📌 Data Sampling
Data sampling을 진행하는 이유
만약 타겟 변수가 1,0이라고 해보자. 그런데 1의 값을 가지는 데이터는 10000개이고 0의 값을 가지는 데이터는 380개인 것이다. 이런 경우, 아무리 모델을 잘 만들어도 0의 값을 잘 도출하지 못할 것이다. 데이터 샘플링이 필요하다!
imbalanced data를 다루는 방법에는
1) 데이터를 더 수집
2) 평가 기준 변경 (e.g., F-beta, Kappa)
3) data sampling/augmentation
4) 모델 변경 (e.g. decision tree)
5) penalty 부여
샘플링은 다양한 방식으로 진행할 수 있음 (imbalanced-learn 패키지에서 다양한 함수들을 제공한다)
Undersampling/Downsampling
데이터가 많은 클래스를 적은 클래스의 수준으로 감소시켜서 imbalenced를 고치는 방법이다. 너무 많은 데이터를 제거할 경우 정보 손실이 발생할 수 있어 제대로 된 학습을 수행할 수 없을 수 있다.
-
Simple random sampling: 다수 범주에서 무작위로 샘플링을 진행
-
RandomUnderSampler: random under-sampling method
-
Stratified random sampling: 클래스 비율을 맞춰서 뽑음
-
Tomek Links: 두 범주 사이의 링크를 탐지하고 다수 범주에 속한 관측치 제거 > 다른 두 범주이면서 거리가 가까워서 그 사이에 아무도 없는 두 개 중에서 더 숫자가 많은 클래스인 변수를 제거한다.

-
CondensedNearestNeighbour: condensed nearest neighbour method
-
OneSidedSelection: under-sampling based on one-sided selection method
-
EditedNearestNeighbours: edited nearest neighbour method
-
NeighbourhoodCleaningRule: neighbourhood cleaning rule
Oversampling/Upsampling
반대로 소수 범주를 다수 범주의 개수만큼 늘리는 방법이다.
-
random oversampling: 소수 범주의 데이터가 무작위로 복제된다. 그러나 동일한 데이터를 여러 번 반복하는 경우 과적합 발생 확률 증가한다.
-
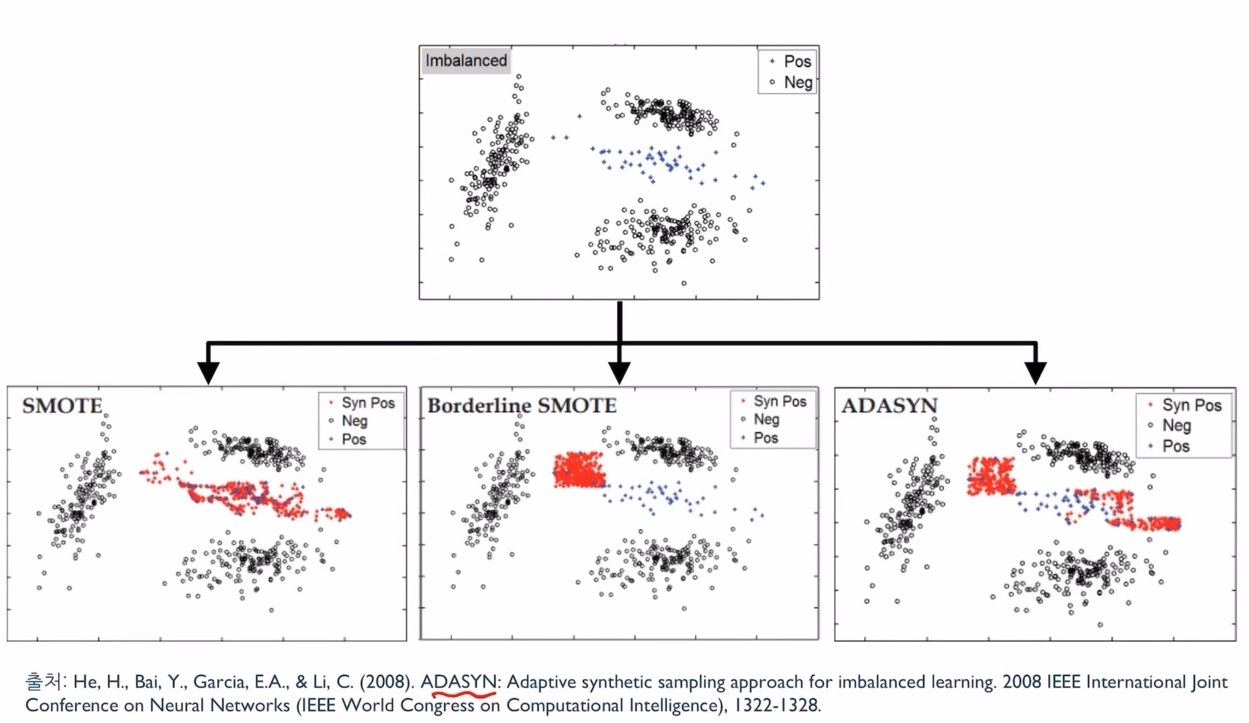
SMOTE(Synthetic Minority Over-sampling Technique): 소수 범주의 데이터를 활용하여 가상의 데이터를 생성한다.
※ 적은 데이터 세트에 있는 개별 데이터들의 K-nearest neighbor을 찾고, 해당 데이터와 k개 이웃들을 선분으로 이을 때 그 선분 위에 새로운 벡터를 생성한다.
4개의 이웃사이에 샘플이 추가된 그림이다. -
ADASYN: 소수 범주 데이터 주변 K개 이웃 중 다수 범주 데이터의 비율을 고려하여 스케일링 하고 SMOTE 방법과 유사한 프로세스를 진행 후 각 점들에 임의의 작은 값을 더해주어 분산이 보다 큰 데이터를 생성한다.
# imbearn 라이브러리로 다양하게 진행해 볼 수 있다.
from imblearn.under_sampling import RandomUnderSampler
undersample = RandomUnderSampler(sampling_strategy='majority') # number of minority class / number of majority class = 1
# undersample = RandomUnderSampler(sampling_strategy=0.5) # number of minority class / number of majority class
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(sampling_strategy='auto')
x_under, y_under = tl.fit_resample(x, y)
from imblearn.over_sampling import RandomOverSampler
oversample = RandomOverSampler()
x_over, y_over = oversample.fit_resample(x, y)
from imblearn.over_sampling import SMOTE
oversample = SMOTE(random_state=312)
x_over, y_over = oversample.fit_resample(x, y)
print(y_over.value_counts())
REFERENCE
