
지난 장에서 Persistence Context의 동작 방식에 대해서 알아봤다.
이번 장은 내용이 이어지기도 하므로, 만약 이에 대해 정확히 숙지가 되지 않았다면 다시 저번 장을 보도록 하자.
지난 장에서 봤던 내용을 간단히 정리해보면,
먼저 User Entity를 생성하고, em.persist를 호출하여 Persistence Context에 Entity를 저장하였다.
그리고 em.flush를 호출할 때, Persistence Context 내에 위치한 모든 Entity가 실제 SQL로 변환되어 DB에 전송, 저장되었다.
이렇게 저장된 User Entity는 Persistence Context, DB에 공존하는 상태가 된다.
이후 em.find로 User Entity 한 개를 찾아오게 되면, 캐시 지역성에 의해 메모리, DB 중 더 가까운 곳에 있는 Entity를 가져오게 되는데,
em.find를 통해 User Entity를 찾아올 때는 먼저 Persistence Context를 찾아본 뒤, 있으면 Entity를 즉시 반환하고, 없으면 DB에 select 문을 보내서 Entity를 DB로부터 가져온다.
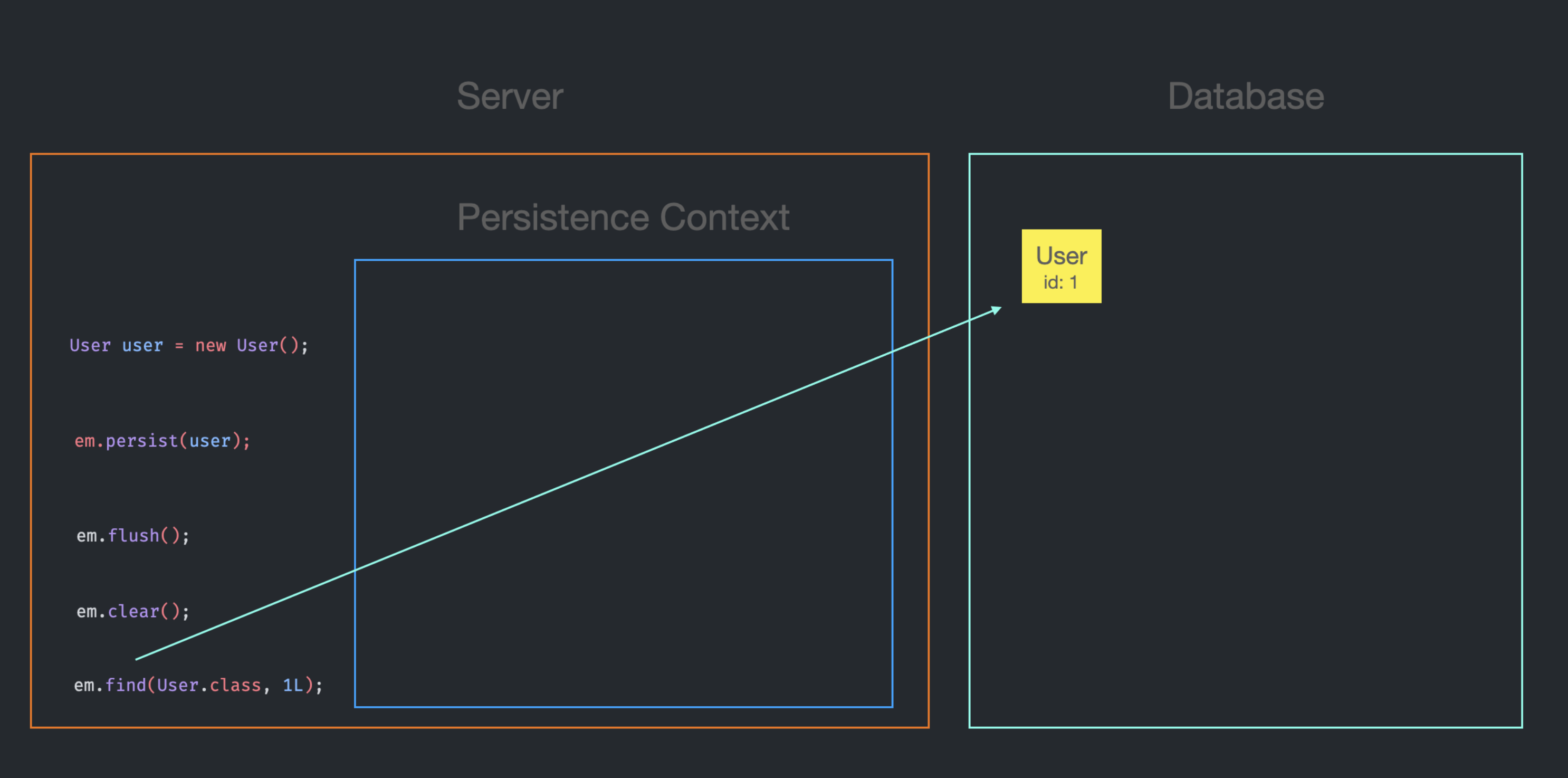
즉, 위와 같은 상황이 된다.
이 때, Persistence Context에 id가 1인 User Entity가 존재하지 않으므로, DB에서 가져오는 User Entity는 Persistence Context에도 저장된다.
em.find 호출 이후의 상황은 다음과 같을 것이다.
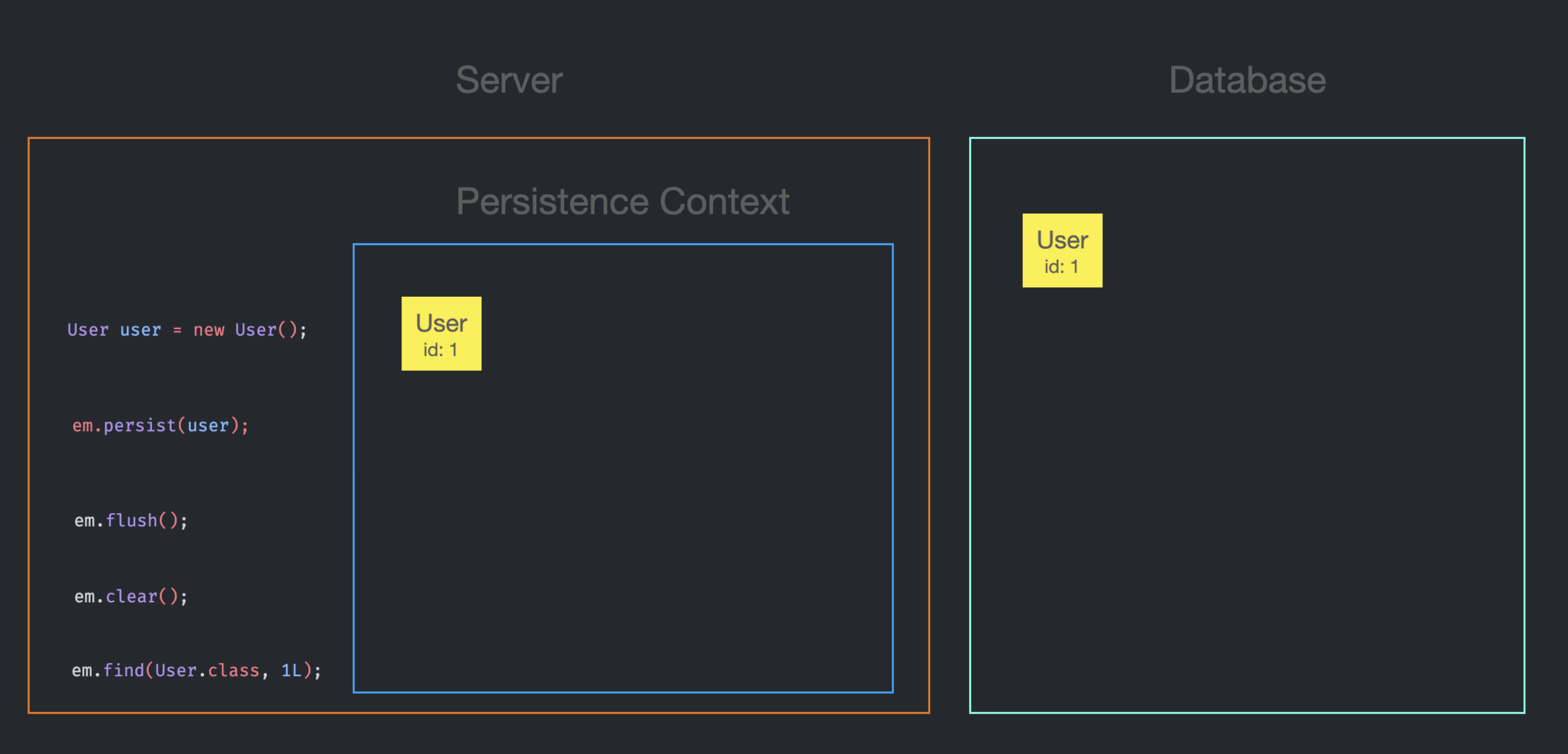
이러면 다음번에 em.find로 동일한 id를 가진 User를 찾을 때, DB 호출을 보낼 필요가 없을 것이다. Persistence Context에 찾아오면 되니까.
em.find를 사용하는 경우는 2가지 케이스로 정리할 수 있겠다.
1. Persistence Context에 Entity가 존재하는 경우
em.find를 호출하면 우선 동일한 id를 가진 Entity가 있는지 Persistence Context를 뒤져본다.
존재하기 때문에 이를 반환하고 DB에 SQL을 전송하지 않는다.
2. Persistence Context에 Entity가 존재하지 않는 경우
em.find를 호출하면 우선 동일한 id를 가진 Entity가 있는지 Persistence Context를 뒤져본다.
존재하지 않기 때문에 DB에 SQL을 전송하여 Entity를 가져온다.
가져온 Entity를 Persistence Context에 저장하고, em.find 호출자에 반환한다.
JPQL
em.find는 Entity를 1개밖에 가져올 수 없다.
다수의 Entity를 가져오는 경우는 em.createQuery를 통해 JPQL을 사용해야 한다.
1000개의 Entity를 가져올 때, 반복문을 통해 다음과 같이 em.find를 여러 번 호출할 수도 있긴 하다.
List<User> foundUsers = new ArrayList();
for (long i = 0; i < 1_000; i++) {
User foundUser = em.find(User.class, i);
foundUsers.add(foundUser);
}그런데 보통 다수의 Entity를 가져올 때는 '특정 조건'을 지정한다.
예를 들어 select * from "users" where age > 10 limit 1000 이런식으로 말이다.
em.find는 오직 id만 지정할 수 있기 때문에 다음과 같은 SQL이 생성된다.
select * from "user" u where u.id = ?
그래서 사실상 다수의 Entity를 가져올 때는 사용하지 않는다.
이 때 등장하는 것이 JPQL인데, 다수의 User Entity를 가져오는 JPQL은 다음과 같다.
List<User> foundUsers = em.createQuery("select u from User as u", User.class)
.getResultList();em.createQuery 메소드를 통해 SQL와 거의 비슷하게 생긴 JPQL을 문자열로 작성할 수 있다.
SQL을 공부한 적이 있다면 매우 쉽게 이해될 것이다.
그러나 자세히 보면 SQL과 조금 다른 부분이 있는데, 이전 시간에 생성한 테이블명은 "user"였는데 User를 테이블로 지정하고 있다는 것과,
*로 모든 필드를 가져오는 것이 아니라 u를 명시한 부분이다.
SQL과 다른 부분에 대해서 간단하게 알아보겠다.
JPQL
지금 사용 중인 User Entity는 다음과 같다.
@Entity
@Getter
@Table(name = "\"user\"")
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
private int age;
}테이블명은 "user", 클래스명은 User다.
SQL에서는 from 뒤에 당연히 테이블명을 따라 명시하겠지만,
JPQL에서는 이를 클래스명으로 대체한다.
-- SQL
select * from "user";
-- JPQL
select u from User as u;
-- JPQL [ERROR]
select * from "user";SQL에서의 *은 "user" 테이블 내의 모든 필드를 뜻하고,
JPQL에서는 User의 별칭으로 지정된 u가 User Entity(Java Instance) 내의 모든 필드를 뜻한다.
사실상 같은 의미다.
그러나 주의할 점은, JPQL에서는 *을 사용할 수 없다는 것과, 모든 필드를 가져오기 위해서는 반드시 Entity에 별칭을 지정하고,
그 별칭을 select 뒤에 명시해야 한다는 것이다.
그러면 실제 SQL은 다음과 같이 *가 아닌, 모든 필드를 펼쳐 놓은 형태가 된다.
Hibernate:
select
u1_0.id,
u1_0.name
from
"user" u1_0JPQL이 알아서 접근하는 테이블에 별칭을 먹이고 객체로 파싱하기 때문에 그런 것으로 보인다.
참고로 SQL과 동일하게 as 구문은 생략할 수 있다.
-- JPQL
select u from User as u;
select u from User u;위 두 JPQL은 동일하며, 편의를 위해 as는 대체로 생략한다.
조건을 지정하지 않았기 때문에 where이 삽입되지 않아서 실제 생성되는 SQL은 다음과 같다.
Hibernate:
select
u1_0.id,
u1_0.name
from
"user" u1_0em.createQuery, em.find의 동작 차이
@Test
void test() {
User user = new User();
em.persist(user);
em.flush();
em.find(User.class, 1L);
}em.find는 먼저 Persistence Context에서 Entity를 찾아본 뒤,
찾지 못한 경우에만 DB에 SQL을 전송한다.
그리고 가져온 Entity를 Persistence Context에 저장하고, em.find의 결과로도 반환한다.
em.flush는 Persistence Context에 존재하는 Entity를 SQL로 변환하여 DB에 저장할 뿐,
Persistence Context 내에 있던 Entity도 제거하지 않고 그대로 유지했었으며,
그 덕분에 위 코드는 em.find 시에 Persistence Context에서 User Entity를 가져오는 방식으로 동작하여, select SQL이 따로 전송되지 않았다.
같은 내용을 계속 반복하고 있기 때문에 이 부분은 어느 정도 익숙해졌을 것이다.
그러나 em.createQuery로 작성한 select 문은 조금 다른 동작을 한다.
@Test
void test() {
User user = new User();
em.persist(user);
em.flush();
// JPQL로 select 시, Persistence Context를 거치지 않고 DB에 select SQL 전송
em.createQuery("select u from User u", User.class)
.getResultList();
}User Entity가 분명 Persistence Context에 존재하는 데도 불구하고, DB에 실제 SQL을 전송하는 것이다.
Hibernate:
select
u1_0.id,
u1_0.name
from
"user" u1_0 em.find는 단 하나의 Entity만 가져왔었고, 지정할 수 있는 조건도 id 비교가 전부였기 때문에 Persistence Context에서 Entity를 가져오던, 실제 DB에서 가져오던 일치함을 보장할 수 있다.
그러나 em.createQuery는 여러 Entity를 가져올 수 있고, 다양한 조건을 넣을 수 있기 때문에 정확성을 보장하기 어려워진다.
예를 들어 Persistence Context에 user1, user2, user3이 저장 되어 있었고,
모든 사용자를 가져와야 하는 경우를 생각해보자.
이 때, 다른 요청에 의해 DB에 user4가 추가 된다면, 정확히 모든 User를 가져왔음을 보장할 수 없을 것이다.
요컨대 em.find는 성능 최적화에 초점을, em.createQuery는 정확성에 초점을 맞추고 설계되어 다르게 동작한다고 생각할 수 있겠다.
그렇다면 em.createQuery로 em.find를 사용할 때와 완전히 동일한 SQL이 작성되도록 하면 어떻게 될까
em.createQuery("select u from User u where u.id = 1", User.class)
.getResultList(); 이러면 em.find(User.class, 1L)을 호출할 때와 완전히 동일한 SQL이 만들어지게 된다.
이 때는 Persistence Context에서 찾아올까?
아니다.
em.createQuery로 em.find와 동일한 SQL이 만들어지도록 하더라도 여전히 SQL은 전송된다.
이럴 때는 그냥 em.find를 쓰자.
생각해보면 이게 맞는 방법이다.
em.createQuery를 쓰는 데, 어떨 때는 SQL이 전송되고, 어떨 때는 나가지 않는다면?
같은 메소드를 사용하는데도 세부적인 사항이 조금씩 달라진다면, 모든 사람이 일일이 기억하기 더 어려울 것이고, 실수도 늘어날 것이다.
예외는 최대한 적고 예측 가능한 것이 좋다고 생각한다.
정리하면, em.find는 선 Persistence Context 탐색 후 DB 조회,
em.createQuery는 즉시 DB 조회
라고 생각하면 된다.
물론 조회 시에 Persistence Context를 거치지 않을 뿐이지, em.createQuery로 가져온 Entity들도 Persistence Context에 저장된다.
도표와 함께 살펴보자.
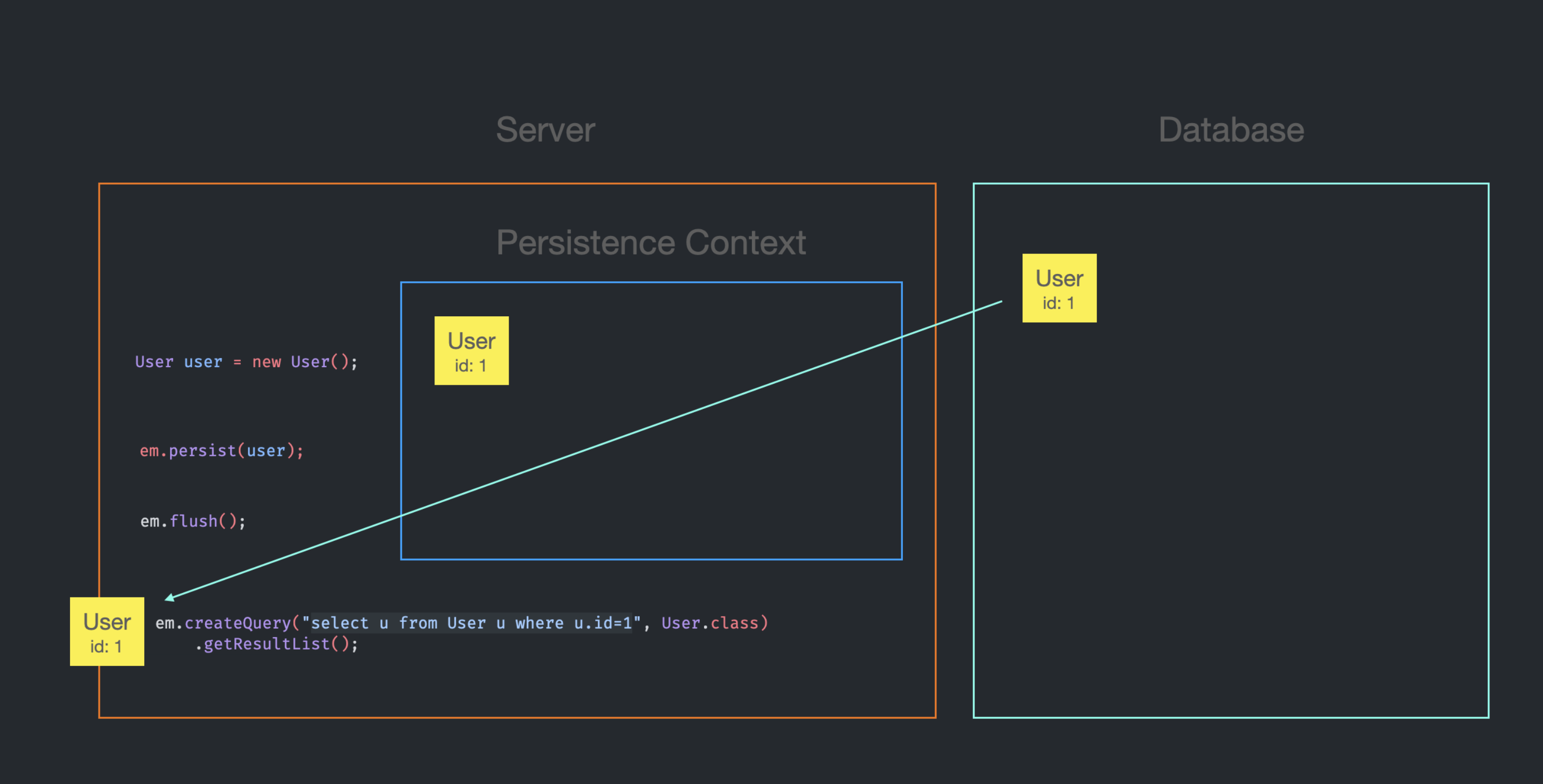
1. em.createQuery로 조회 시, Persistence Context에 Entity가 없는 경우
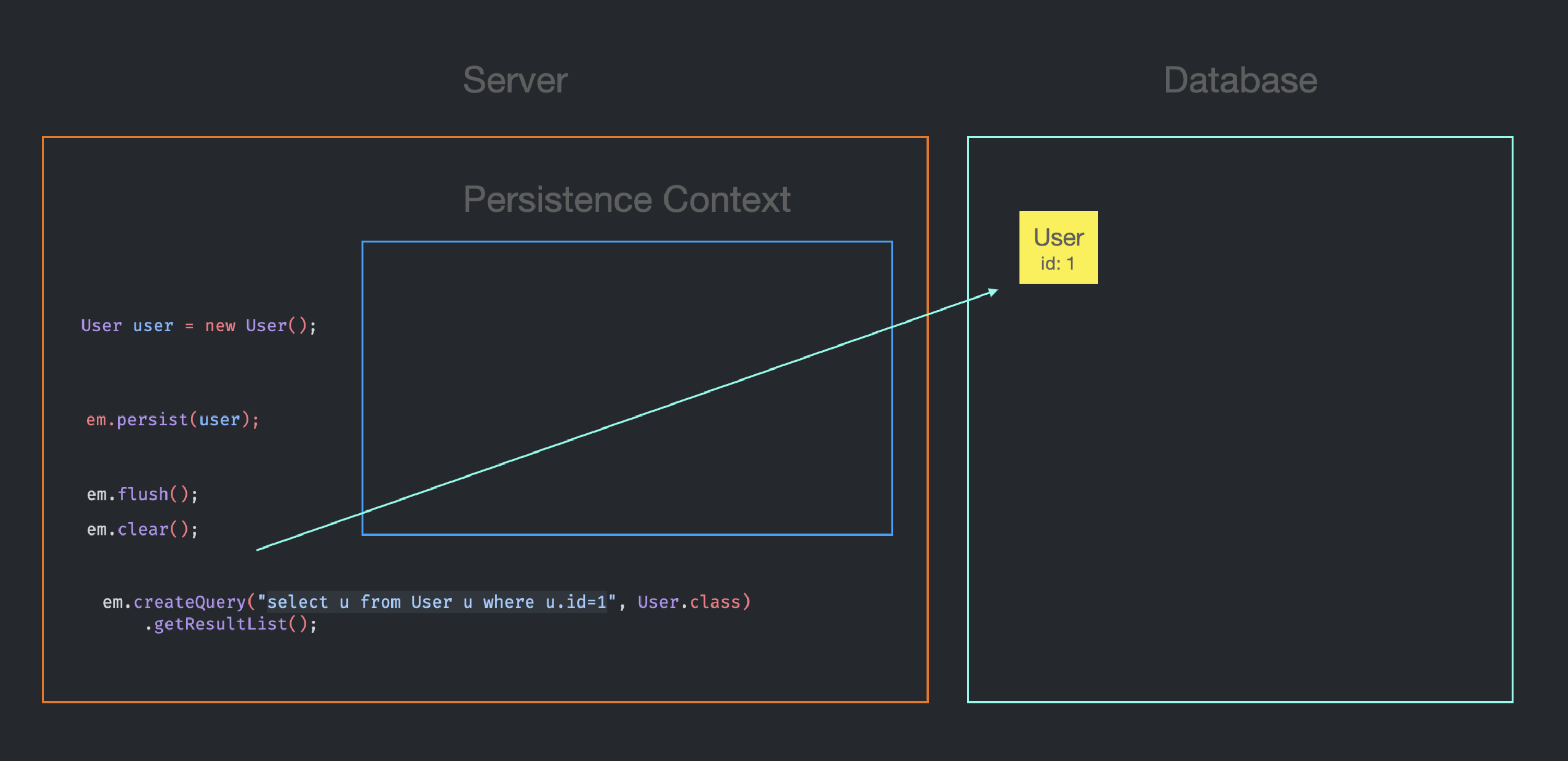
DB에 SQL을 전송한다.
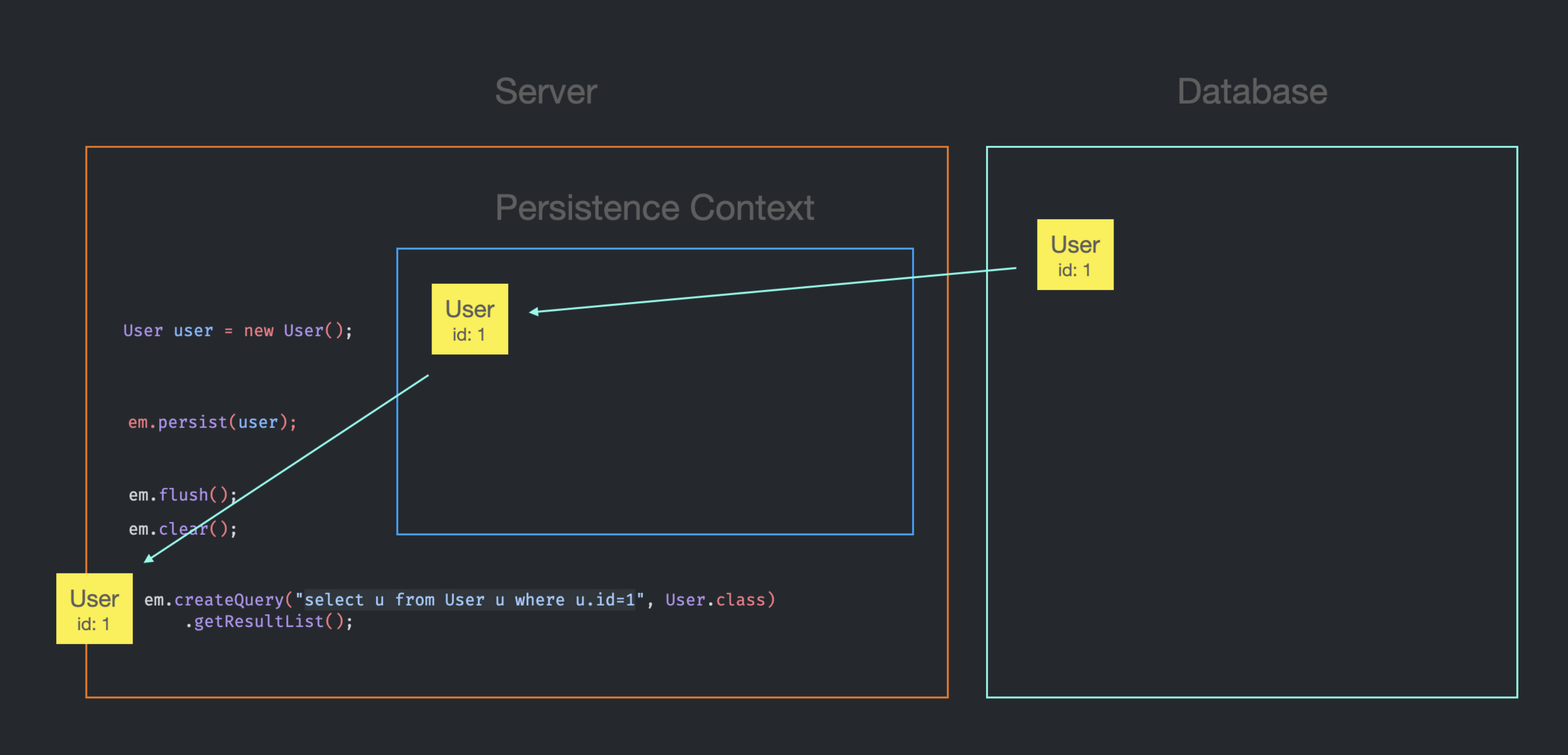
Persistence Context에 id가 1인 User Entity가 없었기 때문에, 가져온 Entity를 Persistence Context에 저장하고, em.createQuery의 반환 결과에 Entity가 추가된다.(정확히는 getResultList의 반환 결과)
2. em.createQuery로 조회 시, Persistence Context에 Entity가 있는 경우
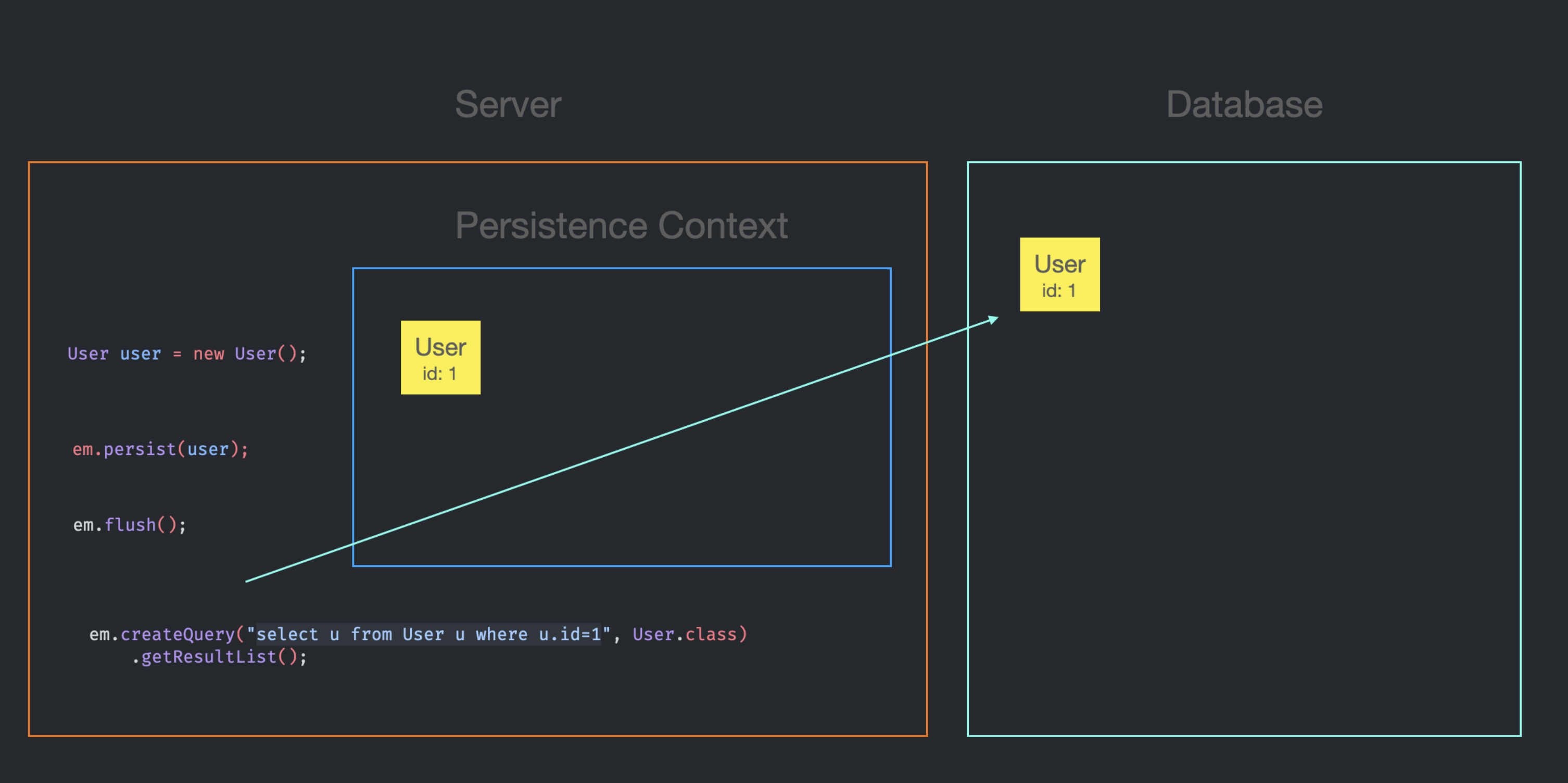
Persistence Context에 id가 1인 User Entity가 존재하지만, em.createQuery를 사용 하였으므로 DB에 SQL을 전송한다.
이미 Persistence Context에 Entity가 존재하기 때문에 DB로부터 가져온 Entity를 별도로 저장할 필요가 없고,
DB에서 가져온 Entity가 getResultList의 결과에 추가된다.
getResultList, getSingleResult
지금까지 JPQL로 조회 시, em.createQuery , getResultList를 함께 사용했었다.
이들 중, 실제로 SQL을 DB에 전송하는 역할은 어떤 메소드가 담당할까.
바로 getResultList다.
실험을 해봐도 좋다.
em.createQuery("select u from User u where u.id = 1", User.class);이 부분만 실행하면 SQL이 Console에 출력되지 않는 것을 확인할 수 있을 것이다.
이를 통해 createQuery은 SQL을 만드는 역할, getResultList는 SQL을 DB에 전송하고 결과를 받아오는 역할을 한다는 사실을 알 수 있다.
그런데 getResultList는 반환 타입이 List<T>으로, DB에서 찾아온 Entity를 List에 넣어서 반환한다.(1개만 찾아오더라도)
em.find처럼 1개의 Entity가 아닌, 여러 Entity를 가져올 수도 있기 때문이다.
그래서 주로 getResultList를 사용하겠지만, 다음과 같이 1개의 Entity만 가져오는 경우도 있다.
User foundUser = em.createQuery("select u from User u where u.id = 1", User.class)
.getSingleResult();getSingleResult는 List가 아닌, 1개의 Entity만 가져오게 되어있다.
주의할 점은 만약 id가 1인 User Entity가 DB에 존재하지 않는데 getSingleResult로 찾으려고 시도하는 경우,
다음과 같은 오류를 발생시킨다.
jakarta.persistence.NoResultException: No result found for query [select u from User u where u.id=1반면 em.find로 DB에서 id가 존재하지 않는 Entity를 찾으려고 하면 오류가 발생하지 않고, null을 반환한다.
User foundUser = em.find(User.class, 1L);
// foundUser == nullsetParameter
지금까지는 JPQL에 id를 "1"이라는 문자열을 그대로 넣어줬는데, 이러면 id가 1인 사용자 외에는 찾을 수 없는 JPQL이 되어 버린다.
그래서 다양한 id를 동적으로 입력할 수 있도록 다음과 같이 where u.id = 1을 where u.id = :id로 변경했다.
for (long i = 0; i < 10; i++) {
em.createQuery("select u from User u where u.id = :id", User.class)
.setParameter("id", i);
}이를 parameter라고 하는데, 문법은 매우 간단하다.
1. Named Parameter
: 뒤에 사용할 parameter 이름을 넣어주고,
.setParameter를 호출하여, parameter 이름, 값을 넣어주면 된다.
em.createQuery("select u from User u where u.id = :id and u.name = :name", User.class)
.setParameter("id", 1L)
.setParameter("name", "user");여러 개의 parameter를 설정할 수도 있다.
오류를 방지하기 위해 JPQL과 setParameter 를 잘 살펴보고 오타만 조심하도록 하자.(Intellij 등의 IDE는 이런 오타가 나면 알려주기도 한다.)
이름 기반으로 parameter를 설정하기 때문에 Named Parameter라고 한다.
Position-based Parameter
parameter 이름이 아닌, 위치 기반으로 설정할 수도 있다.
그러나 parameter 개수가 많아지고, 변경이 발생할 때 순서가 바뀌면 꼬일 수 있기 때문에 Named Parameter가 더 좋은 선택이다.
em.createQuery("select u from User u where u.id = ?1 and u.name = ?2", User.class)
.setParameter(1, 1L)
.setParameter(2, "user");사실 추후 Querydsl을 배우면 setParameter를 직접 사용할 일 자체가 거의 없을 것이라고 생각되지만, 일단 알아는 놓자.
