- 파이썬에서 리스트의 결과를 특정 조건에 따라 원소별로 변환하거나, 필터를 사용해 원하는 값을 뽑아내고, 연산하는 방법으로 함수 map, filter, reduce를 사용한다.
1. 람다 표현식에 조건부 표현식 사용하기
먼저 람다 표현식에서 조건부 표현식을 사용하는 방법이다.
- lambda 매개변수들 : 식1 if 조건식 else 식2
- 삼항연산자 : 조건식이 true일 때는 식1 을 false일 때는 식2를 탄다.
- 파이썬에서는 실질적인 삼항연산자가 없고 위의 방식으로 사용한다. 자바스크립트에서 ? 와 같은 연산자가 없다!
다음은 map을 사용하여 리스트 a에서 3의 배수를 문자열로 반환한다.
>>> a = [1,2,3,4,5,6,7,8,9,10]
>>> list(map(lambda x : str(x) if x % 3 ==0 else x,a))
[1,2,'3',4,5,'6',7,8,'9',10]map은 리스트의 요소를 각각 처리하므로 lambda의 반환값도 요소이다. 여기서는 요소가 3의 배수일떄는 str(x)로 요소를 문자열로 만들어서 반환했고, 3의 배수가 아닐 떄는 x로 요소를 숫자로 반환했다.
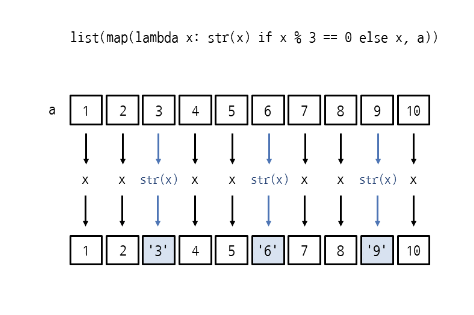
람다 표현식 안에서 조건부 표현식 if, else를 사용할 때는 :(콜론)을 붙이지 않는다. 일반적인 if, else 문법과 다르므로 주의해야한다. 조건부 표현식은 식1 if 조건식 else 식2 형식으로 사용하며 식1은 조건식이 참일 때, 식2는 조건식이 거짓일 때 사용한다.
특히 람다 표현식에서 if를 사용했다면 반드시 else를 사용해야한다. 다음과 같이 if만 사용하면 문법 에러가 발생하므로 주의해야한다!
>>> list(map(lambda x:str(x) if x % 3 ==0, a))
SyntaxError : invaild syntax그리고 람다 표현식 안에서는 elif를 사용할 수 없다!
따라서 조건부 표현식은 식1 if 조건식1 else 식2 if 조건식2 else 식3 형식처럼 if를 연속적으로 사용해야한다.
예를 들어 리스트에서 1은 문자열로 변환하고, 2는 실수로 변환하고, 3이상은 10을 더하는 식은 다음과 같다.
>>> a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(map(lambda x: str(x) if x === 1 else float(x) if x == 2 else x + 10,a))
['1', 2.0, 13, 14, 15, 16, 17, 18, 19, 20]별로 복잡하지 않은 조건인데도, 알아보기가 힘들다. 이런 경우에는 억지로 람다 표현식을 사용하기 보다는 def 함수로 만들기 if, elif, else로 사용하는것을 권장한다.
>>> def f(x):
... if x == 1:
... return str(x)
... elif x == 2:
... return float(x)
... else:
... return x + 10
...
>>> a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(map(f, a))
['1', 2.0, 13, 14, 15, 16, 17, 18, 19, 20]2. map에 객체를 여러 개 넣기
map은 리스트 등의 반복 가능한 객체를 여러 개 넣을 수도 있다. 다음은 두 리스트의 요소를 곱해서 새 리스트를 만든다.
>>> a = [1,2,3,4,5]
>>> b = [2,4,6,8,10]
>>> list(map(lambda x,y : x * y, a,b))
[2,8,18,32,50]이렇게 리스트 두 개를 처리할 때는 람다 표현식에서 lambda x,y : x*y 처럼 매개변수를 두 개로 지정하면 된다. 그리고 map에 람다 표현식을 넣고 그 다음에 리스트 두 개를 콤마로 구분해서 넣어준다. 즉, 람다 표현식의 매개변수 개수에 맞게 반복 가능한 객체도 콤마로 구분해서 넣우주면 된다.
- x에는 a의 리스트의 요소가 한개씩 들어간다.
- y에는 b의 리스트의 요소가 한개씩 들어간다.
2.1 그러면 만약에 리스트 요소의 길이가 다르면??
- 갑자기 궁금해서 돌려봤다.
>>> a = [1, 2, 3, 4, 5,]
>>> b = [2, 4, 6, 8, 10,0]
>>> print(list(map(lambda x, y: x * y, a, b)))
[2,8,18,32,50]- 그냥 길이가 맞는 것 까지 나온다..ㅎㅎ 아마 더하기나 조건에 따라서 출력이 될것이고, 에러가 나는지 안나는지가 궁금했다.
3. fliter 사용하기
이번에는 fliter를 사용해보자. fliter는 반복 가능한 객체에서 특정 조건에 맞는 요소만 가져온다. filter에 지정한 함수의 반환값이 True일 때만 해당 요소를 가져온다.
- filter(함수, 반복가능한 객체(iterable))
먼저 def로 함수를 만들어서 filter를 사용해보자.
리스트에서 5보다 크면서 10보다 작은 숫자를 가져오자.
>>> def f(x):
return x> 5 and x <10
>>> a = [8, 3, 2, 10, 15, 7, 1, 9, 0, 11]
>>> list(filter(f,a))
[8,7,9]리스트 a에서 8, 7, 9를 가져왔다. 즉, filter는 x > 5 and x < 10의 결과가 참인 요소만 가져오고 거짓인 요소는 버린다.
- filter 의 첫번째 매개변수에서 함수명만 가져오고 함수의 매개변수나, ()는 함께 적지 않는다.
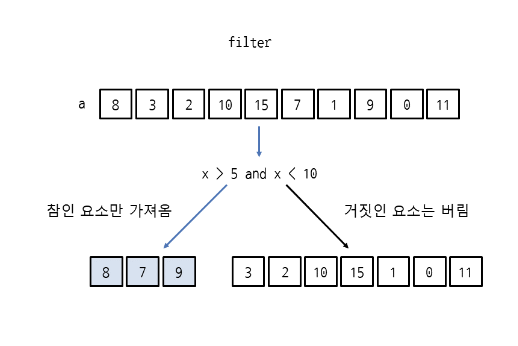
그럼 함수 f를 람다 표현식으로 만들어서 filter에 넣어보자.
>>> a = [8, 3, 2, 10, 15, 7, 1, 9, 0, 11]
>>> list(filter(lambda x : x> 5 and x <10, a))람다 표현식 lambda x: x > 5 and x < 10을 filter에 넣어서 5보다 크면서 10보다 작은 수를 가져오도록 만들었다.
4. reduce 사용하기
reduce는 반복 가능한 객체의 각 요소를 지정된 함수로 처리한 뒤 이전 결과 와 누적해서 반환하는 함수이다.(reduce는 파이썬 3부터 내장 함수가 아니다!!)
따라서 functools 모듈에서 reduce를 가져와야 한다.
- from functools import reduce
- reduce(함수,반복가능한 객체(iterable))
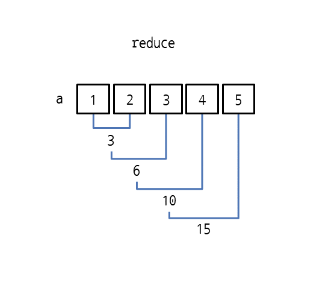
다음은 리스트에 저장된 요소를 순서대로 더한 뒤 누적된 결과를 반환한다.
>>> def f(x,y):
return x+y
>>> a = [1,2,3,4,5]
>>> from functools import reduce
>>> reduce(f,a)
15reduce의 반환값 15가 나왔다. 함수 f에서 x+y를 반환하도록 만들었다. reduce는 그림과 같이 요소 두개를 계속 더하면서 결과를 누적한다.
이번에는 함수 f를 람다 표현식으로 만들어서 reduce에 넣어보자.
>>> a =[1,2,3,4,5]
>>> from functools import reduce
>>> reduce(lambda x,y : x+y,a)
15이 부분이 조금 잘 이해가 안되는데, 천천히 생각하고 이해하자
4.1 다른 예제
>>> users = [
... {'mail': 'gregorythomas@gmail.com', 'name': 'Brett Holland', 'sex': 'M', 'age': 73},
... {'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'sex': 'F', 'age': 29},
... {'mail': 'wwagner@gmail.com', 'name': 'Michael Jenkins', 'sex': 'M', 'age': 51},
... {'mail': 'daniel79@gmail.com', 'name': 'Karen Rodriguez', 'sex': 'F', 'age': 32},
... {'mail': 'ujackson@gmail.com', 'name': 'Amber Rhodes', 'sex': 'F', 'age': 42}
]
>>> reduce(lambda acc, cur: acc + cur["age"], users, 0)
2274.2 나이 누적합 구하기
누작자에 초기값 0이 세팅되고, 그 다음 각 유저의 나이가 집계 함수에 의해서 계속해서 더해지게 된다.
- 직접 따라가 보자!
>>> 0
0
>>> 0 + 73
73
>>> 73 + 29
102
>>> 102 + 51
153
>>> 153 + 32
185
>>> 185 + 42
2274.3 이메일 목록 구하기
유저 이메일 목록도 reduce() 함수를 이용하면 어렵지 않게 만들어 낼 수 있다.
>>> reduce(lambda acc, cur: acc + [cur["mail"]], users, [])
['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com', 'daniel79@gmail.com', 'ujackson@gmail.com']- 직접 따라가 보자!
>>> []
[]
>>> [] + ['gregorythomas@gmail.com']
['gregorythomas@gmail.com']
>>> ['gregorythomas@gmail.com'] + ['hintoncynthia@hotmail.com']
['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com']
>>> ['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com'] + ['wwagner@gmail.com']
['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com']
>>> ['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com'] + ['daniel79@gmail.com']
['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com', 'daniel79@gmail.com']
>>> ['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com', 'daniel79@gmail.com'] + ['ujackson@gmail.com']
['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com', 'daniel79@gmail.com', 'ujackson@gmail.com']4.4 성별로 분류 하기
reduce() 함수는 데이터 그룹핑(data grouping)과 같이 좀 더 복잡한 누적 집계에도 활용될 수 있다.
예를 들어, 유저 이름을 성별에 따라 분류해보도록 하자. 람다 함수를 사용하기에는 다소 복잡한 케이스이므로, names_by_sex()라는 함수를 하나 선언하도록 한다.
>>> def names_by_sex(acc, cur):
... sex = cur["sex"]
... if sex not in acc:
... acc[sex] = []
... acc[sex].append(cur["name"])
... return acc
...
reduce() 함수에 names_by_sex 함수를 인자로 넘기면, 성별을 키로 이름 list를 값으로 갖는 dictionary를 얻게 된다.
>>> reduce(names_by_sex, users, {})
{'M': ['Brett Holland', 'Michael Jenkins'], 'F': ['Madison Martinez', 'Karen Rodriguez', 'Amber Rhodes']}굳이 람다 함수를 통해서 동일한 작업을 하고 싶은 분들은 아래 코드를 참고바라겠습니다. 가독성이 현저히 떨어지기 때문에 상용으로는 사용하기 어려운 코드일 것 같습니다.
>>> reduce(lambda acc, cur: {**acc, cur["sex"]: (acc[cur["sex"]] if cur["sex"] in acc else []) + [cur["name"]]}, users, {})
{'M': ['Brett Holland', 'Michael Jenkins'], 'F': ['Madison Martinez', 'Karen Rodriguez', 'Amber R**acc 뭐냐 이건,,ㅎㅎ
--> https://brunch.co.kr/@princox/180
4.5 초기값의 중요성
reduce() 함수를 사용할 때 많은 분들이 실수하는 부분이 있는데 바로 초기값 세팅 유무에 따라 이상한 결과가 나올 수 있는 것이다.
예를 들어, 유저의 나이 합계를 구하는 예제에서 초기값으로 0을 넘겨주지 않으면 TypeError가 발생한다.
>>> reduce(lambda acc, cur: acc + cur["age"], users)
Traceback (most recent call last):
File "<input>", line 1, in <module>
reduce(lambda acc, cur: acc + cur["age"], users)
File "<input>", line 1, in <lambda>
reduce(lambda acc, cur: acc + cur["age"], users)
TypeError: unsupported operand type(s) for +: 'dict' and 'int'다른 예로, 유저 이름을 성별에 따라 분류하는 예제에서 초기값으로 빈 dictionary을 넘겨주지 않으면 다음과 같이 예상치못한 결과가 나온다.
>>> reduce(names_by_sex, users)
{'mail': 'gregorythomas@gmail.com', 'name': 'Brett Holland', 'sex': 'M', 'age': 73, 'F': [{'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'sex': 'F', 'age': 29}, {
'mail': 'daniel79@gmail.com', 'name': 'Karen Rodriguez', 'sex': 'F', 'age': 32}, {'mail': 'ujackson@gmail.com', 'name': 'Amber Rhodes', 'sex': 'F', 'age': 42}, {'mail': 'hintoncynth
ia@hotmail.com', 'name': 'Madison Martinez', 'sex': 'F', 'age': 29}, {'mail': 'daniel79@gmail.com', 'name': 'Karen Rodriguez', 'sex': 'F', 'age': 32}, {'mail': 'ujackson@gmail.com',
'name': 'Amber Rhodes', 'sex': 'F', 'age': 42}, {'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'sex': 'F', 'age': 29}, {'mail': 'daniel79@gmail.com', 'name': 'Ka
ren Rodriguez', 'sex': 'F', 'age': 32}, {'mail': 'ujackson@gmail.com', 'name': 'Amber Rhodes', 'sex': 'F', 'age': 42}, 'Madison Martinez', 'Karen Rodriguez', 'Amber Rhodes'], 'M': [
{'mail': 'wwagner@gmail.com', 'name': 'Michael Jenkins', 'sex': 'M', 'age': 51}, {'mail': 'wwagner@gmail.com', 'name': 'Michael Jenkins', 'sex': 'M', 'age': 51}, {'mail': 'wwagner@g
mail.com', 'name': 'Michael Jenkins', 'sex': 'M', 'age': 51}, 'Michael Jenkins']}