What You Will Learn
- RDBMS란?
- TABLE이란? Column과 Row 그리고 Primary Key란?
- 테이블의 관계 , One to One, One to Many, Many to Many는 무엇인가?
- 왜 관계형 테이블을 쓰는가?
- 트랜잭션이란? ACID는 무엇인가?
- 관계형 데이터베이스 와 비관계형 데이터베이스의 차이는?
- ERD구성도로 모델링하기
Database 기초 이해 및 설치
- 데이터를 저장 및 보존 하는 시스템
- Application에서는 데이터가 메모리 상에서 존재한다. 그리고 메모리에 존재하는 데이터는 보존이 되지 않는다. 해당 애플리케이션이 종료하면 메모리에 있던 데이터들은 다시 읽어 들일 수 없다. 즉, 메모리는 데이터베이스와 반대되는 개념이다. 대신 메모리는 속도가 빠르다.(그래서 데이터베이스에 영구적으로 저장, 보존하고 메모리에서 읽어들여서 가공처리를 한다.)
- 데이터를 장기 기간동안 저장 및 보존 하기 위해서 데이터 베이스를 사용하는 것이다.
- 그렇다면 파일로 저장해도 되는데 왜 데이터베이스에 저장할까? 바로 접근 및 관리가 더 편하기 때문이다. 데이터베이스는 데이터를 편집, 가공 및 보존을 편하게 해준다.
- 일반적으로 database에는 크게 관계형 데이터베이스(RDBMS)와 "NoSQL"로 명칭되는 비관계형(Non-relational) database가 있다.
관계형 데이터베이스(RDBMS, Relational DataBase Management System)
- 이름 그대로, 관계형 데이터 모델에 기초를 둔 데이터베이스 시스템을 말한다.
- 관계형 데이터란 데이터를 서로 상호관련성을 가진 형태로 표현한 데이터를 말한다.(관계형 데이터베이스는 모든 데이터가 상호연관이 있다는 전제하에 있다.)
- 모든 데이터들은 2차원 테이블(table)들로 표현 된다.(엑셀과 비슷하다)
- 각각의 테이블은 컬럼(column)과 row(로우)로 구성된다.
- 컬럼은 테이블의 각 항목을 말한다. 행으로 생각하면 된다.
- 로우는 각 항목들의 실제 값들을 이야기 한다. 열로 생각하면 된다.
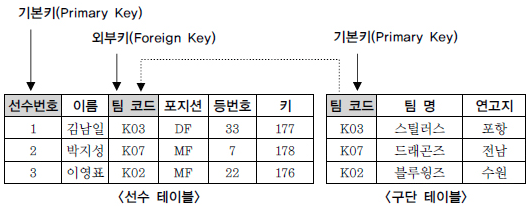
- 각 로우는 저만의 고유 키(Primary Key)가 있다. 주로 이 primary key를 통해서 해당 로우를 찾거나 인용(reference)하게 된다.
- 각각의 테이블들은 서로 상호관련성을 가지고 서로 연결될 수 있다.
- 테이블끼리의 연결에는 크게 3가지 종류가 있다.
- one to one
- one to many
- many to many
- 테이블끼리의 연결에는 크게 3가지 종류가 있다.
- 대표적인 관계형 데이터베이스에는 MySQL과 PostgreSQL(줄여서 Postgres)가 있다.
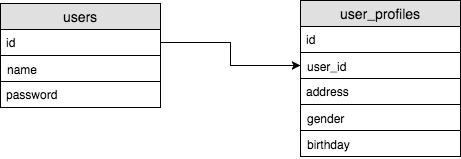
One To One
- 테이블 A의 로우와 테이블 B의 로우가 정확히 일대일 매칭이 되는 관계를 one to one 관계라고 한다.
- 예시에 나온 user table에 나온 하나의 user는 user profile의 부수정보를 참조한다. 이런 관계는 one-to-one 관계로, 한 명의 user는 하나의 user profile만을 갖을 수 있다.
One To Many
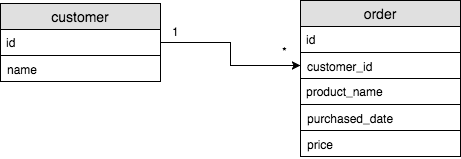
- 테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계를 one to many 관계라고 함.
각 고객은 여러 제품을 구매할 수 있지만 구매된 제품의 주인은 오직 한 고객뿐이다. (one to many) - 하나의 정보를 여러개의 데이터가 연결관계를 가질 수 있다는 걸 나타낸다.
- 해당 예시는 고객이 여러번의 주문을 할 수 있듯, 주문은 여러개가 생성되지만 그 주문을 하는 고객은 한 명뿐이다. 하나의 주체가 여러개의 상태값을 갖는다.
- 다른 예로는 하나의 카테고리에 그에 해당하는 여러 제품이 들어있는 것도 마찬가지이다.
Many To Many
- 테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결이 되는 관계를 many to many 라고 함.
책은 여러 작가에 의해 쓰일 수 있고 작가들은 여러 책을 쓸 수 있다 (many to many) - 하나의 책에 여러명의 저자가 존재할 수 있다. 이 때는 책의 정보를 갖고 있는 book table과 저자의 정보를 가지고 있는 author table이 각각 참조되어서 중간 테이블인 authors_books 테이블에 저장된다. authors_books의 책의 id와 저자의 id를 각각 참조해온다. 이렇게 저장될 때 로우에는 책의 id와 저자의 id가 여러번 기록될 수 있다. 하나의 책의 id에 여러명의 저자의 id를 연결할 수 있다는 의미이다.

어떻게 테이블과 테이블을 연결하는가?
- Foreign key(외부키)라는 개념을 사용하세 주로 연결
- 앞서 본 one to one 예에서 user_profiles 테이블의 user_id 컬럼은 users 테이블에 걸려있는 외부 키라고 지정한다.
- 즉 데이터베이스에게 user_id의 값은 users 테이블의 id 값이며 그러므로 users 테이블의 id 컬럼에 존재하는 값만 생성될 수 있다.
- 만일 users 테이블에 없는 id 값이 user_id 에 지정되면 에러가 난다.
왜 테이블들을 연결하는가?
- 왜 정보를 여러 테이블에 나누어서 저장하는가?
- 앞서 본 one to many의 예에 경우 그냥 하나의 테이블에 고객 정보와 구입한 제품 정보 모두를 저장 하면 안되는가?
- 하나의 테이블에 모든 정보를 다 넣으면 동일한 정보들이 불필요하게 중복되어 저장된다.
- 더 많은 디스크를 사용하게 되고
- 또한, 잘못된 데이터가 저장 될 가능성이 높아진다.
- 예를 들어, 고객의 아이디는 동일한데 이름이 틀린 로우들이 있다면 어떻게 해야 하는가? 어떤 이름이 정확한건가?
- 여러 테이블에 나누어서 저장한후 필요한 테이블 끼리 연결 시키면 위의 2문제가 사라진다.
- 중복된 데이터를 저장하지 않음으로 디스크를 더 효율적으로 쓰고,
- 또한 서로 같은 데이터이지만 부분적으로 틀린 데이터가 생기는 문제가 없어진다.
- 이것을
정규화(normalization)이라고 한다.
트랜잭션(Transaction)
- ACID를 제공함으로 따라서 트랜잭션(일련의 작업들을 한번에 하나의 unit으로 실행하는것) 기능을 제공하다.
- 트랜잭션은 일련의 작업들이 마치 하나의 작업처럼 취급되어서 모두 다 성공하거나 아니면 모두 다 실패하는걸 이야기 한다.
- Commit & rollback
- 질의를 하나의 묶음 처리해서 만약 중간에 실행이 중단되면 처음부터 다시 시작하는 롤백을 수행하고 오류없이 마치면 commit을 마치는 실행단위이다. 즉, 한 번의 질의가 실행되면 질의가 모두 수행되거나 모두 수행되지 않는 작업 수행의 단위이다.
- 예를 들어 친구에게 인터넷뱅킹으로 만원을 송금하는 상황을 가정해보자. 친구에게 송금을 한다면 내 계좌에서 만원을 차감하고 친구의 계좌에 만원을 증가시켜야되는데, 이 과정에서 알 수 없는 오류로 내 계좌는 만원이 줄었지만 친구 계좌에서는 만원이 증가되지 않으면 만원은 증발된것이다. 이런 상황이 발생하지 않도록 중간에 오류가 발생하면 다시 처음부터 송금을 하도록 하는게 롤백이다. 오류없이 송금이 완료되었다면 정상적으로 실행이 끝났으니 commit을 한다.
- 트랜잭션을 작업수행의 논리적 단위라고 표현했다. 때문에 DBMS의 성능은 초당 트랙잭션 실행수로 측정한다. 이를 TPS라고 부른다.
- 트랜잭션은 DB서버에 여러개의 클라이언트가 액서스하거나 응용프로그램이 갱신을 처리하는 과정에서 중단될 수 있는 경우인 데이터 부정합을 방지하고자 사용한다.
ACID(Atomicity, Consistency, Isolation, Durability)
- 트랙잭션의 네가지 특성이다.
- 원자성, 일관성, 고립성, 지속성
원자성(Atomicity)은 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력이다.(즉, all or nothing 개념이다. 작업 단위를 일부분만 실행하지는 않는다는 것이다.) 예를 들어, 자금 이체는 성공할 수도 실패할 수도 있지만 보내는 쪽에서 돈을 빼 오는 작업만 성공하고 받는 쪽에 돈을 넣는 작업을 실패해서는 안된다. 원자성은 이와 같이 중간 단계까지 실행되고 실패하는 일이 없도록 하는 것이다.일관성(Consistency)은 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 여기서 일관성이란 데이터의 타입이나 상태가 중간과정에서 변질되지 않는것을 말한다. 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.고립성(Isolation)은 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다.(트랙잭션끼리는 서로 간섭할 수 없다.) 이것은 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다. 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다. 공식적으로 고립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다. 성능관련 이유로 인해 이 특성은 가장 유연성 있는 제약 조건이다. 자세한 내용은 관련 문서를 참조해야 한다.지속성(Durability)은 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다. 시스템 문제, DB 일관성 체크 등을 하더라도 유지되어야 함을 의미한다. 전형적으로 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.- 이 네가지 특성은 외우기보다는 이해해놓고 천천히 깊게 공부해보자.
NoSQL 데이터베이스
- 비관계형 타입의 데이터를 저장할때 주로 사용되는 데이터베이스 시스템
- 관계형 데이터베이스와 다르게 비관계형 이기 때문에 데이터들을 저장하기 전에 정의 할 필요가 없다.
- 관계형 데이터베이스는 데이터들을 저장하기 전에 어디에 어떻게 저장할것인지를 정의 해야한다.
- 즉 테이블을 정의해야함 (테이블 이름, 테이블과 다른 테이블의 관계, 각 컬럼의 타입 등등)
- 관계형 데이터베이스는 데이터들을 저장하기 전에 어디에 어떻게 저장할것인지를 정의 해야한다.
- 관계형 데이터베이스와는 다르게 스키마 즉, 관계설정에 따른 테이블 모델링이 없으므로 데이터를 저장하기전에 정형화할 필요 없다. 관계형 데이터베이스는 저장하기전에 어디 어떻게 저장할지 정의를 해야지만, 비관계형 데이터를 그럴 필요가 없다. 주로 빠른 저장이 필요하고 정형화할 시간이 없을 때 사용한다.
- MongoDB, Redis, Cassandra 등이 가장 대표적인 NoSQL 데이터 베이스이다.
SQL(RDBMS) VS NoSQL
SQL
- 장점:
- 관계형 데이터베이스는 데이터를 더 효율적으로 그리고 체계적으로 저장할 수 있고 관리 할 수 있다.
- 미리 저장하는 데이터들의 구조(테이블 스키마)를 정의함으로 데이터의 완전성이 보장된다.
- 트랜잭션(transaction)를 통해 안정적인 작업이 가능하다.
- 단점:
- 테이블을 미리 정의해야 함으로 테이블 구조 변화 등에 덜 유연한다.
- 확장성이 쉽지 않다.
- 역시 테이블 구조가 미리 정의 되어 있다보니 단순히 서버를 늘리는것 만으로 확장하기가 쉽지 않고 서버의 성능 자체도 높여야 한다.
- 서버를 늘려서 분산 저장 하는것도 쉽지 않다.
- Scale up (서버의 성능을 높이는것)으로 확장성이 됨.
- 정형화된 데이터들 그리고 데이터의 완전성이 중요한 데이터들을 저장하는데 유리하다.
- 예) 전자상거래 정보. 은행 계좌 정보, 거래 정보 등등.
NoSQL
- 장점:
- 데이터 구조를 미리 정의하지 않아도 됨으로 저장하는 데이터의 구조 변화에 유연하다.
- 확장하기가 비교적 쉽다. 그냥 서버 수를 늘리면 됨(scale out)
- 확장하기가 쉽고 테이터의 구조도 유연하다 보니 방대한 양의 데이터를 저장하는데 유리하다.
- 단점:
- 데이터의 완전성이 덜 보장된다.
- 트랜잭션이 안되거나 비교적 불안정하다.
- 주로 비정형화 데이터 그리고 완전성이 상대적으로 덜 유리한 데이터를 저장하는데 유리하다.
- 예) 로그 데이타
1. RDBMS란?
- 2차원 테이블 형식을 이용하여 데이터를 정의하고 설명하는 데이터 모델이다. 데이터를 속성과 데이터 값으로 구조화한다. 속성과 데이터값 사이에서 관계를 찾아내고 이를 테이블 모양의 구조로 도식화하는 것이다.
2. TABLE이란? Column과 Row 그리고 Primary Key란?
- 테이블 : RDBMS에서 데이터를 테이블이라는 데이터베이스 개체에 저장한다. 테이블은 서로 관계있는 데이터 목록의 집합이며, 행(row)와 열(columns)로 구성되어 있다. 관계 데이터베이스에서 가장 단순하고 흔한 데이터 저장소의 형태이다.
- 열(column): 열은 테이블에서 특정 필드와 연관된 모든 정보를 포함하는 수직적인 독립체이다.
- 행(row): 데이터의 행이라고도 하며 한 테이블에서 각각 독립적인 데이터목록이다. 테이블에서 수평적인 개체이다.
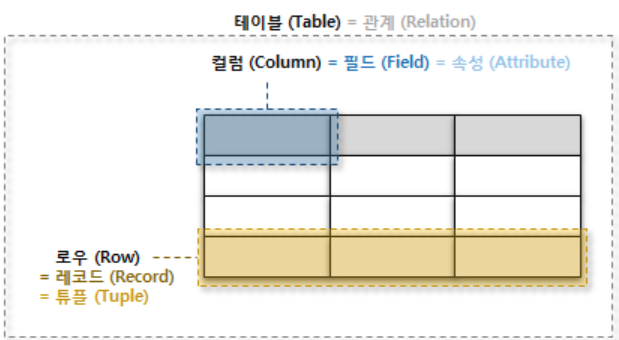
- Primary Key : 한 테이블의 각 로우를 유일하게 식별해주는 컬럼이다. 각 테이블마다 Primary Key가 존재하며 NULL값을 허용하지 않고, 각 로우마다 유일한 값이어야한다.
3. 테이블의 관계 , One to One, One to Many, Many to Many는 무엇인가?
- one to one: 테이블 A와 테이블 B의 로우가 정확히 일대일 매칭되는 관계이다.
- one to many: 테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계이다.
- many to many: 테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결이 되는 관계이다.
4. 왜 관계형 테이블을 쓰는가?
5. 트랜잭션이란? ACID는 무엇인가?
6. 관계형 데이터베이스 와 비관계형 데이터베이스의 차이는?
7. ERD구성도로 모델링하기
ERD 구성도 그리기 (Aquerytool)
https://aquerytool.com/ 에서 ERD 구성도 그리는 연습을 해볼것이다.
일단 가입을 해놓고 시작하자.
ERD를 구성하려면 새로운 ERD를 생성해야한다.
먼저 erd 버튼을 누르면 펴지는 메뉴에서 새로운 ERD 버튼을 누르자.
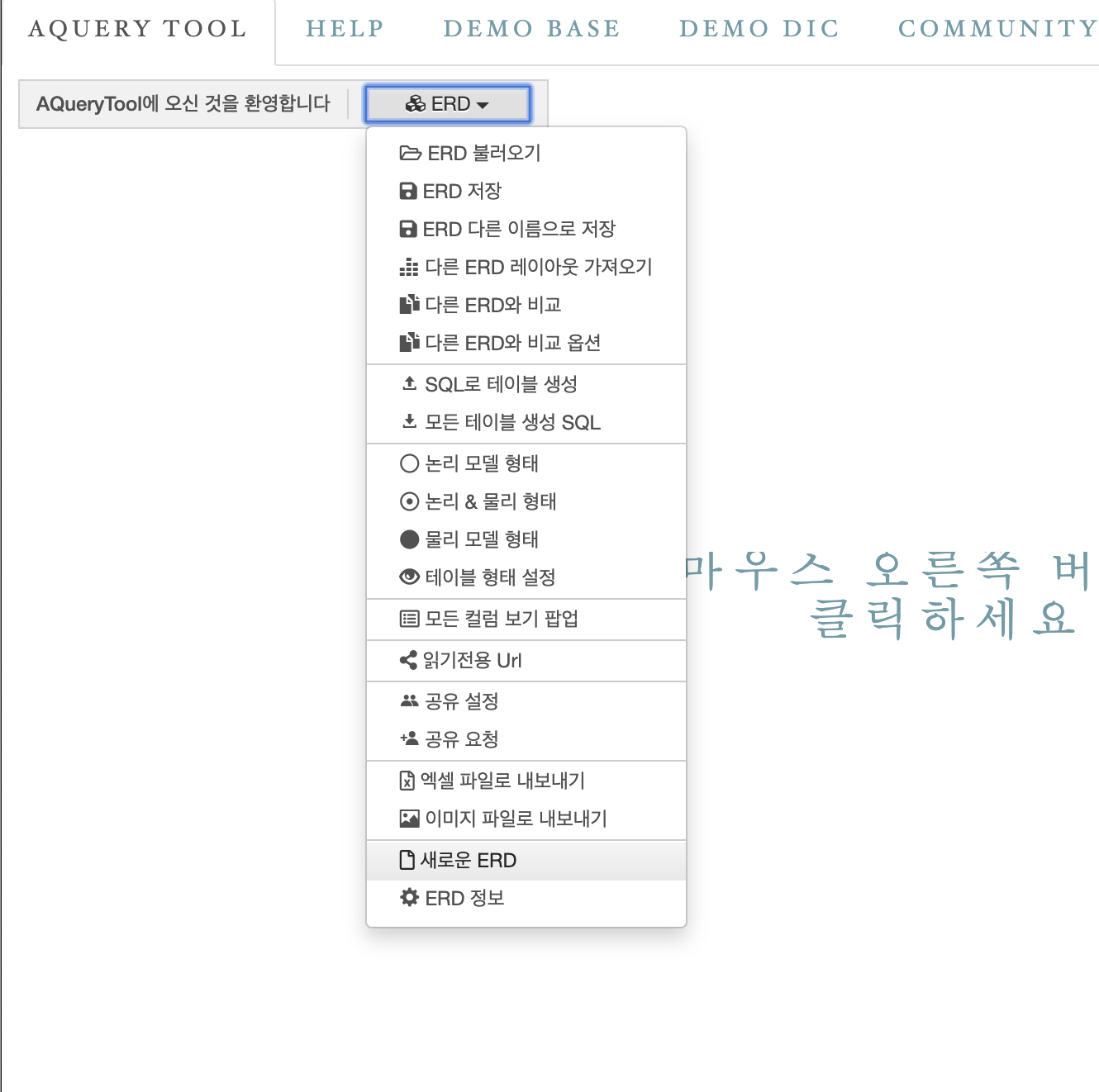
새로운 ERD를 만드는 창에서 데이터베이스 타입은 우리가 자주 사용하게될 MySQL을 선택하자.
ERD이름과 데이터베이스 이름은 아무거나 정해도 좋다.
ERD 크기는 디스플레이(창크기)에 따라 자동 조정되니 그냥 자동으로 설정되는걸 써도 된다.
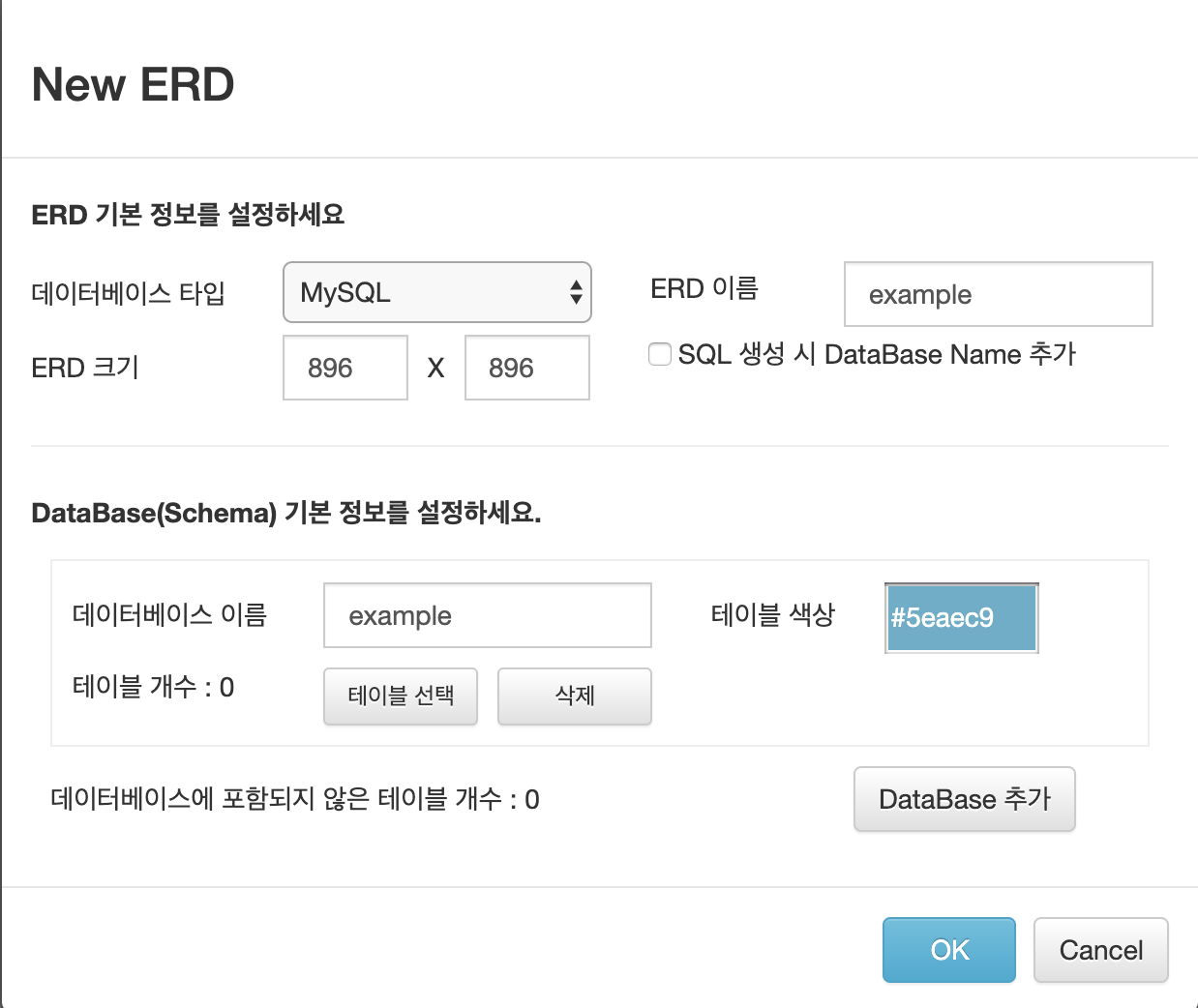
OK를 눌러도 화면이 바뀐게 없어 보이지만 MySQL 데이터베이스가 생성된것이다.
이제 화면에 오른쪽 클릭 후, 테이블 생성을 하자.
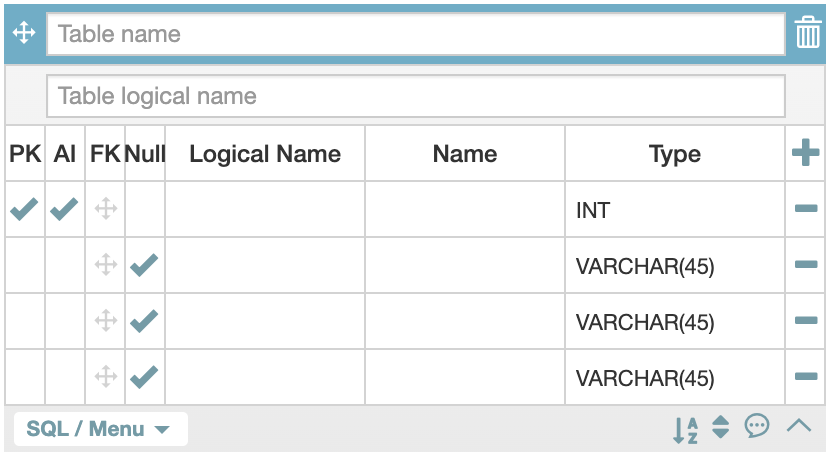
-
테이블 이름은 소문자에 복수로 줘야한다.
-
Table logical name은 말 그대로 논리적 이름인데, 테이블을 설명하거나 컬럼을 설명할 때 사용한다.
-
PK는 Primary Key의 줄임말이다.
-
AI는 Auto Increment속성을 표현한다. PK는 데이터베이스에서 자동생성되고 자동증가하도록 옵션이 되있다. 그래서 해당 요소가 현재 자동으로 체크되있는것이다.
-
FK는 바로 Foreign Key 이다. 연결관계가 주어지기 전까지는 활성화되지 않는다. FK가 있다는 것은 바로보고 싶은 방향을 바라보고 있다는 의미이다.
-
Null은 체크가 되면 널값을 허용한다는 뜻이고, 체크되있지 않으면 널이 허용되지 않는다.
-
Logical Name은 말 그대로 논리적인 이름을 작성하는 곳이다.
-
Name은 컬럼명을 정하는 곳이다. 실제로 데이터베이스에 저장되는 컬럼명이다. 보통 PK의 이름은 id 로 많이 하고 Type은 integer를 많이쓴다(INT)
-
데이터베이스에서는 string을 VARCHAR로 표현한다. 길이는 email은 200자 password는 300자정도 준다.
-
user_profile_id 는 FK로 만들것이다. 즉, user_profiles이란 테이블을 만들고서 이 컬럼을 통해서 user_profile을 참조할거란 의미이다.
-
user_profile 테이블에도 마찬가지로 테이블 이름과 PK에 name을 id로 설정해준다. profile에는 유저 필수정보 외에 추가정보를 적는곳이다. name, address, hobby 등을 줄 수 있다.(보통 gender를 한다면 별도의 테이블을 만들어서 원투원으로 만들수 있지만 지금은 생략)
-
글자수는 name은 50, address는 500, hobby는 100정도 주자. 요즘에는 부족한거보다 넉넉하게 주는게 낫다는 분위기여서 적당히 넉넉하게 설정해주는게 좋다.
-
이제 FK를 설정해줘야하는데, 해당하는 컬럼 옆에 FK를 보면 십자가 모양이 있다. 그 부분을 클릭하고 드래그해서 참조한 테이블의 PK부분에 갖다주면된다.
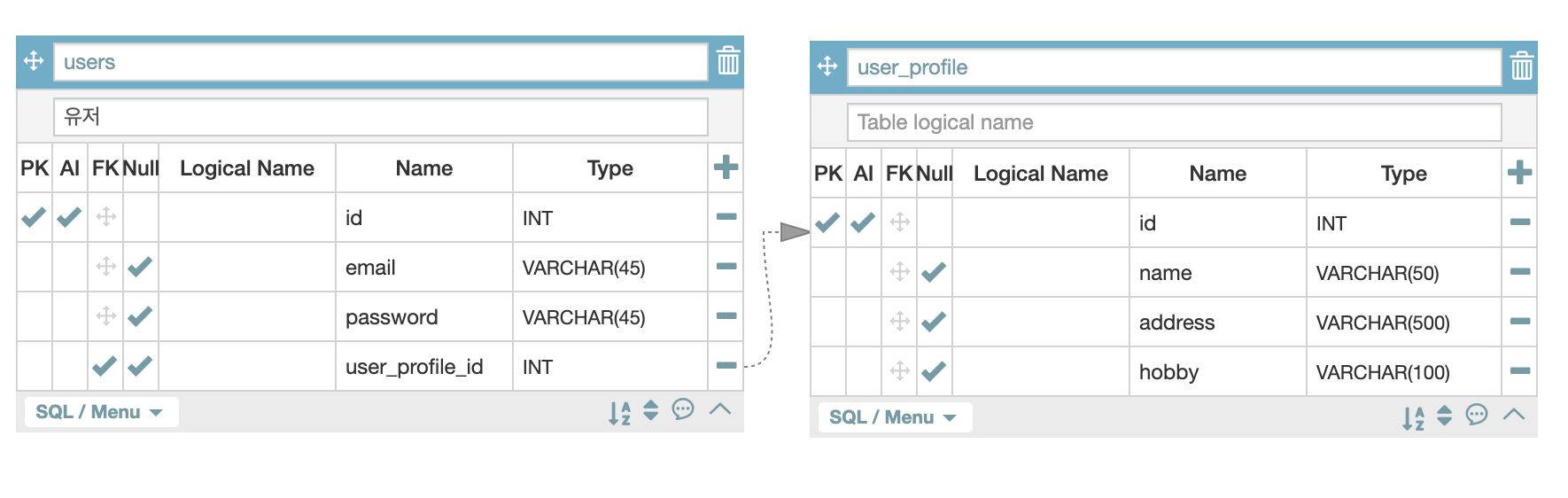
사진과 같이 표시한게 바로 One-to-One 관계이다.
유저의 입장에서 user_profile은 한번만 선택할 수 있다. user_profile이 여러개 생성되도 user는 하나의 profile만 갖을 수 있으므로 one-to-one 관계가 된다.
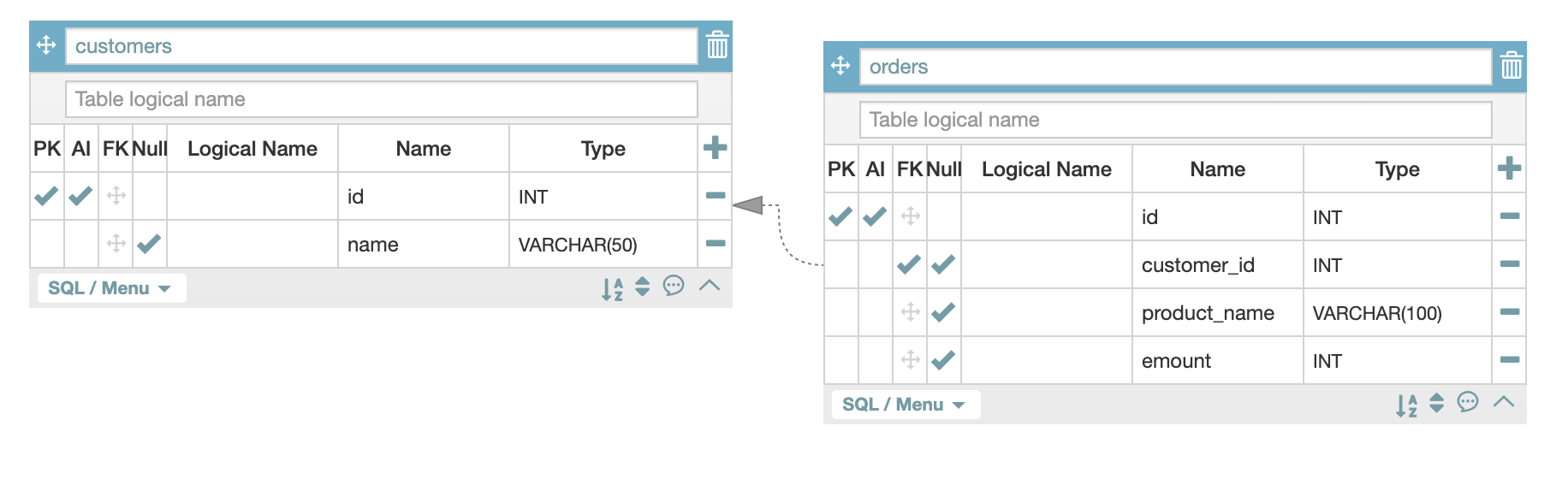
one-to-many 의 경우에는 order 테이블이 customer을 바라본다. customer id를 바라보는 여러개의 오더가 생길 수 있다. 그 이야기는 한 고객이 여러번의 주문을 할 수 있다는 것이다.
customer id를 바라보는 여러개의 order가 생성되는 기준의 연결과계가 바로 one-to-many이다.
many-to-many 에서 authors 테이블과 books 테이블에 id와 name만 줘보자. 현재로서는 서로를 참조할 수 없다. 하지만 하나의 책이 여러명의 저자를 갖아야할 수 있다.
이럴때 중간테이블을 만들어야한다.
author_books 는 중간테이블의 이름이고, 중간테이블은 authors와 books를 각각 참조하게 된다. 이 이야기는
