임베딩이란?
사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과나 그 일련의 과정 전체를 말합니다.
각 단어가 문장에 등장하는 빈도를 활용해서, 문장을 숫자로 변환하는 방법을 바로 떠올릴 수 있겠네요.
TF-IDF, PMI 상호정보량, PLM 뉴럴네트워크 기반 확률 모델등이 있습니다.
그럼 어느 수준으로 문장을 쪼개어 볼 수 있을까요? 단어나 문자, 문장등이 있겠네요. 긴 말들을 작은 조각으로 쪼개는 토크나이저는 아래와 같이 정리해볼 수 있습니다.
토크나이저 구분
- 단어 기반 토크나이저
- NPLM
- Word2Vec
- GLoVe
- FastText
- 하위 단어 토크나이저
- byte level bpe
- word piece
- sentence piece
- 문장 기반 토크나이저
- ELMo
- BERT
- GPT
임베딩 기법
방식은 크게 3가지가 있습니다.
- 행렬 분해 : 말뭉치 정보가 들어있는 원래 행렬을 두 개 이상의 작은 행렬로 쪼개는 방식
- GLoVe
- 예측 : 어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 이전 단어들이 주어졌을 때 다음 단어가 무엇일지 예측하는 방식
- Word2Vec, FastText, BERT, ELMo, GPT
- 토픽 기반 : 주어진 문서에 잠재된 주제를 추론하는 방식으로 임베딩을 수행하는 방식
- LDA
한국어의 특징
한국어는 조사와 어미가 발달한 교착어라는 특성 때문에, 단어 사이에 띄어쓰기가 일어나지 않는 경우도 있습니다.
한국어 동사 가다 도 가겠다 또는 가더라 라고도 문맥에 따라 다양하게 활용될 수 있습니다. 이런 활용형을 전부 어휘 집합에 넣어주어야겠죠. 많은 활용형을 커버하기 위해, 형태소 단위로 분리하는 토크나이저로 말뭉치 속 여러 단어를 찾아봅시다. 단어를 구성하는 하위 유닛을 발견하여 병합하는 알고리즘인, Byte Pair Encoding 를 통해 자주 등장하는 문자열의 조합을 찾아내어 새로운 토큰을 만들 수 있습니다.
연구 현황
2020년에는 아래와 같이, 한국어에서 구분할 수 있는 가장 작은 단위부터 큰 단위까지 정리된 논문도 발간되었습니다. 간단히 살펴볼까요?
- 논문명 : An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
해당 논문에서 소개된 전략은 총 6단계를 가지고 있습니다.
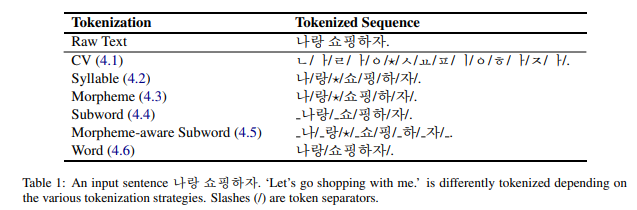
-
CV 자음 및 모음
한글은 자모와 모음이 모여 음절 문자를 이룹니다. ‘나’ 는 ‘ㄴ’ 와 ‘ㅏ’ 와 결합하여 음절이 됩니다. 음절 문자 하나를 만들려면, 자모의 합으로 가능합니다. 두번째 ‘랑’ 은 ‘ㄹ’+’ㅏ’+’o’ 3가지로 토큰화 됩니다.
-
Syllable 음절
문장을 음절 수준에서 토큰화 할 수 있습니다. 공백은 특수기호 * 로 대체됩니다.
나/랑/*/쇼/핑/하/자
-
Morpheme 형태소
문장을 형태소 단위로 토큰화 합니다. 원래 공백은 누락되고 다시 디코딩을 해도 복구되진 않습니다. 이러한 점 때문에 기계번역 , 주어진 텍스트 구문을 정답으로 제시해야 하는 경우는 사용하기 어렵습니다.
나/랑/*/쇼핑/하/자
-
Subword 하위단어
SentencePiece 라이브러리를 사용하여 BPE를 학습하고 적용합니다. 기존의 공백을 표시하기 위해 모든 단어 앞에 ‘ ‘를 추가한 다음, 텍스트를 하위 단어 조각으로 토큰화합니다.
나랑/쇼/핑하/자/.
-
Morpheme-aware Subword 형태소 인식 하위 단어 데이터 기반 접근 방식
한국어와 BPE를 순서대로 사용하여 형태소 인식 하위단어를 만듭니다. 원문을 형태로소 분할한 후 BPE를 적용하므로 여러 형태소에 걸쳐 있는 토큰이 생성되지 않습니다. 대신 BPE알고리즘은 형태소를 빈번하게 등장한 조각으로 세분화 합니다.
나/랑/*/쇼/핑/하/자/
-
Word 단어
텍스트를 공백으로 간단히 나누면 되고, 구두점은 별도의 토큰으로 분할하면 됩니다.
나랑/쇼핑하자/.
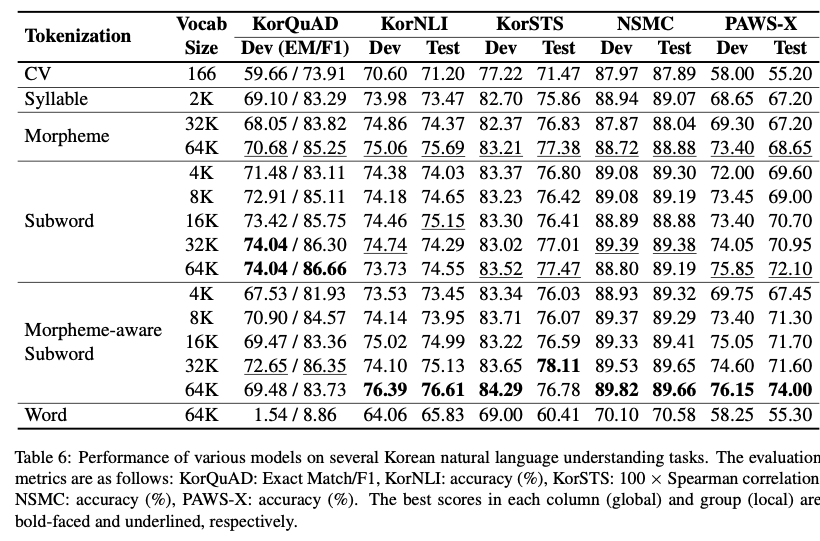
이 전략 중, 어떤 것이 가장 좋을까요? 논문에 소개된 결과는 다음과 같습니다.
- KorQuAD 태스크에서는 Subword - 64K모델이 에서 가장 높은 EM, F1 점수를 얻었습니다.
- KorNLI에서는 Morpheme-aware Subword 64K 모델이 가장 높은 성능을 얻었습니다.
- KorSTS, NSMC, PAWS-X에서도 Morpheme-aware Subword 모델의 결과물이 가장 우수했습니다.
큰 Vocab Size를 가져아만 높은 성능이 나오지 않는다는 사실도 아래에서 알 수 있습니다.
형테소를 고려한 하위 단어를 활용한 토크나이저 생성이 가장 좋은 성능을 낸다면, 어떻게 만들 수 있을까요?
BPE, Byte Pair Encoding은 신경망 기반의 기계 번역 모델과 언어모델에 적용되어있습니다. 기계 번역에서는 특히, 단어 수준의 토큰화보다 byte 기반의 성능이 더 우수합니다. BPE는 훈련데이터에서 자주 등장하는 문자열의 조합을 찾아내기 때문에, OOV처리도 탁월합니다.
Transformer 아키텍쳐에서 BPE가 사용되기 때문에, BERT / GPT에서 해당 방식을 활용하고 있는데요, 그냥 이렇게 하위단어를 만들면 될까요? BPE 프레임워크가 좋다는 것은 다 알고 계실거라고 생각합니다. 형태소 토큰화 후 하위 문자를 어떻게 분해할 때 조금 더 좋은 성능을 낼까요?
이 부분에 대해 조금 더 나아간 분석을 한 논문도 소개해봅니다.
- Improving Korean NLP Tasks with Linguistically Informed Subword Tokenization and Sub-character Decomposition, 2023 (깃헙링크)
- raw corpus 준비
- wiki-ko 1-1) Dowloading the File
-
Dump file repository: https://dumps.wikimedia.org/kowiki/latest/
- Download the pages-articles.xml.bz2 file.
- Version of the file used in the experiment: 09/01/21 (MM/DD/YY)1-2) Extracting Text
-
Use Wikiextractor (https://github.com/attardi/wikiextractor) to extract text from the downloaded dump file.
- The text extraction process using Wikiextractor is not included in the code of this repository. For detailed usage, refer to https://github.com/attardi/wikiextractor.1-3) Moving the Extracted Text Files
-
After using Wikiextractor, place the created 'text' folder in the following path:
- ./corpus/raw_corpus
-
- wiki-ko 1-1) Dowloading the File
- 데이터 전처리
- 괄호 삭제, 자모만 남은 글자 포함, 빈문장과 공백 제거, 짧은 문장 삭제
def preprocess(sent_lst): # our p_paren_str = re.compile("\(.+?\)") # 괄호 문자열("(xxx)") 삭제용 sent_lst = [re.sub(p_paren_str, "", sent) for sent in sent_lst] # 사람(인간)은 짐승(동물)이다 > 사람은 짐승이다 # kortok # p_kakao = re.compile(r"[^가-힣\x20-\x7F]*") # 타 언어 문자, 특수 기호 제거 p_kakao = re.compile(r"[^ㄱ-ㅎㅏ-ㅣ가-힣\x20-\x7F]*") # 타 언어 문자, 특수 기호 제거 # 자모 낱글자 살리기 sent_lst = [re.sub(p_kakao, "", sent) for sent in sent_lst] # our p_multiple_spaces = re.compile("\s+") # 무의미한 공백 sent_lst = [re.sub(p_multiple_spaces, " ", sent) for sent in sent_lst] # 무의미한 공백을 스페이스(" ")로 치환 # our sent_lst = [sent for sent in sent_lst if not re.search(r"^\s+$", sent)] # 빈 문장 제거 sent_lst = [sent.strip() for sent in sent_lst if sent != ""] # 빈 문장 제거 # our sent_lst = [sent for sent in sent_lst if len(sent.split(" ")) >= 3 ] # 퇴임 이후. 어린 시절. 생애 후반. 등등의 짧은 라인 없애기 return sent_lst
- 괄호 삭제, 자모만 남은 글자 포함, 빈문장과 공백 제거, 짧은 문장 삭제
- 토크나이징
- 어절 변경
## 0. eojeol def eojeol_tokenizer(self, sent, decomposition_type: str): # nfd: bool = False, morpheme_normalization: bool = False): # morpheme_normalization: 좋아해 -> 좋아하아 p_multiple_spaces = re.compile("\s+") # multiple blanks if decomposition_type == "composed": eojeol_tokenized = sent.split() elif decomposition_type == "decomposed_simple": if self.nfd == True: eojeol_tokenized = [self.transform_v3(eojeol) for eojeol in re.sub(p_multiple_spaces, " ", sent).split(" ")] elif self.nfd == False: eojeol_tokenized = [self.str2jamo(eojeol) for eojeol in re.sub(p_multiple_spaces, " ", sent).split(" ")] return eojeol_tokenized - 구성에 따라 형태소 추가 분리
-
Unicode normalization Form 에 따라 예시와 맞게 구분
- 'ㄴㅓㄴ ㄴㅏㄹ ㅈㅗㅎㅇㅏ#ㅎㅐ#와 비슷한 형태
-
문법적인 역할을 하는 형태소만 분리 vs mecab 활용한 형태소 전체 분리
# 1-1. composed & decomposed_simple def mecab_composed_decomposed_simple(self, sent: str, use_original: bool, pure_decomposition: bool, nfd: bool, flatten: bool = True, lexical_grammatical: bool = False): # 문법 형태소만 분리: 육식동물 에서 는 (육식-동물)은 붙 if lexical_grammatical == True: mor_poss = self.mecab_grammatical_tokenizer(sent=sent, nfd=nfd) # 순수 형태소 분석: 육식 동물 에서 는 elif lexical_grammatical == False: if use_original == True: if nfd == False: mor_poss = self.mc_orig.pos(sent, flatten=False, coda_normalization=True) # [[('넌', 'NP+JX')], [('날', 'NNG')], [('좋', 'VA'), ('아', 'EC'), ('해', 'VV+EC')]] elif nfd == True: mor_poss = self.mc_orig.pos(sent, flatten=False, coda_normalization=False) # [[('넌', 'NP+JX')], [('날', 'NNG')], [('좋', 'VA'), ('아', 'EC'), ('해', 'VV+EC')]] else: if nfd == False: mor_poss = self.mc_fixed.pos(sent, flatten=False, coda_normalization=True) # [[('너', 'NP'), ('ㄴ', 'JX')], [('날', 'NNG')], [('좋', 'VA'), ('아', 'EC'), ('하', 'VV'), ('아', 'EC')]] # mor_poss = self.mc_orig.pos(sent, flatten=False, coda_normalization=True) # [[('너', 'NP'), ('ㄴ', 'JX')], [('날', 'NNG')], [('좋', 'VA'), ('아', 'EC'), ('하', 'VV'), ('아', 'EC')]] elif nfd == True: mor_poss = self.mc_fixed.pos(sent, flatten=False, coda_normalization=False) # [[('너', 'NP'), ('ㄴ', 'JX')], [('날', 'NNG')], [('좋', 'VA'), ('아', 'EC'), ('하', 'VV'), ('아', 'EC')]] # mor_poss = self.mc_orig.pos(sent, flatten=False, coda_normalization=False) # [[('너', 'NP'), ('ㄴ', 'JX')], [('날', 'NNG')], [('좋', 'VA'), ('아', 'EC'), ('하', 'VV'), ('아', 'EC')]] # insert grammatical symbol if len(self.grammatical_symbol) > 0: # grammatical_symbol 사용하면 mor_poss = [[self.insert_grammar_symbol(mor_pos=mor_pos) for mor_pos in word] for word in mor_poss] # remove pos tags if pure_decomposition == False: mors = [[mor_pos[0] for mor_pos in word] for word in mor_poss] # [['너', 'ㄴ'], ['날'], ['좋', '아', '하', '아']] elif pure_decomposition == True: if nfd == False: mors = [ [ self.str2jamo(mor_pos[0], grammatical=True) if (mor_pos[-1] in self.grammatical_pos ) else self.str2jamo(mor_pos[0], grammatical=False) for mor_pos in word] for word in mor_poss] # convert jamo morpheme like ㄴ, ㄹ into ##ㄴ, ##ㄹ elif nfd == True: mors = [[self.transform_v3(mor_pos[0]) for mor_pos in word] for word in mor_poss] if flatten == True: mecab_tokenized = list(chain.from_iterable(self.intersperse(mors, self.space_symbol))) # ['너', 'ㄴ', '▃', '날', '▃', '좋', '아', '하', '아'] if self.space_symbol == "": # 스페이스 심벌 안 쓴다면 mecab_tokenized = [token for token in mecab_tokenized if token != ""] # 빈 토큰 제외 elif flatten == False: mecab_tokenized = self.intersperse(mors, self.space_symbol) # [['너', 'ㄴ'], ['▃'], ['날'], ['▃'], ['좋', '아', '하', '아']] if self.space_symbol == "": # 스페이스 심벌 안 쓴다면 mecab_tokenized = [token for token in mecab_tokenized if token != [""]] # 빈 토큰 제외 return mecab_tokenized
-
- mecab을 응용한 토크나이징
class MeCabTokenizer_all(BaseTokenizer): # def __init__(self, token_type: str, tokenizer_type: str, decomposition_type: str, space_symbol: str = "", dummy_letter: str = "", nfd: bool = True, grammatical_symbol: list = ["", ""]): def __init__(self, token_type: str, tokenizer_type: str, decomposition_type: str, space_symbol: str = "", dummy_letter: str = "", nfd: bool = True, grammatical_symbol: list = ["", ""], lexical_grammatical: bool = False): # for LG assert (token_type in ["eojeol", "morpheme"] ), 'check the token type!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!' assert (tokenizer_type in ["mecab_orig", "mecab_fixed"] ), 'check the tokenizer type!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!' # assert (decomposition_type in ["composed", "decomposed_pure", "decomposed_morphological", "composed_nfd", "decomposed_pure_nfd", "decomposed_morphological_nfd"] ), 'check the decomposition type!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!' self.mecab = MeCab.Tagger(f"--dicdir /usr/local/lib/mecab/dic/mecab-ko-dic") # self.use_original = use_original # True: mecab orig False: mecab fixed self.token_type = token_type # eojeol / morpheme self.tokenizer_type = tokenizer_type # mecab_orig / mecab_fixed self.lexical_grammatical = lexical_grammatical # LG 적용 여부 (내셔널 지오 그래픽 vs. 내셔널지오그래픽) self.decomposition_type = decomposition_type # composed decomposed_pure decomposed_morphological self.space_symbol = space_symbol # 단어 사이 특수 문자 # "▃" self.dummy_letter = dummy_letter # 초성/중성/종성 자리 채우기용 더미 문자 self.nfd = nfd # NFD 이용해 자모 분해할지 self.grammatical_symbol = grammatical_symbol # 문법 형태소 표지 self.grammatical_pos = ["JKS", "JKC", "JKG", "JKO", "JKB", "JKV", "JKQ", "JX", "JC", "EP", "EF", "EC", "ETN", "ETM"] # 어미, 조사 self.tok = tok.tokenizers(dummy_letter=self.dummy_letter , space_symbol=self.space_symbol, nfd=self.nfd, grammatical_symbol=self.grammatical_symbol) # 토크나이저 인스턴스 생성
- 어절 변경

-
WP (WordPiece): 하위 단어 토큰화
-
WP-SD: 하위 문자 분해를 활용한 하위 단어 토큰화
-
MorWP: 형태소 인식 하위 단어 토큰화
-
MorWP-SD: 하위 문자 분해를 활용한 형태소 인식 하위단어 토큰화
-
MorWP-MD: 형태소적 문자 분해를 활용한 형태소 인식 하위단어 토큰화 Morpheme-aware Subword Tokenization with Morphological Sub-character Decomposition
→ 형태소를 인식했기 때문에 ‘명사 ‘라면’ 만 분해됩니다
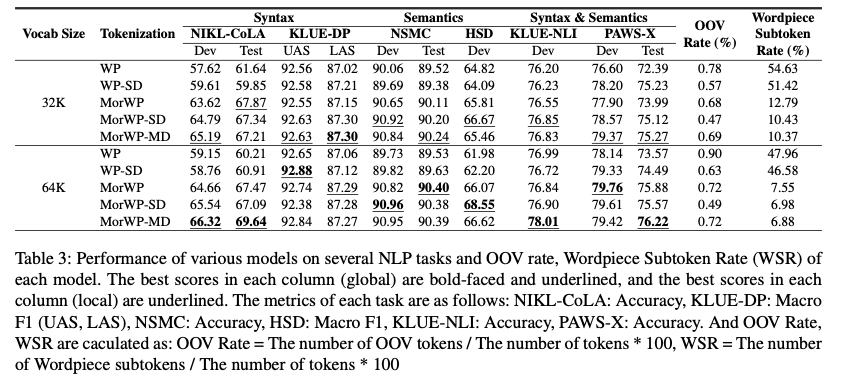
그 결과는 아래와 같습니다.
- 어휘 크기가 클 수록 전반적으로 성능이 더 좋습니다.
- 32K에서 MorWP-MD 성능이 가장 높습니다.
다음글에서 실습 코드와 함께 확인해보겠습니다.
