
지난 장에서 작성한 코드를 그대로 사용하되,
테스트 코드 중 em.clear를 주석 처리하고 테스트를 다시 실행해보자
// UserTest.java
@Test
void test() {
for (int i = 0; i < 10; i++) {
User user = User.builder()
.name("user" + i)
.build();
for (int j = 0; j < 100; j++) {
Post post = Post.builder()
.author(user)
.title("post" + j)
.content("content" + j)
.build();
em.persist(post);
}
em.persist(user);
}
em.flush();
// em.clear();
System.out.println("----------em.createQuery----------");
List<User> foundUsers = em.createQuery("select u from User u", User.class)
.getResultList();
for (User foundUser : foundUsers) {
foundUser.getPosts();
}
}Console 맨 아래로 내려보면 다음과 같은 오류가 발생한다.
java.lang.IndexOutOfBoundsException: Index 0 out of bounds for length 0
at java.base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64)
at java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70)
at java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:266em.clear를 호출하지 않았기 때문에 이전에 만들었던 user Entity 10개가 여전히 Persistence Context에 남아 있는 상태일 것이고,
em.createQuery를 호출했을 때, 아직 DB에 저장되지 않은 user, post Entity가 존재하므로 변경 감지를 하고, em.flush가 자동으로 호출되어 Persistence Context에 존재하는 user Entity를 먼저 insert 시킨 후, select SQL을 전송하여 DB로부터 Entity를 가져왔을 것이다.
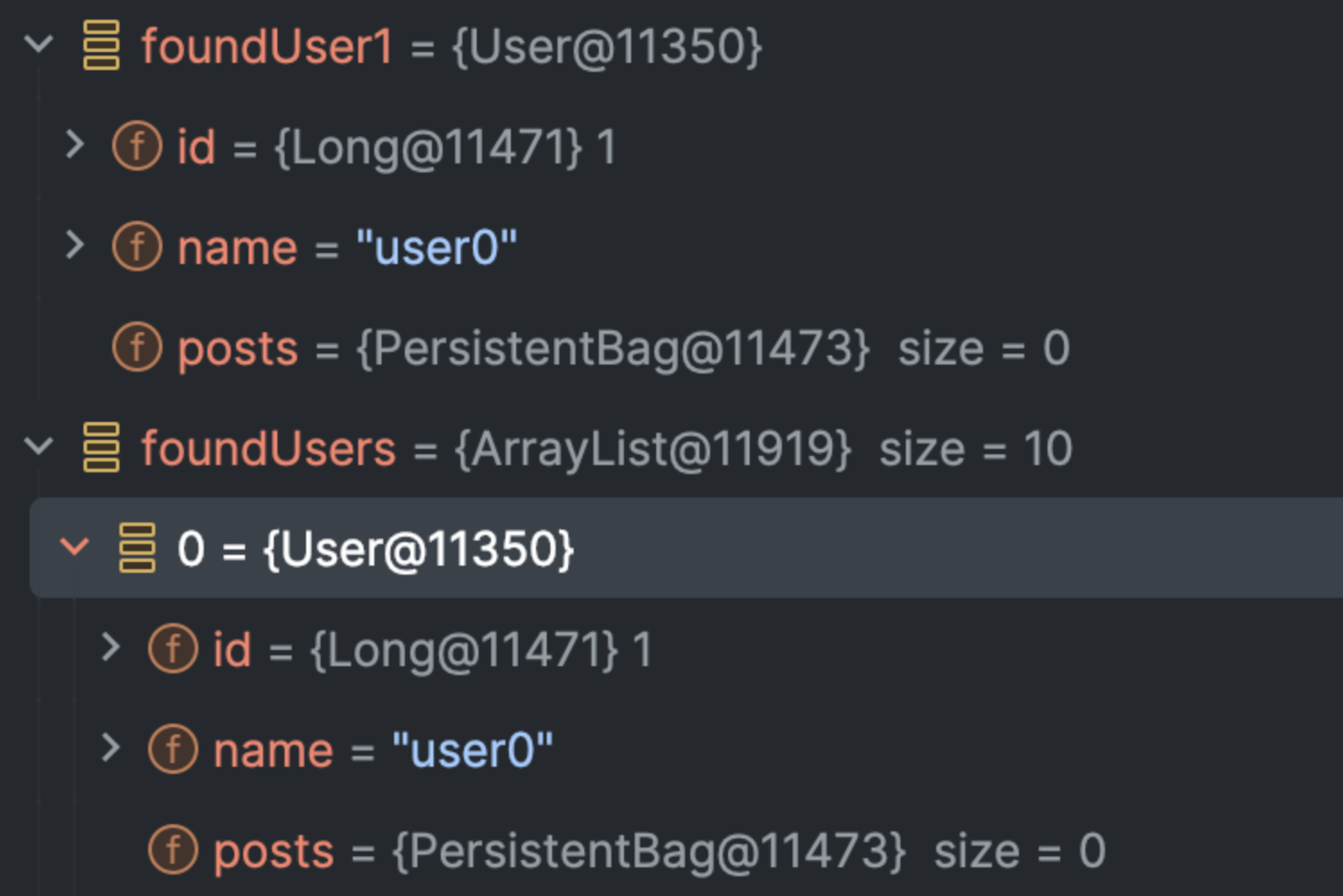
디버깅을 한 결과, Persistence Context에서 가져온 user나 DB에서 가져온 user가 모두 User@11350으로 동일하다는 것을 확인할 수 있다.
(foundUser1이 Persistence Context에서 가져온 Entity, foundUsers[0]이 DB에서 가져온 Entity)
모든 Entity는 고유한 id로 구분되기 때문에 DB에서 가져온 user Entity가 Persistence Context 내의 user Entity와 차이가 없으면 그냥 버려지는 것으로 추측된다.
그런데 user는 1:N에서 1이기 때문에 FK가 존재하지 않는다.
즉, user가 가진 post에 대한 정보가 DB에 없는 것이다.
그래서 post가 1000개 추가 되었더라도 user는 이를 전혀 감지할 수 없다.
이를 감지하기 위해서는 user.posts에도 post Entity를 추가해줬어야 하는 것이다.
현재 user는 Application 상에서 다음과 같은 상태다.
user: {
name: "user0",
posts: [], // 빈 리스트
}post.setUser는 호출했어도 user에 따로 post를 추가한 적이 없기 때문이다.
그럼 Jpa는 이를 보고 user.posts가 비어있다고 판단하여 em.createQuery로 user를 다시 가져오더라도, post에 대한 추가적인 SQL을 내보내지 않게 된다.
EAGER이던 LAZY던 말이다.
그냥 빈 리스트라고 판단하여 IndexOutOfBounds 오류가 발생하는 것이다.
이를 해결하기 위해서는 반드시 user에도 post Entity를 등록해야 한다.
코드를 다음과 같이 수정하고 테스트를 다시 실행해보자.
// UserTest.java
@Test
void test() {
for (int i = 0; i < 10; i++) {
User user = User.builder()
.name("user" + i)
.build();
for (int j = 0; j < 100; j++) {
Post post = Post.builder()
.author(user)
.title("post" + j)
.content("content" + j)
.build();
// user instance에 post를 등록
user.getPosts().add(post);
em.persist(post);
}
em.persist(user);
}
em.flush();
// em.clear();
System.out.println("----------em.createQuery----------");
List<User> foundUsers = em.createQuery("select u from User u", User.class)
.getResultList();
for (User foundUser : foundUsers) {
foundUser.getPosts();
}
}이제 정상적으로 실행된다.
현재 구조 상 user는 post를 필드로 가지고, post는 user를 필드로 가지는, 양방향 연관 관계이다.
이렇게 양방향 연관 관계를 갖는 Entity를 만들 경우, 위와 같은 오류를 방지하기 위해서 반드시 양 쪽 다 연관 관계 필드에 서로를 할당해야 한다.
애초에 setter 자체가 지양되기도 하고, 이를 수동으로 setter를 호출 하다보면 잊어버리기 쉽기 때문에
연관 관계 편의 메소드라는 것을 만들어서 실수를 방지할 수 있도록 자동화 하는 것이 좋다.
// User.java
public void addPost(final Post post) {
post.setAuthor(this);
posts.add(post);
}로직은 매우 간단하다.
User 클래스에서 post를 인자로 받아서 post를 추가하기 전에 setAuthor를 호출하여 양 쪽의 연관 관계 필드를 동기화 시켜주면 된다.
// UserTest.java
Post post = Post.builder()
// .author(user)
.title("post" + j)
.content("content" + j)
.build();
// user에 post, post에 user 양방향 등록
user.addPost(post);
em.persist(post);테스트 코드에서 post를 생성할 때, author를 넣는 부분을 주석 처리하고 user.addPost만 넣고 실행해보자.
아주 잘 실행될 것이다.
생각해 볼만한 부분이 하나 더 있는데, 양방향 관계인 경우, 연관 관계 편의 메소드가 어느 Entity에 존재해야 하는 것이 바람직할지에 대해서다.
user가 아닌 post 쪽에 연관 관계 편의 메소드를 작성할 수도 있고, 양쪽에 작성할 수도 있을 것이다.
우선 양쪽에 작성하면 같은 일을 하는 다른 메소드가 2개가 되어 혼동될 가능성이 크다고 생각된다.
이는 배제하고 나머지를 보면, 1:N 관계에서 N(post) 쪽에 작성하는 것보다 1(user) 쪽에 작성하는 것이 좀 더 낫다고 생각한다.
user has post라는 명제는 참이다.
이렇듯 보통 1이 N을 소유하는 관계이기 때문이다.
고로 user 없이는 post도 존재할 수 없으며, user의 생명 주기가 post보다 항상 같거나 길다.
user가 post를 삭제할 일은 있어도, post가 user를 삭제할 일은 없기 때문이다.
이러한 소유 관계에서 user에 post를 관리하는 메소드가 들어가는 것이 보다 직관적이라고 생각한다.
em.clear 호출 시 잘 실행되는 이유
연관 관계를 양방향에 모두 세팅 해주지 않아도 em.clear를 호출하면 잘 실행되었던 것이 기억날 것이다.
이 때, 연관 관계가 1:N인 경우, user.posts를 new ArrayList<>()로 필드 초기화를 했었는데, 이는 Jpa 내부적으로 PersistentBag라는 Instance로 래핑된다.
이 PersistentBag 내부에 '초기화 여부'를 저장하는 initialized 필드가 존재하는데, em.clear를 호출하지 않은 경우에는 다음과 같이 user.posts가 빈 리스트인 상태로 Persistence Context에 남아 있는데, initialized 상태가 되어 EAGER든 LAZY든 추가 SQL을 날리지 않게 된 것이다.
user: {
name: "user0",
posts: [], // initialized
}그런데 만약 em.clear를 호출해서 Persistence Context에 새로 user Entity를 가져와서 덮어버리면 initialized가 false로 설정되어 추가 SQL을 내보내서 DB에서 post를 가져오기 때문에 문제가 발생하지 않은 것이다.
