
OCR, 즉 Optical Character Recognition(광학 문자 인식)은 이미지나 PDF 파일 속의 글자를 텍스트 데이터로 변환해주는 기술입니다. 이번 시간에 문서 관리, 데이터 입력 자동화 등 다양한 분야에서 널리 사용되는 이 기술에 대해 알아보고 배우며 활용할 수 있는 능력을 길러봅시다.
OCR(Optical Character Recognition) ?
사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것이다.
이미지 스캔으로 얻을 수 있는 문서의 활자 영상을 컴퓨터가 편집 가능한 문자 코드 등의 형식으로 변환하는 소프트웨어로써 일반적으로 OCR이라고 하면, OCR은 인공지능이나 기계 시각(machine vision)의 연구 분야로 시작되었다.
출처:
https://ko.wikipedia.org/wiki/%EA%B4%91%ED%95%99_%EB%AC%B8%EC%9E%90_%EC%9D%B8%EC%8B%9D
역사와 발전
-
초기 OCR 기술: 초기의 OCR 시스템은 고정된 글꼴과 제한된 문자 집합을 인식하는데 사용 됨
- 예시: 은행의 수표 처리 시스템
-
현대 OCR 기술: 머신 러닝과 딥러닝의 발전으로 다양한 글꼴, 손글씨, 여러 언어를 인식할 수 있는 범용 OCR 시스템이 개발
작동 원리
1. 이미지 전처리 (Image Preprocessing)
- 설명: 이미지를 OCR에 사용하기 전에, 이미지를 더 잘 인식할 수 있도록 개선하는 과정. 이 과정에는 이미지의 노이즈 제거, 이진화(흑백 변환), 기울기 보정 등 포함
- 예시:
- 노이즈 제거: 스캔한 문서에 잉크 범짐이 있는 경우, 이를
- 이진화: 컬러 문서나 그레이스 케일 문서를 흑백으로 변환. 예를 들어, 흰 종이에 검은 글씨로 된 문서를 처리할 때, 배경을 흰색으로, 글씨를 검은색으로 변환하여 인식
2. 문자 분할 (Segmentation)
-
설명: 이미지에서 개별 문자를 분리하는 단계. 단어를 문자 단위로, 문장을 단어 단위로 분리 함. 이 단계는 문서 레이아웃 분석과 관련 있음
-
예시:
- 단어 분할: 문장에서 공백을 기준으로 단어를 분리
- 문자 분할: 단어를 개별 문자로 분리함. 예를 들어, "Nice"라는 단어를 'N', 'i', 'c', 'e'로 분리
3. 특징 추출 (Feautre Extension)
-
설명: 각 문자 이미지에서 특징을 추출하는 단계. 이러한 특징은 문자 인식을 위한 입력으로 사용 됨. 특징은 가장자리, 선, 곡선 등으로 구성
-
예시:
- 가장자리 검출: 각 문자의 윤곽선을 검출
- 곡선과 직선 추출: 'S'와 같은 곡선 문자와 'L'과 같은 직선 문자를 구분할 수 있도록 특징을 추출
4. 문자 인식 (Recognition)
- 설명: 추출된 특징을 바탕으로 각 문자를 인식하는 단계. 이 단계에서는 머신 러닝 알고리즘이나 딥러닝 모델이 사용 됨
- 딥러닝 모델: CNN(Convolutional Neural Networks)이나 RNN(Recurrent Neural Networks)을 사용하여 문자를 인식
5. 후처리 (Post-Processing)
- 설명: 인식된 문자 데이터를 검증하고 수정하는 단계. 문맥을 바탕으로 오류를 수정하거나, 문법적 일관성을 확인
- 예시:
- 스펠링 교정: 인식된 텍스트에서 철자가 틀린 단어를 사전 데이터를 이용해 수정
- 문백 분석: 문장 내에서 문맥에 맞지 않는 단어를 교정 함. 예를 들어 "I lvoe programming"을 "I love programming"으로 수정 함
간단한 실습
[실습 환경 구축]
1. 가상 환경 구축 (Anaconda)
-
구축 이유?
프로젝트별로 독립적인 파이썬 환경을 만들어 패키지 종속성 문제를 방지하고, 시스템 파이썬 환경에 영향을 주지 않으며, 이를 통해 협업과 코드 재현 가능성을 높여 안정적인 개발 환경을 제공하기 위해 아나콘다를 설치합니다. -
아나콘다 다운 받기
링크: https://www.anaconda.com/download -
Anaconda Prompt 실행
- 명령어 입력:
# conda create -n '본인이 희망하는 가상환경 이름' python='원하는 버전' conda create -n ocr_env python=3.7
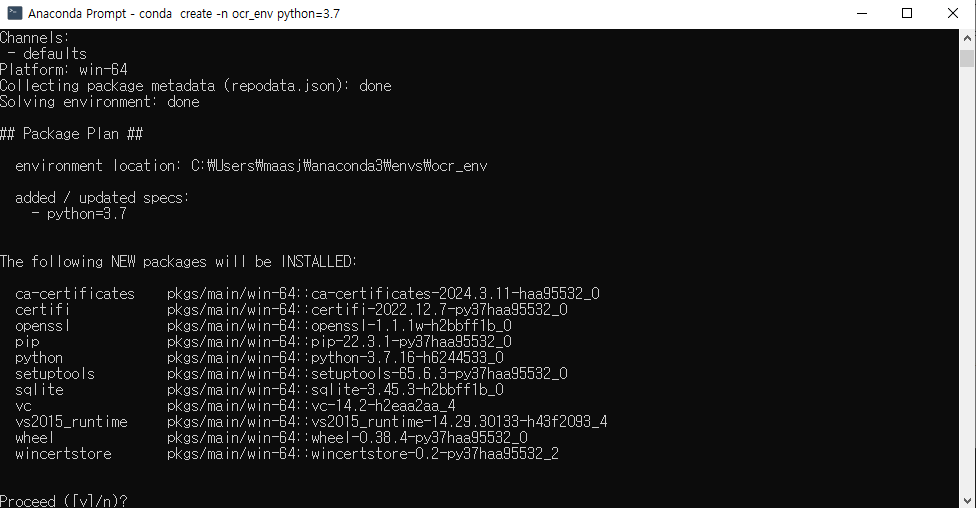
- 아래 화면이 등장하면, y 입력
-
가상환경 세팅 확인
-
명령어 입력:
conda info --envs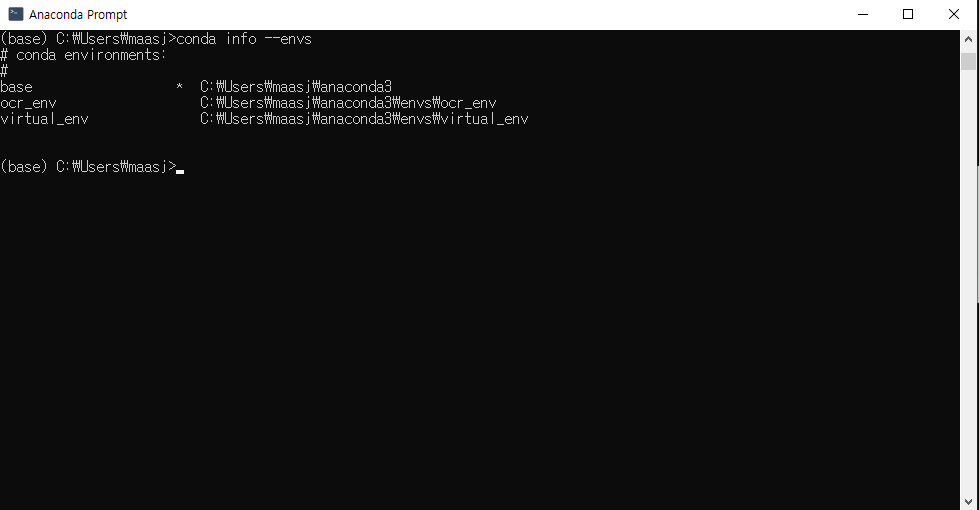
ocr_env라는 가상환경이 잘 구축된 것을 확인할 수 있다.
-
2. 가상환경에 필요한 패키지 설치
- 가상환경 활성화
- 명령어 입력:
# activate '시작하고 싶은 가상환경 이름' activate ocr_env
- 명령어 입력:
- 필요한 패키지 설치
가상환경이 활성화된 상태에서 OCR 관련 패키지를 설치- 명령어 입력:
# OCR 패키지 설치 conda install -c conda-forge pytesseract conda install -c conda-forge pillow
- 명령어 입력:
3. pytesseract 라이브러리 초읽기
pytesseract 라이브러리는 Tesseract OCR 엔진을 Python에서 사용할 수 있게 해주는 인터페이스입니다. 지금부터 pytesseract의 주요 함수들과 다양한 사용 방법에 대해 정리하겠습니다.
[주요 함수]
3.1 이미지에서 텍스트를 추출
pytesseract.image_to_string
- 예시:
# 텍스트 추출 text = pytesseract.image_to_string(image, lang='eng')- image: 이미지 파일 또는 PIL.Image 객체
- lang: 사용할 언어. 기본값은 'eng' (영어)
3.2 이미지에서 문자 단위의 위치 정보를 추출
pytesseract.image_to_boxes
- 예시:
# 문자 단위 위치 정보 추출 boxes = pytesseract.image_to_boxes(image) print(boxes)- 각 문자의 위치 정보를 포함하는 문자열을 반환
3.3 이미지에서 텍스트와 위치 정보를 추출
pytesseract.image_to_boxes
- 예시:
# 텍스트와 위치 정보 추출 data = pytesseract.image_to_data(image, output_type=pytesseract.Output.DICT) print(data)- output_type: 출력 형식. Output.STRING, Output.DICT, Output.BYTES 중 선택
3.4 이미지의 방향과 스크립트 감지(OSD: Orientation and Script Detection) 정보를 추출
pytesseract.image_to_boxes
- 예시:
# 이미지 방향 및 스크립트 감지 osd = pytesseract.image_to_osd(image) print(osd)
3.5 이미지를 PDF 또는 hOCR 형식으로 변환
pytesseract.image_to_pdf_or_hocr
- 예시:
# 이미지 변환 pdf = pytesseract.image_to_pdf_or_hocr(image, extension='pdf') with open('output.pdf', 'wb') as f: f.write(pdf)- extension: 'pdf' 또는 'hocr' 중 선택
[기본 사용법 예시]
-
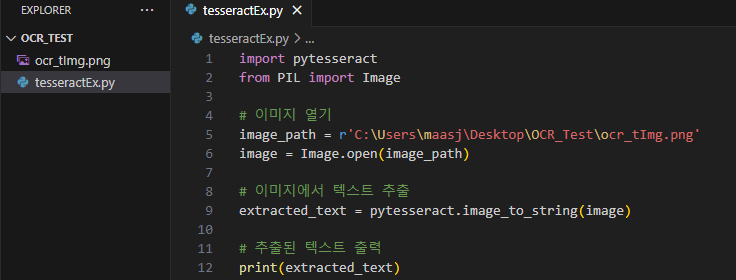
대표적인 이미지에서 텍스트 추출 코드
# 텍스트 추출 예시 import pytesseract from PIL import Image # 이미지 열기 image_path = 'path_to_image.png' image = Image.open(image_path) # 이미지에서 텍스트 추출 extracted_text = pytesseract.image_to_string(image) print(extracted_text)이 대표 코드를 활용해보도록 하겠습니다.
- 예제로 사용한 이미지 (명언 모음집)

- 사용 코드
- 아나콘다 가상환경에서 컴파일
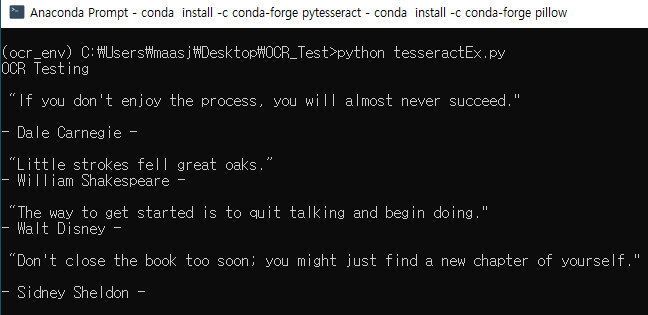
- 실행 결과
- 예제로 사용한 이미지 (명언 모음집)
마무리
OCR(Optical Character Recognition)은 이미지나 PDF 파일 속의 글자를 텍스트 데이터로 변환해주는 강력한 기술입니다.
이번 시간을 통해 OCR의 원리와 활용 방법을 배우면서 문서 관리, 데이터 입력 자동화 등 다양한 분야에서의 응용 가능성을 확인하셨을 것입니다.
앞으로 OCR 기술을 활용하여 더욱 효율적인 작업 환경을 만들어 나가봅시다 :)
