작업 환경 : 맥 OS + 크롬 + 파이참
네이버 날씨 페이지 가져오기
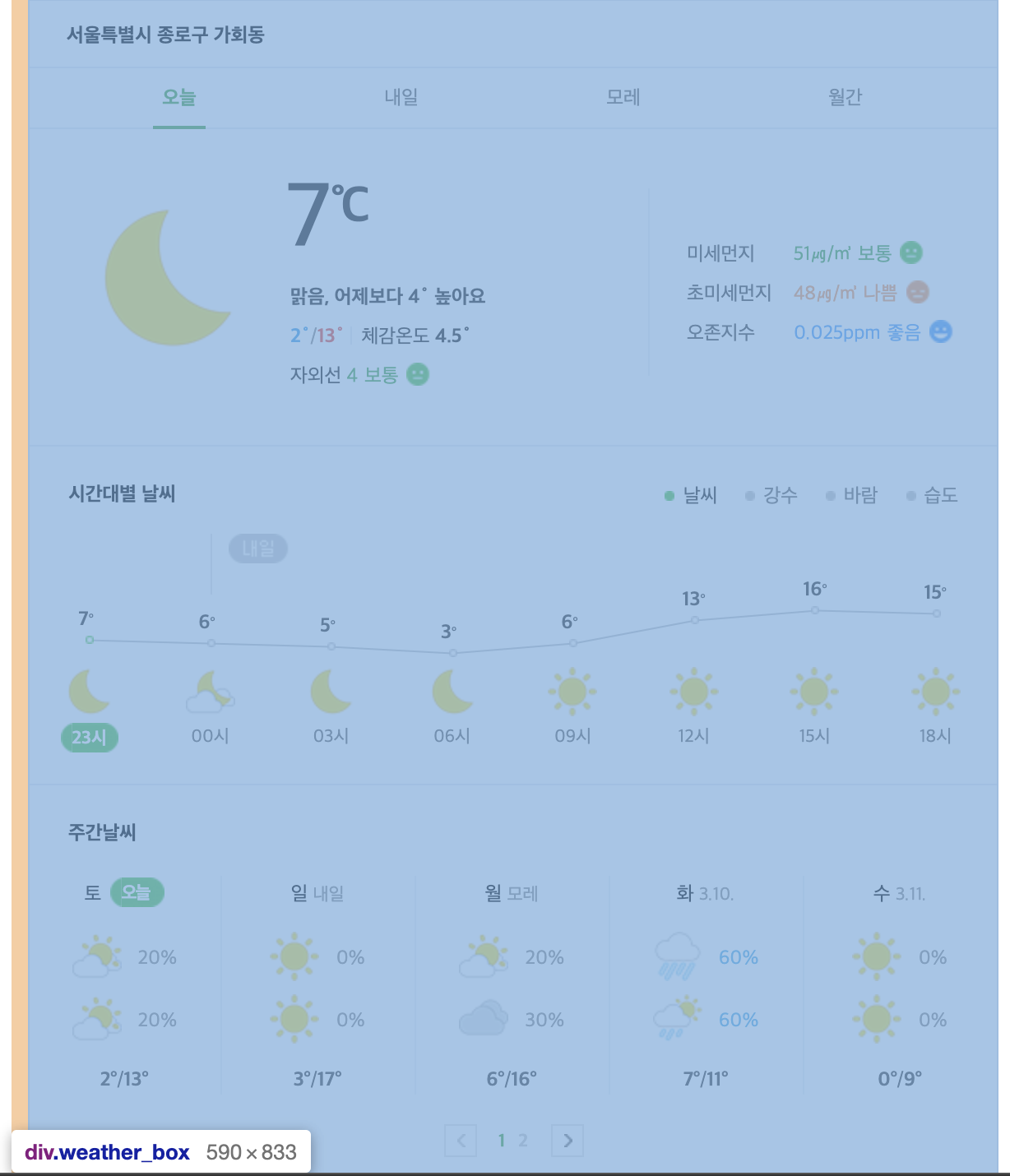
- 보통 날씨 정보를 알기 위해서는 내 위치 정보를 넘겨줘야 그곳에 대한 날씨정보를 얻어올 수 있다.
- 그러나 네이버는 자동으로 내 접속위치를 알아서 계산해준다음 정보를 날씨 정보를 넘겨준다.
- 일단 네이버에 '날씨'로 검색을 하면 오늘 날씨, 강수량, 미세먼지 등의 정보를 알 수 있다.
- 여기에 나오는 주소, 현재 온도, 미세먼지, 초미세먼지, 오존지수를 크롤링해보자.
크롤링을 위한 기본 지식
- 네이버에서 '날씨'를 검색한 뒤, 해당 페이지에서 마우스 오른쪽 클릭 후 '검사'를 눌러보자.
- 개발자 도구가 열리는데, 여기서 Elements 부분을 클릭하면 현재 페이지의 코드들을 확인할 수 있다.
- 개발자 도구에서 왼쪽 위에 보면 화살표 표시가 있는데, 클릭한 후 페이지로 마우스 커서를 옮겨보면 페이지 각 부분의 코드들을 확인 할 수 있다.
- 네이버 날씨 부분을 선택해보면 페이지가 이렇게 나온다.
- 개발자 도구에서 코드부분을 확인해보면 이런식으로 강조가 된다.
- 크롤링을 위해서는 HTML에 대한 기본지식이 필요한데, HTML은 <태그 속성=속성값>텍스트</태그> 라는 기본구조를 갖고 있다.(예외도 있다.)
위 스크린샷을 보자면 div라는 태그에 class 라는 속성, weather_box라는 속성값을 지니고 있는 것이다.


웹페이지 가져오기
1. 우선 웹크롤링을 하기 위해서 코드를 작성할 때 도움을 받을 모듈들을 import 해야한다.
from bs4 import beautifulsoup4
from pprint import pprint
import requests
#pprint는 딕셔너리의 데이터가 긴 경우에 좀 더 보기 편하게 보여주게 도와준다.2. import 가 끝났으면 requests를 이용해서 현재 '네이버 날씨' 웹페이지의 전체 소스코드를 갖고와보자.
html = requests.get('https://search.naver.com/search.naver?query=날씨')
#웹페이지 요청을 하는 코드이다. 특정 url을 적으면 웹피이지에 대한 소스코드들을 볼 수 있다.
pprint(html.text)
#html 이라는 변수에 저장된 소스코드들 중 텍스트들을 pprint로 정렬한걸 눈으로 확인한다.3. 소스코드들을 갖고왔지만 이것들은 HTML 언어로 작성된 코드들이다.
파이썬에서 이용할 수 있는 의미있는 부분들을 보려면 Parsing 작업이 필요하다.
soup = BeaoutifulSoup(html.text, 'html.parser')
#파이썬에서 보기 좋게, 다루기 쉽게 파싱작업을 거쳐야 각 요소에 접근이 쉬워진다.
#이것을 도와주는게 beautifulsoup4 모듈이다.4. 이제 파싱작업이 끝난 데이터에서 find 함수를 통해 필요한 부분들만 추출해보자.
한단계씩 대상을 좁혀간다고 생각하면 좋다.
data1 = soup.find('div', {'class':'weather_box'})
#soup 모듈의 find 함수를 사용해서 data1에 값을 저장한다.
#매개변수에는 div 태그명과 class 라는 속성의 값이 weather_box라는 녀석을 딕셔너리로 저장하는 코드이다.
#find 함수를 사용할 때 주의할 점은 같은 웹피이지 소스코드에 같은 소스가 여러가지 있으면 맨 처음 탐색된것만 반환하고 나머지는 무시된다는 점이다.5. 이제 속성값이 weather_box에 해당하는 코드들을 data1에 저장했으니 weather_box 내부에 있는 정보들중에서 현재 주소를 추출해보자.
find_address = data1.find('span', {'class':'btn_select'}).text
print('현재 위치: '+find_address)
#data1 변수에 저장된 정보중 span 태그명과 btn_select라는 속성값을 갖고 있는 녀석을 딕셔너리로 저장하는 코드이다.6. 이후에 온도정보도 추출해보자.
find_currenttemp = data1.find('span',{'class': 'todaytemp'}).text
print('현재 온도: '+find_currenttemp+'℃')7. 미세먼지와, 초미세먼지, 오존지수를 추출할때는 조금 다른점이 있다.
개발자도구를 통해서 확인해보면 각 줄이 dd 라는 공통된 태그를 갖고있으며 클래스명이 지수에 따라 계속 변화한다. find 함수는 첫 정보만을 반환하므로 findAll 함수를 이용해야한다.
(물론 각각 한개씩 find 할 수 있지만 조금이라도 다른 방법으로 추출연습해보자.)
data2 = data1.findAll('dd')8. 이제 data2에 저장된 dd 태그 코드들 안에있는 span 태그와 num 클래스를 추출하면 총 3개의 정보를 얻을 수 있다. 첫번째 미세먼지는 인데스 [0], 두번째 초미세먼지는 [1] 라는 식으로 따로따로 추출할 수 있다.
find_dust = data2[0].find('span', {'class':'num'}).text
find_ultra_dust = data2[1].find('span', {'class':'num'}).text
find_ozone = data2[2].find('span', {'class':'num'}).text
print('현재 미세먼지: '+find_dust)
print('현재 초미세먼지: '+find_ultra_dust)
print('현재 오존지수: '+find_ozone)9. 모든 코드들을 정리해보면 이렇게 된다.
from bs4 import BeautifulSoup
from pprint import pprint
import requests
html = requests.get('https://search.naver.com/search.naver?query=날씨')
#pprint(html.text)
soup = BeautifulSoup(html.text, 'html.parser')
data1 = soup.find('div', {'class': 'weather_box'})
find_address = data1.find('span', {'class':'btn_select'}).text
print('현재 위치: '+find_address)
find_currenttemp = data1.find('span',{'class': 'todaytemp'}).text
print('현재 온도: '+find_currenttemp+'℃')
data2 = data1.findAll('dd')
find_dust = data2[0].find('span', {'class':'num'}).text
find_ultra_dust = data2[1].find('span', {'class':'num'}).text
find_ozone = data2[2].find('span', {'class':'num'}).text
print('현재 미세먼지: '+find_dust)
print('현재 초미세먼지: '+find_ultra_dust)
print('현재 오존지수: '+find_ozone)

from bs4 import beautifulsoup4
from pprint import pprint
import requests
여기 코드에서 beautifulsoup4 오타인것같아요! 맨 마지막에 코드 통합본의 내용이랑 다르네요~