V8 문서를 기반으로 Deep Dive하며 Map과 Object의 성능차이의 원인을 찾자
내가 가진 가설은 다음과 같다.
{ },Map의 자료구조가 다르다.{ },Map둘 다 Hash Table을 사용하지만, Hash 함수가 다르거나 충돌 해결 방식이 다르다.
💡 결론은 1번으로 Map은 결정론적 해시 테이블이고, { }는 그렇지 못 하다.Map에 대해 Deep Dive 해보자
먼저 Map 은 V8 블로그에 따르면 Tyler Cloase가 제안한 결정론적 해시 테이블 자료구조를 따른다. 간소화한 자료구조는 아래와 같다.
class 명과 field 명은 자의적으로 작성했습니다.정확한 구조와는 거리가 멀 수 있습니다.현재는 이터러블 객체가 아닙니다
interface Node {
key: any;
value: any;
next: number;
}
interface Map {
hashTable:number[];
dataTable:Node[];
nextSlot:number;
size:number;
}class Node부터 살펴보자. Node에 key, value 필드에 값을 저장하는 것을 알 수 있다. 특이한 점은 next다. 해당 필드는 해시 충돌이 일어났을 때, 다음 node의 위치를 가리키기 위해 존재한다. 단방향 링크드 리스트라고 생각하면 된다. next의 초기 값은 -1이다. next가 -1이라는 의미는 해당 node와 충돌을 일으킨 node가 존재하지 않는다는 것을 의미한다. 만약 충돌이 일어난다면 충돌난 위치의 index에 있는 노드의 next에 새로운 Node가 저장될 주소값을 저장한다. 새로운 노드가 저장될 주소 값은 Map의 nextSlot에 저장되어 있다.
먼 소리야 ❓ 하시는 분들을 위한 예시
key = 'A', value = 'aValue'와
key = 'B', value = 'bValue'를 저장할 때 해시 충돌을 일으킨다고 가정해보자
즉 hashFunction('A') === hashFunction('A')일 때다.
먼저 'A'가 저장되어 있다.
nodeA {
key:'A',
value:'aValue',
next = -1
}
그 뒤에 'B'가 들어오는데 해시 충돌이 난다.
nodeA {
key:'A',
value:'aValue',
next = bNode의 주소// 🧐 next가 -1 에서 nodeB의 주소값이 저장됨
}
nodeB {
key:'A',
value:'aValue',
next = -1
}
정확한 로직은 Map Class에서 일어나기 때문에 우선은 해시 충돌이 일어나면
충돌이 일어난 기존 노드의 next에 새롭게 저장될 노드의 위치가 저장된다고만 생각하자.class Map에 대해서 알아보자. 총 4개의 필드가 있다. hashTable에는 key값에 대한 hash값이 저장된다. dataTable에는 Node들이 삽입 순서대로 들어간다. dataTable에 Node들이 삽입 순서대로 들어가기 때문에 Map은 key값의 순서를 보장받을 수 있게 된다. nextSlot에는 다음 Node가 dataTable에 저장될 위치에 대한 index 정보가 들어간다. 위의 Class Node에서 hash 충돌이 발생하면 next에 새로운 Node의 주소 값이 저장된다고 했는데, 새로운 Node의 주소 값이 nextSlot이다.
간단히 알아보자
const 새로운노드 = new Node(key,value);
충돌난노드.next = nextSlot;
dataTable[nextSlot] = 새로운노드;
nextSlot++;
size++;마지막으로 size 필드에는 저장된 전체 key의 수가 저장된다. 필드에 대한 설명은 이정도로 마치자.
Map 구현방법 중에 눈길이 갔던 부분은 key를 삭제하는 로직이었는데, 해당 Node를 dataTable에서 빼는 것이 아니라 key,value 값을 undefined으로 처리한다.
이런식으로 구현할 경우에 발생할 메모리 낭비보다는 재정렬하는 오버헤드가 더 크다고 판단한 것 같다.
- 여기서 조심할 부분은 next를 그대로 둬야한다는 것이다.
- next도 변경시키게 되면, 과거에 충돌났었던 Node의 정보를 잃게 된다.
간단히 알아보자
키값 a,b,c를 순서대로 저장하자.
운이 나빠서 모두 해시 충돌이 났다.
그렇다면 a는 b Node가 위치한 dataTable의 인덱스인 1을 next로 가진다.
b도 c Node가 위치한 dataTable의 인덱스인 2을 next로 가진다.
dataTable = [nodeA,nodeB,nodeC]
nodeA.next = 1
nodeB.next = 2
여기서 a 키를 지우고 싶다고
해당 Node의 next를 변경하게 된다면 nodeB,nodeC에 접근할 수 없게 된다.
결정론적 해시 테이블을 구현해보자
최대한 해시 충돌이 많이 일어나길 원해서 key로 int를 받고 2로 나눈 나머지를 리턴하는 함수를 해시 함수로 사용했다.
for of나 [...]를 사용하기 위해 이터러블한 객체로 바꾸는 작업이 예정 중이다.
해당 글도 포스팅하겠습니다. 많관부 🙇♂️
interface INode<T> {
key: T | undefined;
value: unknown;
next: number;
}
class MyNode<T> implements INode<T> {
key: T | undefined;
value: unknown;
next: number;
constructor(key: T, value: unknown, next = -1) {
this.key = key;
this.value = value;
this.next = next;
}
}
class MyMap<T> {
hashTable: number[];
dataTable: INode<T>[];
nextSlot: number;
length: number;
constructor() {
this.hashTable = [];
this.dataTable = [];
this.nextSlot = 0;
this.length = 0;
}
find(key: T): INode<T> | undefined {
const hash = MyMap.hashFn(key);
if (!this.hashTable.includes(hash)) {
return undefined;
}
let current = this.dataTable[hash];
while (current !== undefined) {
if (current.key === key) {
return current;
}
if (current.next === -1) {
break;
}
current = this.dataTable[current.next];
}
return undefined;
}
set(key: T, value: unknown) {
const hash = MyMap.hashFn(key);
if (!this.hashTable.includes(hash)) {
this.hashTable.push(hash);
}
let current = this.dataTable[hash];
if (current === undefined) {
this.dataTable[hash] = new MyNode<T>(key, value);
this.nextSlot++;
this.length++;
return;
}
while (current !== undefined) {
if (current.key === key) {
current.value = value;
return;
}
if (current.next === -1) {
break;
}
current = this.dataTable[current.next];
}
current.next = this.nextSlot;
this.dataTable[this.nextSlot] = new MyNode<T>(key, value);
this.nextSlot++;
this.length++;
}
get(key: T): unknown {
const current = this.find(key);
if (current === undefined) return undefined;
return current.value;
}
delete(key: T) {
const current = this.find(key);
if (current === undefined) return;
current.value = undefined;
current.key = undefined;
this.length--;
}
get size() {
return this.length;
}
static hashFn(key: any): number {
return Number(key) % 2;
}
}작성한 MyMap의 테스트 코드는 옆에 링크에서 확인할 수 있다. 링크
Object에 대해 Deep Dive 해보자
결론부터 얘기하자면, Hash Table로 구현되어 있지 않다. 크롬이나 Node.js 환경에서 사용되는 v8 엔진이 Object를 어떻게 처리하는 지 알아보자.
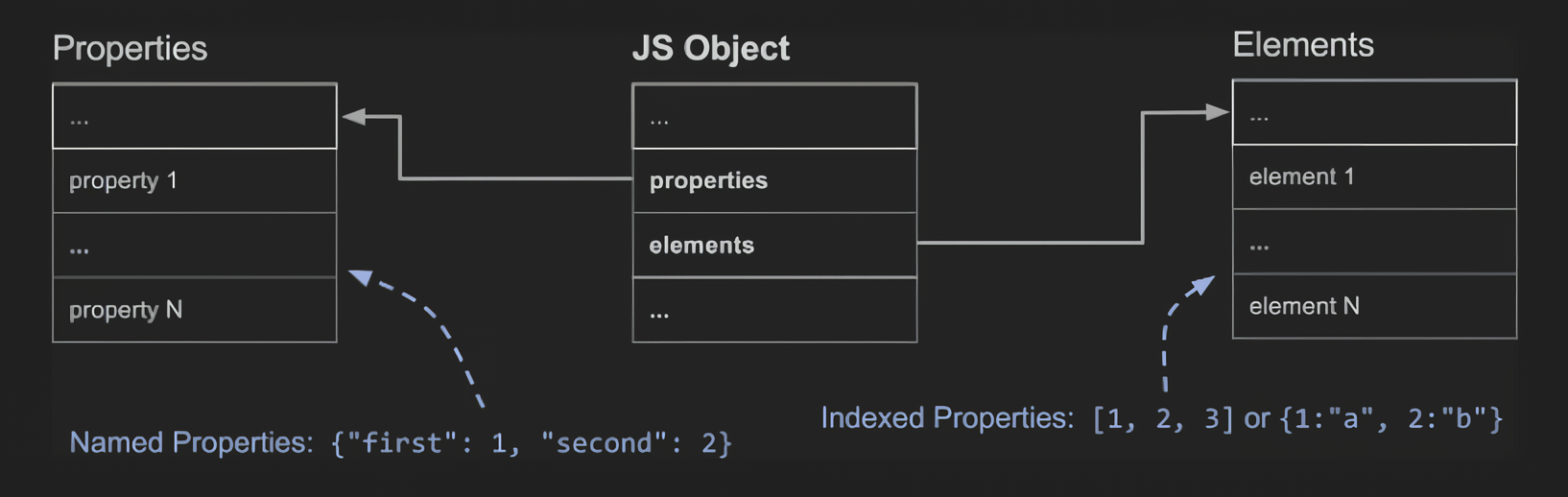
자바스크립트의 객체는 대부분 문자열 키와 임의의 객체를 값으로 사용하는 딕셔너리처럼 행동한다. 그러나 스펙상으로는 인덱스화된 프로퍼티와 명명된 프로퍼티를 다르게 처리한다. 출처: v8 블로그
자바스크립트 객체가 메모리상에서 어떻게 저장되는지 알아보자.
크게 두 가지 형식으로 저장된다.
- Indexed Properties(인덱스화된 프로퍼티)
- Named Properties(명명된 프로퍼티)
인덱스화된 프로퍼티
배열이거나 key 값이 정수 형태인 key가 저장된다.
- Array.prototype methods은 인덱스화된 프로퍼티를 사용한다.
- 배열의 type이 object인 이유가 여기 있다.
명명된 프로퍼티
key 값이 정수 인덱스가 아닌 경우의 key가 저장된다.
명명된 프로퍼티도 사실 별도의 배열에 저장되는데, 해당 객체의 정보는 HiddenClass에 저장된다. HiddenClass에는 객체의 구조에 대한 정보 뿐만 아니라 속성 인덱스로의 매핑을 저장하다. 인덱스화된 프로퍼티의 경우 새로운 HiddenClass를 생성하지 않는다.
난해하지만, 참고 끝까지 읽으면 누구나 이해할 수 있습니다. 🍀
객체의 정보를 저장하는 HiddenClass
HiddenClass는 객체의 프로퍼티 수와 객체의 프로토타입에 대한 참조를 포함하여 객체에 대한 메타 정보를 저장한다. 자바스크립트와 같은 프로토타입 기반 언어에서는 일반적인 상황에서 클래스를 미리 알 수 없다. V8에서는 객체가 변경될 때마다 HiddenClass가 즉석에서 생성되고 동적으로 업데이트 된다.
💡 내가 생각한 HiddenClass의 존재 이유는 다음과 같다.
HiddenClass는 객체의 모양을 식별하는 역할을 하는데, 이는 최적화에 중요하지 않을까? 오브젝트 구조를 보장할 수 있다면 캐싱이 가능하다.
프로토타입 기반 언어의 특징인 프로토타입 체이닝을 이용한 프로퍼티를 찾아내는 비용은 꽤나 비싸다. 같은 구조라면, 이전에 찾았던 결과를 캐싱하면 성능이 좋아지지않을까?
HiddenClass는 어떻게 객체의 모양을 보장할까?
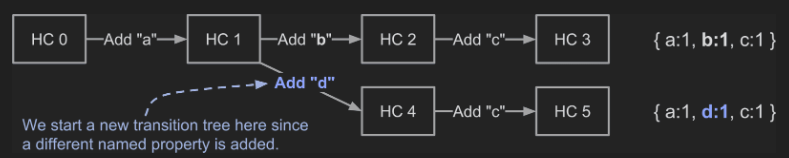
- 새로운 프로퍼티가 추가될 때마다 HiddenClass는 변경된다.
- 하지만, 동일한 순서로 동일한 프로퍼티를 저장한 객체는 같은 HiddenClass를 갖는다.
- 배열은 새로운 인덱스를 추가해도 새 HiddenClass가 생성되지 않는다.
즉, 같은 순서로 같은 key를 저장하거나 삭제했다면 같은 모양의 객체라고 판단한다.
왜 같은 순서일까❓
a 추가, b 추가, a 삭제 => b만 남음
a 삭제, b 추가, a 추가 => a,b 남음
순서에 따라서 객체가 달라지는 경우를 대비한 것이 아닐까..?
HiddenClass의 데이터 구조에 대해서 알아보자
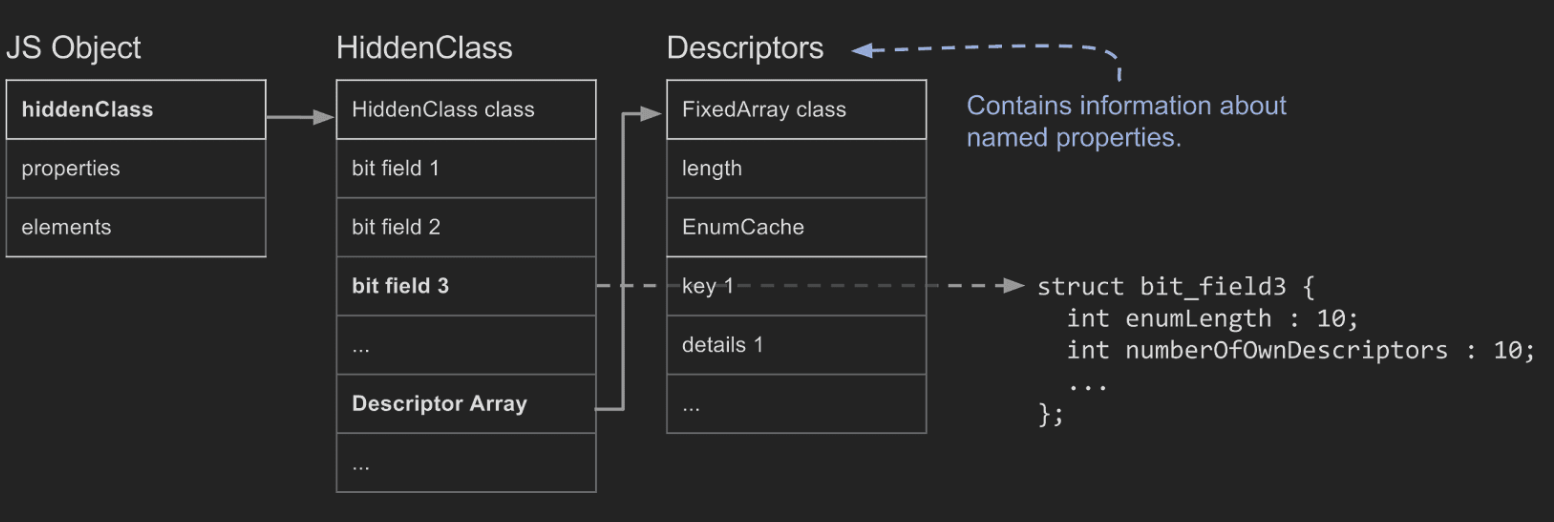
HiddenClass의 field 중에 눈여겨 볼 녀석은 bit field 3과 Descriptor Array이다.
bit field 3은 프로퍼티의 수를 저장하고, Descriptor Array에는 class명, 저장된 위치, Properties(Named Properties) 정보가 들어있다. 당연히, 정수 인덱싱된 프로퍼티는 해당 항목에 없다.
명명된 프로퍼티는 3가지의 종류가 존재한다.🎯
해당 섹션에서 Deep Dive 하면서 얻고자 했던 정보들이 포함되어 있다.
Deep Dive 하면서 얻고자 했던 사실은 프로퍼티 수가 많아지면 왜 Map 에 비해 Object 의 성능이 훨씬 나쁜지였다.
Object는 3 가지 방법으로 프로퍼티를 구별한다.
- In-object properties ⚡
- normal fast properties 🐰
- normal slow properties 🐢
In-object properties는 오브젝트 자체에 직접 저장되기 때문에 우회 없이 엑세스할 수 있어 매우 빠르다. 오브젝트 내의 프로퍼티의 수는 오브젝트의 초기 크기에 따라 미리 결정되고, 오브젝트의 공간보다 더 많은 프로퍼티가 추가된다면 프로퍼티를 다른 곳에 저장하게 된다.
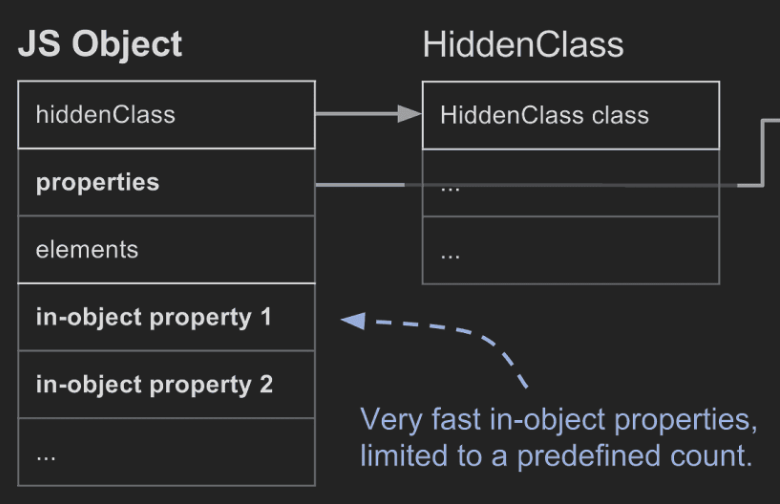
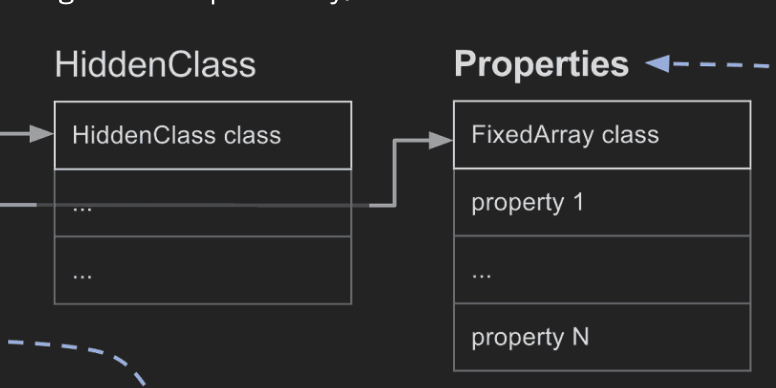
normal fast properties는 In-object와 달리 객체 내부에 정보가 저장되어 있기 때문에 In-object보다 느리지만, HiddenClass의 Properties 필드에 선형으로 저장되어 있기 때문에 인덱스로 접근할 수 있어 빠르다. HiddenClass의 Descriptor Array를 참고해서 실제 프로퍼티 값을 찾을 수 있다.
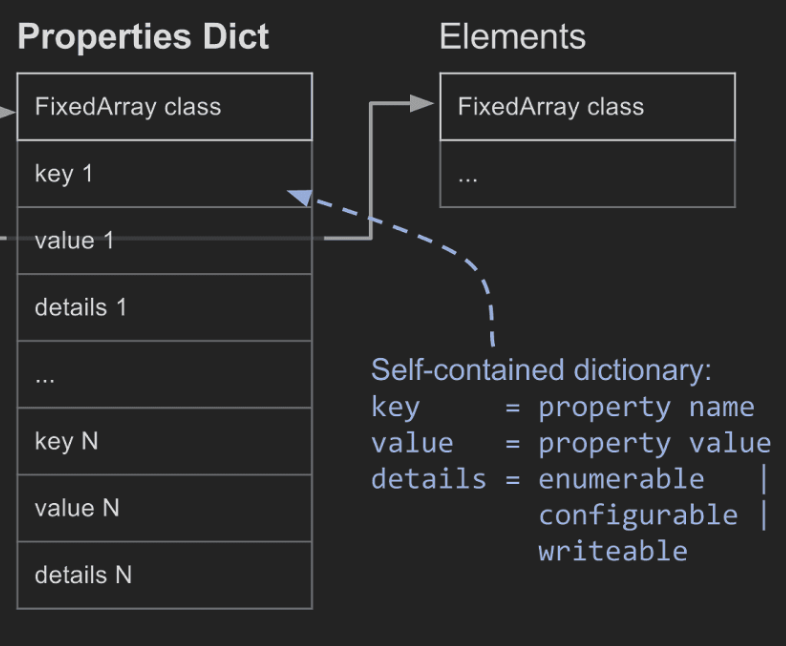
normal slow properties는 딕셔너리 형태로 key,value를 저장한다. In-object 처럼 객체내에 있지 않고, 선형적으로 저장하지 않기 때문에 매우 느리다.
역설적이지만, 딕셔너리 형태로 저장하는 것이 특정한 상황에서는 최고의 선택일 수 있다.
먼저, In-object 방식은 저장할 수 있는 프로퍼티 수가 제한적이라 많은 프로퍼티를 저장할 때는 사용할 수 없다.
HiddenClass를 사용하여 선형적으로 프로퍼티에 접근하는 방식은 딕셔너리보다 빠르긴 하지만, 객체에 프로퍼티가 추가되고 삭제되는 과정에서 HiddenClass가 재생성된다. 이때 많은 시간과 메모리 오버헤드가 발생할 수 있다. 프로퍼티 수가 많아진다면 이러한 오버헤드가 인덱스로 접근하는 장점보다 커질 수 있다.
결론
Deep Dive해서 얻은게 뭐야
Map은 HashTable이다.- Object는 그렇지 않고, 3가지의 프로퍼티 저장 방법을 가진다.
- Object의 경우 프로퍼티 수가 많아지면, 점점 느린 방식의 프로퍼티 접근 방법을 사용할 수밖에 없는 구조다.
뭔가 부족해..
프로퍼티 수가 많아지고, 업데이트, 삭제 등의 로직이 많아지면 Object 의 성능이 Map 에 비해 나빠진다로 글을 끝내기엔 아쉽다. 개발자는 수치로 말해야하지 않을까. 실험을 설계하고 측정한 후에 시각화하자.
