Python
Deleting Elements From List
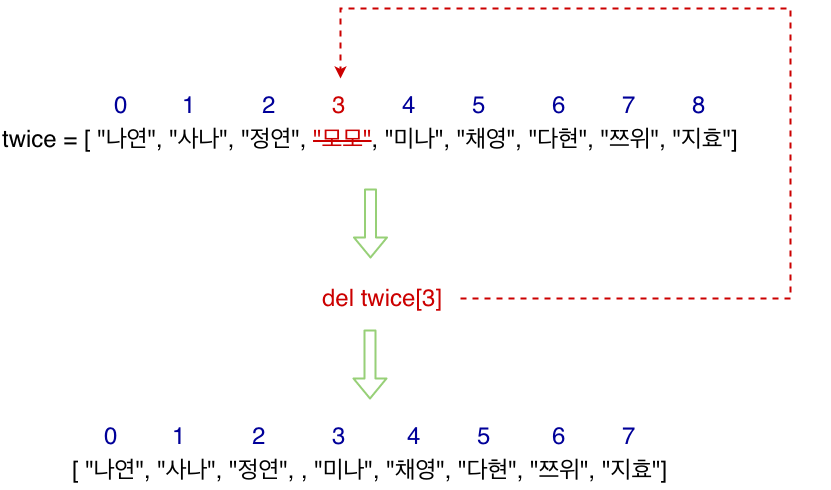
del
students = ["라이언", "튜브", "어피치", "무지", "네오", "프로도", "콘"]
#여기서 누군가를 탈퇴시키려면 del 키워드를 사용해야한다.
del students[1]
print(students)
>>> ["라이언", "어피치", "무지", "네오", "프로도", "콘"]- del 키워드와 list의 인덱스를 사용하여 원하는 요소를 리스트에서 삭제할 수 있다.
- 참고로 요소가 리스트에서 삭제되면 파이썬이 자동으로 리스트의 인덱스를 다시 정렬해준다.
remove
- del 키워드는 요소를 리스트에서 삭제하지만 단점은 인덱스를 사용해야된다는 점이다.
- 인덱스를 사용하기 불편할 때 remove를 사용하면 된다.
students.remove("라이언")- del과 다르게 remove는 리스트의 메소드(method)인데, 삭제하고자하는 요소의 값을 입력해서 삭제할 수 있다.
#Input으로 주어진 리스트에서 홀수는 전부 지우고 짝수만 남은 리스트를 리턴해주세요. 리스트의 요소들은 전부 숫자값이고 총 요소 수는 5개 입니다.
#예를 들어, 다음과 같은 listrk input으로 주어졌다면:
#[1, 2, 3, 4, 5]
#다음과 같은 결과물이 리턴되어야 합니다.
#[2, 4]
def remove_odd_numbers(numbers):
if(numbers[4] % 2 != 0):
del numbers[4]
if(numbers[3] % 2 != 0):
del numbers[3]
if(numbers[2] % 2 != 0):
del numbers[2]
if(numbers[1] % 2 != 0):
del numbers[1]
if(numbers[0] % 2 != 0):
del numbers[0]
return numbers
#앞에서부터 지우면 인덱스가 엉클어지기에 뒤에서부터 지워봤다.
#elif를 안 쓴 이유는 elif를 쓰게된다면 elif 조건문이 만족할 시 코드를 실행시키고 조건문을 빠져나가기 때문에, 그 이후것들을 비교할 수 없기때문이다.Tuples
- tuple은 list와 비슷하게 요소들을 저장할 때 쓰인다. 기본적으로 list와 동일하지만 한 번 선언되면 수정이 불가능하다는 특징을 지니고 있다.
my_tuple = (1, 2, 3)- 선언은 리스트와 다르게 일반 괄호를 사용한다는 점이다.
- 그외에 요소를 읽는 방법이나 slicing은 모두 리스트와 같다.
When to use tuples
- 튜플과 리스트는 굉장히 유사한데 차이점때문에 특정한 상황에 사용되곤 한다.
- 일반적으로 2개에서 5개 사이의 요소들을 저장할 때 사용되며, 특정 데이터를 ad hoc(즉석적으로)하게 표현하고 싶을때 사용된다.
- A = (4, 4) / B = (5, 2) / C = (-2, 2) / D = (-3, -4)
- 이런 데이터들을 표현할 때 리스트와 같이 사용된다.
- coords = [(4, 4), (5, 2), (-2, 2), (-3, -4)]
- 물론 리스트로도 표현할 수 있지만, 리스트는 수정이 가능하고 튜플보다 차지하는 메모리 용량이 크다. 더 많은 기능과 flexibility를 제공하기 때문에 어쩔 수 점이다. 튜플은 제한적인만큼 용량이 더 적기에 간단한 형태의 데이터를 표현할 때는 튜플이 훨씬 효과적이다.
#Input으로 주어진 list를 3개의 tuples로 구성된 리스트로 변환하여 리턴해주세요.
#Input 리스트는 정확히 6개의 요소를 가지고 있습니다.
# My Solution
def convert_list_to_list_of_tuples(my_list):
last_list = [(my_list[:2][0], my_list[:2][1]), (my_list[2:4][0], my_list[2:4][1]), (my_list[4:][0], my_list[4:][1])]
return last_list
# input받은 리스트를 슬라이싱하고 슬라이싱한 리스트의 요소를 튜플로 감싸준 뒤, 리스트로 다시 감싸줬다.
# 쓸데없이 길어진거 같은 느낌이다.Set
- set은 list의 친척이다. 여러 다양한 타입의 요소들을 저장할 수 있다. 하지만 list와 다른 점이 있기에 알아둬야한다.
- list와 다르게 요소들이 순서대로 저장되어 있찌 않다. ordering이 없으므로, for문에서 읽어들일 때 요소들이 순서대로 나오는게 아니라 무작위 순서대로 나온다.
- 순서가 없으므로 indexing도 없다. 몇 번째 요솓를 읽어들이거나 할 수 없다.
- 동일한 값을 가지고 있는 요소가 1개 이상 존재 할 수 없다. 즉, 중복된 값을 저장할 수 없으므로, 새로 저장하려고 하는 요소와 동일한 값의 요소가 존재하면 새로운 요소가 이 전 요소를 치환(replace)합니다.
set 생성법
- set을 생성하는 방법은 중괄호({})를 사용하는 방법과 set()함수를 사용하는 방법이 있다.
set1 = {1, 2, 3}
set2 = set([1, 2, 3])- 보시다시피 set()함수를 사용해서 set을 만들려면 list를 parameter로 전달해야한다.
- 그러므로 set() 함수로 set을 만드는 경우는 list를 set으로 변환하고 싶을 때 사용한다.
set1 = {1, 2, 3, 1}
print(set1)
>>> {1, 2, 3}- set은 중복된 값이 안되므로 맨 나중에 저장되는 요소만 남아있게 된다.
set에 새로운 요소 추가하기
- list는 순서가 있기에 append라는 함수를 사용해서 새로운 요소를 추가하기에 좋았다.
- set은 순서가 없기에 add라는 함수를 사용해서 추가하게된다.
my_set = {1, 2, 3}
my_set.add(4)
print(my_set)
>>> {1, 2, 3, 4}set에서 요소 삭제하기
- set 요소를 삭제할때는 remove 함수를 사용해서 삭제하게된다.
my_set = {1, 2, 3}
my_set.remove(3)
print(my_set)
>>> {1, 2}Look Up
- set에 어떠한 값이 포함되어 있는지 알아보는 것은 look up 이라고 한다.
- set에서 look up을 하기 위해서 in 키워드를 사용한다.
my_set = {1, 2, 3}
if 1 in my_set:
print("1 is in the set")
>>> 1 in in the setIntersection(교집합) & Union(합집합)
- set은 교집합과 합집합을 구할때도 사용될 수 있다.
- 교집합은 &키워드 혹은 intersection 함수를 사용한다.
set1 = {1, 2, 3, 4, 5, 6}
set2 = {4 ,5, 6, 7, 8, 9}
print(set1 & set2)
>>> {4, 5, 6,}
print(set1.intersection(set2))
>>> {4, 5, 6}- 합집합은 | 키워드 혹은 union 함수를 사용한다.
print (set1 | set2)
>>> {1, 2, 3, 4, 5, 6, 7, 8, 9}
print(set1.union(set2))
>>> {1, 2, 3, 4, 5, 6, 7, 8, 9}왼쪽 상단의 get_unique_numbers_count 함수를 구현해주세요.
get_unique_numbers_count 함수는 numbers 라는 parameter를 받습니다.
numbers는 list 입니다. Numbers의 고유 값들의 수를 리턴해주면 됩니다.
예를 들어, 다음과 같은 input이 들어왔다면:
[1, 2, 1, 1, 3, 4, 5]
5를 리턴해주면 됩니다.
# MY Solution
def get_unique_numbers_count(numbers):
return len(set(numbers))
# numbers는 리스트 이므로 set 함수로 set으로 바꿔주는데, 이때 자동적으로 중복 요소들은 replacing된다.
# 그 후에 이전에 배웠던대로 len 함수로 길이를 리턴해줬다.Dictionary
my_dic = {"key1" : "value1" , "key2" : "value2"}- 중괄호를 사용해서 dictionary를 선언한다.
- key와 value 값으로 이뤄져있는데, key값이 먼저 오고 : 가 위치한 다음에 value값이 온다.
- 각각의 key: value 들은 comma로 구분한다.
dictionary에서 요소(element) 읽어들이기
- dictionary에서 요소 읽기는 list와 유사하다. 차이점은 index가 아니라 key 값을 사용한다는 점이다.
- my_dic["key1"]
- dictionary에서 key와 관련하여 기억해야될 사항이 있다.
- key는 string뿐만 아니라 숫자도 가능하다
- key 값은 중복될 수 없다.
- 만약 이미 존재하는 key값이 또 추가되면 기존의 key값의 요소를 치환하게 된다.
dict1 = {1 : "one", 1: "two"}
ptinr(dict1)
>>> {1 : "two"}dictionary에서 새로운 요소(element) 추가하기
- dictionary에서 새로운 요소를 추가하는 문법은 다음과 같다.
- dictionary_name[new_key] = new_value
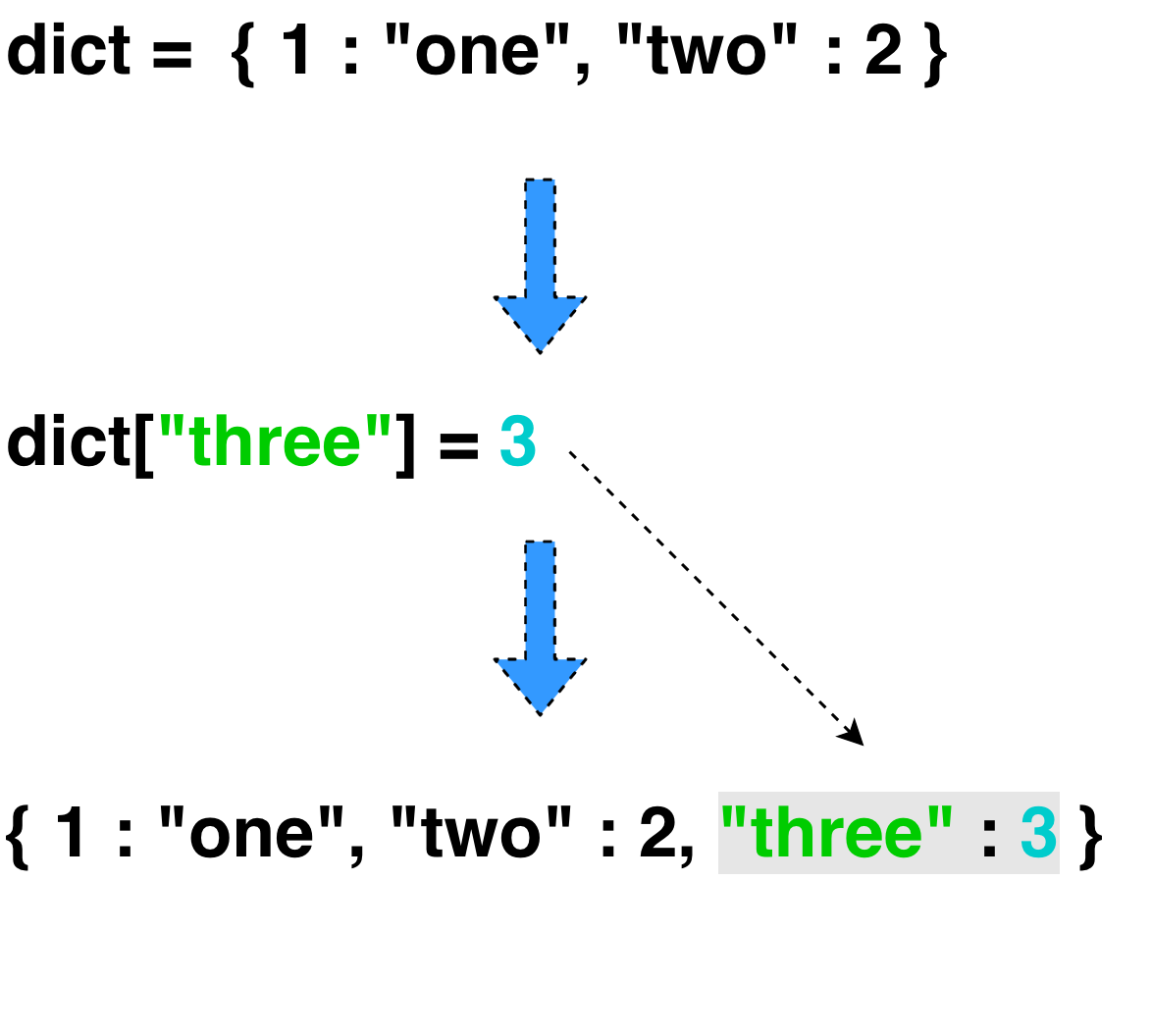
- 여기서 조심해야될건 값이 동일한 key가 존재하면 새로 추가되는 요소가 그 전의 요소를 치환한다는 점이다.
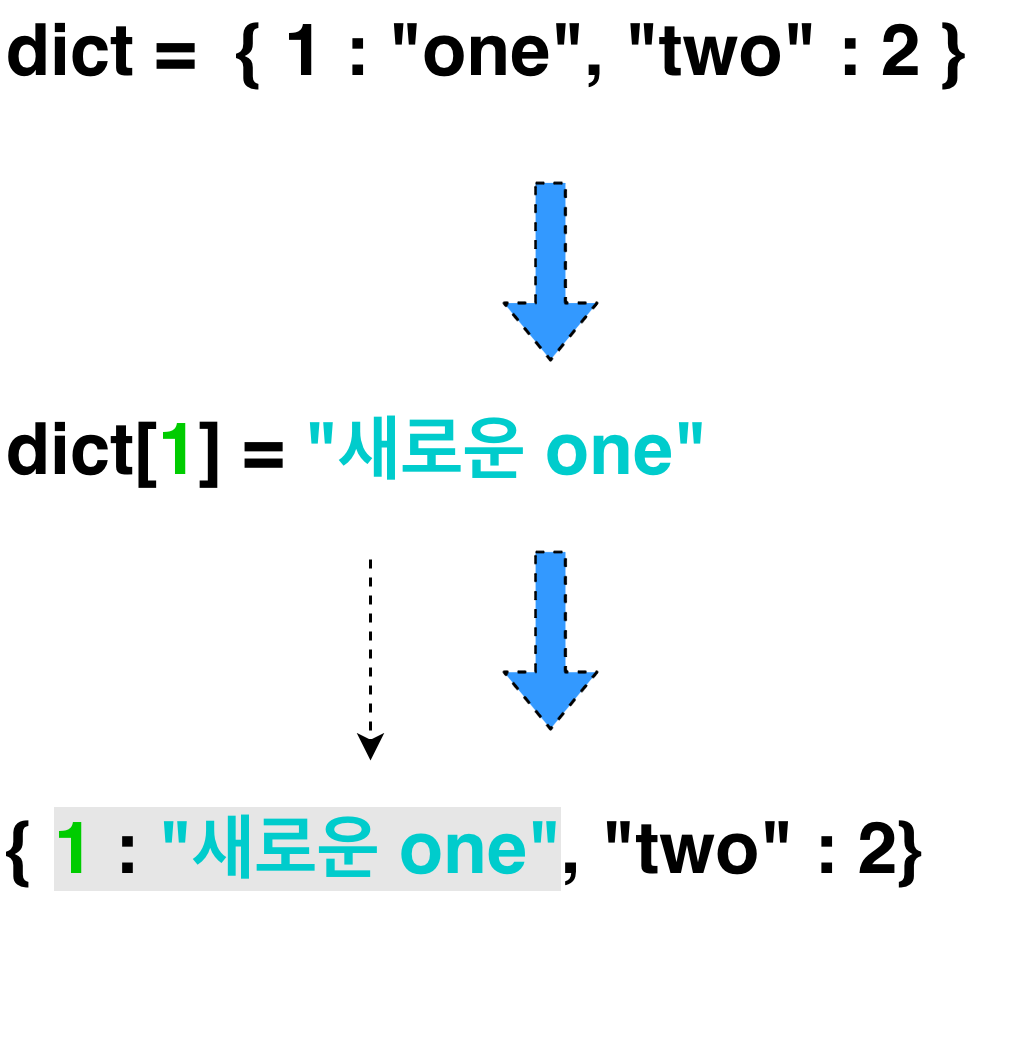
dictionary에서 요소 수정하기
- dictionary에서 요소 수정하기도 list와 유사하다. 차이점은 index가 아니라 key값을 사용한다는 점이다.
my_dict = { "one": 1, 2: "two", 3 : "three" }
my_dict["four"] = 4
print(my_dict)
> {'one': 1, 2: 'two', 3: 'three', 'four': 4}- 처음부터 비어있는 dictionary를 만든 다음에 하나씩 추가해 나가는 것도 가능하다.
my_dict = { }
my_dict[1] = "one"
my_dict[2] = "two"
> {1: 'one', 2: 'two'}dictionary에서 요소 삭제하기
- 역시나 list와 유사하지만 이것도 key값을 사용한다.
my_dict = { "one": 1, 2: "two", 3 : "three" }
del my_dict["one"]
print(my_dict)
> {2: 'two', 3: 'three'}BTS 멤버중 하나인 "지민"의 다음 사항들을 인터넷 검색을 통해서 찾으셔서 dictionary로 구현하여 출력해주세요:
가명
본명
생년월일
출생지
포지션
학력
힌트: 다음 링크를 참고하시면 위의 정보들을 찾을 수 있습니다.
# My Solution
chimmy = {
"가명":"지민",
"본명":"박지민",
"생년원일":"1995년 10월 13일",
"출생지":"대한민국 부산광역시 금정수 금사동",
"포지션":"리드 보컬, 메인 댄서",
"학력":"글로벌사이버대학교(재학)"
}
print(chimmy)For Loops
- for 구문은 list(혹은 다른 자료 구조)의 요소를 한 번에 하나씩 가지고 원하는 로직을 실행할 수 있게 해주는 역할을 한다.
- for 구문의 문법은 다음과 같다.
for element in list:
do_something_with_element- List의 요소를 한 번에 한개씩 가지고 for 구문 안에 있는 코드를 실행하게 된다.
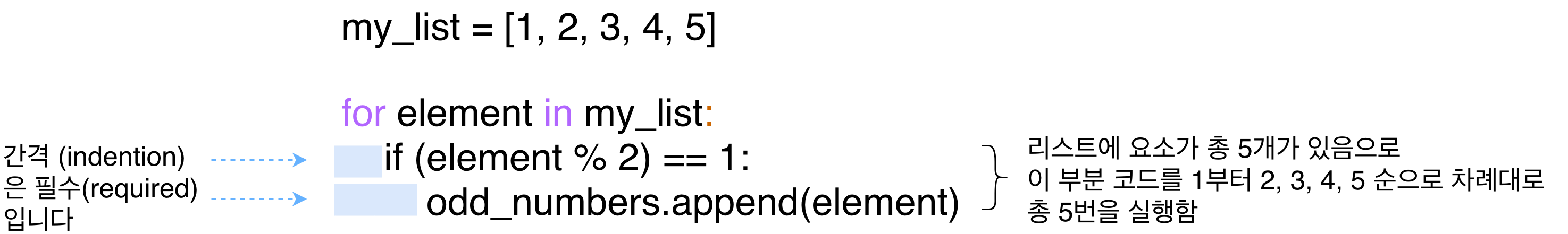
- foransdms list뿐만 아니라 tuple, set 등 다른 자료구조와도 사용할 수 있다.
break
- for 구문은 리스트가 가지고 있는 요소의 수 만큼 for 구문에 속해있는 코드를 실행한다. 이런걸 iteration이라고 하는데, 리스트가 5개의 요소를 갖고 있다면 5 interations 라고 한다.
- 그런데 중간에 끝내버리고 싶을때 있을텐데, 그럴때는 break문을 사용할 수 있다.
- break 문이 실행되면 다음 interation으로 넘어가지 않고 for 구문에서 빠져나가게 된다.

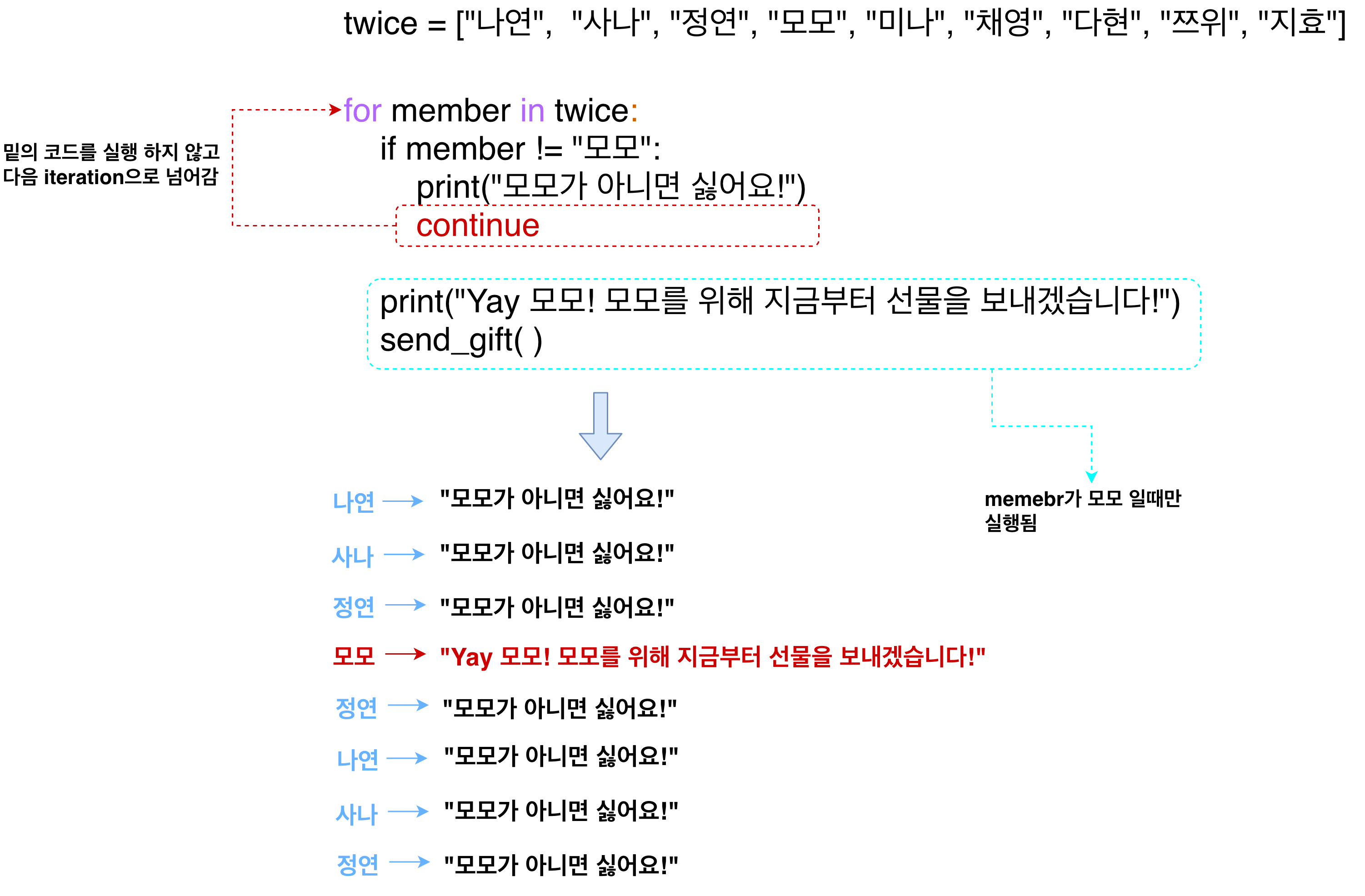
continue
- break 처럼 for 구문에서 빠져나오고 싶지는 않지만 다음 요소, 즉 다음 interation으로 넘어가고 싶을 때는 continue문을 사용하면 된다.
Nested for loops
- if 구문과 마찬가지로 for 구문도 nesting이 가능하다.
numbers1 = [1, 2, 3, 4, 5]
numbers2 = [10, 20, 30, 40, 50]
for num1 in numbers1:
for num2 in numbers2:
print(f"{num1} * {num2} == {num1 * num2}")Input 으로 주어진 리스트에서 오직 한번만 나타나는 값 (unique value)을 가지고 있는 요소는 출력해주세요.
예를 들어, 다음과 같은 리스트가 주어졌다면:
[1, 2, 3, 4, 5, 1, 2, 3, 7, 9, 9, 7]
다음과 같이 출력되어야 합니다.
4
5
# My Solution
my_list = [s for s in input().split()]
new_list = []
for i in my_list:
if i not in new_list:
new_list.append(i)
elif i in new_list:
new_list.remove(i)
print(new_list)
# 새로운 리스트를 작성한 후 input된 my_list의 값 중 new_list에 없는건 추가하고, 있는건 제거해버린다.
# 1을 넣고 또 1이 나오면 같이 저장되있던 1도 지워버린다.
## 뭔가 만족스럽지 않고 때려박다가 맞춘 느낌이라서 애매하다.While Loops
- for 구문말고도 while 반복구문이 있다.
- for문은 list나 set, dictionary 같은 data structure 등을 기반으로 코드블럭을 반복실행한다. 그러나 가끔 list 같은 data structure 기반이 아니라도 코드블록을 반복해야 할 때가 있는데, 이럴때 while 구문이 사용된다.
- while 구문은 특정조건이 True 일동안 코드블럭을 반복실행한다.
while <조건문>:
<수행할 문장1>
<수행할 문장2>
<수행할 문장3>
...
<수행할 문장N>break & continue
- for문과 마찬가지로 while문도 break과 continue가 있다.
- for문과 마찬가지로 break문은 while 문을 강제종료, continue문은 다음 iteration으로 넘어간다.
number = 0
while number <= 10:
if number == 9:
break
elif number <= 5:
number += 1
continue
else:
print(number)
number += 1
> 6
7
8while else
- 파이썬 while 문은 else문이 추가될 수 있다.
- if문은 else 문이 if문 조건이 False이면 실행되었었는데, while문도 while 조건문이 False 이면 실행된다.
- 즉, while문이 종료되면 else문이 실행된다는 의미이다.
while <조건문>:
<수행할 문장1>
<수행할 문장2>
<수행할 문장3>
...
<수행할 문장N>
else:
<while문이 종료된 후 수행할 문장1>
<while문이 종료된 후 수행할 문장2>
<while문이 종료된 후 수행할 문장3>
...
<while문이 종료된 후 수행할 문장N>find_smallest_integer_divisor 라는 이름의 함수를 구현해 주세요.
find_smallest_integer_divisor 함수는 하나의 parameter를 받습니다.
Parameter 값은 integer만 주어집니다.
find_smallest_integer_divisor 주어진 parameter 값을 정수로 나눌 수 있는 최소한의 수를 리턴하여야 합니다.
예제:
find_smallest_integer_divisor(15) == 3
# My Solution
def find_smallest_integer_divisor(numb):
n = 2
while numb % n != 0:
n += 1
return n
# n 을 2로 설정하고 input 받은 numb를 n으로 나눠봤을 때 0이 나오면 바로 리턴, 아니면 n에 1을 더해서 계속해서 반복시킨다.Looping Dictionary
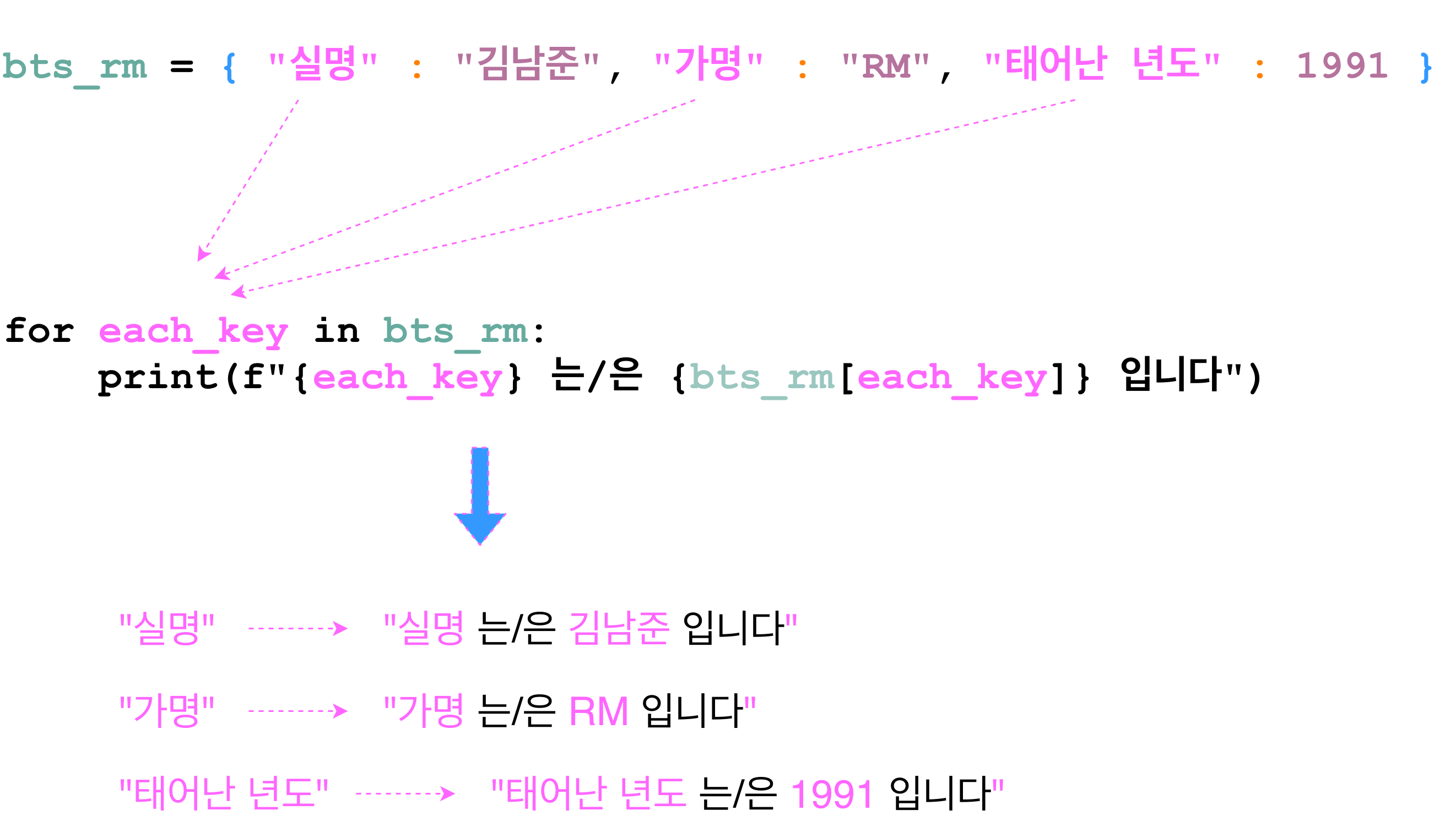
- list와 마찬가지로 dictionary도 for 반복구문을 사용하여 요소 하나하나를 가지고 반복으로 로직을 실행 시킬 수 있다. 다만 list와 다르게 dictionary는 각 요소가 key와 value로 이루어져 있다.
- 그러므로 dictionary를 사용한 for 구문에서는 각 요소의 key만 리턴을 한다.
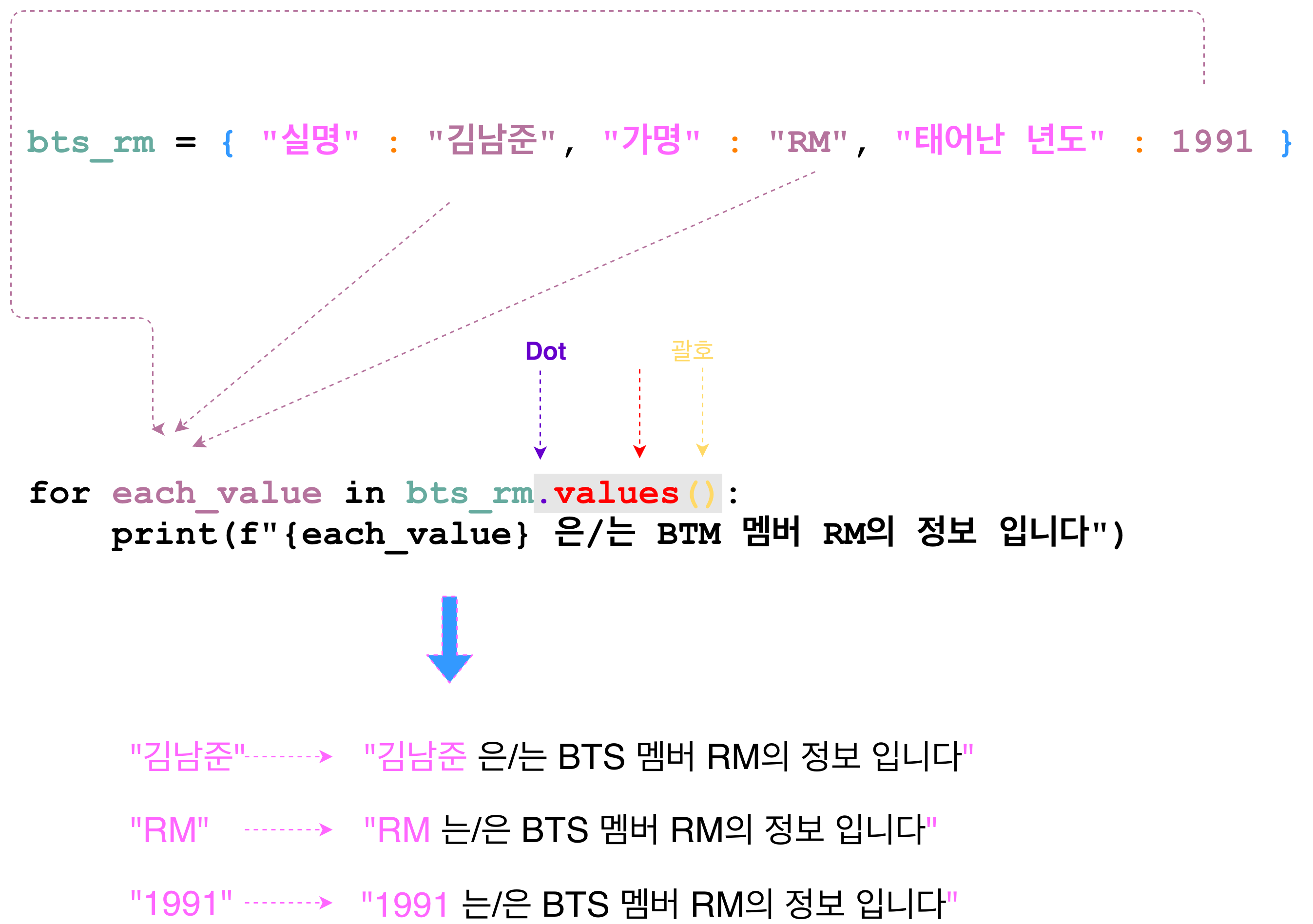
looping dictionary with values instead of keys
- 키 값 말고 value 값으로 처음부터 looping하는 방법도 있다.
- dictionary는 values 라는 함수를 속성으로 가지고 있는데, 이 values 함수는 dictionary의 value 들을 리턴해준다.
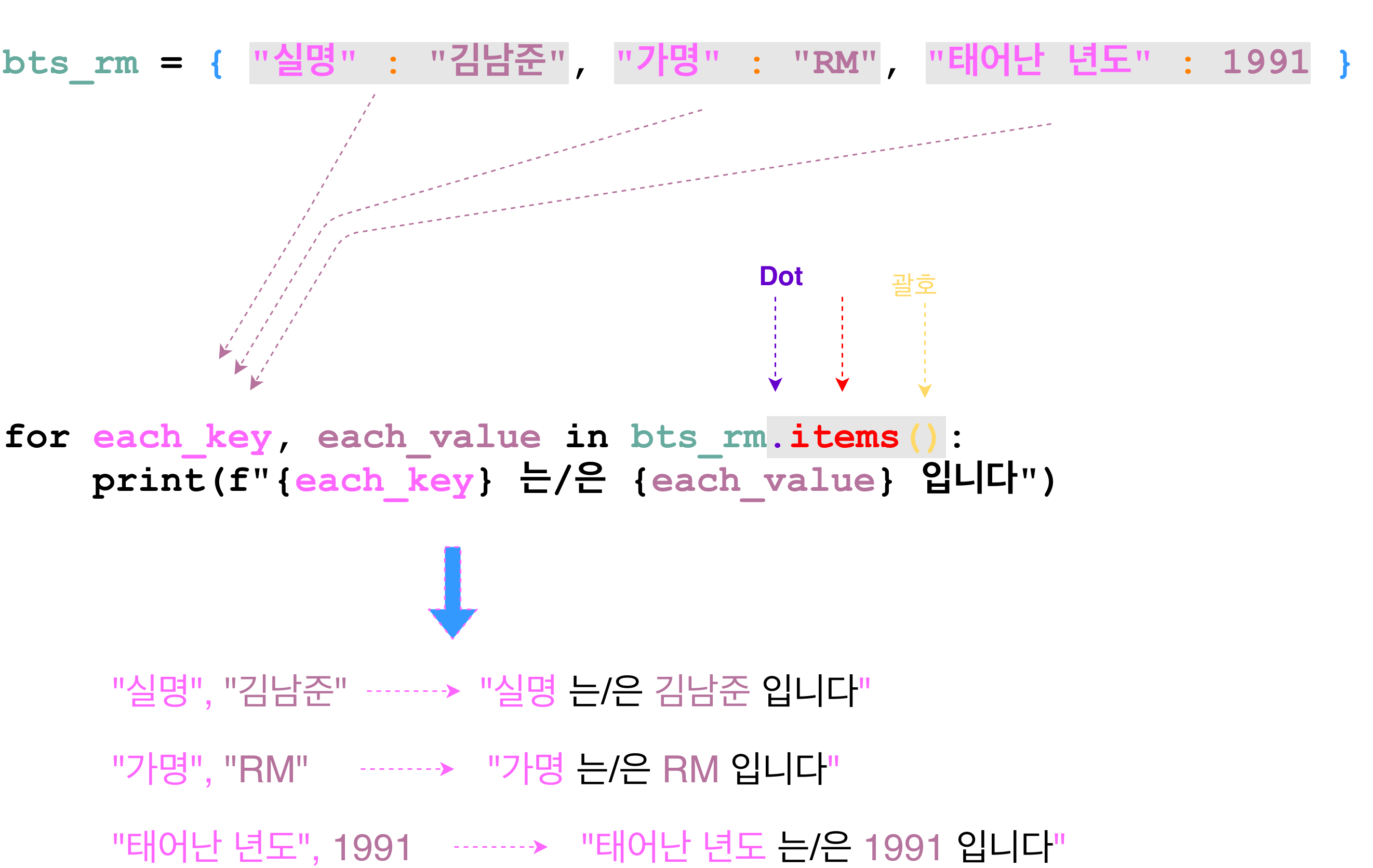
looping dictionary with both keys and values
- key와 value 값 전부를 가지고 for문 실행하는 것도 가능하다.
- 그러기위해서는 items라는 함수를 사용해야 한다. dictionray의 items 함수는 key와 value를 tuple로 리턴해준다.
Input으로 주어진 list의 각 요소(element)가 해당 list에 몇번 나타나는지 수를 dictionary로 만들어서 리턴해주세요. Dictionary의 key는 list의 요소 값이며 value는 해당 요소의 출 빈도수 입니다.
예를 들어, 다음과 같은 list가 input으로 주어졌다면:
my_list = ["one", 2, 3, 2, "one"]
다음과 같은 dictionary가 리턴되어야 합니다.
{
"one" : 2,
2 : 2,
3: 1
}
# My Solution
def get_occurrence_count(my_list):
new_dict = {}
for each_key in my_list:
if each_key in new_dict:
new_dict[each_key] = new_dict[each_key] + 1
else:
new_dict[each_key] = 1
return new_dict
# 먼저 빈 딕셔너리를 만들어준다.
# each_key는 my_list 값을 하나씩 꺼내서 저장되는 변수이다.
# if문에 in 키워드를 쓰면 each_key 변수에 담겨진 값이 new_dict 딕셔너리에 있는지 look up 해준다.
# new_dict[each_key] 가 의미하는 건 new_dict 딕셔너리의 each_key 라는 키값을 지닌 value 값을 말한다. each_key가 이미 있다면 value 값에 + 1 해준다.
# 만약 look up 했는데 False 라면 중복되지 않고 처음 들어온 수라는 의미이므로, value 값은 1이 된다.Complex Dictionary
list of dictionary
- list를 dictionary로 구성하면 손쉽게 여러 dictionary를 grouping 할 수 있다.
- 거기에 for 구문을 사용하면 각각의 dictionary들을 읽어들이고 원하는 로직을 실행할 수 있다.
bts = [
{
"실명" : "김남준",
"가명" : "RM",
"생년월일" : "1994년 9월 12일",
"출생지" : "대한민국 서울특별시 동작구 상도동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "리더 · 메인 래퍼"
},
{
"실명" : "김석진",
"가명" : "진",
"생년월일" : "1992년 12월 4일",
"출생지" : "대한민국 경기도 과천시",
"학력" : "한양사이버대학교 대학원",
"포지션" : "서브 보컬"
},
{
"실명" : "민윤기",
"가명" : "슈가",
"생년월일" : "1993년 3월 9일",
"출생지" : "대한민국 대구광역시 북구 태전동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "리드 래퍼"
},
{
"실명" : "정호석",
"가명" : "제이홉",
"생년월일" : "1994년 2월 18일",
"출생지" : "대한민국 광주광역시 북구 일곡동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "서브 래퍼 · 메인 댄서"
},
{
"실명" : "박지민",
"가명" : "지민",
"생년월일" : "1995년 10월 13일",
"출생지" : "대한민국 부산광역시 금정구 금사동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "리드 보컬 · 메인 댄서"
},
{
"실명" : "김태형",
"가명" : "뷔",
"생년월일" : "1995년 12월 30일",
"출생지" : "대한민국 대구광역시 서구 비산동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "서브 보컬"
},
{
"실명" : "전정국",
"가명" : "정국",
"생년월일" : "1997년 9월 1일",
"출생지" : "대한민국 부산광역시 북구 만덕동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "메인 보컬 · 서브 래퍼 · 리드 댄서"
}
]nested dictionary
- 특정 데이터를 읽고싶다면 dictionary 안에 dictionary를 하면 더욱 쉽게 데이터를 불러들일 수 있다.
bts = {
"RM": {
"실명" : "김남준",
"가명" : "RM",
"생년월일" : "1994년 9월 12일",
"출생지" : "대한민국 서울특별시 동작구 상도동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "리더 · 메인 래퍼"
},
"진": {
"실명" : "김석진",
"가명" : "진",
"생년월일" : "1992년 12월 4일",
"출생지" : "대한민국 경기도 과천시",
"학력" : "한양사이버대학교 대학원",
"포지션" : "서브 보컬"
},
"슈가": {
"실명" : "민윤기",
"가명" : "슈가",
"생년월일" : "1993년 3월 9일",
"출생지" : "대한민국 대구광역시 북구 태전동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "리드 래퍼"
},
"제이홉": {
"실명" : "정호석",
"가명" : "제이홉",
"생년월일" : "1994년 2월 18일",
"출생지" : "대한민국 광주광역시 북구 일곡동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "서브 래퍼 · 메인 댄서"
},
"지민": {
"실명" : "박지민",
"가명" : "지민",
"생년월일" : "1995년 10월 13일",
"출생지" : "대한민국 부산광역시 금정구 금사동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "리드 보컬 · 메인 댄서"
},
"뷔": {
"실명" : "김태형",
"가명" : "뷔",
"생년월일" : "1995년 12월 30일",
"출생지" : "대한민국 대구광역시 서구 비산동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "서브 보컬"
},
"정국": {
"실명" : "전정국",
"가명" : "정국",
"생년월일" : "1997년 9월 1일",
"출생지" : "대한민국 부산광역시 북구 만덕동",
"학력" : "글로벌사이버대학교 방송연예학과",
"포지션" : "메인 보컬 · 서브 래퍼 · 리드 댄서"
}
}
print(bts["제이홉"]["생년월일"])More Complex Function Parameters
handing unknown number of arguments
- 사전에 정확히 필요한 parameter 수와 구조를 알 수 없는 경우는 어떻게 해야할까?
- 가장 간단한 경우는 dictionary를 parameter로 받아서 사용하는 것이다.
def buy_A_car(options):
print(f"다음 사양의 자동차를 구입하십니다:")
for option in options:
print(f"{option} : {options[option]}")
options = {"seat" : "가죽", "blackbox" : "최신"}
buy_A_car(options)
> 다음 사양의 자동차를 구입하십니다:
seat : 가죽
blackbox : 최신- 이렇게 하면 원하는 옵션만 간단하게 설정 할 수 있다는 장점은 있지만 옵션을 dictionary로 받아야만 한다는 제약사항이 있습니다. 만일 옵션을 하나도 추가 안하고 기본사양으로 사는 경우에도 비어있는 dictionary를 넘겨줘야 하는것이죠. 게다가 dictionary가 아닌 다른 타입의 값 (예를 들어 string)을 넘겨주는 오류가 생길 확률도 있습니다.
keyworded variable length of arguments
- 그래서 파이썬에는 keyworded variable length of arguments 기능이 있다.
- 이름 그대로 keword argument 인데 그 수가 정해지지 않고 유동적으로 변할 수 있다.
- keyworded variable length of arguments를 선언하기 위해서는 parameter 이름 앞에 ** 로 시작해야 한다.
- 그리고 일반적인 keyword argument와 다른점이 있다.
- argument 수를 0부터 n까지 유동적으로 넘겨줄 수 있다.
- keyword가 미리 정해져있지 않기때문에 원하는 keyword를 유동적으로 사용할 수 있다.
- keyworded variable length of arguments는 dictionary 형태로 지정된다.
- keyworded variable length of arguments 를 사용할 때 일반적으로 argument 이름을 kwargs라고 짓는다. 그래서 대부분 **kwargs 라고 parameter 이름을 정한다.
- keyworded variable length of arguments 가 dictionary로 지정된다고 했는데, 이 부분이 혼동될 수 있으니 예를 들어보자.
#다음과 같이 선언된 함수가 있다고 해보자.
def buy_A_car(**kwargs):
print(f"다음 사양의 자동차를 구입하십니다:")
for option in kwargs:
print(f"{option} : {kwargs[option]}")
# 호출을 할 때는 다음 처럼 호출 할 수 있다.
buy_A_car(seat="가죽", blackbox="최신", tint="yes")
# 그러면 kwargs 파라미터는 다음과 같은 dictionary로 함수에 전해지게 된다.
{'seat': '가죽', 'blackbox': '최신', 'tint': 'yes'}
# 그러므로 함수 body 안에서는 dictionary를 사용하듯이 kwargs를 사용하면 된다.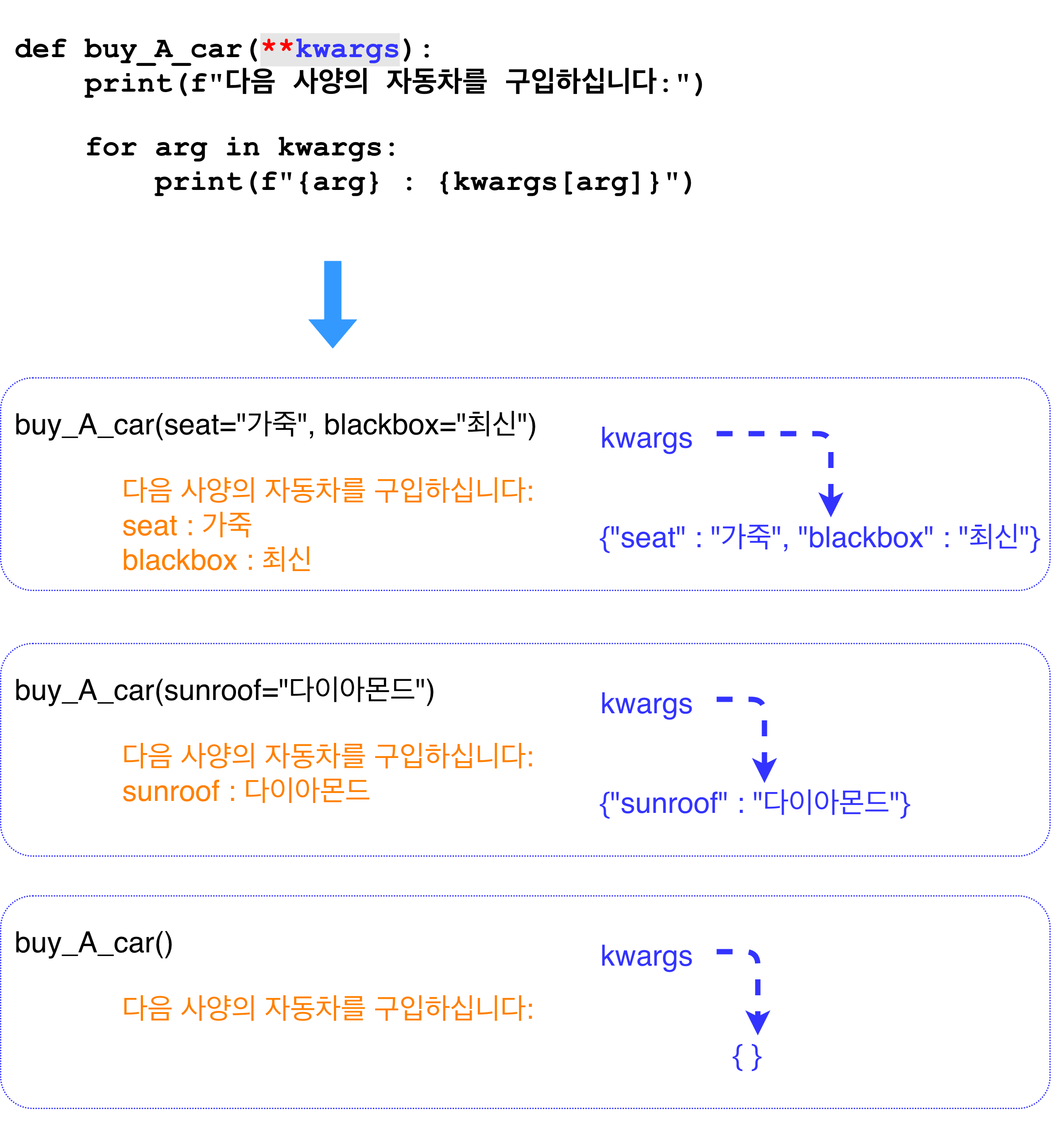
non-keyworded variable length of arguments
- keyworded variable length of arguments 와 동일하지만 keyword를 사용하지 않고 순서대로 값을 전달하는 방식도 가능하다. 그걸 non-keyworded variable length of arguments이라고 하거나 그냥 variable length of arguments 라고 한다. 더 간단하게 variable arguments 라고 하기도 한다.
- variable arguments 를 선언하는 방법은 별표 2개 대신에 1개를 사용해서 선언한다. 그리고 이 variable arguments 는 tuple로 변환되어 함수에 전달된다.
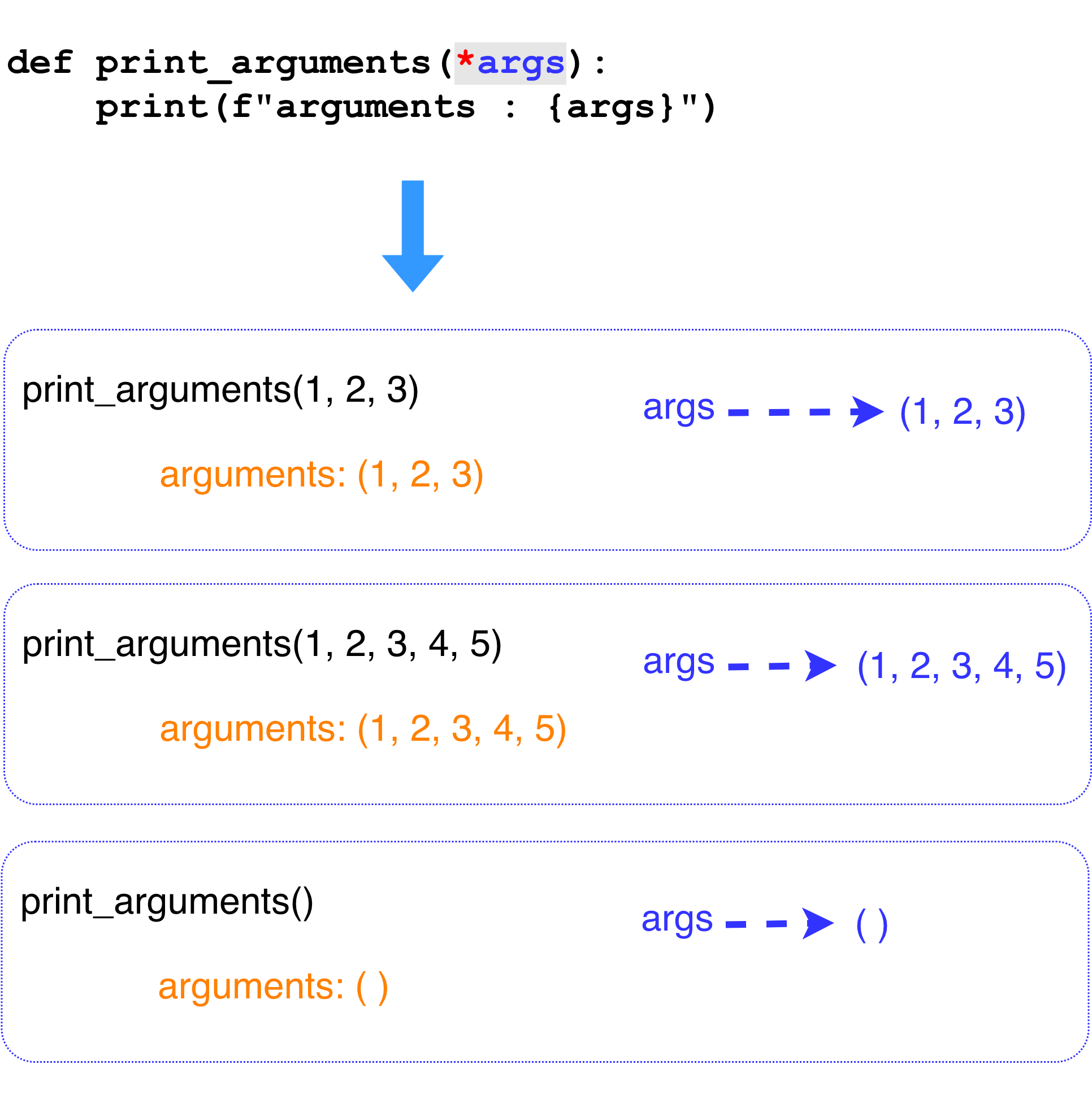
mixing args and kwargs
- Variable arguments와 keyworded variable arguments 둘 다 사용하여 함수를 정의할 수 도 있다.
def do_something(*args, **kwargs):
## some code here...
....- 그렇다면 왜 둘 다 사용할까? 그 이유는 어떠한 형태와 수의 argument도 허용 가능한 함수가 되기 때문이다. 즉, parameter에 있어서 굉장히 유동적인 함수가 된다는 의미이다.
do_something(1, 2, 3, name="정우성", age=45)
do_something(1, 2, 3, 4, 5, "hello", {"주소" : "서울", "국가" : "한국"})
do_something(name="정우성", gender="남", height="187")
do_something(1)
do_something()함수 2개를 구현해주세요. 함수의 이름은 다음과 같아야 합니다.
sum_of_numbers
what_is_my_full_name
함수 sum_of_numbers는 arugment로 주어지는 모든 수를 합한 값을 리턴해야 합니다.
예를 들어, sum_of_numbers(1, 2, 3, 4, 5) 는 15를 리턴해야 하고 sum_of_numbers(1,2)는 3을 리턴해야 합니다.
만일 parameter가 주어지지 않으면 0을 리턴해야 합니다.
what_is_my_full_name 함수는 주어진 parameter중 first_name 과 last_name 이라는 parameter를 조합하여 full name을 리턴해주어야 합니다.
예를 들어, first_name이 "우성" 이고 last_name 이 "정" 이면 "정 우성" 라고 리턴하면 됩니다.
Last name과 first name 사이에 space(빈칸)이 들어가 있어야 합니다.
만일 last_name이 없거나 first_name이 없으면 둘 중하나만 리턴하면 됩니다.
예를 들어, last_name이 없으면 "우성" 이라고 이름만 리턴하면 됩니다,
마지막으로, last_name과 first_name 둘다 없으면 "Nobody" 라고 리턴하면 됩니다.
# My Solution
def sum_of_numbers(*args):
sum = 0
if args == 0:
return 0
for i in args:
sum += i
return sum
#
def what_is_my_full_name(**kwargs):
if "first_name" in kwargs and "last_name" in kwargs:
return f"""{kwargs["last_name"]} {kwargs["first_name"]}"""
elif "first_name" in kwargs and "last_name" not in kwargs:
return f"""{kwargs["first_name"]}"""
elif "first_name" not in kwargs and "last_name" in kwargs:
return f"""{kwargs["last_name"]}"""
else:
return "Nobody"
이제 막 배우기 시작한 개발자입니다.