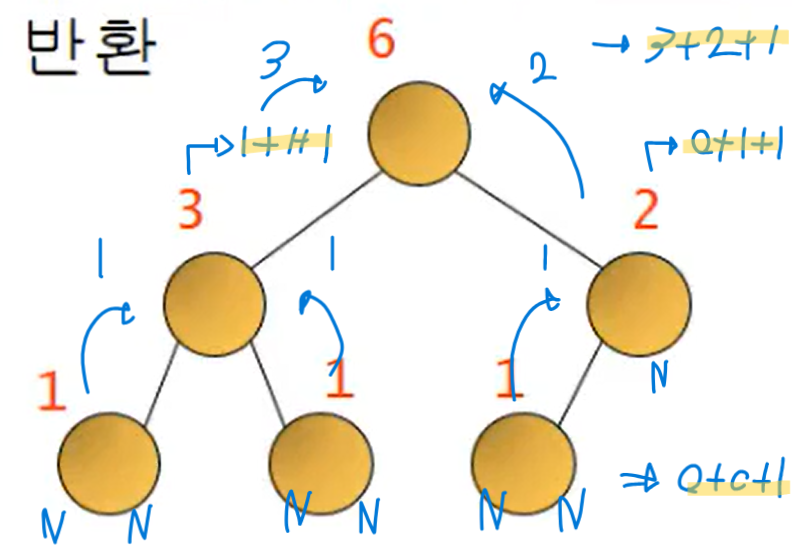
- 노드가 NULL이면, 0을 반환
- 노드가 NULL이 아니면, 현재 노드 + 왼쪽 서브트리의 노드 개수 + 오른쪽 서브트리의 노드 개수를 반환
int get_node_count(TreeNode*node)
{
int count = 0;
if(node != NULL)
count = 1 + get_node_count(node->left) + get_node_count(node->right);
return count;
}2. 높이 구하기
서브 트리에 대하여 순환호출하고 서브 트리들의 반환값 중에서 최대값을 구하여 반환
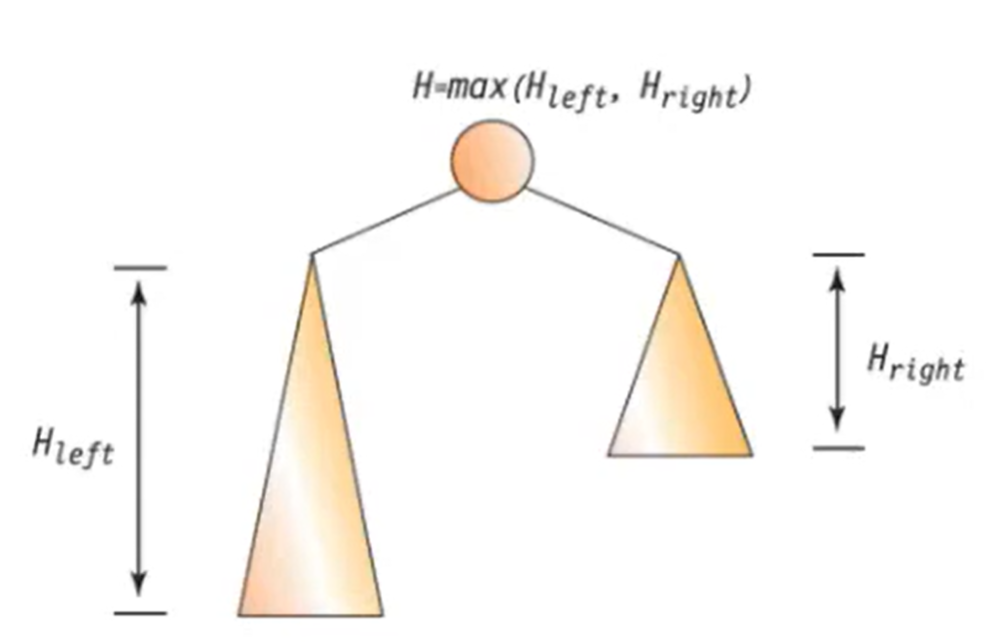
- 노드가 NULL이면 0을 반환
- NULL이 아니라면, 왼쪽 서브트리와 오른쪽 서브트리의 높이를 비교하여 큰값 + 1 (현재 노드)을 반환
int get_height(TreeNode*node)
{
int height = 0;
if(node != NULL)
height = 1 + max(get_height(node->left), get_height(node->right));
return height;
}탐색, 삽입, 삭제, 성능 분석
이진 탐색 트리 (BST)
: 각 노드마다 왼쪽 자식 노드는 부모 노드보다 작고, 오른쪽 자식 노드는 부모 노드보다 큰 값을 가지는 속성을 가짐
왼쪽 서브트리 key <= 루트 노드 key <= 오른쪽 서브트리 key
또한 탐색 작업 시간이 단축된다는 장점이 있음
1. 탐색 연산
특정한 키 값을 가진 노드가 트리 내에 존재하는 지 찾는 연산
- 특정한 키 값보다 작으면 왼쪽 서브 트리
- 크면 오른쪽 서브 트리
- 같으면 현위치 값 반환하여 트리 내에 존재 확인
- NULL이면 찾는 값이 트리에 존재하지 않음
2. 삽입 연산
특정한 값을 노드에 삽입하는 연산
- 먼저 탐색연산 수행
- 새로운 노드 값이 현재 노드 값보다 작으면 왼쪽으로
- 크면 오른쪽으로 이동
- NULL이면 삽입 연산을 수행
3. 삭제 연산
특정 노드를 삭제하는 연산으로, 트리의 BST속성을 유지해야하므로 총 3가지 상황으로 나뉜다
- 삭제할 노드가 단말 노드인 경우
그냥 단말노드를 삭제하면 됨 - 삭제할 노드의 자식이 하나 있는 경우
노드를 삭제하고 자식 노드를 삭제된 부모 노드 위치에 연결 - 삭제할 노드의 자식이 둘인 경우
먼저 오른쪽 서브트리의 최솟값을 찾는 과정이 필요함
그후 오른쪽 서브트리의 최솟값을 가지는 노드를 삭제할 노드의 위치에 연결
코드
// 탐색 (Search)
Node* search(Node* root, int key) {
// 노드가 없거나 값이 일치하면 해당 노드를 반환
if (root == NULL || root->value == key) {
return root;
}
// 찾는 값이 더 작으면 왼쪽 서브트리에서 탐색
if (key < root->value) {
return search(root->left, key);
}
// 더 크면 오른쪽 서브트리에서 탐색
return search(root->right, key);
}
// 삽입 (Insert)
Node* insert(Node* root, int key) {
// 비어 있는 위치에 도달하면 새 노드를 생성하여 삽입
if (root == NULL) {
return create_node(key);
}
// key가 작으면 왼쪽에 삽입
if (key < root->value) {
root->left = insert(root->left, key);
}
// key가 크면 오른쪽에 삽입
else if (key > root->value) {
root->right = insert(root->right, key);
}
// 같으면 아무 것도 하지 않음 (BST는 중복 허용X가 일반적)
return root; // 루트 반환
}
// 삭제 (Delete)
// 오른쪽 서브트리에서 가장 작은 값을 가진 노드 찾기 (후계자 찾기)
Node* find_min(Node* node) {
Node* current = node;
// 가장 왼쪽 끝이 가장 작은 값
while (current && current->left != NULL) {
current = current->left;
}
return current;
}
Node* delete_node(Node* root, int key) {
if (root == NULL) {
return root; // 삭제할 노드가 없음
}
// 1) 삭제할 노드를 탐색
if (key < root->value) {
root->left = delete_node(root->left, key);
}
else if (key > root->value) {
root->right = delete_node(root->right, key);
}
// 2) 삭제할 노드를 찾았을 때
else {
// (1) 자식이 없거나 하나만 있는 경우
if (root->left == NULL) {
Node* temp = root->right; // 오른쪽 자식(있을 수도, NULL일 수도)
free(root); // 현재 노드 삭제
return temp; // 자식(혹은 NULL) 반환
}
else if (root->right == NULL) {
Node* temp = root->left; // 왼쪽 자식
free(root);
return temp;
}
// (2) 자식이 둘 다 있는 경우
// 오른쪽 서브트리에서 가장 작은 값을 찾음 (중위 후속자)
Node* temp = find_min(root->right);
// 현재 노드 값을 후속자의 값으로 교체
root->value = temp->value;
// 후속자 값을 실제로 삭제
root->right = delete_node(root->right, temp->value);
}
return root;
}4. 성능 분석
탐색 속도가 BST의 성능과 같다
이는 삽입, 삭제 연산을 할 때에도 탐색과정이 필요하기 때문이다
연산의 시간 복잡도: 트리높이(h) + 1
NULL까지 확인하기 때문에 1더함
시간복잡도를 분석할 때 빅오 표기법을 사용, 연산횟수에 가장 지배적인 요소만을 남기고 삽입과 삭제의 시간복잡도는 아래와 같다
삽입 시간복잡도: O(h)
삭제 시간복잡도: O(h)
- 최선의 경우: 균형 잡힌 트리
- 최악의 경우: 편향된 트리
-> 이를 방지하기 위해 AVL 트리(:자가 균형 이진 탐색 트리, 높이의 균형을 유지함) 사용
그래프
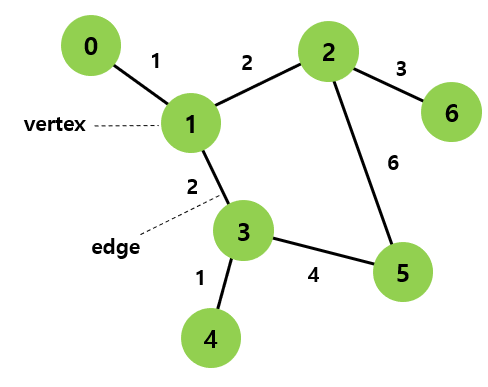
그래프란, 연결되어있는 객체간의 관계를 나타낸 구조이며 정점과 간선으로 이루어짐
그래프 구조를 배울 때 알아야하는 용어와 개념에 대해
용어 정리
정점: 여러가지 특성을 가질 수 있는 개체나 위치를 나타내는 점으로 식별이 가능하다 (노드)
- V (그래프) = {정점의 집합}: 예시 V(G) = {A, B, C, D}
- 인접 정점: 두 정점이 간선으로 연결되어 있다면 두 정점은 인접하다
간선: 정점들 사이의 관계를 나타내는 선 (링크)
-
E (그래프) = {간선의 집합}:
-
무방향: 예시 E(G) = {(A, B), (B, C), (C, A)}
- 방향이 없는 그래프이다
- ( ) 소괄호로 묶어 표현한다
- (A, B)와 (B, A)는 같은 간선이다
-
방향: 예시 E(G) = {<A, C>, <B, A>, <C, D>, <D, B>}
- 방향이 있는 그래프이다
- <> 꺽쇠로 묶어 표현한다
- <A, B>와 <B, A>는 다른 간선이다
그래프 표현 방법
1. 인접행렬 (이중 배열로 구현)
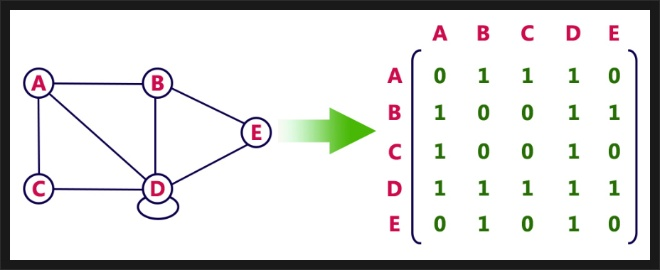
인접행렬은 두 정점의 간선의 유무를 이중 배열에 저장한다
인접되어 있으면 1로, 인접되어 있지 않으면 0으로 표현한다
n개의 정점을 가진 그래프를 n x n으로 나타낸다
무방향
양쪽 방향으로 연결되어 있어 A-B가 연결이면, B-A도 연결되어야 함
그래서 무방향 그래프에서는 행렬이 대칭이 된다
(edge[a][b] == edge[b][a])
ex) 정점의 개수: 3
edge[0][1] = 1;
edge[1][0] = 1;
edge[1][2] = 1;
edge[2][1] = 1;
//출력결과
//[0, 1, 0]
//[1, 0, 1]
//[0, 1, 0]방향
한쪽 방향으로만 연결되어 있어 A->B는 연결이지만, B->A는 아닐 수 있음
ex) 정점의 개수: 3
edge[0][1] = 1;
edge[1][2] = 1;
//출력결과
//[0, 1, 0]
//[0, 0, 1]
//[0, 0, 0]구현이 간단하고 연결여부를 빠르게 확인 가능하다는 장점이 있지만, n x n만큼의 메모리를 차지하여 노드 개수가 많을수록 메모리가 낭비된다
2. 인접리스트 (포인터 배열로 구현)
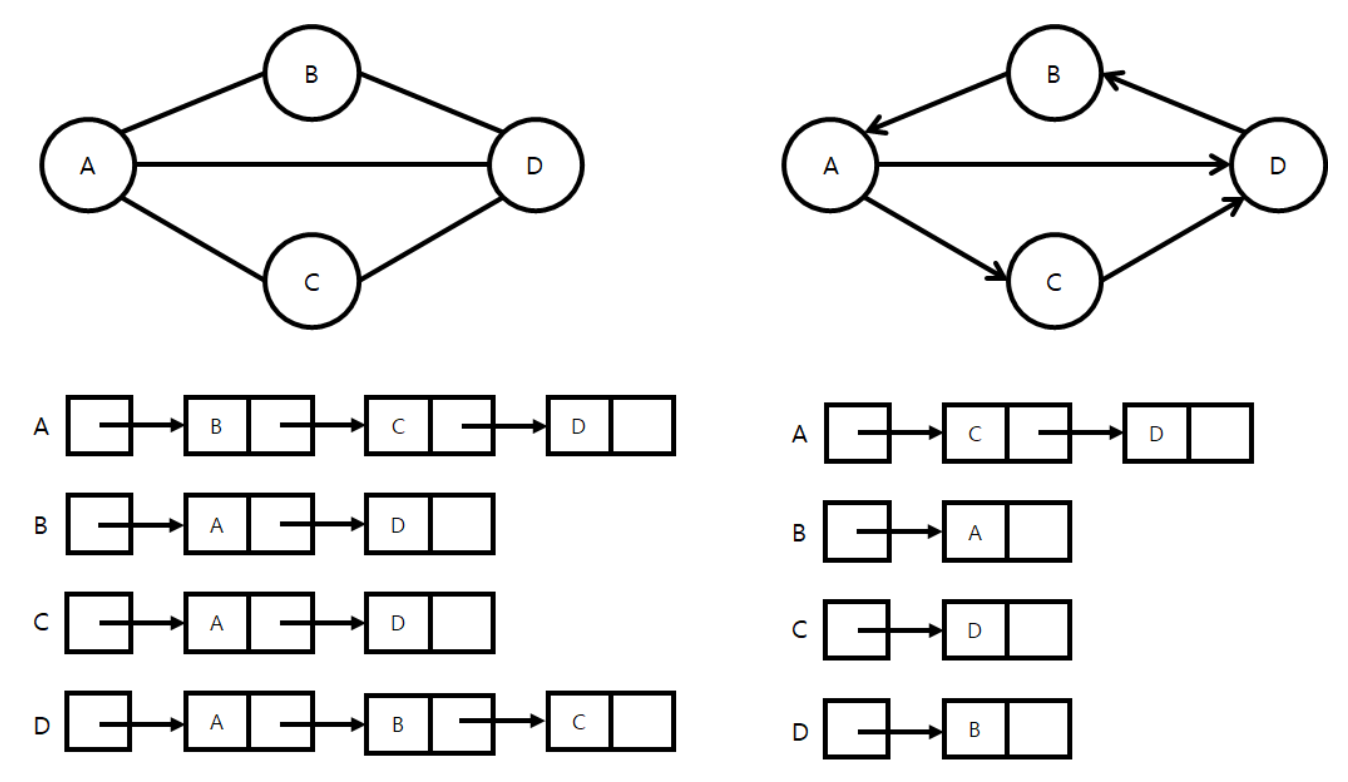
인접리스트는 두 정점을 연결한 간선의 유무를 연결리스트에 저장한다
즉 누구랑 연결되어 있는지만 따로 저장해둔 형태이다
정점의 개수가 총 n개라면, n개의 연결리스트가 있게 된다
구조체를 계속 만들어서 동적할당하므로 구조체의 개수에 따라 메모리가 늘어난다
무방향
각 간선을 두 정점 모두의 리스트에 저장하여 양쪽 방향의 연결을 표현하는 그래프이다
간선이 양방향으로 존재하므로 특정 노드에 연결된 이웃 노드를을 각 정점의 인접리스트에 모두 추가한다
방향
간선을 출발 노드에만 저장한다
정점 A에서 B로 가는 방향 간선이 있다면 A의 인접 리스트에만 B를 추가함
필요한 간선만 저장하여 메모리 사용과 특정 정점에 연결된 모든 정점을 찾을 때 효율적이며 시간복잡도 측면에서 좋다는 장점이 있다. 특정 정점이 연결되어 있는지 확인하려면 리스트 전체를 탐색하므로 연결 여부 확인 속도가 느리다
그래프 순회 / 탐색
하나의 정점에서 시작하여 중복없이 차례대로 모든 정점을 한번씩 방문하는 과정이다
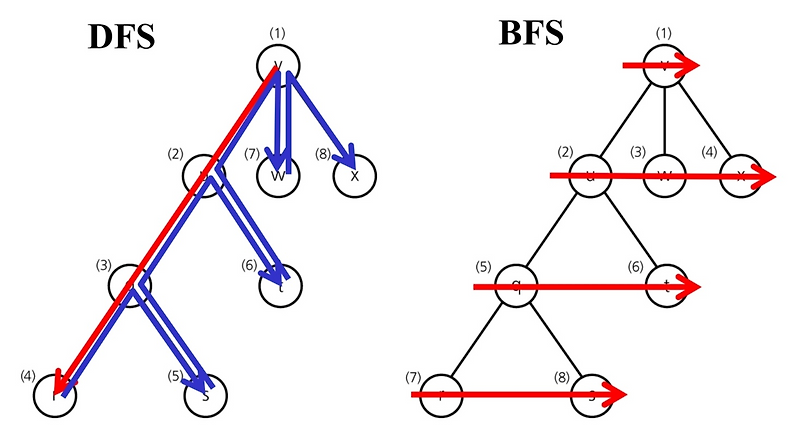
1. DFS (Depth First Search:깊이 우선 탐색)
한 방향으로 갈 수 있을 때까지 가다가 더이상 갈 수 없게 되면 가장 가까운 길로 되돌아감
가장 최근에 넣었던 정점을 꺼내어 그 정점의 다른 이웃을 탐색하기 위해 스택을 사용
- 수직적인 탐색(최대한 아래로 갚숙히 내려가면서 탐색을 진행)
- 한 서브트리나 경로가 완전히 탐색되기 전까지는 다른 서브트리로 넘어가지 않음
void dfs(Graph* graph, int start_node, int visited[]) {
// 1. 현재 노드를 방문 처리하고 출력
visited[start_node] = 1;
printf("%d ", start_node);
// 2. 현재 노드의 인접 리스트 순회
Node* current = graph->adj_list[start_node];
while (current != NULL) {
int neighbor = current->to;
// 3. 인접 노드가 아직 방문되지 않았다면 재귀 호출
if (!visited[neighbor]) {
dfs(graph, neighbor, visited);
}
current = current->next;
}
}2. BFS (Breadth First Search:너비 우선 탐색)
시작 정점으로 부터 가까운 (최단 경로) 정점을 먼저 방문하고 멀리 떨어져있는 정점을 나중에 방문
방문 순서가 선착순이기에 큐를 사용해서 구현됨 + 반복문
- 수평적인 탐색(같은 레벨을 먼저 탐색한 후 거리가 멀어지는 정점들로 넓혀감)
- 시작 정점에서 가까운 정점들을 먼저 방문한다
특징
- 이동거리가 같은 애들은 붙어서 출력
- 특정 정점기준 뒤로는 이동거리가 크거나 같다
ex) A(루트) BC(이동거리 1) DEF(이동거리 2)
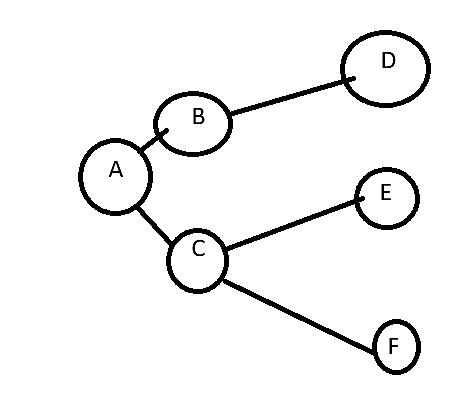
void bfs(Graph* graph, int start_node, int visited[]) {
// 1. 큐 초기화 및 시작 노드 삽입
Queue* q = create_queue();
visited[start_node] = 1;
enqueue(q, start_node);
// 2. 큐가 빌 때까지 반복
while (!is_empty(q)) {
// 3. 큐에서 노드를 꺼내고 출력
int current_node = dequeue(q);
printf("%d ", current_node);
// 4. 현재 노드의 인접 리스트 순회
Node* current = graph->adj_list[current_node];
while (current != NULL) {
int neighbor = current->to;
// 5. 인접 노드가 아직 방문되지 않았다면 방문 처리 후 큐에 삽입
if (!visited[neighbor]) {
visited[neighbor] = 1;
enqueue(q, neighbor);
}
current = current->next;
}
}
// 큐 메모리 해제