
2장 Persistence Context에서 설정에 따라 em.persist 의 동작이 달라질 수 있다고 이야기 했었다.
이번 장에서는 @GeneratedValue의 전략을 어떻게 설정 하느냐에 따라 em.persist의 동작이 어떻게 바뀌는지 살펴볼 것이다.
이전에 만들었던 User Entity는 다음과 같다
// User.java
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
private int age;
}@GeneratedValue Annotation에 아무런 옵션도 주지 않았다.
여기에 strategy라는 옵션을 수동으로 넣어줄 수 있는데,
여기에 들어갈 수 있는 값은 총 5가지다.
GenerationType.AUTOGenerationType.IDENTITYGenerationType.SEQUENCEGenerationType.TABLEGenerationType.UUID
옵션을 입력하지 않았을 경우, 기본 값은 GenerationType.AUTO이며
가급적 strategy를 명시하는 것이 권장된다.
strategy가 AUTO로 설정될 경우, 어떤 DB를 사용하냐에 따라서 값이 달라지기 때문이다.
Persistence Context에서 Entity를 구분하는 방법
지금까지 Persistence Context에 대해 알아본 바를 정리하면
em.persist를 호출 했을 때, Entity가 임시로 저장되는 캐시 레이어. Entity를 모아서em.flush시점에 한 번에 DB에 요청하여 네트워크 요청 수를 줄일 수 있음em.find를 호출했을 때, Persistence Context 내부에서 Entity를 먼저 찾고, 찾지 못한 경우에는 DB에 요청. 역시 네트워크 요청 수를 줄일 수 있음em.find,em.createQuery등으로 DB에서 찾아온 Entity가 Persistence Context 내부에 존재하지 않을 때, 자동으로 Persistence Context에 저장. 다음 번에는 DB 요청을 보내지 않고 빠르게 찾아올 수 있음
위와 같다.
그런데 중요한 사실이 빠졌다.
Persistence Context 내의 Entity들은 어떻게 식별될까
답은 id를 통해 식별된다는 것이다.
id는 DB에서는 PK라고 불리며, 같은 Entity는 동일한 id를 절대로 가질 수 없다.
만약 동일한 id를 갖는 일이 생긴다면, 두 Entity를 구분할 방법이 없어진다.
테이블을 학급이라고 생각하고, 테이블 내의 각 Entity를 학생이라고 생각해보자.
이 때, '이름'으로 학생을 구분할 수 있다.
동명이인이 존재하지 않는다면 말이다.
'곽한구'라는 사람이 같은 반에 2명 존재한다면 이야기는 달라진다.
누군가 '곽한구'를 불러도 정확히 누구를 지칭하는 것인지 확신할 수 없을 것이다.
그러나 이 때도 확실하게 동명이인을 구분하는 방법은 존재한다.
각 학생의 번호는 언제나 유일하므로, 번호로 구분하면 된다.
10번 곽한구, 24번 곽한구 이런식으로 말이다.
그러면 언제나 누구를 지칭하는 것인지 100% 확신할 수 있다.
PK도 이와 동일하게 언제나 고유성이 보장되기 때문에, id가 동일하다면, 항상 같은 Entity를 지칭함을 확신할 수 있다.
DB에서 id(PK)가 필요한 이유이며, 이는 Persistence Context에도 동일하게 적용된다.
즉, Entity는 항상 id를 가져야 한다.
Persistence Context에 있던, DB에 있던 말이다.
그렇다면 id가 없는 Entity는 Persistence Context에 저장될 수 없다는 말이 된다.

위와 같은 상황에서, User Entity의 이름이 같은 경우, 어떻게 각 Entity를 구별할 수 있을까.
2명의 동명이인을 이름으로 구별할 수 없듯, 불가능하다.
그런데 우리는 지금까지 id를 직접 설정한 적이 없다.
지나가듯이 id를 자동으로 넣어준다고 생각하라고 이야기 했었는데,
사실이다.
id를 넣지 않으면 em.persist를 호출하는 시점에 자동으로 id가 설정된다.
다만, strategy에 따라 id가 설정되는 방법이 조금씩 달라진다.
지금부터 각 strategy를 하나씩 살펴보겠다.
SEQUENCE Strategy
User Entity의 strategy를 SEQUENCE로 변경한다.
// User.java
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String name;
private int age;
}만약 PostgreSQL을 사용한다면 strategy가 AUTO인 경우, 자동으로 SEQUENCE가 설정된다.
PostgreSQL에는 Sequence라는 객체가 존재하는데,
다음 번에 사용될 id의 값을 기록해 둔 객체라고 생각하면 된다.
예를 들어 Java로 표현하면 다음과 유사하다.
public class Sequence {
private long sequence = 1L;
public long nextVal() {
// 이전 sequence 저장
long prevSequence = sequence;
// sequence 50 증가
sequence += 50;
// 이전 sequence 반환
return prevSequence;
}
}Java로 표현했지만 Sequence는 DB에 존재한다.
Jpa가 DB에 요청을 보낼 때, nextVal을 호출하여 sequence를 받아온다.
처음에는 아무런 Entity도 저장되어 있지 않기 때문에 1부터 시작한다.
그리고 em.persist를 호출하여 Entity를 저장할 때마다 id를 1씩 증가시킨다.
도표로 보면 다음과 같다.
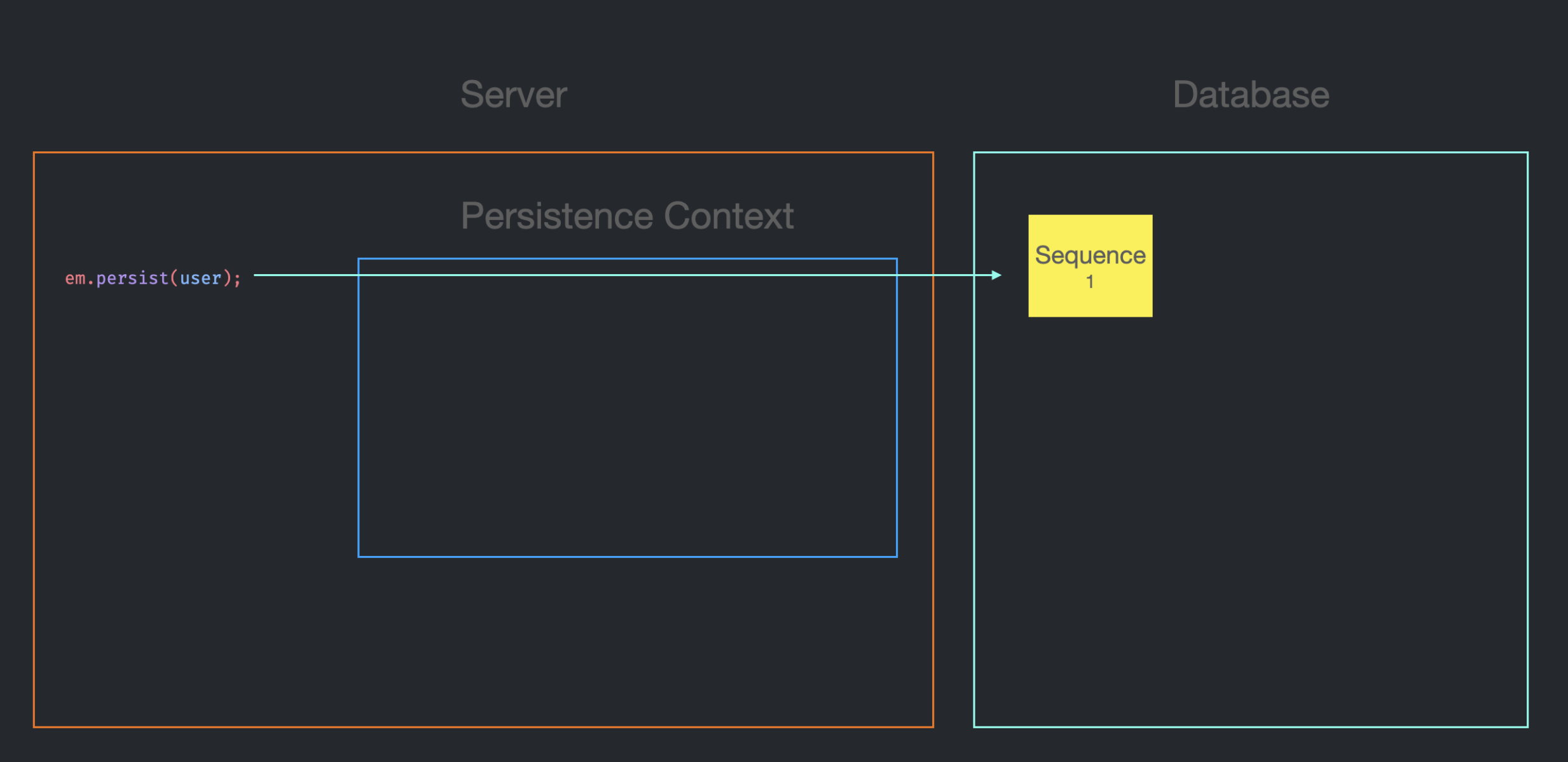
User Entity에 수동으로 id를 설정하지 않은 상태에서 처음 em.persist가 호출되면, DB에 User Entity에 대한 sequence를 요청한다.
Console에서 계속 보였던 바로 이 SQL이 그것이다.
Hibernate:
select
next value for user_seq그러면 DB는 서버에 원래 sequence 값이었던 1을 반환하고, DB 내의 sequence는 50을 증가시켜서 51을 저장한다.(sequence가 50이 증가하는 이유는 설정 때문이며, application.yaml에서 변경 가능하다.)
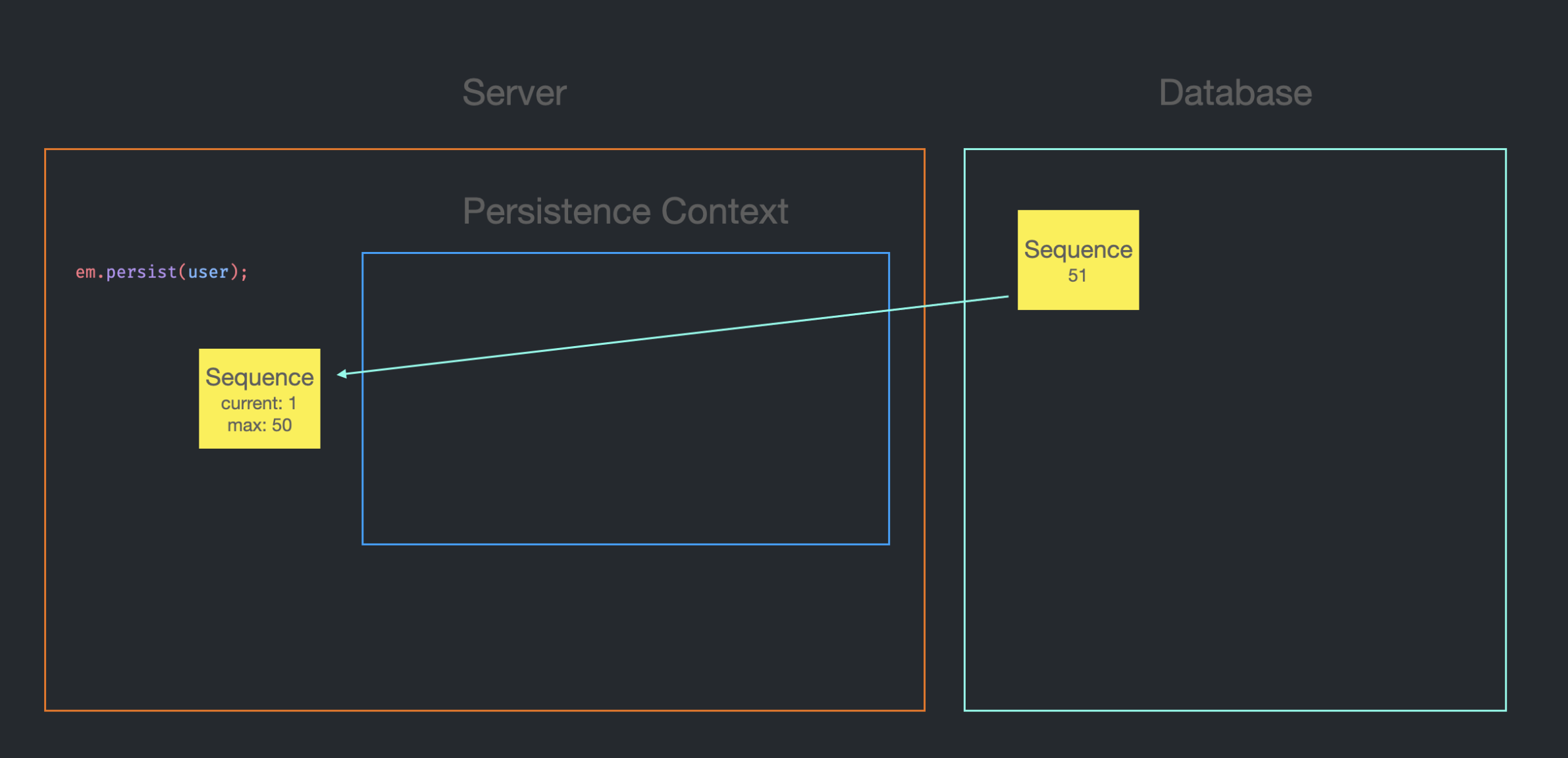
DB로부터 가져온 sequence 값은 Jpa에 의해 관리된다.
current는 1, max는 50이 된다.
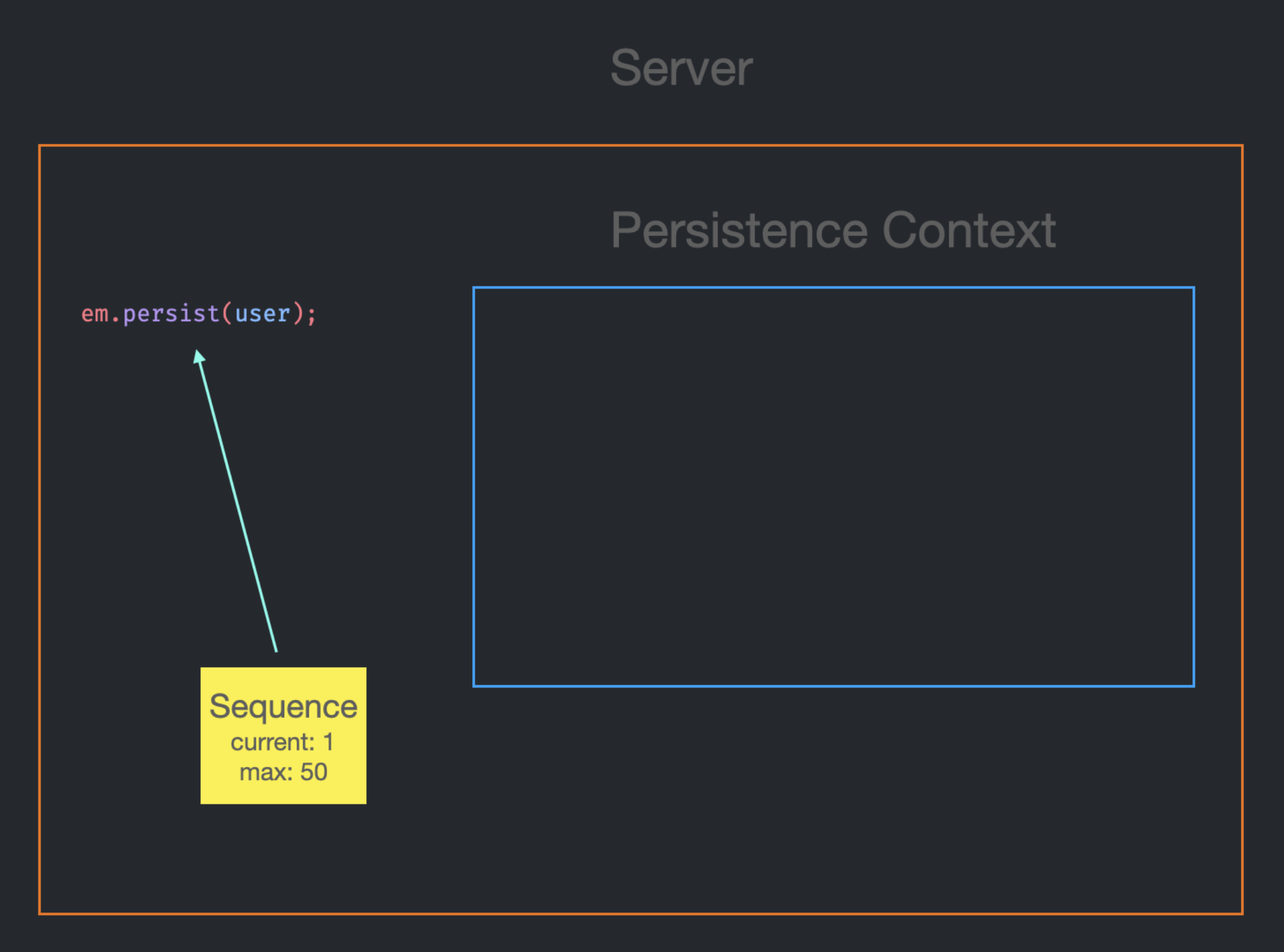
이제 em.persist를 호출할 때마다 Jpa에 의해 관리되는 sequence로부터 id를 반환 받는다.
첫 번째 Entity이므로 id는 1이 될 것이며, 반환과 동시에 current는 1씩 증가할 것이다.
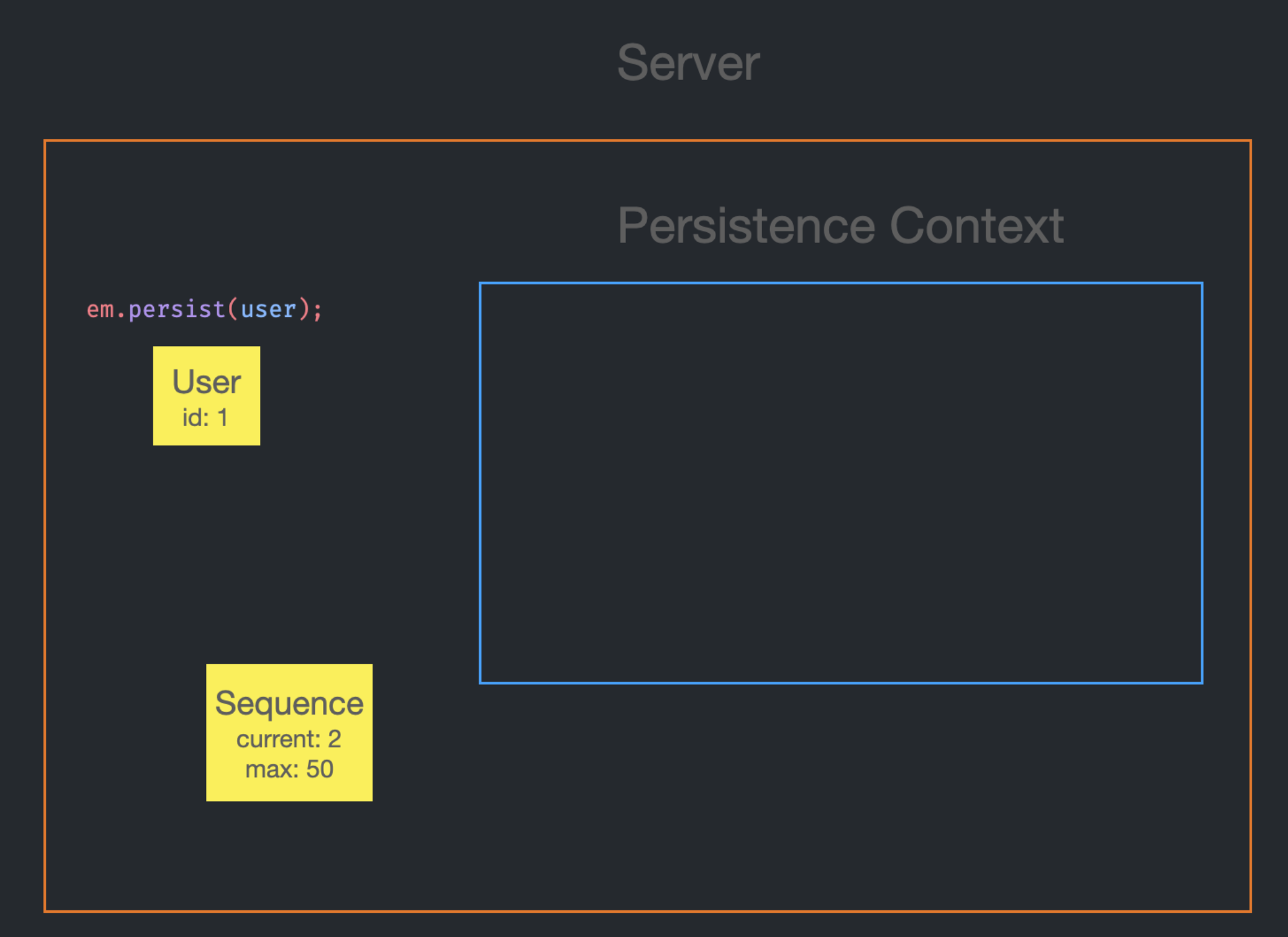
이제 id가 존재하기 때문에 Persistence Context에 저장될 수 있는 상태가 되었다.
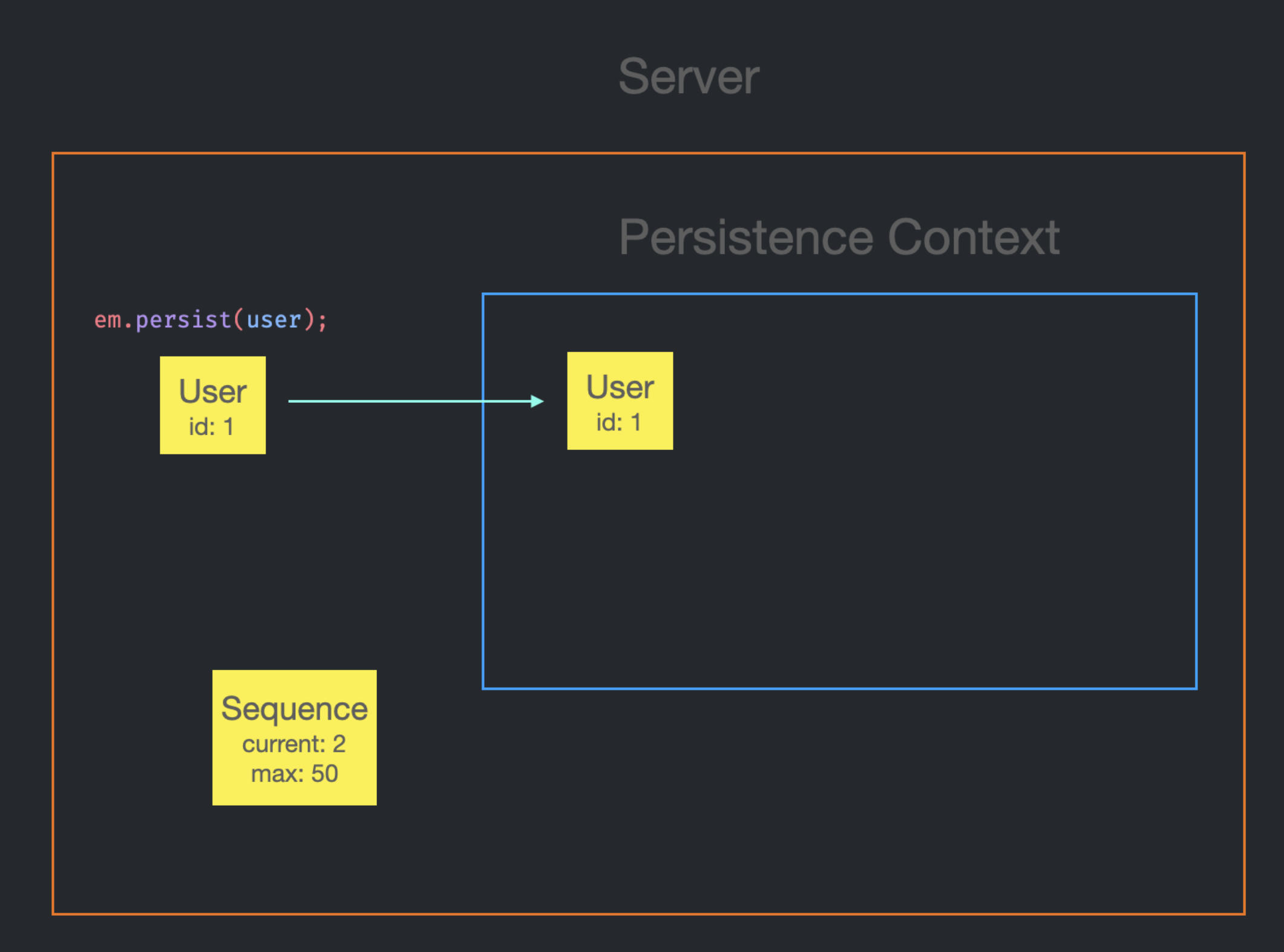
그대로 저장하면 된다.
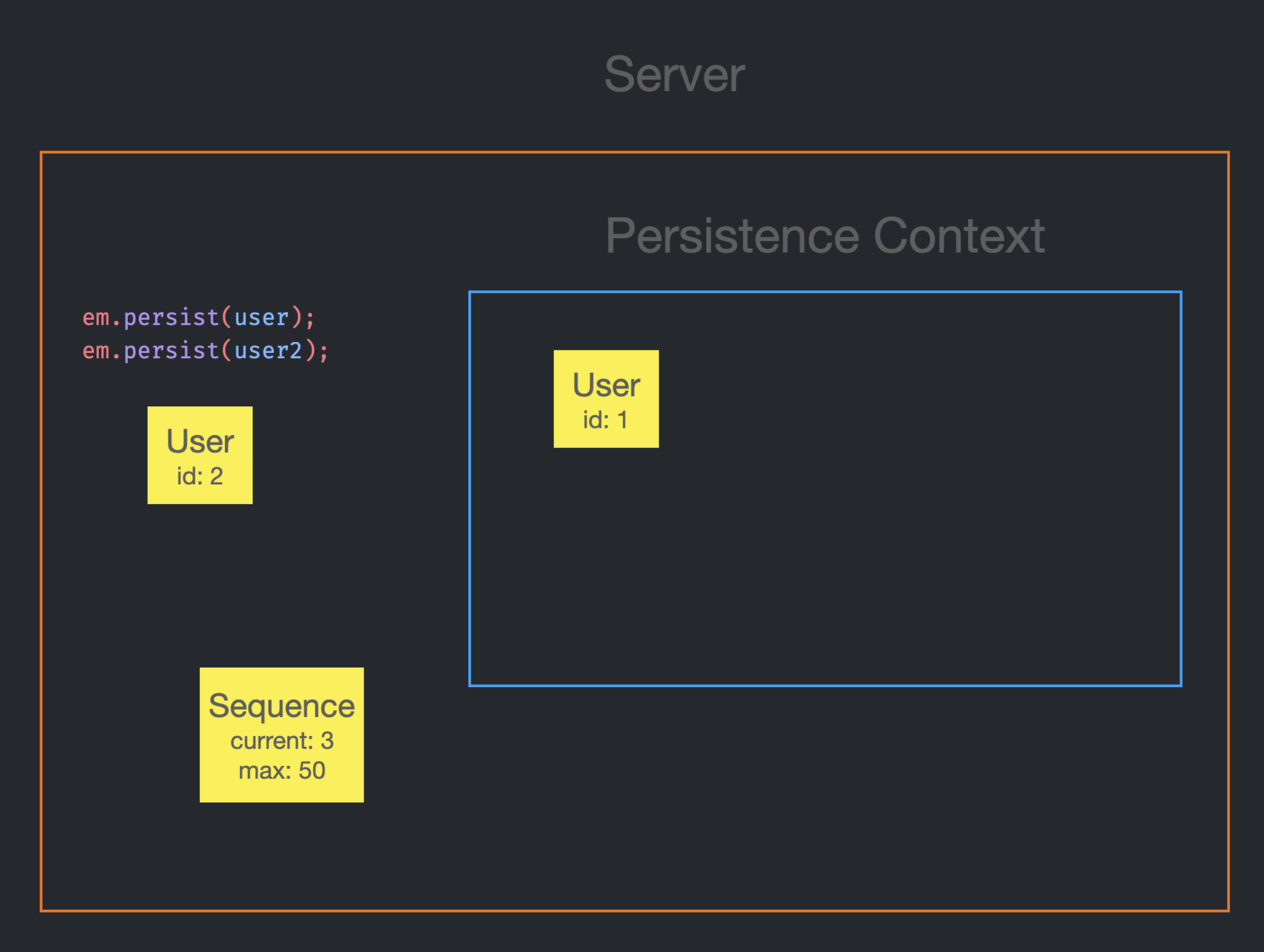
em.persist를 호출할 때마다 sequence로부터 current 값을 받고 current는 1을 증가시킨다.
em.persist(user2) 호출 시, user2의 id가 null인 상태였기 때문에 Persistence Context에 들어갈 수 없다. 그래서 sequence에게 currnet인 2를 받아오게 되고, id를 2로 설정한다.
이 때, current는 1 증가되어 3이 된다.
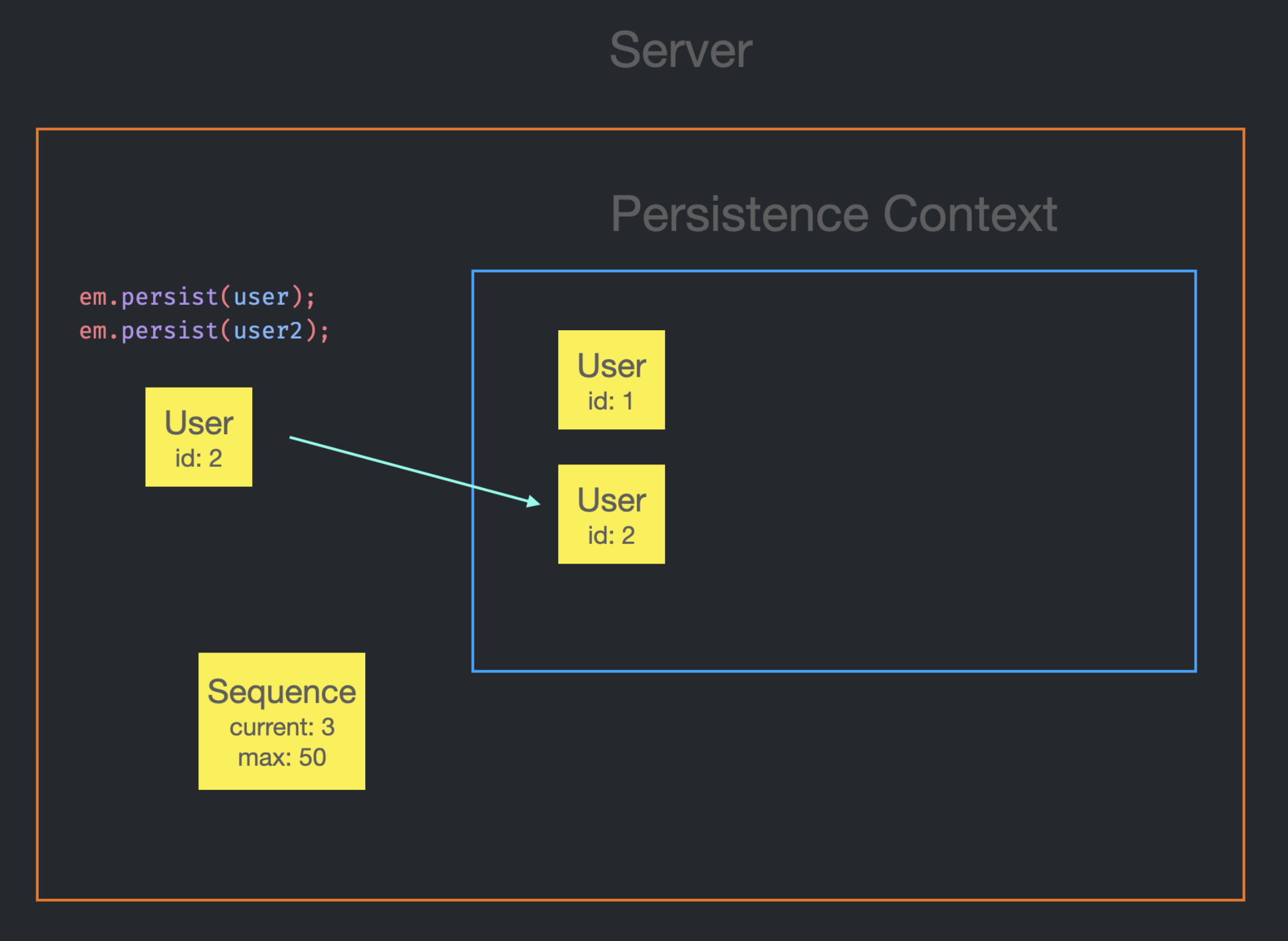
이제 id가 존재하기 때문에 user2는 Persistence Context에 잘 저장된다.
sequence로부터 id로 사용될 값을 가져올 수 있기 때문에 current가 max가 될 때까지는 DB에 요청을 보내지 않고도 id를 설정할 수 있게 된 것이다.
current가 max보다 커지는 경우는 어떨까

처음 DB에서 current로 1, max로 50을 가져올 때, DB의 sequence는 51이 되었다.
이는 1 ~ 50 까지의 id를 현재 Application에서 사용할 것이며, 50이 넘어가는 값은 id로는 사용해서는 안 된다는 의미다.
51을 사용하고 싶으면 다시 DB에 요청을 보내서 51 ~ 100 까지의 id를 사용하겠다고 DB에게 알려줘야 한다.
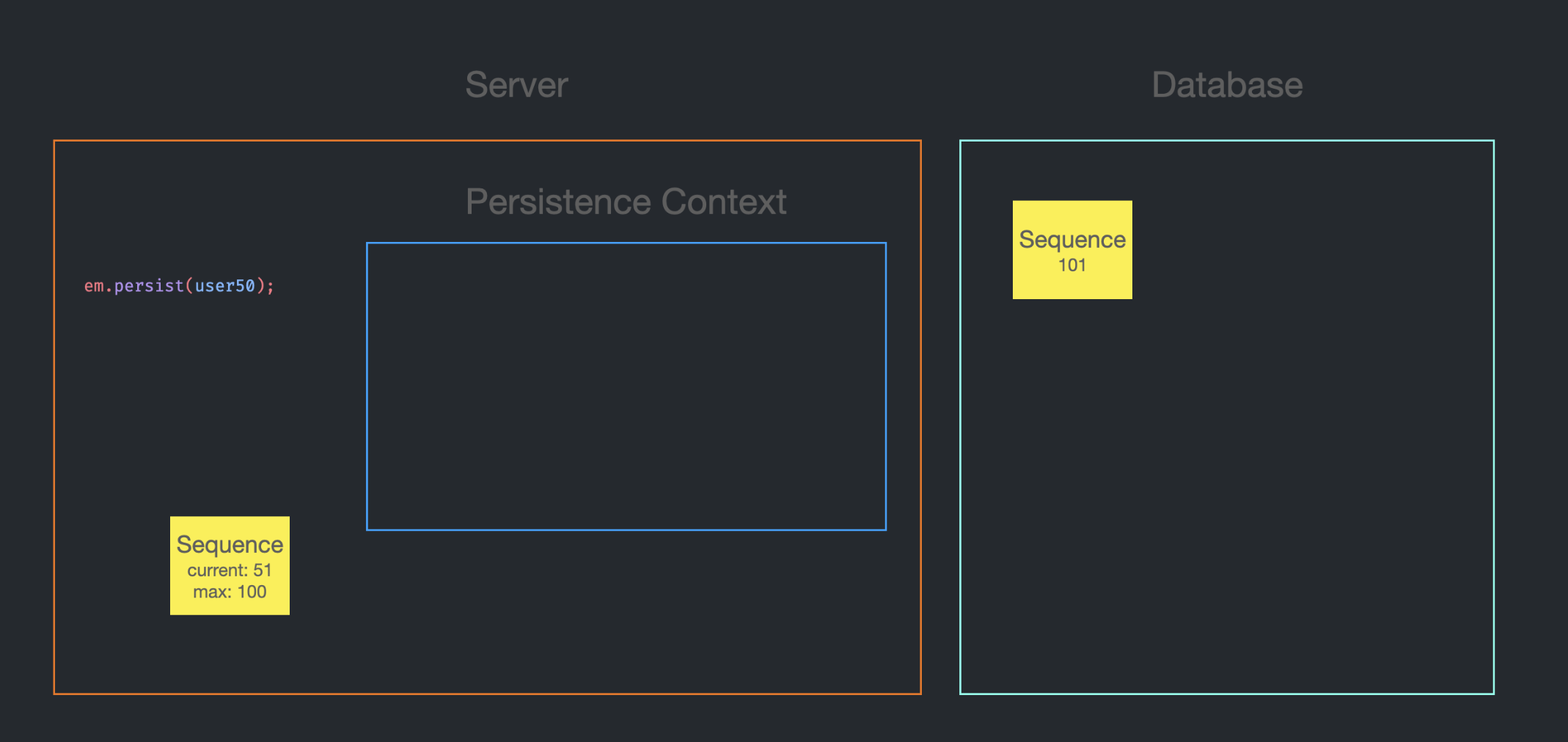
그 결과, 위와 같이 DB의 sequence는 101로 설정되고, Application의 sequence는 current 51, max 100이 될 것이다.
SEQUENCE strategy는 이렇게 한 번에 DB의 sequence를 50씩 올리면서 50개의 id를 사용하는 동안 따로 요청을 보내지 않고 id를 설정할 수 있는 전략을 뜻한다.
id를 매 번 DB로부터 부여받는 것이 아니라, 미리 당겨와서 쓰는 것이다.
그렇다면 다음과 같은 상황에서 SQL이 어떻게 전송될지 예상해보자.
// UserTest.java
@Test
void test() {
User user = new User();
// DB에 요청을 보내서 sequence 범위를 1 ~ 50로 설정
em.persist(user);
System.out.println("--------------------");
// 실제 insert into SQL 전송
em.flush();
}1 ~ 50 범위의 sequence를 미리 당겨오기 때문에 1개의 user_seq를 가져오고, 1번의 insert가 발생한다.
중간에 "--------------------"을 출력한 것은 insert into SQL이 em.flush 호출 이후에 전송되는지 확인하기 위함이다.
Hibernate:
select
next value for user_seq
Hibernate:
insert
into
"user"
(name, id)
values
(?, ?)그렇다면 2개의 User Entity를 persist 할 때는 어떨까.
// UserTest.java
@Test
void test() {
User user = new User();
// DB에 요청을 보내서 sequence 범위를 1 ~ 50로 설정
em.persist(user);
User user2 = new User();
// DB에 요청을 보내서 sequence 범위를 51 ~ 100으로 설정(1 ~ 50이 이미 있으므로 2 ~ 100이 될 것)
em.persist(user2);
System.out.println("--------------------");
// 실제 insert into SQL 2개 전송
em.flush();
}아마 많은 사람들이 sequence를 1번 요청할 것이라고 예상했을 것이다.
그러나 Console에 출력된 결과는 다음과 같다.(insert는 생략했다.)
Hibernate:
select
next value for user_seq
Hibernate:
select
next value for user_seq이 부분이 헷갈릴 수 있는데, 잘 이해가 안되면 id 1 ~ 50 범위를 가져올 때만 2번 호출된다고 생각하고 넘어가도 무방하다.(이후로 51 ~ 100, 101 ~ 150 범위 등은 1번 호출)
처음에는 Application에 sequence가 존재하지 않기 때문에 DB에 요청을 보내서 1 ~50 범위의 sequence를 가져오는 것은 동일하다.
그러나 2번째 요청에서 sequence를 또 가져오는 것은 조금 이상하게 느껴질 것이다.
이유는 Jpa 최적화 때문이다.
sequence 범위가 1001 ~ 1050이라고 생각하면, 1050번 id를 사용할 때가 되어서야 1051 ~ 1100 sequence를 가져오는 것이 아니라, 1002번 id를 사용할 때, 1051 ~ 1100 범위의 sequence를 미리 요청해서 받아두는 것이다.
이 때문에 처음 id 1, 2번을 사용하면 2번째 id 사용 시, 51 ~ 100을 미리 요청하여 2번의 요청이 나가는 것이다.
그 뒤로는 51번 id를 사용하려고 할 때 이미 51 ~ 100 범위의 sequence를 받아 두었기 때문에, 52일 때 101 ~ 150만 요청하면 되므로 50개의 id를 사용할 때마다 1번의 요청만 나가게 되는 것이다.
이 부분은 현재로서는 크게 중요하진 않으니 이해가 잘 안되면 직접 실험을 해보거나 넘어가도록 하자.
한가지 기억해 둘 것은, PostgreSQL과 달리 MySQL는 SEQUENCE를 지원하지 않기 때문에 SEQUENCE strategy 선택 시, 자동으로 TABLE 전략이 선택된다.
SEQUENCE와 달리 TABLE 전략은 성능 이슈가 있기 때문에 MySQL은 IDENTITY 전략을 주로 사용한다.
PostgreSQL일 때만 SEQUENCE 전략을 사용하도록 하자.
IDENTITY Strategy
다음과 같이 설정을 변경했다.
// User.java
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int age;
}MySQL의 AUTO_INCREMENT, PostgreSQL의 serial을 사용하면 DB에 새로운 Record를 삽입할 때마다 자동으로 id를 부여한다.
IDENTITY 전략은 이를 그대로 이용한다.
id가 없는 Entity를 생성한 뒤, DB에 insert 할 때 id가 생성되는 것이다.
즉, id를 설정하기 위해서 em.persist를 호출할 때마다 insert SQL을 날려야 한다는 의미가 된다.
@Test
void test() {
User user = new User();
// persist를 위한 id를 얻기 위해 DB에 insert into SQL 전송
em.persist(user);
User user2 = new User();
// persist를 위한 id를 얻기 위해 DB에 insert into SQL 전송
em.persist(user2);
System.out.println("--------------------");
// SEQUENCE 전략에서는 em.flush 호출 시점에 insert into SQL 전송
em.flush();
}위 코드를 실행하고 Console을 통해 결과를 확인해보자.
Hibernate:
insert
into
"user"
(name, id)
values
(?, default)
Hibernate:
insert
into
"user"
(name, id)
values
(?, default)
----------구분선 위쪽에 SQL이 출력되는 것을 볼 수 있다.
즉, em.flush가 호출되기 이전인 em.persist 시점에 SQL이 출력됨을 확인한 것이다.
이 과정을 도표로 다시 한 번 살펴보자.
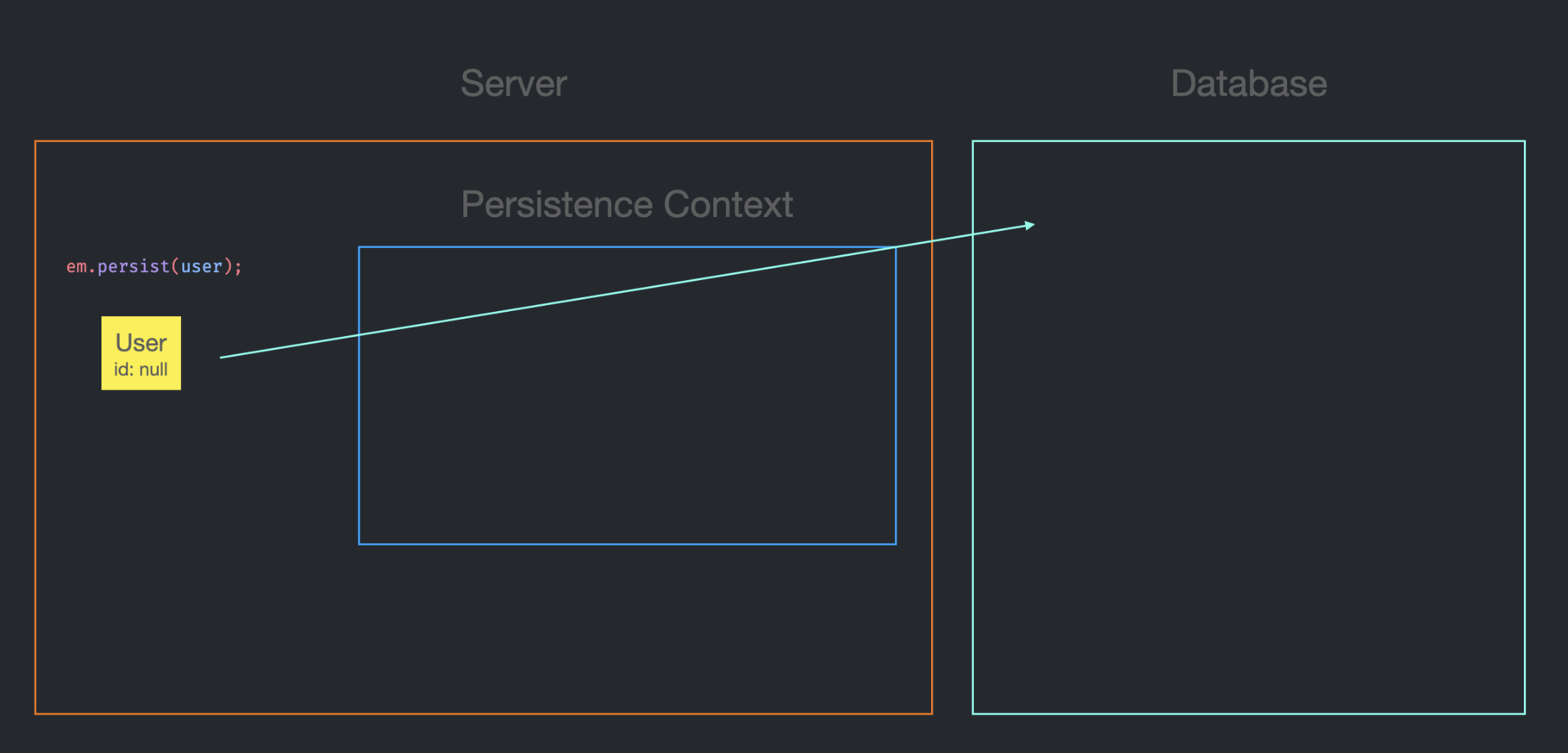
id가 null인 User Entity를 생성하고, em.persist를 호출한다.
SEQUENCE 전략과 달리, id를 받아올 sequence 객체가 Application 상에 존재하지 않는다.
고로 Application에서 id를 생성할 방법이 없기 때문에 DB에 insert into SQL을 전송한다.
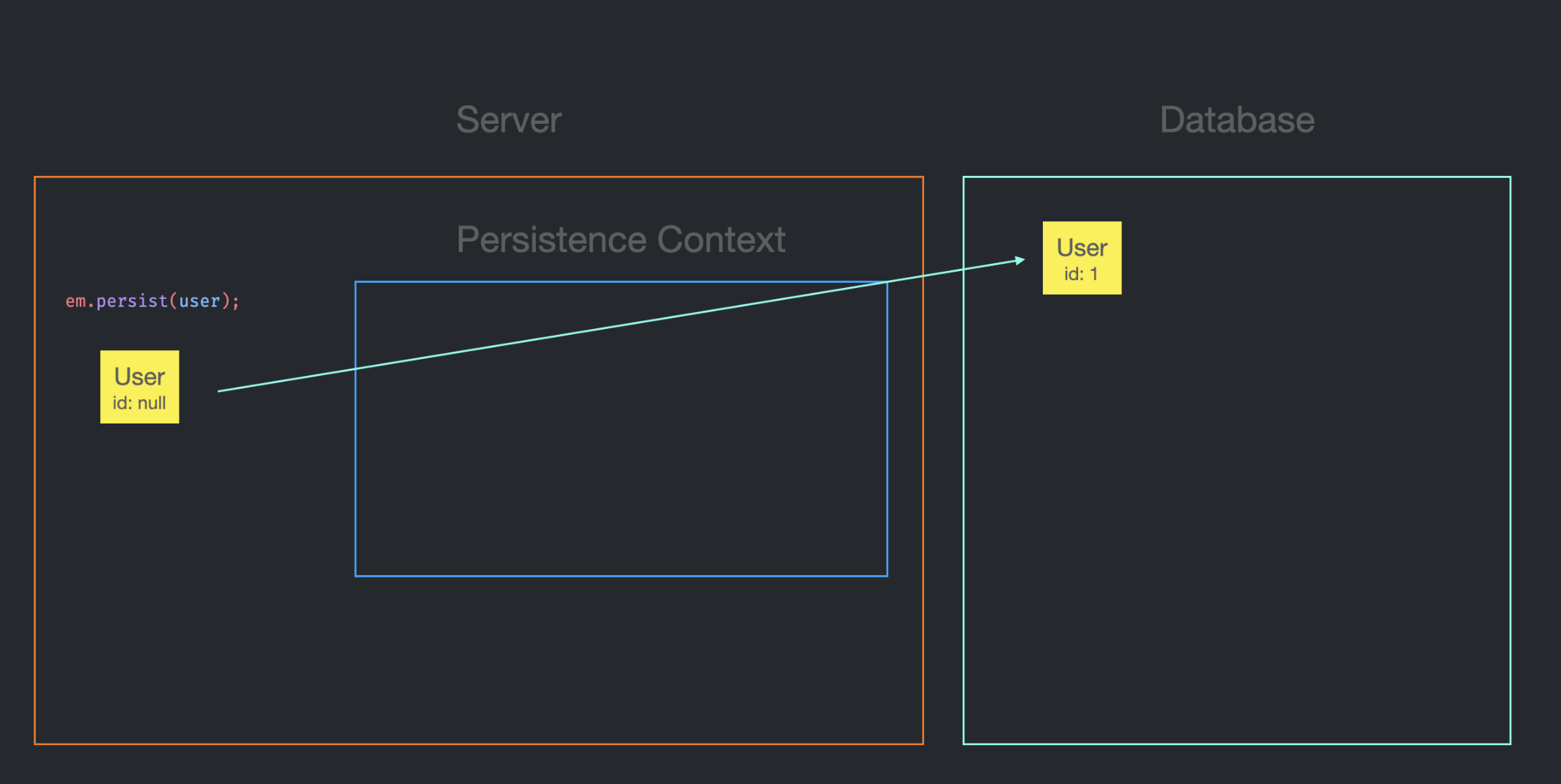
DB에서 id를 1로 설정하여 Record를 저장했다.
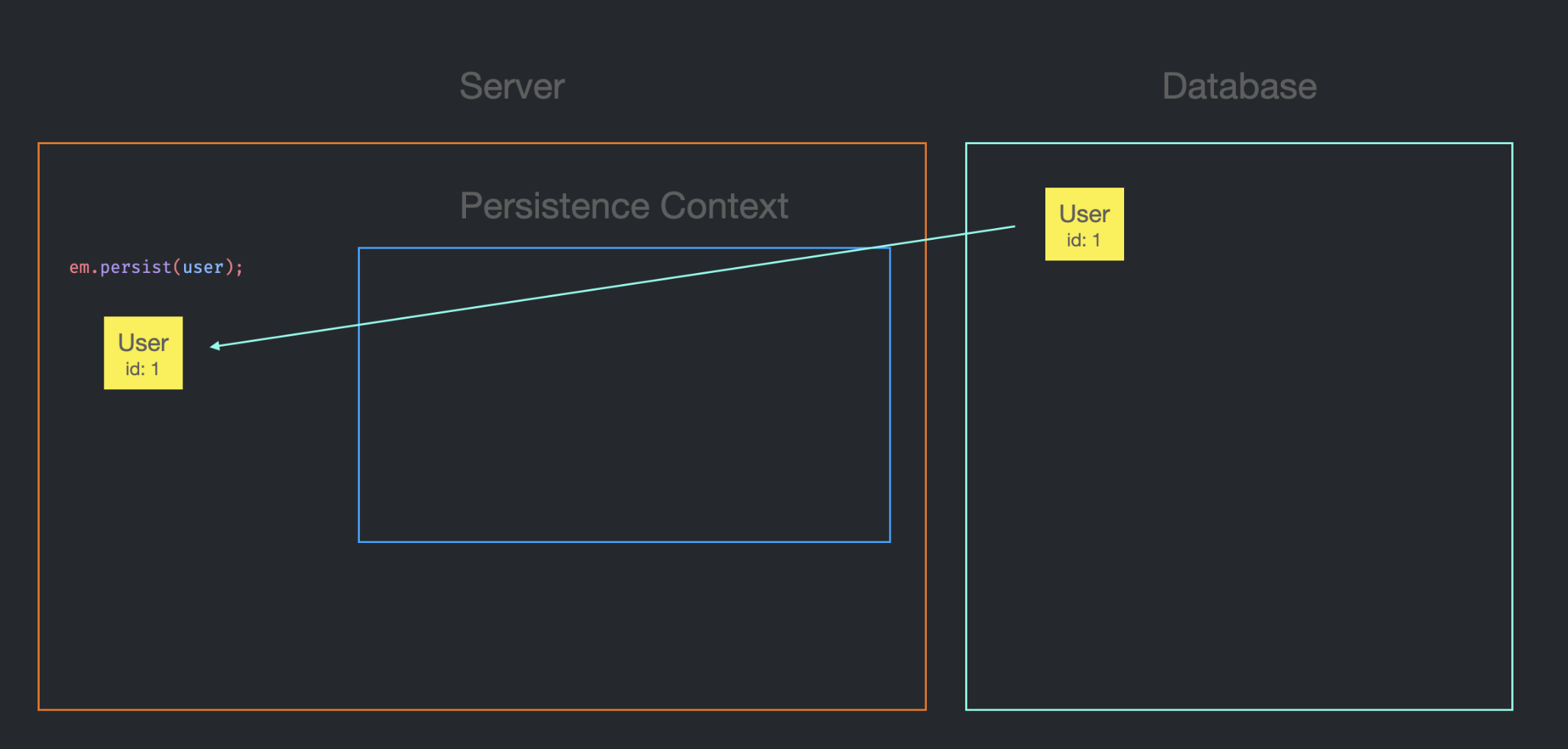
DB로부터 id를 가져와서 Application User Entity에 반영한다.
이제 id가 존재하므로 Persistence Context에 Entity를 저장할 수 있게 되었다.
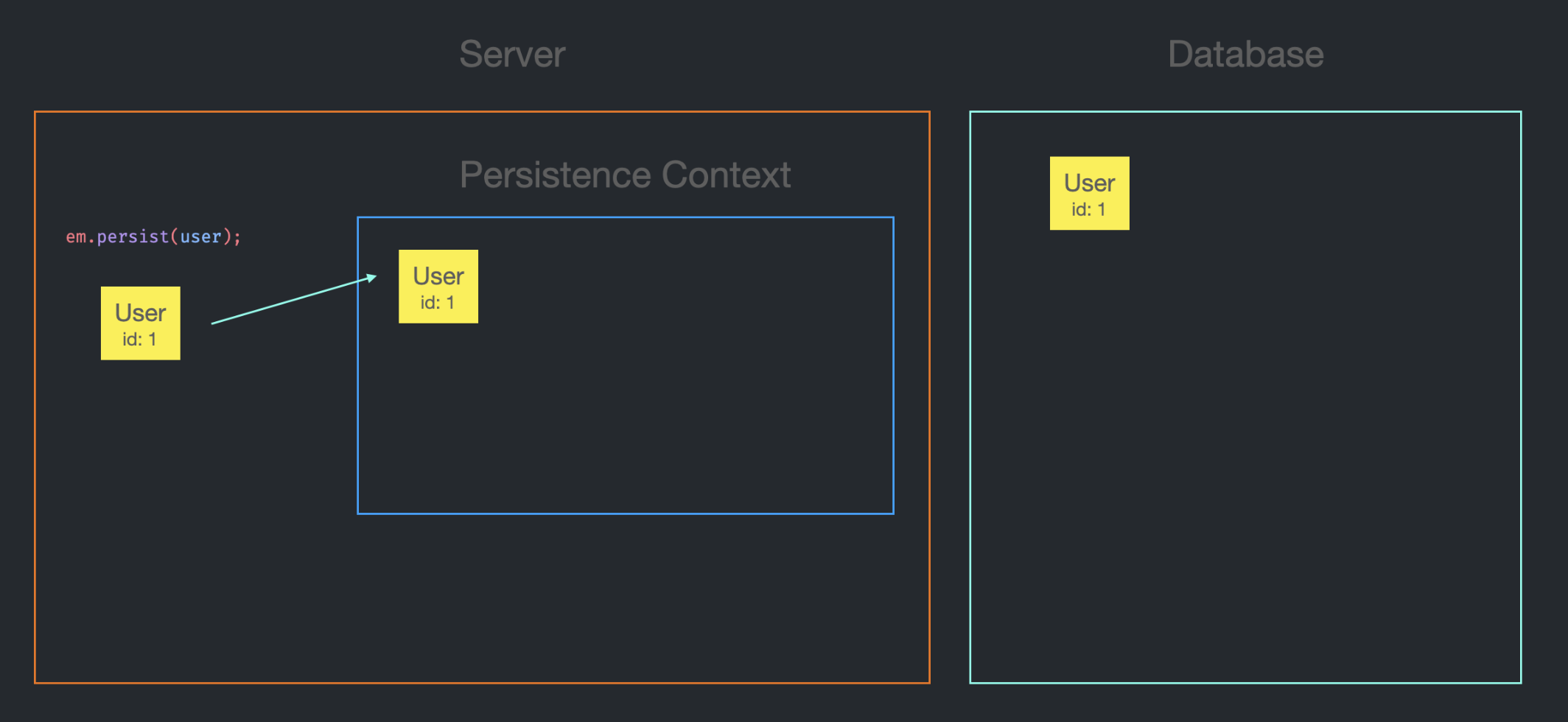
최종적인 그림은 위와 같다.
한 번에 여러 Entity를 모아서 전송하는 SEQUENCE 전략을 먼저 봤기 때문에 언뜻 매우 비효율적인 방식처럼 느껴질 수도 있겠지만, 몇 백, 몇 천 건이 넘는 대량의 데이터를 저장하는 것이 아니라면 큰 성능 차이는 없을 것이다.
단, 일반적인 용례가 아니라 대량의 데이터를 삽입할 때는 JDBC Template 등을 이용한 Batch 처리가 필요할 것이다.
Table Strategy
Sequence를 미지원하는 MySQL 등의 DB에서 Table을 하나 생성해서 Sequence를 흉내내는 방법이다.
내부적으로 Pessimistic Lock을 걸기 때문에 Lightweight Lock을 거는 sequence에 비해 느려서 성능 이슈가 발생할 수 있다.
// User.java
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.TABLE)
private Long id;
private String name;
private int age;
}그로 인해 실제로는 사용되지 않는다고 하니 여기까지만 정리하겠다.
UUID Strategy
UUID는 고유성을 보장하기 위해 만들어진 128bit 길이의 숫자 + 알파벳으로 이루어진 id다.
여러 가지 버전이 있지만, 일반적으로 v4가 사용되며,
v4 기준 중복 확률은 초당 100만개의 ID를 100년동안 생성 할 시, 약 0.00009%라고 한다.
조 단위 이상의 Record를 만들어야 중복이 날까 말까 라고 생각하면 될 것 같다.
코드는 다음과 같다.
// User.java
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.UUID)
private Long id;
private String name;
private int age;
}이것도 흐름은 Sequence, Table 전략과 동일하다.
단, 지금까지는 1씩 증가하는 정수를 id로 사용했었기 때문에 DB에서 id를 어디까지 사용했는지 받아왔어야 했는데 UUID는 중복 가능성이 매우 낮기 때문에 그냥 Application에서 자체 생성해서 넣어주면 된다.
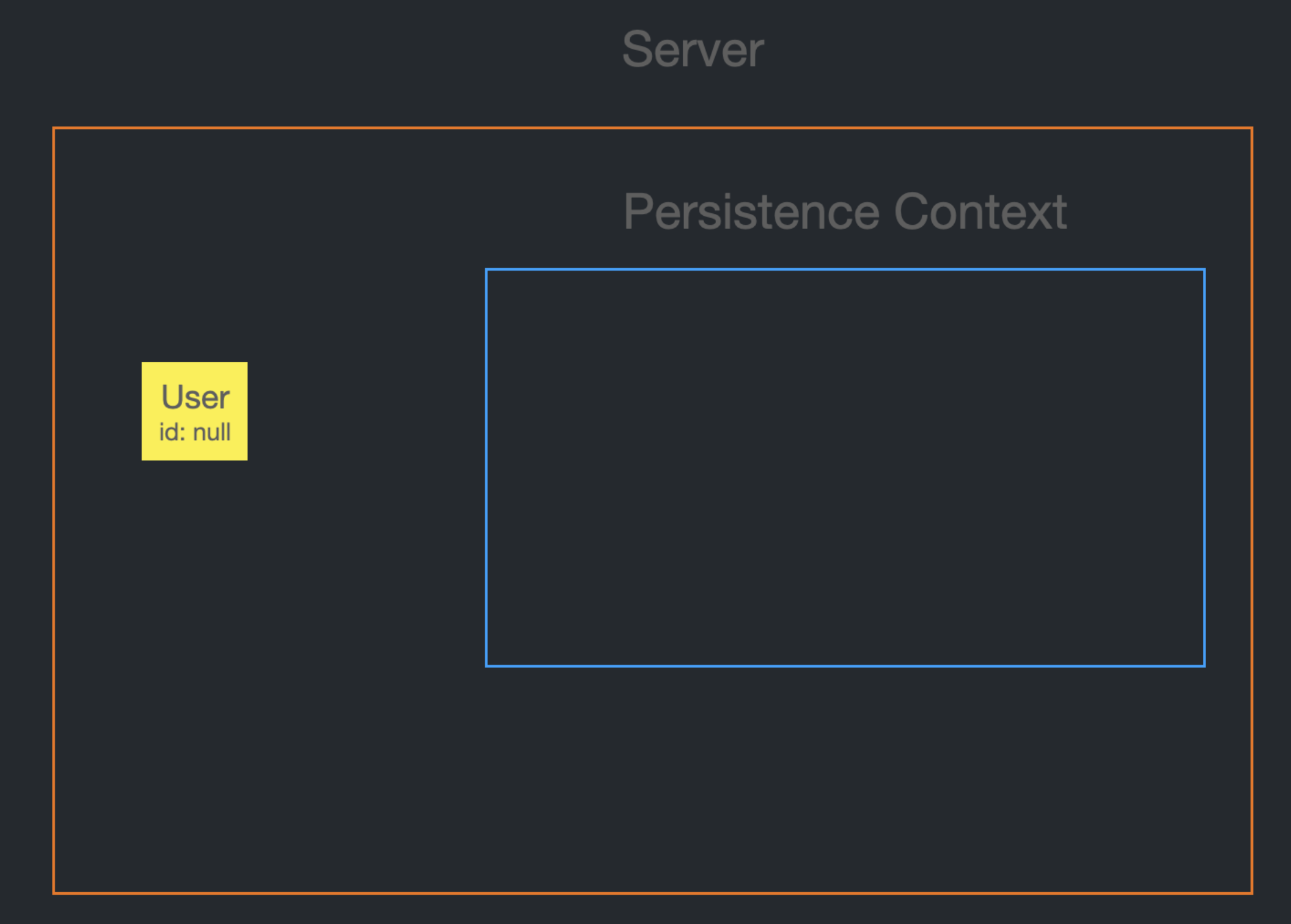
일단 User Entity 생성할 때는 id가 null이다.
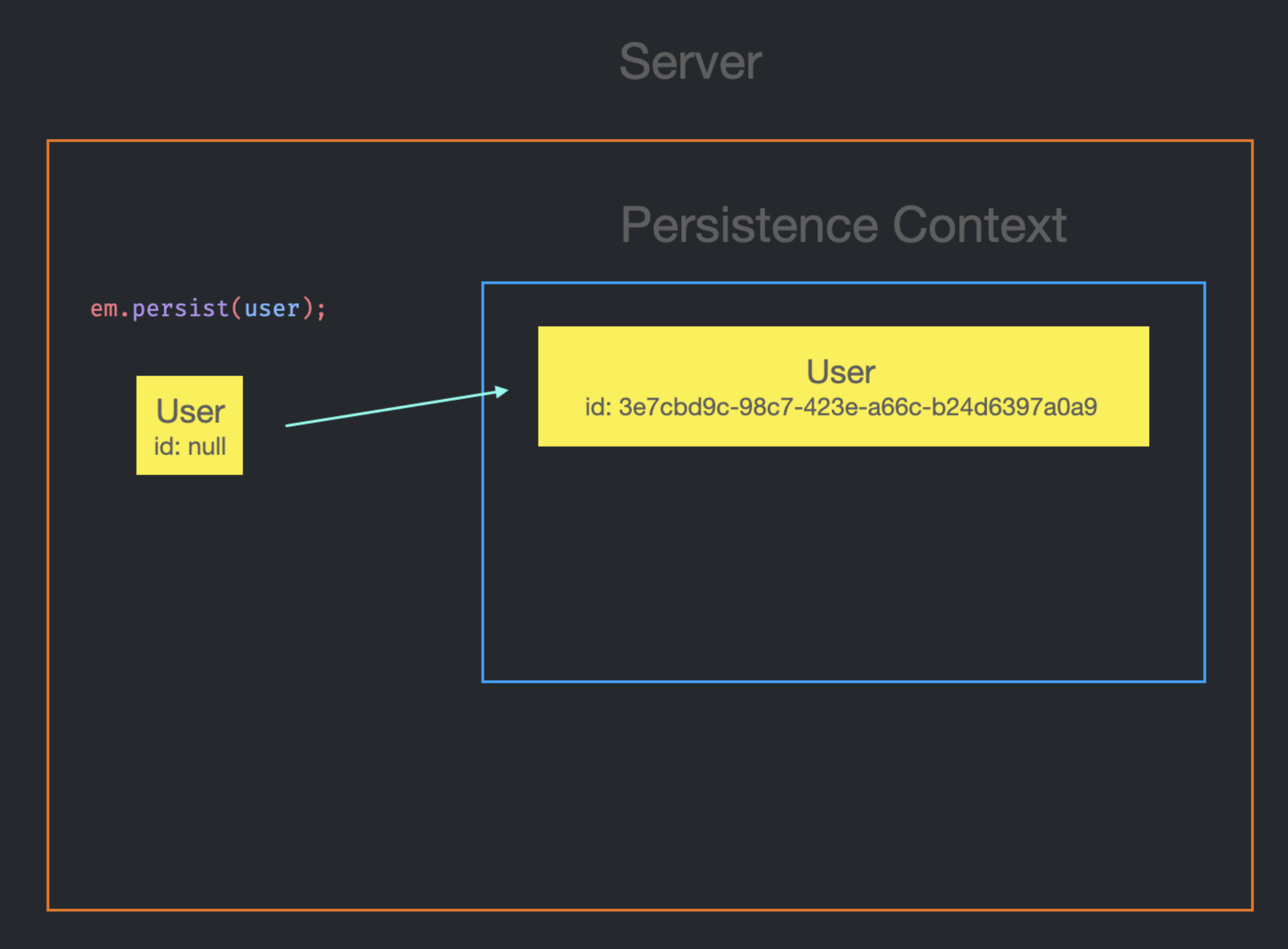
em.persist를 호출할 때 비로소 UUID Generator에 의해 자동으로 랜덤 UUID가 생성 및 설정된다.
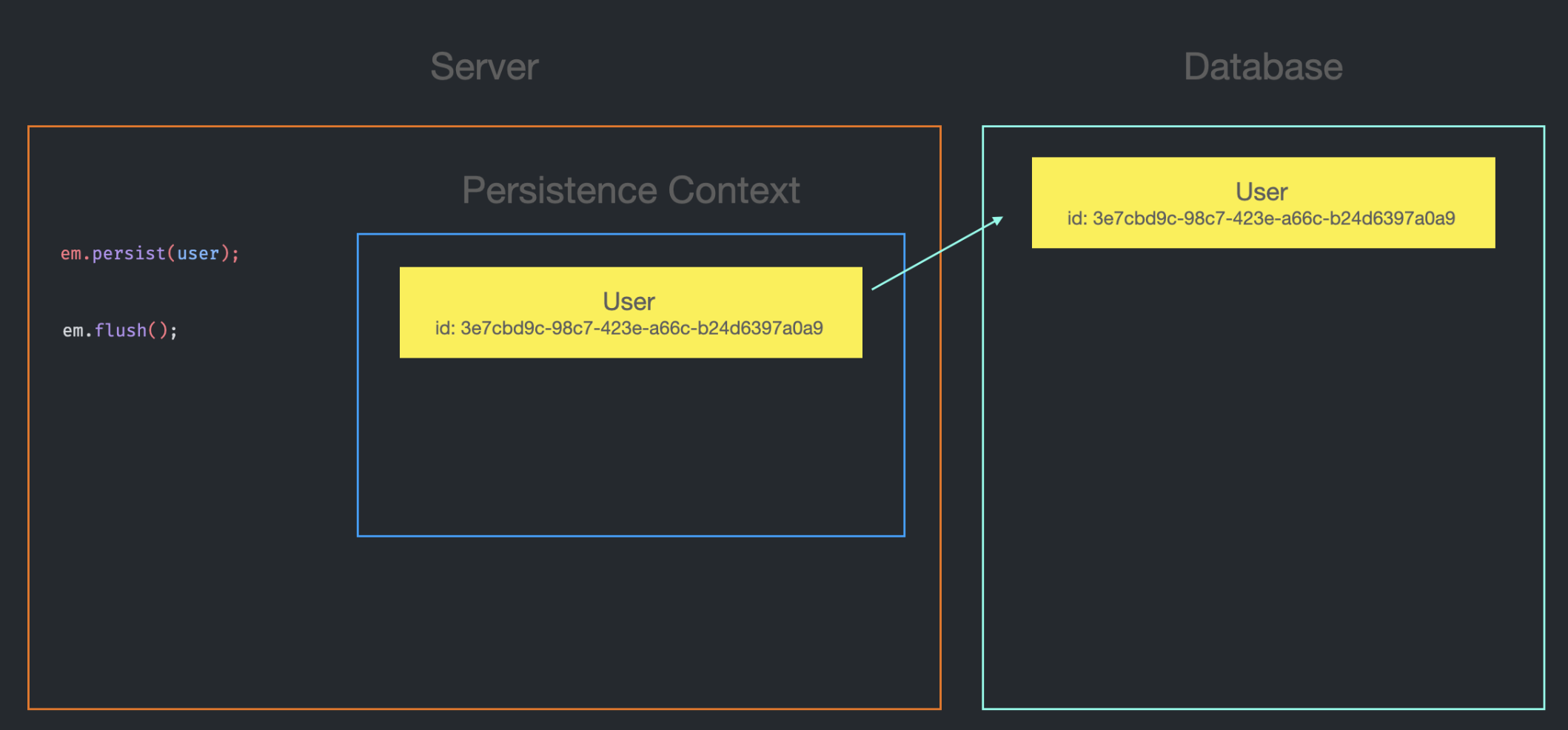
마지막으로 em.flush가 호출되는 시점에 DB에 실제 SQL이 전송되어 Record가 저장된다.
1씩 증가하는 정수 타입의 id를 사용할 경우는 DB로부터 id를 어디까지 사용했는지 SEQUENCE, TABLE 전략이라면 id를 50개(설정에 따라 바뀜) 사용할 때마다 DB에 요청을 보내서 다음 id 범위를 가져와야 하고, IDENTITY 전략이라면 em.persist를 호출할 때마다 DB에 요청을 보내서 id를 DB로부터 생성해서 받아와야 한다.
그러나 UUID는 그럴 필요가 없다.
그냥 Application에서 UUID를 생성하여 DB에 저장하면 된다.
중복 위험이 매우 낮기 때문에 Record 수가 적다면 아예 중복 체크를 안 해도 될 것이고, 중복 되어도 큰 문제가 생기지 않을 때도 마찬가지일 것이다.
그러나 UUID는 보통 수백 억 개의 Record가 존재하는 분산 시스템 환경에서 주로 사용된다고 알고 있기 때문에, UNIQUE constraint을 걸어서 중복 확인을 해주면 될 것 같다.
Auto Strategy
앞서 살펴봤듯, @GeneratedValue에 strategy를 지정하지 않을 경우 기본적으로 AUTO가 되며, 사용하는 DB에 따라 다르게 설정되기 때문에 strategy를 지정해주는 것이 권장된다.
@Id
@GeneratedValue
private UUID id;우선 DB 종류와 상관 없이, 식별자의 타입을 UUID로 설정하면 자동으로 UUID 전략이 적용된다.
@Id
@GeneratedValue
private Long id;Integer, Long 등의 정수형 타입인 경우, DB에서 sequence를 지원하면 SEQUENCE 전략이 선택되고, 지원하지 않으면 TABLE 전략이 선택된다.
TABLE은 테이블을 생성하여 SEQUENCE를 흉내내는 것이었다.
즉, 전략을 명시하지 않으면 MySQL은 TABLE, PostgreSQL은 SEQUENCE 전략을 사용하게 된다.
단, 추가 설정이나 버전 등에 따라 예상치 못하게 바뀔 수 있기 때문에 전략을 명시해주는 것이 좋다.
마지막으로 어떤 전략을 사용하더라도 id는 em.persist를 호출할 때 생성되며, Persistence Context에 Entity가 저장되기 위해서는 id가 반드시 필요하다는 사실을 기억해두자.
