Dacon에서 주최한 MNIST 변형 대회 참가 코드 리뷰
대회 정보 : Dacon
제출 코드 : Github
1. EDA (Exploratory Data Analysis)
EDA를 진행하기 위해 먼저 대회에서 제공되는 데이터셋을 불러와서
train과 test 데이터셋의 shape가 어떻게 되는지 살펴보았다.

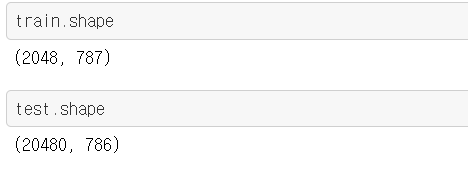
보면 train 데이터셋이 2048개, test 데이터셋이 20480개가 되는 것을 볼 수 있다.
이는 학습할 수 있는 데이터가 2048개이고 예측해야하는 결과가 20480개라는 의미이다.
( train 데이터셋보다 test 데이터셋이 많은 경우는 처음봐서 조금 당황했었다;; )
다음으로 우리의 모델에 학습시켜야할 train 데이터셋을 살펴보았다.

총 787개의 columns가 있지만 기존 mnist 데이터셋의 shape가 28 by 28인 것을 생각해보면
28 * 28 = 784개를 제외한 나머지 column들은 특징이 아닌 다른 정보인 것을 알 수 있었다.
실제로 앞에 3개의 column들은 id 값, digit 정답, letter 정답인 것을 볼 수 있다.
그 뒤부터 title이 0~783인 데이터들은 mnist와 동일하게 이미지의 픽셀 값을 가지고 있다.
※ test 데이터셋은 앞에 정답 부분이 없고 픽셀 값의 정보만 있다
Note
EDA 단계적으로 봤을 때 정답 값들과 픽셀 값들을 분리해야 한다고 생각했고
각 픽셀값의 범위가 0~255 사이이기 때문에 정규화를 적용시켜 학습 효율을 높여야 함을 파악했다.
그 다음 픽셀값들을 조합했을 때 어떤 이미지가 나오는 지
matplotlib 라이브러리를 이용하여 확인해보았다.
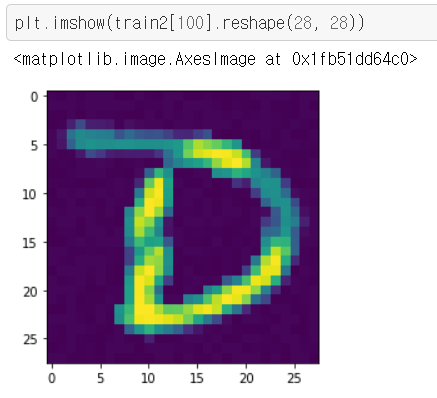
결과는 위 사진과 같다.
주최측의 데이터 설명을 보면 주어진 MNIST 변형 데이터는
기존 숫자 이미지에다가 문자 이미지를 덮어 씌운 이미지라고 한다.
위 이미지에는 D라는 문자가 보이는데 부분적으로 노란색을 띈 영역이 있다.
이게 가려진 숫자이다.
쉽게말해 문자 부분이 투명이라 가정했을 때 뒤에 가려진 숫자가 부분적으로 보여지는 것이다.
아래 이미지는 다른 고수분이 이미지 출력 방식을 바꿔 뒤에있는 숫자를 본 예시이다.
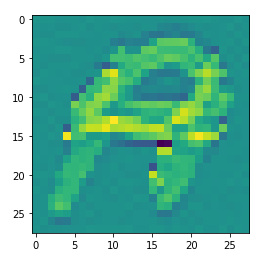
이런 이미지를 2048장 가지고 있고 정답 또한 알고있다.
이제 모델에 학습시키기 전 데이터를 잘 가공하는 전처리를 해야한다.
2. 전처리 (Preprocessing)
전처리 단계에서는 EDA 단계에서 봐둔 데이터셋 분리와 정규화를 하였다.
x_train = train.iloc[:, 3:] / 255.
y_train = train['digit']
x_test = (test.iloc[:, 2:] / 255.).values.reshape(-1, 28, 28, 1)위에 전처리만하고 모델링 하였을 때 정확도는 형편없었다.
내가 판단했을 때 학습데이터가 너무 부족해서 정확도가 안나온다고 생각했고
Augmentation(데이터증가) 기술을 추후에 전처리에 추가했다.
Augmentation이란?
이미지가 주어졌을 때 이미지를 뒤집거나(Flip) 확대하거나(zoom) 자르는(crop) 등
여러 기술을 적용한다. 그럼 기존 이미지와 다른 픽셀 값들을 갖는 새로운 이미지들이 생성되고
이를 우리의 모델이 새로운 데이터라고 인지하고 학습하는 방식이다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range = 15,
width_shift_range = 0.1,
height_shift_range = 0.1,
zoom_range = 0.10
)
train_generator = datagen.flow_from_directory(
'dataset/train',
target_size=(28, 28),
batch_size=16,
)keras에 ImageDataGenerator라는 라이브러리를 이용하여 쉽게 데이터 증가시켰다
ImageDataGenerator() 함수 안에 여러 하이퍼 파라미터를 설정하여 데이터 증량을 정의한다.
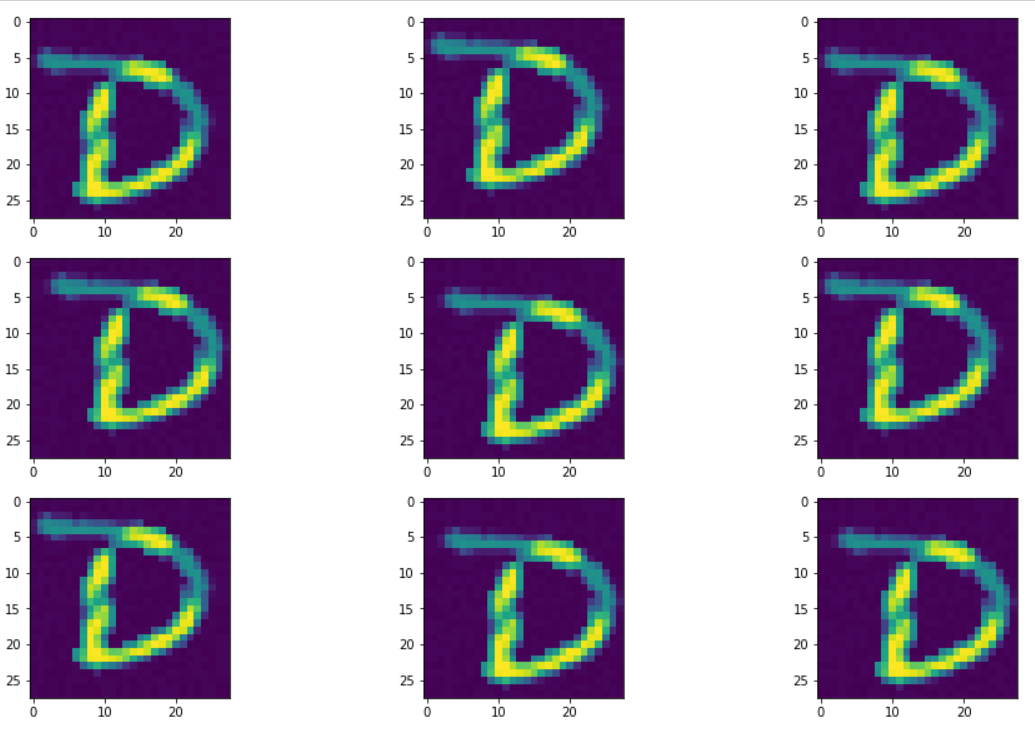
위 사진은 ImageDataGenerator로 위치만 변경시키고 확인해 본 결과이다.
약간씩 위치가 다름을 볼 수 있는데 이정도만 돼도 픽셀 값이 완전히 변하기 때문에
정확도가 향상되기에 충분하다.
augmentation 적용 후 증가된 train 데이터 셋에서 validation 데이터셋을 추출하였다.
from sklearn.model_selection import train_test_split
annealer = LearningRateScheduler(lambda x: 1e-3 * 0.95 ** x, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
x_train = x_train.values.reshape(-1, 28, 28, 1)
y_train = to_categorical(y_train.values)
x_train2, x_val, y_train2, y_val = train_test_split(x_train, y_train, test_size=0.1, random_state = 42)
이제 전처리는 모두 끝났고 모델링을 할 차례이다.
3. 모델링 (Modelling)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.20))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Dropout(0.20))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Dropout(0.20))
model.add(layers.Flatten())
model.add(layers.Dense(400, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
model.summary()모델은 CNN을 사용해 layer를 쌓았고 중간중간 MaxPooling 기법과 Dropout 기법을 써서 Overfitting을 최대한 막으려고 노력했다. 마지막 출력층에서는 mnist와 동일하게 0~9까지의 숫자를 확률적으로 얻을 수 있도록 softmax를 사용하였다.
아래는 model summary이다.
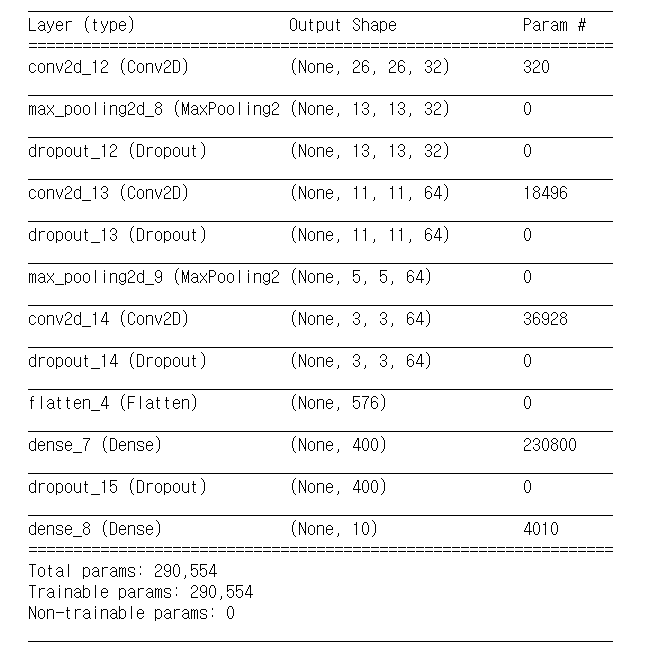
모델의 컴파일은 아래와 같이 하였다.
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])4. 모델 학습 & 예측
history = model.fit(
x_train2, y_train2,
epochs=45,
callbacks=[annealer, early_stopping],
validation_data=(x_val, y_val),
verbose=2
)학습 결과는 train 데이터셋의 정확도는 87%, validation 데이터셋의 정확도는 81%가 나왔다
y_test = model.predict(x_test)
y_test = np.argmax(y_test, axis=1)
y_test = pd.Series(y_test, name="digit")
submission = pd.concat([pd.Series(range(2049, 22529), name="id"), y_test], axis=1)
submission.to_csv("2020-08-13-pred1.csv", index=False)결과를 제출 형식에 맞춰 csv 파일로 변환시키고 제출하였을 때 정확도가 83%로 나왔다.
augmentation을 하지 않고 제출했을 땐 50% 정도의 정확도를 보였었는데
훨씬 학습이 잘 된 것을 볼 수 있었다.
