전화번호 목록
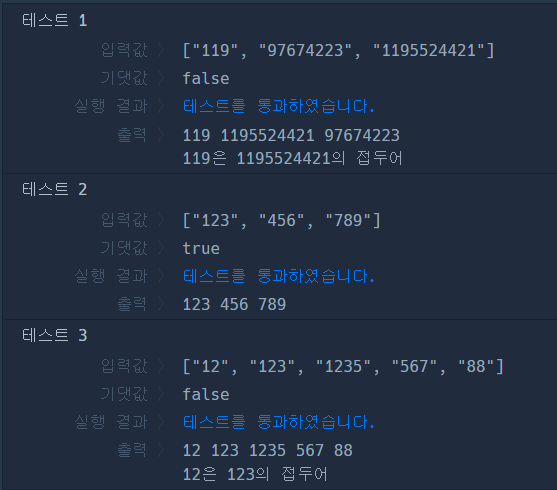
문자열 정렬은 사전순으로 정렬됨을 까먹고, compare 함수를 만들어서 길이순으로 정렬했다. 사실 사전순으로 정렬하면 길이 상관 없이 바로 다음 문자열이 현재 문자열을 접두어로 포함하는지 확인만 하면 되서 효율성을 올릴 수 있다.
또한 첫 풀이에서 substr()를 사용해 각 문자열을 비교했지만, 이후 find() 함수를 사용했다.
문자열B.find(문자열A | 문자A): 처음부터 탐색
문자열B.rfind(문자열A | 문자A): 뒤에서부터 탐색
문자열B.find("문자열A | 문자A", 5): 인덱스 5부터 탐색
문자열B에서문자열A또는문자A의 위치 인덱스를 찾아서 반환한다. 찾지 못하면-1을 반환한다.
phone_book[i + 1].find(phone_book[i]) == 0: 탐색 결과가 0이면phone_book[i]는phone_book[i + 1]의 접두어이다.
#include <string>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
bool solution(vector<string> phone_book) {
bool answer = true;
int i, j;
//string current_str, compare_str;
sort(phone_book.begin(), phone_book.end());//사전 순 정렬
for(string temp : phone_book){
cout << temp << " ";
}
cout << "\n";
for(i = 0; i < phone_book.size() - 1; i++){
// current_str = phone_book[i];
// for(j = i + 1; j < phone_book.size(); j++){
// compare_str = phone_book[j];
// if(compare_str.substr(0, current_str.size()) == current_str){
// //cout << current_str << "은 " << compare_str << "의 접두어\n";
// return false;
// }
// }
if (phone_book[i + 1].find(phone_book[i]) == 0) {
cout << phone_book[i] << "은 " << phone_book[i + 1] << "의 접두어\n";
return false;
}
}
return answer;
}