용어정리::Elasticsearch
elasticsearch?
- Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색 엔진
- elasticsearch를 통해 루씬 라이브러리 사용할수 있으며
- 방대한 양의 데이터를 신속하게 거의?실시간 으로 저장, 검색, 분석 할수있다.
- 검색을 위해 단독으로 사용되기도 하며
- ELK(Elasticsearch + Logstash + Kibana) 스택으로 사용되기도 한다.
- Logstash
- 다양한 소스(DB,csv파일 등)의 로그 또는 트렌잭션 데이터를 수집, 집계, 파싱 하여 Elasticsearch 로 전달
- Elasticsearch
- Logstash 로부터 받은 데이터를 검색 및 집계를 해서 필요한 관심있는 정보를 획득.
- Kibana
- Elasticsearch 의 빠른 검색을 통해 데이터를 시각화 및 모니터링
- Logstash
Elasticsearch 와 관계형 DB 비교
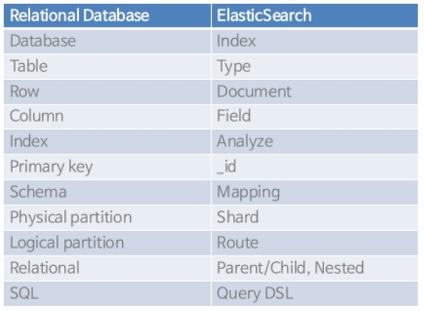
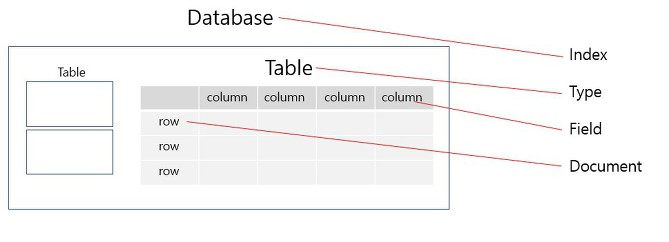
Elasticsearch 아키텍쳐, 용어정리
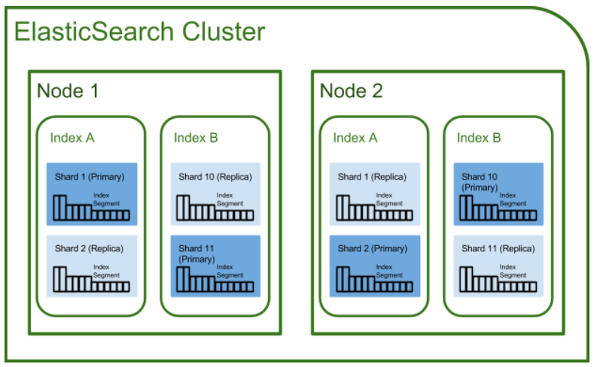
1)클러스터
- 클러스터란 Ela에서 가장 큰 시스템 단위를 의미.
- 최소 하나 이상의 노드로 이루어진 노드들의 집합
- 서로다른 클러스터는 데이터의 접근 교환을 할 수 없는 독립적인 시스템으로 유지
- 여러 대의 서버가 하나의 클러스터를 구성할 수 있고
- 한 서버에 여러개의 클러스터가 존재 할 수도 있다.
2) 노드
-
Elasticsearch를 구성 하는 하나의 단위 프로세스를 의미
-
역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수있다.
-
Master-eligible node
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드를 말합니다.
- 인덱스 생성, 삭제
- 클러스터 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당 할 것인지
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드를 말합니다.
-
Data node
- 데이터와 관련된 CRUD 작업과 관련있는 노드
- CPU, 메모리 등 자원을 많이 소모해서 모니터링 필요, master 노드와 분리되는것이 좋다.
-
Ingest node
- 데이터를 변환 하는 등 사전 처리 파이프라인을 실행하는 역할.
-
Coordination only node
- data node 와 master-eligible node 의 일을 대신하는 이 노드는 대규모 클러스터에서 이점이 있다.
- 즉 로드밸런서와 비슷!
index, shard, replica 는 나중에 ~

be pro