예제: 트리 순회 순서 변경
트리를 순회하는 알고리즘은 트리의 모든 노드들을 특정 순서에 맞춰 방문하지만, 트리는 배열처럼 1차원적인 구조가 아니기 때문에 단 한 가지의 당연한 순서가 존재하지 않습니다. 때문에 필요에 맞춰 순서를 정의해야 합니다. 이진 트리(binary tree)는 모든 노드에 왼쪽과 오른쪽, 최대 두 개의 자손이 있는 트리를 말하는데, 이진 트리의 순회 순서 중 유명한 세 가지로 전위 순회(preorder traverse), 중위 순회(inorder traverse) 그리고 후위 순회(postorder traverse)가 있습니다. 이들은 모두 왼쪽 서브트리를 오른쪽보다 먼저 방문한다는 점에선 같지만, 트리의 루트를 언제 방문하는지가 서로 다릅니다.
전위 순회는 맨 처음에 트리의 루트를 방문하고, 왼쪽과 오른쪽 서브트리를 순서대로 방문합니다. 중위 순회는 왼쪽과 오른쪽 서브트리 사이에 트리의 루트를 방문하고, 후위 순회는 왼쪽과 오른쪽 서브트리를 모두 방문한 뒤에야 루트를 방문합니다.
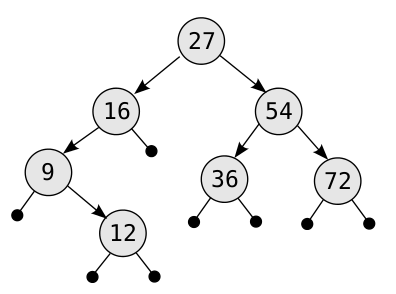
다음 그림은 이진 트리의 한 예를 보여 줍니다. 이 트리를 전위 순회하면 모든 노드를 27, 16, 9, 12, 54, 36, 72의 순서대로 방문하게 됩니다. 반면 중위 순회했을 때는 9, 12, 16, 27, 36, 54, 72의 순서로, 후위 순회했을 때는 12, 9, 16, 36, 72, 54, 27의 순서로 방문하게 되지요.
어떤 이진 트리를 전위 순회했을 때 노드들의 방문 순서와, 중위 순회했을 때 노드들의 방문 순서가 주어졌다고 합시다. 이 트리를 후위 순회했을 때 각 노드들을 어떤 순서대로 방문하게 될지 계산하는 프로그램을 작성하세요.
입력
입력의 첫 줄에는 테스트 케이스의 수 C (1≤C≤100)가 주어집니다. 각 테스트 케이스는 세 줄로 구성되며, 첫 줄에는 트리에 포함된 노드의 수 N (1≤N≤100)이 주어집니다. 그 후 두 줄에 각각 트리를 전위 순회했을 때와 중위순회 했을 때의 노드 방문 순서가 N개의 정수로 주어집니다. 각 노드는 1000 이하의 자연수로 번호 매겨져 있으며, 한 트리에서 두 노드의 번호가 같은 일은 없습니다.출력
각 테스트 케이스마다, 한 줄에 해당 트리의 후위 순회했을 때 노드들의 방문 순서를 출력합니다.예제 입력
2 7 27 16 9 12 54 36 72 9 12 16 27 36 54 72 6 409 479 10 838 150 441 409 10 479 150 838 441예제 출력
12 9 16 36 72 54 27 10 150 441 838 479 409
풀이
올해 처음 풀어보는 트리 문제이다.
전위순회, 중위순회, 후위순회.. 참 많이 보는 것이면서도 헛갈리는 것들이다.
이 순회들을 이해하고 있다면, 이를 이용해서 문제를 푸는게 가능하다.
예를 들어, 전위 순회 순서가 A, B, C 이고 중위 순회 순서가 B, A, C 이면
후위 순회는 B출력, C출력, A출력 이런 순서대로 출력하도록 재귀함수를 구성하면 된다.
꼭 벡터로 안해도 되고, list나 ListNode 구조체를 만들어도 될 것 같지만, 이진 트리에서는 벡터를 쓰는게 좋은 방법이라 생각한다.
전체적인 소스코드는 아래와 같다.
소스 코드
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
void postorder(const vector<int>& preorder, const vector<int>& inorder, const int& N) {
//기저: N = 0일 때
if (N == 0) return;
//기저: N = 1일 때
if (N == 1) {
cout << preorder[0] << " ";
return;
}
int idx;
for (int i = 0; i < N; i++) {
if (inorder[i] == preorder[0]) {
idx = i;
break;
}
}
//left
postorder(vector<int>(preorder.begin() + 1, preorder.begin() + 1 + idx)
, vector<int>(inorder.begin(), inorder.begin() + idx), idx);
//right
postorder(vector<int>(preorder.begin() + 1 + idx, preorder.end())
, vector<int>(inorder.begin() + idx + 1, inorder.end()), N - idx - 1);
//parent
cout << preorder[0] << " ";
}
int main() {
int testCase;
cin >> testCase;
for (int tc = 0; tc < testCase; tc++) {
int N;
cin >> N;
vector<int> preorder(N, 0), inorder(N, 0);
for (int i = 0; i < N; i++) {
cin >> preorder[i];
}
for (int i = 0; i < N; i++) {
cin >> inorder[i];
}
postorder2(preorder, inorder);
cout << endl;
}
return 0;
}풀이 후기
필자의 코드 중 idx를 찾는 부분을 도서 풀이는 find로 깔끔하게 해낸다. 아직 STL이 머리에 없는지 필자는 바로바로 머리에 떠오르질 않는다.
또한, 노드 방문 순서를 입력받으려면 당연히 노드의 수 N개를 입력받아야 하는데, 필자는 갑자기 정신을 놓았는지 '아 이걸 매개변수로 쓰라고 주는건가?' 하고 필요도 없는 N을 매개변수로 쓰고있다. 'size()로 알 수 있는데 이걸 왜 매개변수로 받지?' 하는 생각을 하면서도 그냥 진행한 걸 보면 새벽시간이라 정신이 몽롱한가보다.
그래도 로직은 도서 풀이와 같아서 기분이 좋았다.
