책 < 통계학 대백과 사전> 을 읽고 정리한 내용입니다.
(추가 참고자료1 )
- 피어슨 상관계수
- 피어슨 상관계수는 공분산을 표준편차 2개의 곱으로 나눈 것을 의미합니다.
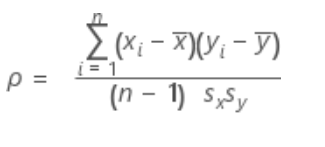
- 피어슨 상관계수는 -1 ~ 1 사이의 값을 가지게 되며, 양수이면 '양의 상관관계', 음수이면 '음의 상관관계' 를 의미합니다.
- 데이터의 산점도를 그렸을 때, 피어슨 상관계수가 낮은 경우에도 데이터 간의 분포에서 인사이트를 얻을 수 있습니다. 그룹별로 유저를 분리하는 '층화' 진행할 시, 전체로는 낮은 스코어이나, 그룹별 의미를 찾을 수 있기 때문입니다.
- 스피어만 상관계수
- 스피어만 상관계수는 값들에 순위를 매긴 뒤 상관계수를 계산하는 것을 말합니다.
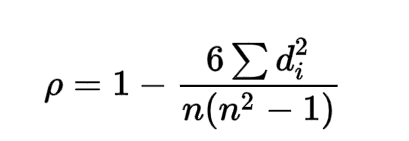
- 순서는 값이 큰 순서대로 부여하게 됩니다.
- 수식에 의해 계산할 수 있는 순위 상관계수 역시 -1 ~ 1 사이의 값을 갖게 되며, 1에 가까울 수록 x, y의 순위가 같고 -1 에 가까울 수록 역순이 됩니다.
- 순위를 매길 때, 데이터가 같아 '같은 순위'를 부여해야 하는 경우가 있습니다. 그럴 경우 두 값의 중간값을 부여하게 됩니다. (2, 3위가 같을 경우 2.5, 2.5를 부여)
- '같은 순위' 인 경우 분모도 조정하게 되어, 최종적으로는 아래와 같은 수식을 볼 수 있습니다.
- 켄달의 순위 상관계수
- 켄달의 순위 상관계수는 양적 데이터 뿐 아니라 서열척도 데이터에도 사용이 가능합니다.
- 두 순위 가 동일할 수록 1에, 역순일 수록 -1에 가까워지는 값을 갖습니다.
- 크기가 n 인 2변량 데이터 (x, y)가 있을 때, n개 중 2개를 골라 이를 x끼리, y끼리 곱하면 아래와 같은 조건도 성립합니다.
(Xi - Xj)(Yi-Yj)> 0 이라면 aij = 1
(Xi - Xj)(Yi-Yj)< 0 이라면 aij = -1
- 두 변수가 통계적으로 종속적인 것으로 간주될 수 있는지 여부를 결정하기 위해, 통계가설에서 검정 통계량으로 자주 사용합니다.
- X 또는 Y의 분포에 대한 가정에 의존하지 않는 비모수 검정입니다.
- 크라메르의 연관계수
- 크라메르의 연관계수는 범주 데이터의 교차표에 이용합니다.
- 카이제곱 통계량을 0~ 1까지의 수가 되도록 조정합니다.
- Ai의 범주가 정해진 대로 Bj의 값이 정해질 경우 연관계수는 1에 가까워집니다.
- 반대로 Ai의 범주와 관계없이 Bj 의 범주에 속한 개체수의 비율이 일정할 때, 연관계수는 0에 가까워집니다.
- 상관계수의 추정과 검정
- 상관계수를 구했다면, 그 값의 95% 신뢰구간에 대한 식도 이해할 수 있습니다.
- 이는 자유도 n-2 인 t분포를 따르며 이를 활용하여 기각역을 정하면 됩니다.
- 추정과 검정 시, 가설 검증은 '상관성이 없다' 라는 귀무가설을 활용할 수 있습니다.
- 자기 상관 계수
- 시계열 데이터도 평균이나 상관관계를 이용하여 데이터 분석이 가능합니다.
- 예를 들어, 30개월 간의 커피 판매량과 30개월 월 평균 커피 판매량이 있다고 칩시다.- 현재 데이터와 1개월 전의 데이터를 조합하여 2변량 데이터로 만들고, 3개월 월 평균 데이터를 이용하여 계산한 공분산을 '시간차가 30인 y30' 인 자기 공분산이라고 부를 수 있습니다.
- 시간차 k인 자기 공분산(auto covariance)
y1 ~ yt 인 시계열 데이터 라고 한다면, 아래와 같이 표현할 수 있습니다.
- y_mean= (1 / T) ( y1 + ... + yt) 라고 함
- rk = Cov[yi, yi-k] = 1 / T ( sigma(yi-y_mean)(y_i-k - y_mean) - 시간차 k인 자기 상관계수
- pk = rk / r0- pk를 k의 함수로 나타낼 떄 p(k)를 자기 상관함수
- p(k) 의 그래프를 상관도표 correlogram 이라고 부르기도 합니다.
