들어가기 전

이게 뭔가요?
맥도날드에서 햄버거를 먹고싶은날 아침에 가면 햄버거 대신 볼 수 있는
해시 브라운이다.
갑자기 이걸 왜 말하냐고?
해시 라는것은 잘게 써는 조리법을 의미하고, 브라운은 갈색으로 익힐 떄까지 튀긴 것을 말하는 거란다.
즉 동그란 감자를 내가 원하는 모양으로 으깨 다른모양을 만들고 조리하는 과정이라 생각한다.
엥 우리가 코딩을 할때 어떠한 것을 다른 모양으로 만들어야할때가 있나?
해시 테이블을 왜 배워야 할까?
취업해야 하기 때문에 &&
만약에 유저가 회원가입을 하고 id, password 정보를 DB에 저장해야한다고 생각해보자.
id는 그렇다 쳐도 password를 직접 DB에 저장하게 되면 정보통신망법 에 의해 처벌받는다.
그래서 비밀번호 1234를 해시 함수 를 이용해 329jv#s9v 이런식으로 암호화해서 저장한다.
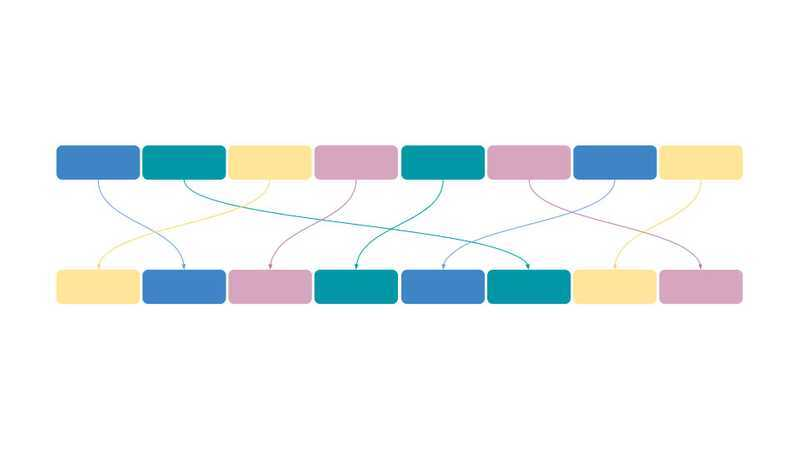
이때 암호화하기 전 원래 데이터의 값 1234를 키 , 매핑 후 데이터의 값을 해시 , 매핑 과정을 해싱 이라 한다.
뭐 솔트라는 값을 넣거나 해시 함수를 여러번 돌리는 방법도 있지만 그건 관련이 없으니~
그럼 해시 테이블(Hash Table)이 뭔데?
우선 해시 테이블이란 본 게임으로 들어가기전
준비 동작을 좀 해보자.
직접 주소 테이블(Direct Address Table)
해시 테이블의 아이디어는 직접 주소 테이블이라는 자료구조에서 출발한다.
이는 입력받은 value가 곧 키 가 되는 데이터 매핑 방식이다.
조금 예시를 보자면
class DirectAddressTable {
constructor () {
this.table = [];
}
setValue (value = -1) {
this.table[value] = value;
}
getValue (value = -1) {
return this.table[value];
}
getTable () {
return this.table;
}
}
const myTable = new DirectAddressTable();
myTable.setValue(7);
myTable.setValue(20);
myTable.setValue(50);
console.log(myTable.getTable());를 크롬 개발자 도구나 node.js에서 실행시키면
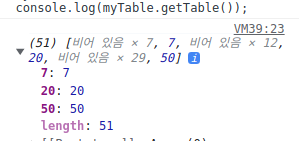
이렇게 7을 테이블에 넣으면 이 값은 배열의 7번 인덱스의 요소가 되고(그래서 앞의 7개가 비어있어야 한다)
20을 넣으면 이 값은 배열의 20번째 인덱스의 요소가 되는 방식이다.
말 그대로 직접 주소 테이블
즉, 들어오는 값을 알면 저장된 인덱스도 함께 알 수 있겠네 ⇒ 시간 복잡도는 O(1)이다.
엄첨 좋은거임 왜냐?
보통 탐색, 삽입, 수정 ,삭제 하는 알고리즘이 시간을 잡아먹게 되는 이유는
- 내가 찾고 싶은 값이 어디 있는지 모른다.(이진트리탐색 같은 경우)
- 내가 이 값을 삽입하거나 삭제하면 다른 값이 영향을 받는다. (링크드 리스트 같은 경우)
인데 얘는 그냥 1000번쨰 찾고싶으면 바로 찾아지니까 좋네.
허나, 빠르긴 빠른데 당연히 단점이 있겠지? 단점은 뭘까…
저 결과창을 보면 알겠지만
저장된 데이터를 제외한 나머지 공간은 값이 없지만 메모리 공간을 할당되어 있기 때문에
저장해야 할 값의 범위가 102942842389 이렇게 크다면, 큰 비효율성을 보이겠지
Array(91) [
0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 10, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 90]이와 반대로 저장해야 할 값의 범위가 크지 않으면 사용해 볼법하겠네.
여튼
자, 그럼 이제
이런 직접 주소 테이블의 단점을 보완할 수 있는 방법은 뭐가 있나요??라고 물어봐야됨
직접 주소 테이블의 단점을 해시 함수로 보완하자!
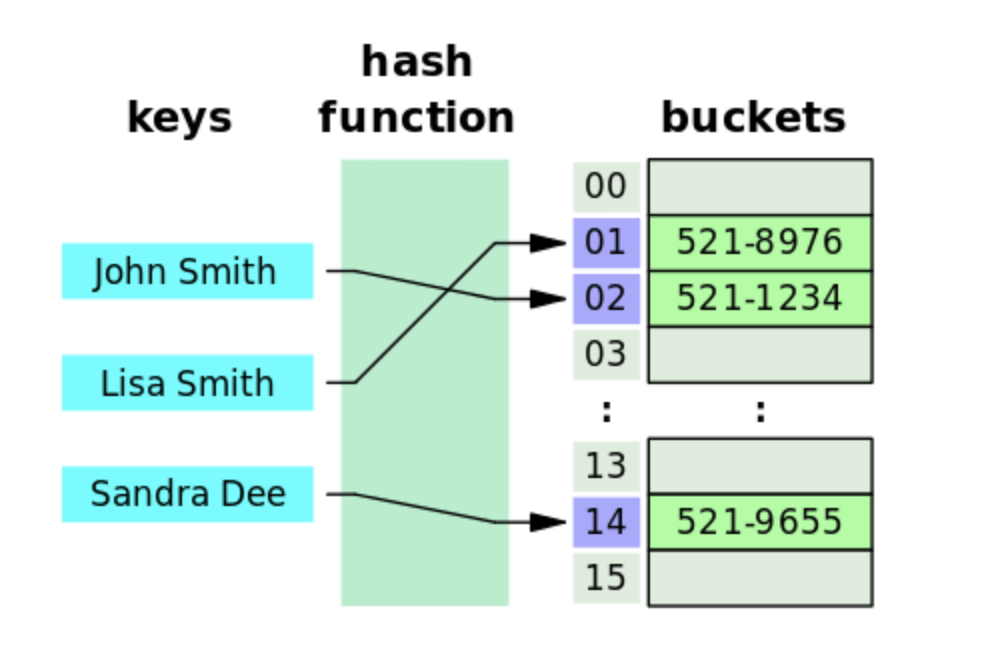
해시 테이블 은 직접 주소 테이블과 같이 값을 바로 테이블의 인덱스로 사용하는 것이 아니라
해시 함수 라는것에 한번 통과 시켜 사용한다.
해시 테이블 은 해시 함수를 활용해서 키 값에 인덱스를 배정하고,
인덱스의 값에 데이터를 넣는 자료 구조를 말한다.
그리고 해시란, 이 함수가 뱉어내는 결과물을 말한다.
이것도 예시를 봐야겠지?
function hashFunction (key) {
return key % 10;
}
console.log(hashFunction(102948)); // 8
console.log(hashFunction(191919191)); // 1
console.log(hashFunction(13)); // 3
console.log(hashFunction(997)); // 7위의 해시 함수는 들어오는 키값을 10으로 나눈 후의 나머지를 반환한다.
그래서 어떤 큰 값이 들어오든 0 ~ 9까지의 값만 반환하게 된다.
직접 주소 테이블 에서는 1000이 들어오면 무조건 1000의 크기를 가진 테이블을 생성해야 했고 999개의 버리는 공간이 발생했지만
해시함수를 활용하니 고정된 테이블의 길이를 내 마음대로 정해둘 수 있고(0 ~ 9) 그 안에만 데이터를 저장할 수 있다!
근데 여기서 눈치가 빠른 사람은 또다른 문제가 생겼다는 것을 깨달았을 것이다.
9나 19나 해싱 함수를 거치면 똑같이 9를 반환하는데 그러면 그 데이터들의 구별은 어떻게 할 것이냐??
상식적으로 생각해봐도 테이블의 크기를 100으로 잡고 테이블에 200개의 데이터를 넣는다면
어떻게 할까 싶겠지.
이걸 유식한말로 해시의 충돌 이라고 한다.
해시의 충돌(Collision)
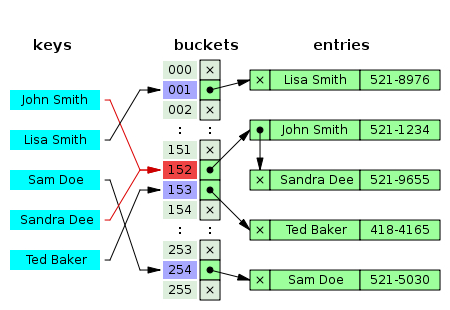
위의 그림처럼
John Smith와 Sam Doe는 해쉬함수를 통해 152라는 인덱스를 배정받았다.
이것을 해시의 충돌이라고 한다.
그럼 당연히 우리는 충돌을 근본적으로 피할 수는 없으니
충돌을 최소화시키는 해시 함수를 짜거나, 충돌이 발생하더라도 우회해서 해결할 수 있는 방법을 사용해야 겠지!
개방 주소법(Open Address)
해시 충돌이 발생하면 테이블 내의 새로운 주소를 탐사(Probe) 한 후, 비어있는 곳에 충돌된 데이터를 입력하는 방식.
해시 함수를 통해서 얻은 인덱스가 아니라 다른 인덱스를 허용한다는 의미로 개방 주소 라고 한다.
그러면 어떻게 비어있는 공간을 탐사할 것이냐에 따라 무려 4가지로 나누어 진다.
1. 선형 탐사법(Linear Probing)
function hashFunction (key) {
return key % 10;
}
console.log(hashFunction(1001)); // 1
console.log(hashFunction(11)); // 1
원래는 1001과 11보수 1번 인덱스에 들어가야 하지만
11은 해시 테이블에 들어갈 자리가 없으니 정해진 칸만큼의 옆 방(n칸)을 준다.
이게 선형 탐사법이다. 여기서는 n = 1칸으로 준다.
이떄 또 21, 31이 들어오면

이렇게 되겠지
근데 이것의 문제점이 뭘까?
해시로 8, 7 인 키가 들어오면 상관이 없지만
계속 1인 해시의 키가 들어오면?? 데이터가 1을 기준으로 연속으로 저장될것이고
그러면 데이터가 1을 기준으로 밀집되어있는 큰 덩어리가 생길 것이다.
그러면 충돌이 더 발생하고 ⇒ 그래서 옆에 저장하여 커지고 ⇒ 충돌 발생 가능성이 더 커지고..
악순환의 반복이다.
이것을 일차 군집화**(Primary Clustering) 이라고 한다.**
그럼 이 선형 탐사법을 보완한 새로운 룰이 나오겠지?
2. 제곱 탐사법(Quadratic Probing)
이름을 보고 유추할 수 있다시피 선형처럼고정된 n칸만큼 늘어나는게 아니라
제곱 만큼 늘어난다.
첫번쨰 충볼이 발생했을 때는 충돌난 지점으로 만큼, 두번쨰는 , 세번쨰는 이런식으로 탐사한다.

이런식으로..
근데 문제는 어차피 해시로 1이 나오면 결국 1끼리는 충돌이 나겠지.
이것을 이차 군집화**(Secondary Clustering) 라고 한다.**
그럼 이걸 개선 하려면?
3. 이중해싱(Double Hashing)
이름 그대로 해시 함수를 이중으로 사용하는 것이다.
중요한점은 단순히 같은 해시 함수를 두 번 사용하는게 아니라
첫번쨰 함수는 최초 해시를 얻을 때 그대로 사용하지만
다른 하나는 충돌이 났을 경우 탐사 이동폭을 얻기 위해 사용 하는 것이다.
이렇게 하면 최초 해시로 같은 값이 나오더라도 다른 해시 함수를 거치면서 다른 탐사 이동폭이 나올 확률이 높기 때문에 값이 골고루 저장될 확률도 높아진다.
예제를 좀 보자
const myTableSize = 23; // 테이블 사이즈가 소수여야 효과가 좋다
const myHashTable = [];
const getSaveHash = value => value % myTableSize;
// 스텝 해시에 사용되는 수는 테이블 사이즈보다 약간 작은 소수를 사용한다.
const getStepHash = value => 17 - (value % 17);
const setValue = value => {
let index = getSaveHash(value);
let targetValue = myHashTable[index];
while (true) {
if (!targetValue) {
myHashTable[index] = value;
console.log(`${index}번 인덱스에 ${value} 저장! `);
return;
}
else if (myHashTable.length >= myTableSize) {
console.log('풀방입니다');
return;
}
else {
console.log(`${index}번 인덱스에 ${value} 저장하려다 충돌 발생!ㅜㅜ`);
index += getStepHash(value);
index = index > myTableSize ? index - myTableSize : index;
targetValue = myHashTable[index];
}
}
}
console.log(setValue(1991));
console.log(setValue(6));
console.log(setValue(13));
console.log(setValue(21));
의 결과는
13번 인덱스에 1991 저장!
undefined
6번 인덱스에 6 저장!
undefined
13번 인덱스에 13 저장하려다 충돌 발생!ㅜㅜ
17번 인덱스에 13 저장!
undefined
21번 인덱스에 21 저장!
undefined작동과정은
1. 저장할 인덱스를 getSaveHash 해시 함수로 얻는다.
2. 반복문 시작
3. 거기 비었니?
3-1. 비었으면 저장! (!targetValue)
3-2. 있으면 다음 인덱스 줘! (getStepHash)
3-3. 테이블이 꽉 찼어? 끝내자!우선 이때 테이블 사이즈와 두번쨰 해시함수에 사용될 수는 둘 다 소수 를 사용하는 것이 좋다.
둘 중에 하나라도 소수가 아니라면 결국 언젠가 같은 해싱이 반복되기 때문이다.
자 이제 앞의 3가지 방법과 전혀 다른 방법을 마지막으로 알아보자
4. 분리 연결법(Separate Chaining)
분리 연결법은 해쉬 테이블의 버킷에 하나의 값이 아니라 링크드 리스트나 트리를 사용한다.
링크드 리스트 사용이나 트리 사용 모두 개념은 동일하니 링크드 리스트로 예제를 보자.
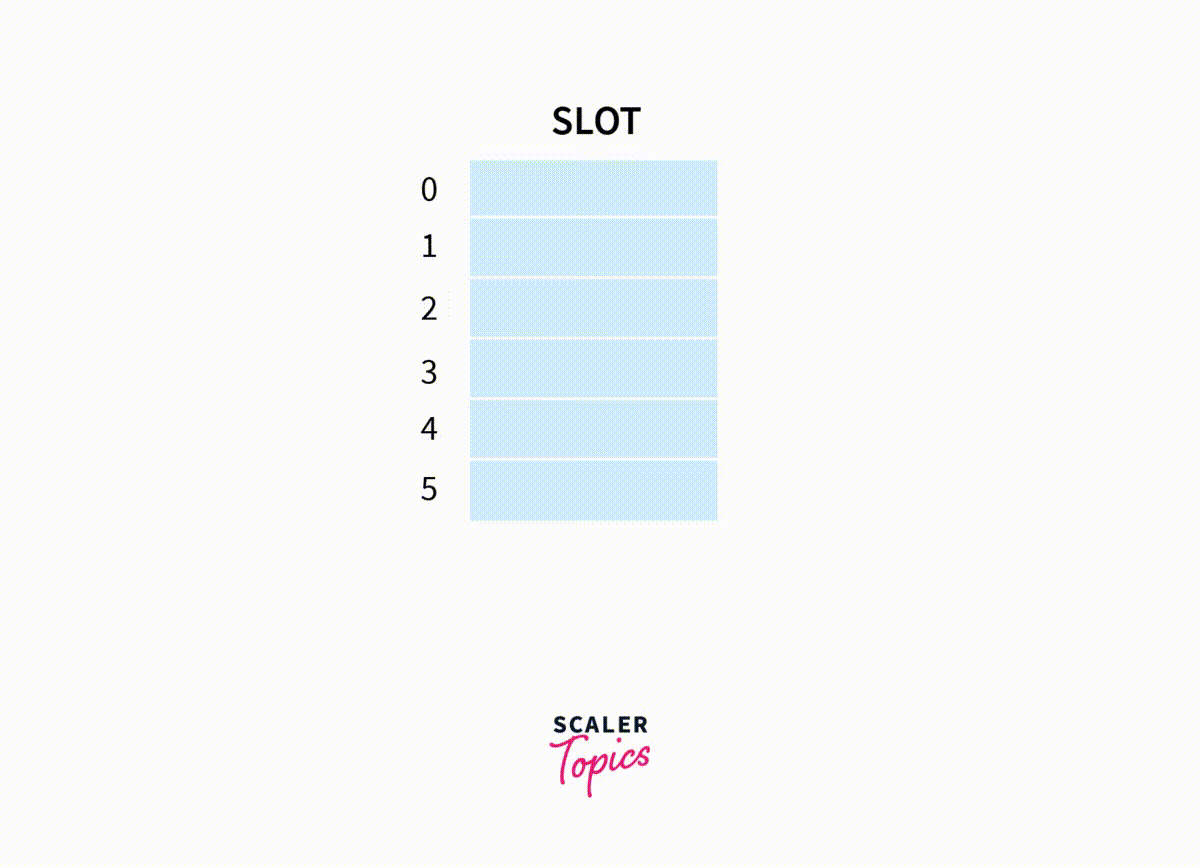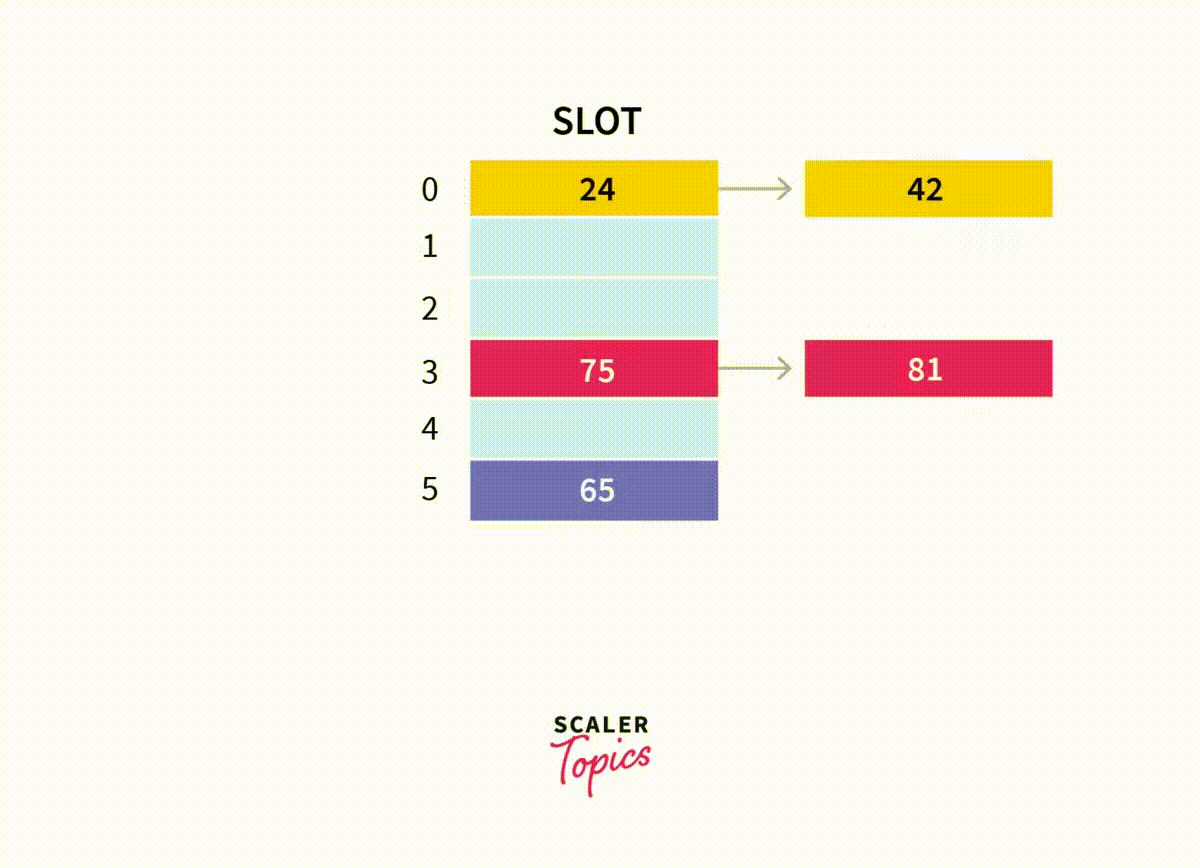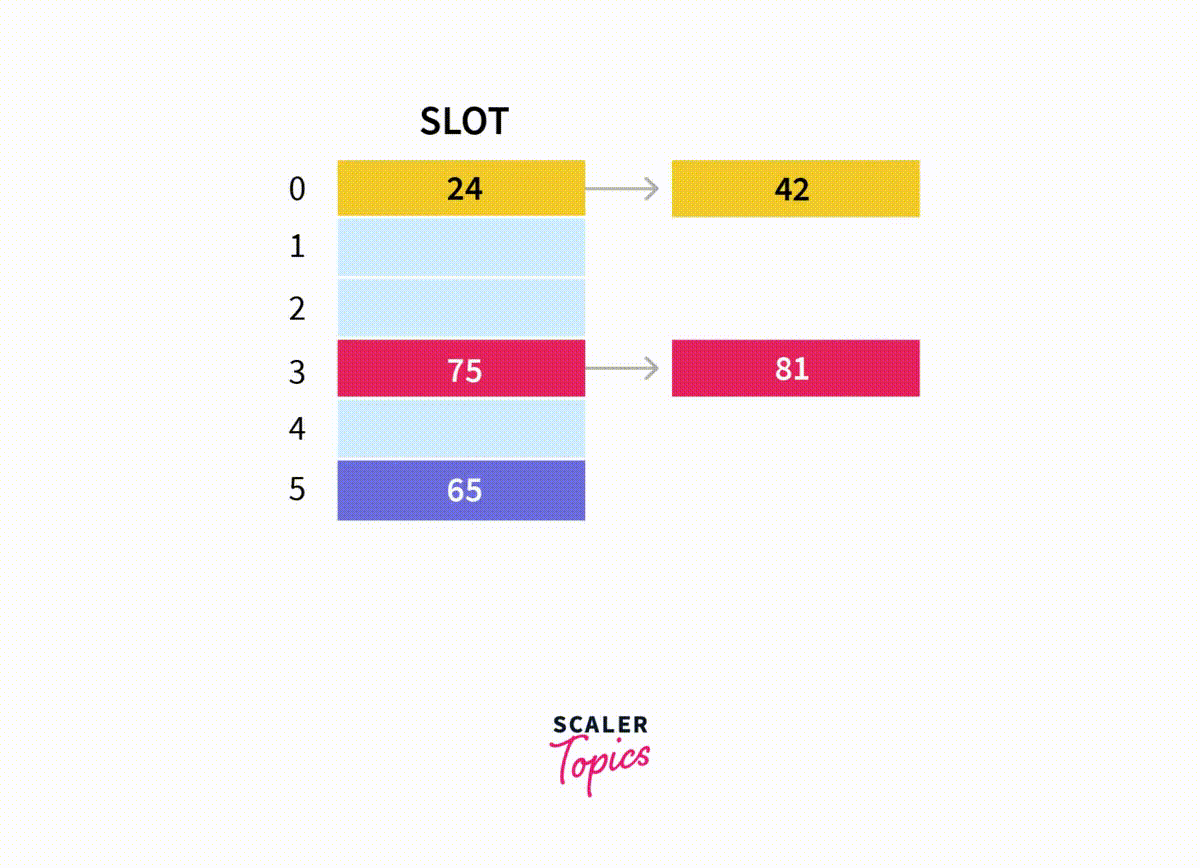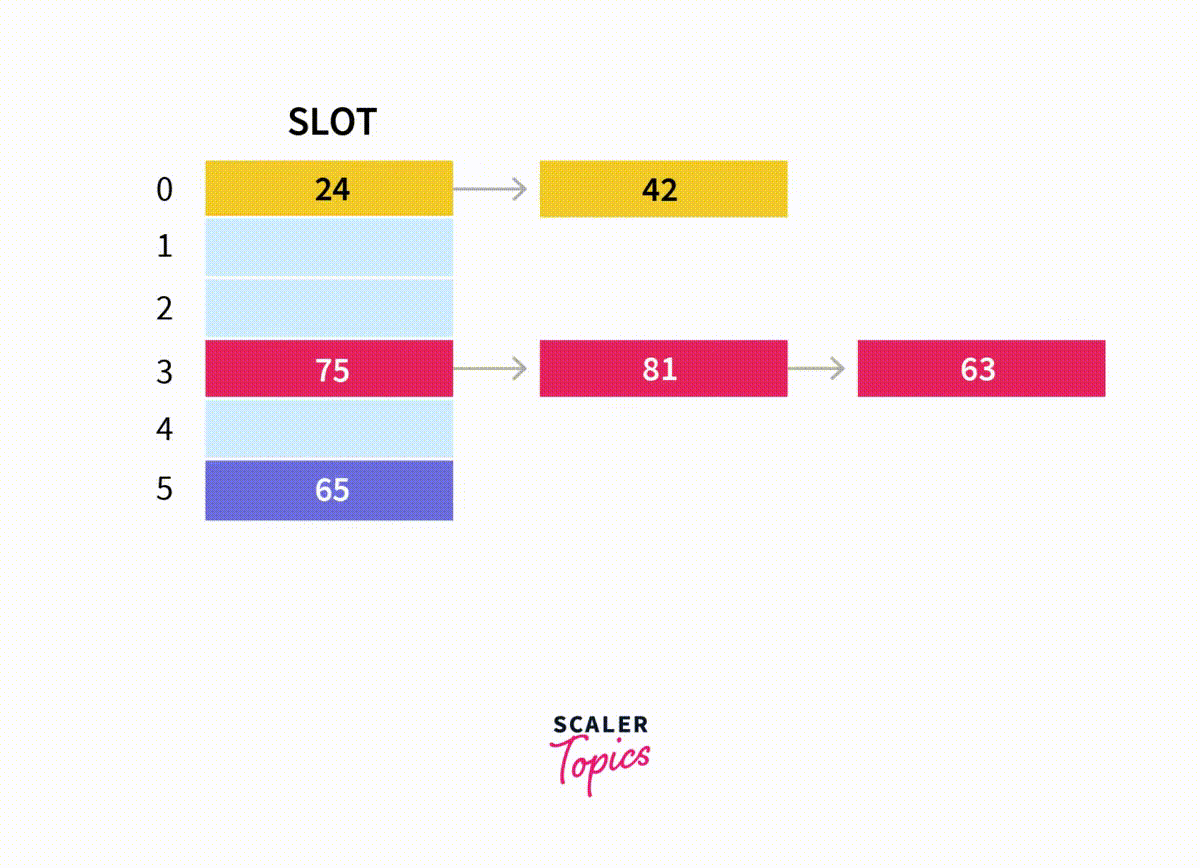
테이블 크기가 5일때 해시로 1을 반환하는 1991, 6, 13, 21을 저장할 때 분리 연결법을 쓰면

이렇게 하면 된다.
근데… 뭔가 이상하네 왜 1991, 6, 13, 21 이 아니라 21, 13 ,6 ,1991로 저장 순서가 거꾸로 추가되어 있을까
그것을 알아보기 위해 저장된 연결 리스트가 [1991, 6, 13, 21] 순서일떄를 살펴보자.

이때 여기서 11을 추가해야한다고 해보자.
-
일단 메모리 주소가 99인 곳이 남길래 여기에 { 값: 11, 다음 노드: null }을 저장한다.
-
그리고 이 새로운 노드를 리스트에 붙혀야 하니까 해당 리스트의 마지막 노드인 메모리 4에 저장된 노드까지 찾아가야 한다.
-
4에 저장된 값을 { 값: 21, 다음 노드: 99 } 로 바꾼다.

문제는 2번 과정이다.
해당 리스트의 마지막 노드 까지 가기위해 메모리 1, 2, 3, 4까지 확인해야 하는 불편함이 있다. 허나
메모리 4의 값은 놔두고 거꾸로 메모리 주소 99를 1앞에 붙이게 되면 메모리 4까지 찾아갈 필요도 없는 것이다.

따라서 해시 테이블에 저장할때 리스트의 꼬리 에 데이터를 붙히기보다 머리 에 붙이면 편하다.
허나 이 분리 연결법을 사용할때 균일하지 못한 해시를 사용하게 되면

그냥 이렇게 저장하는 것과 다를 바가 없다.
또한 분리 연결법을 사용할때 내가 찾고자 하는 값이 리스트의 맨 마지막에 위치하고 있다면
연결 리스트를 처음부터 끝까지 다 탐색해야하기 때문에 의 시간복잡도를 가지게 된다.
참조 :
https://evan-moon.github.io/2019/06/25/hashtable-with-js/
https://overcome-the-limits.tistory.com/9#해시-테이블이-그래서-뭐야?
분리연결법
https://www.scaler.com/topics/data-structures/separate-chaining/
