

- 같은 타입의 데이터를 연속된 형태로 저장한 구조
- 생성된 데이터에 대해서 수정이 가능
- 저장된 각 데이터에
index를 이용해서 순서를 지정(zero based index) - 중복 데이터를 허용
1 배열 탐색&수정
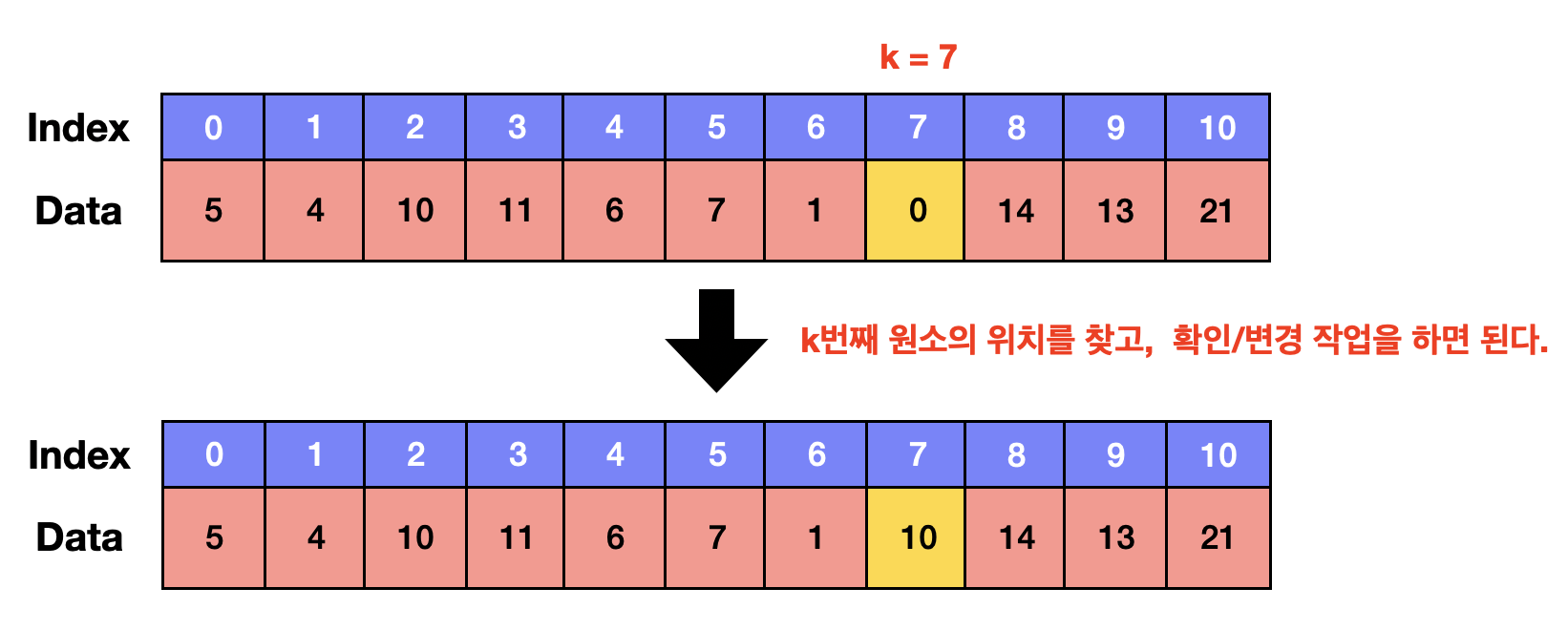
- 배열은
index를 가지고 있기 때문에n번째 데이터를 찾기 위해서 O(1)의 시간 복잡도를 갖는다. - 수정도 마찬가지로 데이터를 찾아서 바로 수정하기 때문에 O(1)의 시간 복잡도를 갖는다.
2. 배열 삽입&삭제
- 탐색&수정과 마찬가지로 그냥 찾아서 수행할 수 있을 것 같지만, 그렇지 않다.
- 배열은 기본적으로 연속적으로 메모리를 점유하고 있기 때문에 삽입을 할 경우 해당 위치부터 데이터를 한 칸씩 뒤로 미뤄야 하고 삭제할 경우 앞으로 당겨야 한다.(O(n))
- 파이썬과 같은 언어의 경우 리스트를 배열로 사용하고 있기 때문에 삽입&삭제가 용이하지만, C언어와 같이 배열의 크기를 지정해 놓고 사용하면
overflow가 발생할 수 있다.
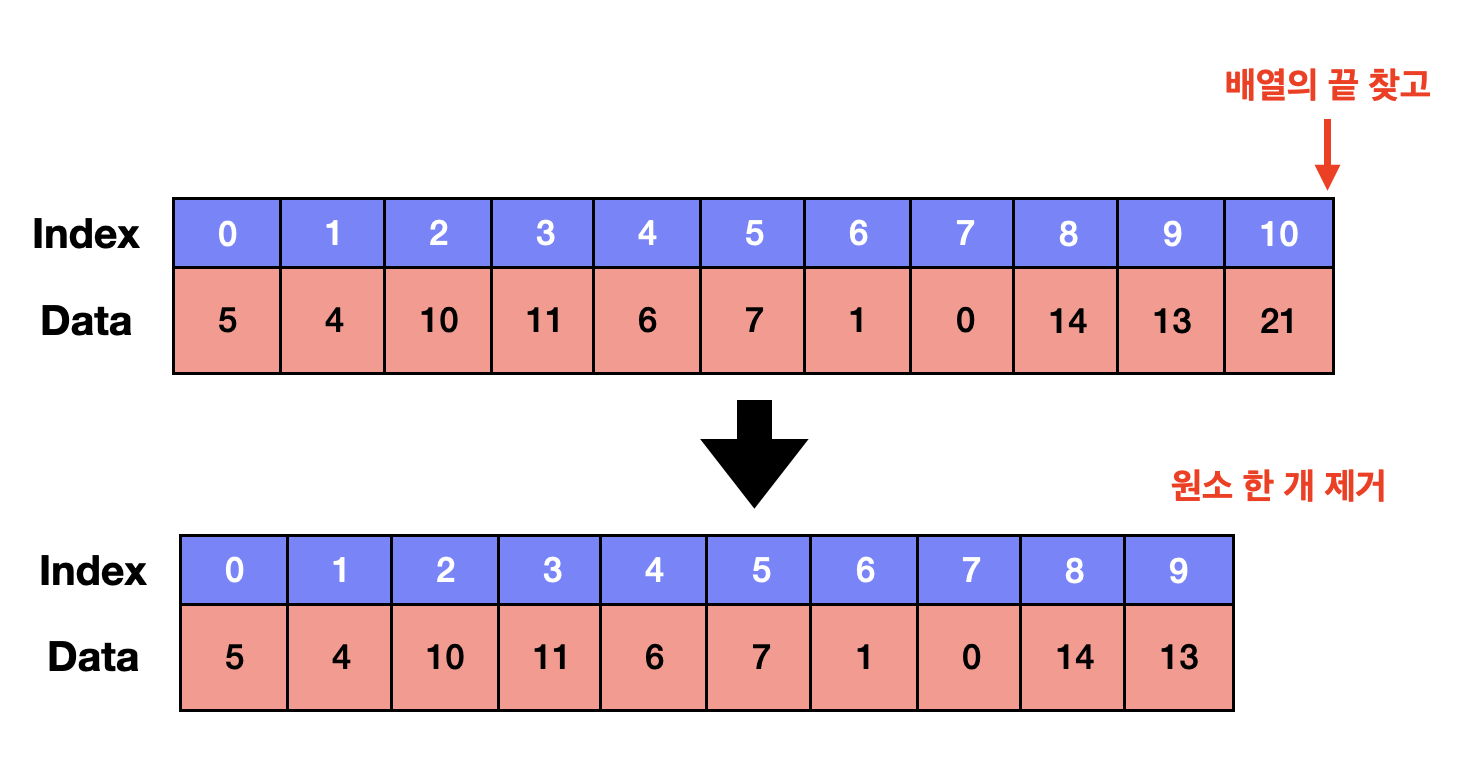
2.1 맨 끝에 삽입&삭제
- 맨 뒤에 삭세 혹은 삽입
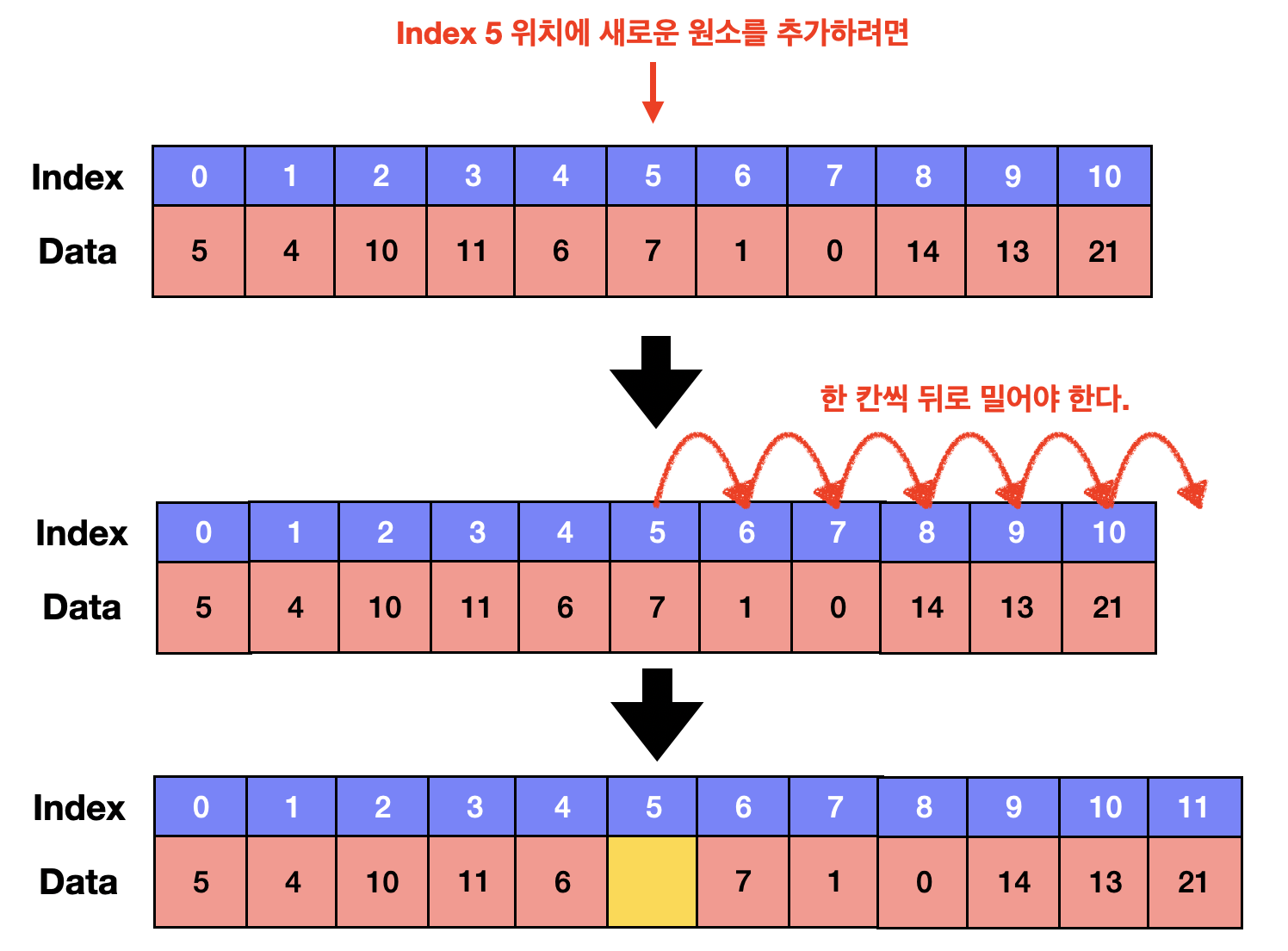
2.2 임의의 위치에 삽입&삭제
- 원소의 위치를 탐색(O(1))한
- 원소를 추가 혹은 삭제(O(1))
- 해당 위치 이후부터 데이터 위치 변경(O(n))
3. 배열의 사용
- 순차적이고 크기가 지정되어 있을 때
- 데이터의 삽입/삭제가 적을 때
- 데이터 검색 양이 많을 때(
index를 통해서 빠르게 접근이 가능)
출처
https://kim-mj.tistory.com/236
https://choheeis.github.io/newblog//articles/2020-12/data-structure-array
