
웹크롤링
파이썬을 이용한 웹 크롤링 기법과 그에 따른 데이터 처리, 이동평균선 그리기 등의 실습 내용을 다룹니다. 각 단계별로 필요한 라이브러리 설치부터 웹 페이지 요청, 데이터 파싱, 그리고 시각화까지의 과정을 정리하였습니다.

1. 라이브러리 설치
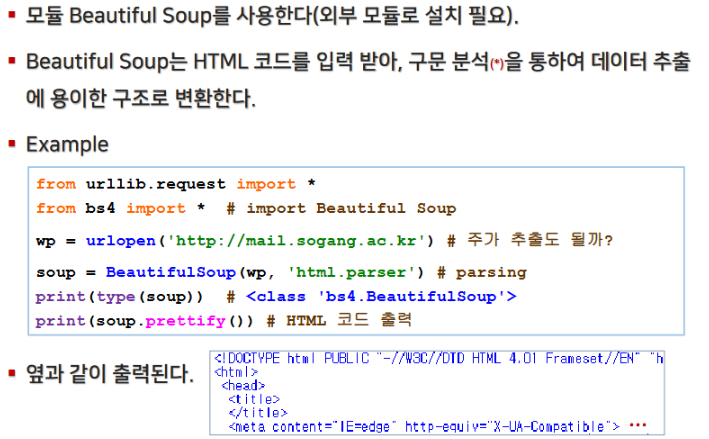
웹 크롤링과 데이터 시각화를 위해 주로 사용하는 라이브러리는 BeautifulSoup4와 matplotlib 입니다.
아래의 명령어를 사용하여 설치합니다.

pip install beautifulsoup4
pip install matplotlib2. 웹 문서 읽기 및 요청(Request)
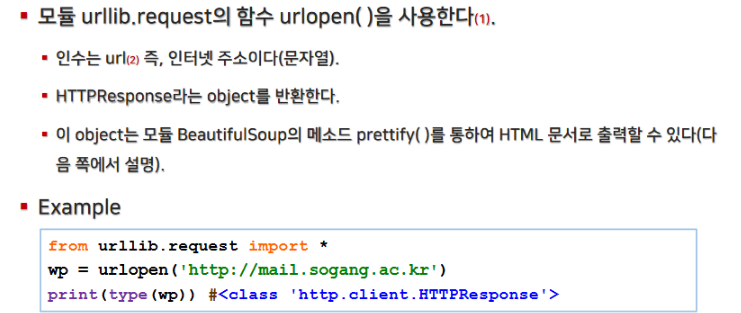
파이썬의 urllib.request 모듈의 urlopen() 함수를 사용하여 웹 페이지를 가져올 수 있습니다.
그러나, 많은 웹 사이트에서는 단순 요청만으로는 봇의 접근으로 판단되어 차단될 수 있기 때문에,
Request 객체를 사용하여 HTTP 요청 헤더에 올바른 User-Agent를 추가하는 것이 권장됩니다.
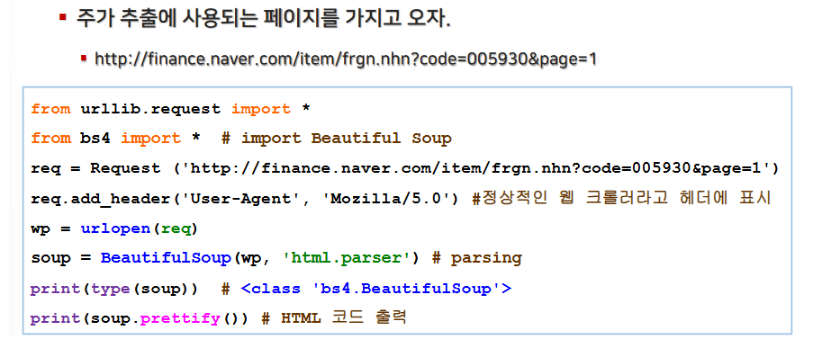
예제 URL: https://finance.naver.com/item/frgn.nhn?code=005930&page=1
아래 이미지들은 Request 객체를 사용하여 헤더를 추가한 후 웹 문서를 요청하는 과정을 보여줍니다.


중요 사항:
HTTP 요청 시 Request 객체를 먼저 생성하고, add_header('User-Agent', 'Mozilla/5.0') 와 같이 헤더를 추가하는 것이 정석입니다.
헤더가 없으면 서버가 이를 봇으로 인식하여 접근을 차단할 수 있습니다.
아래 이미지는 이러한 방식으로 Request 객체를 생성한 후 웹 페이지를 요청하는 코드 예제를 보여줍니다.
{kind=link}
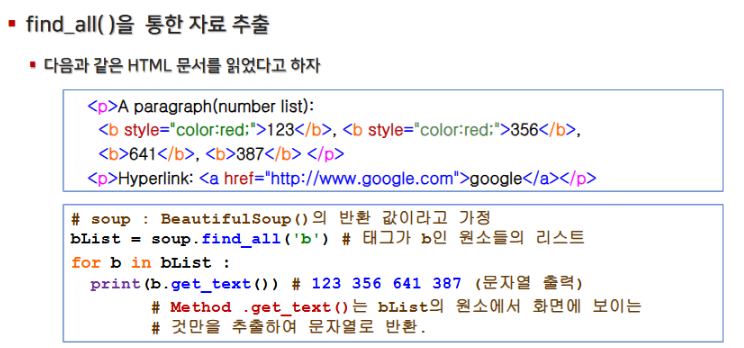
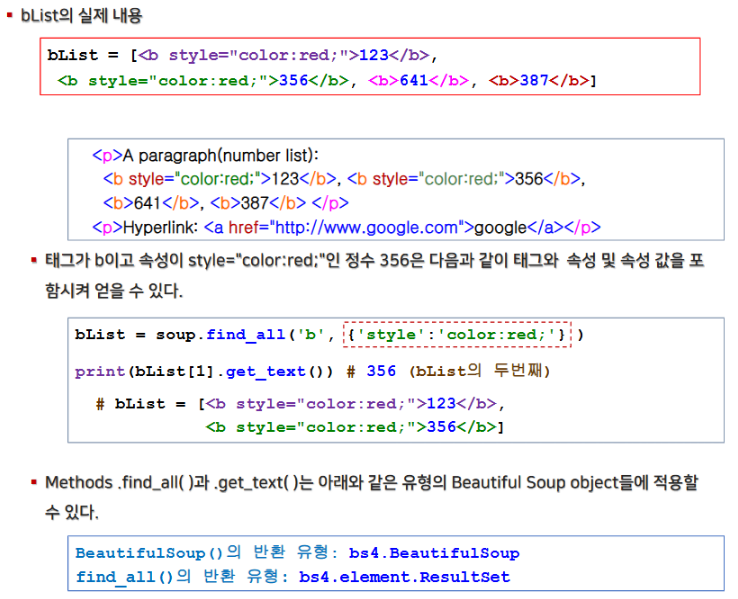

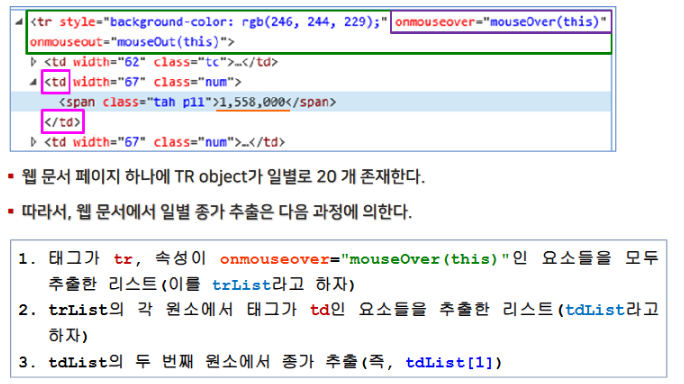

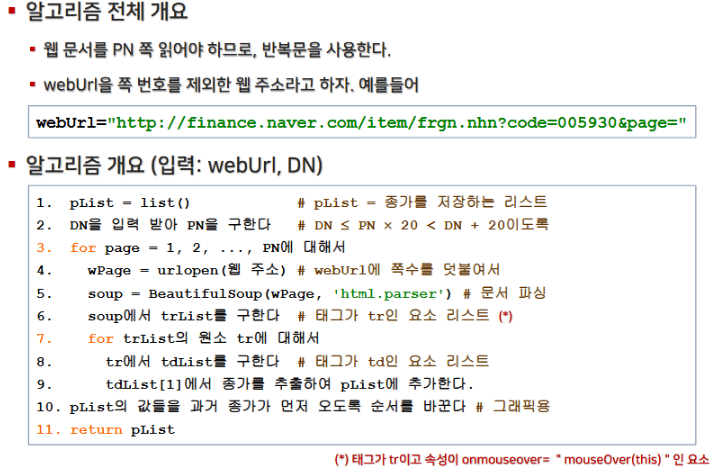
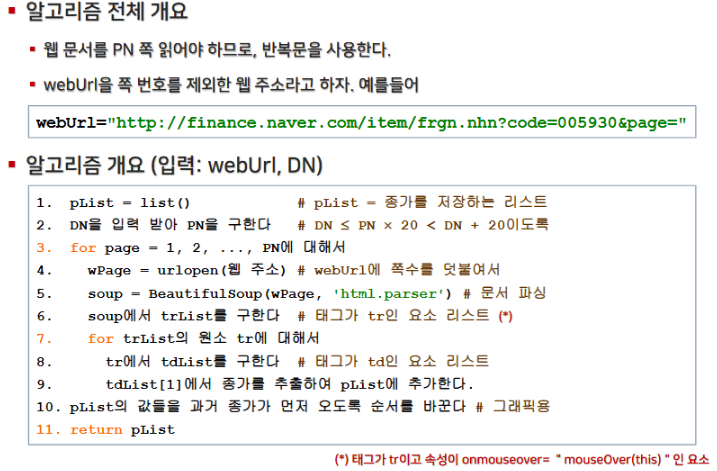

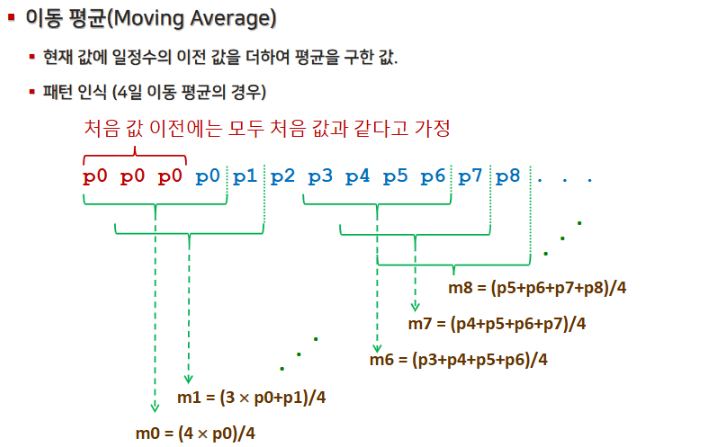
3. 이동평균선 그리기
웹 크롤링으로 수집한 데이터를 활용하여 시계열 데이터를 분석할 때, 이동평균선은 데이터의 전반적인 추세를 파악하는 데 유용합니다.
아래 이미지는 이동평균선을 그리는 과정을 단계별로 보여줍니다.




참고:
show() 함수 호출 이전까지는 그래프가 메모리에 그려지고 있을 뿐, 실제 화면에 출력되지는 않습니다.
그래프를 최종적으로 화면에 표시하려면 show() 함수를 호출해야 합니다.

