
학급 - 학생
버스 - 승객
시험 - 수험생
사용자 - 포스트
모두 1 : N 관계에 대한 예시다.
서비스를 만들다 보면 1:N 관계를 갖는 다양한 데이터를 마주하게 되는데,
그 때 @OneToMany, @ManyToOne Annotation을 통해 연관 관계를 맺을 수 있다.
매우 흔한 예시인 User : Post로 예시 코드를 작성해 보겠다.
연관 관계를 갖는 User, Post Entity 작성
// User.java
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "author")
private List<Post> posts = new ArrayList<>();
}
// Post.java
@Entity
@Getter
@Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
@ManyToOne
private User author;
}User Entity와, Post Entity를 작성했다.
다른 부분은 모두 지난 장까지 함께 다뤘었기 때문에 쉽게 이해 되겠지만,
@OneToMany와 @ManyToOne은 처음 볼 수도 있다.
우선 개념적으로 접근해보자.
1명의 User는 여러 개의 Post를 가질 수 있다.
고로 User와 Post는 1:N 관계다.
User의 posts 필드를 보면 @OneToMany Annotation이 붙어 있는데,
여기서 One이 해당 객체, User를, Many가 상대 객체, Post를 가리킨다.
@OneToMany, @ManyToOne, @OneToOne, @ManyToMany 4가지의 Annotation이 존재하지만 위 규칙은 일관적이기 때문에 한 번 기억해두면 다른 것도 헷갈리지 않는다.
@XToX Annotation에서 앞 부분이 객체 자신, 뒷 부분이 상대 객체를 가리키는 규칙을 꼭 기억하자.
이제 반대로 Post를 보자.
author 필드를 보면 @ManyToOne Annotation이 붙어있다.
여러 Post는 1명의 User에게 소유될 수 있기 때문에, 객체 자신(Post)을 가리키는 앞부분이 Many가 맞다.
상대 객체인 User도 One이 맞다.
필드명을 author라고 한 이유는 Post 입장에서 생각 했을 때는, user보다 author가 맥락 상 더 자연스럽기 때문이다.
어떤 사람이 누군가에게는 가족, 누군가에게는 직장 동료, 누군가에게는 동창이 될 수 있듯
Entity 필드 및 DB Column 명도 맥락에 따라 상대적으로 작명하는 것이 좀 더 이해하기 쉬운 듯 하다.
이번 편에서 자세히 설명하지는 않겠지만 반드시 알아둬야 할 2가지가 있다.
첫 번째는, 1:N 관계에서 1인 Entity(User)는 N인 Entity(Post)의 필드를 선언할 때, 반드시 컬렉션으로 초기값을 할당해야 한다는 것이다.
바로 이 부분이다.
private List<Post> posts = new ArrayList<>();
두 번째로 User Entity에 @OneToMany(mappedBy = "author") 부분을 보면, mappedBy = "author" 옵션이 설정되어 있는데, User가 FK를 가지지 못했기 때문에 연관 관계의 반대편인 Post에 의해 매핑되었다는 의미다.
주의할 점은 mappedBy에 작성할 이름은 Post DB Column명이 아닌, Java Instance의 필드명을 적어야 한다는 것이다.
mappedBy는 반드시 붙여주는 것이 좋다.
위 2가지를 설정하는 좀 더 자세한 이유는 추후 다른 장에서 자세히 살펴보도록 하겠다.
DB에서의 연관 관계 표현
Java에서 1:N, N:1 관계를 나타내는 것은 간단하다.
// 간결함을 위해 Annotation 모두 생략
public class User {
private Long id;
private String name;
// 1명의 사용자가 여러 개의 포스트를 가짐
private List<Post> posts = new ArrayList<>();
}
public class Post {
private Long id;
private String title;
private String content;
// N개의 포스트가 한 명의 사용자를 가짐
private User author;
}
// 1명의 사용자에게
User user new User();
for (int i = 0; i < 10; i++) {
// 10개의 포스트 추가
Post post = new Post();
user.posts.add(post);
}위 코드는 매우 쉽게 이해될 것이다.
그러나 DB에 익숙하지 않다면 테이블 상에서 위와 같은 관계를 어떻게 표현해야 할지 헷갈릴 수 있다.
다음 코드를 자세히 살펴보자.
create table "user" (
id bigint primary key
name varchar(20)
);
create table "post" (
id bigint primary key,
title varchar(20),
content text,
-- 소유자 id, FK로 등록
author_id bigint,
foreign key (author_id) references "user"(id)
);user, post 테이블을 만들었으며, post 테이블 내에 author_id라는 Column을 FK로 등록했다.
FK는 연관된 Record를 찾기 위해 필요한 연결 고리다.
예를 들어, user의 id가 1이고, post의 author_id가 1이라면,
id가 1번인 user와, author_id가 1번인 post를 찾아와서 하나의 Record로 합칠 수 있다.
Join이라 부른다.
-- select * from "user";
id | name
----|------
1 | John
2 | Alice
3 | Bob
-- select * from "post";
id | title | content | author_id
---- |----------|------------------|----------
1 | Post1 | Content of post1 | 1
2 | Post2 | Content of post2 | 2
3 | Post3 | Content of post3 | 1
-- select * from "user"
-- join "post" on "user".id = "post".author_id ;
"user".id | "user".name | "post".id | "post".title | "post".content
-----------|-------------|-----------|----------------|---------------
1 | John | 1 | Post1 | Content of post1
1 | John | 3 | Post3 | Content of post3
2 | Alice | 2 | Post2 | Content of post2
3번째 예시가 JOIN 된 결과이다.
여기서 매우 주의깊게 살펴봐야 할 부분이 있는데,
바로 user는 post에 대한 어떠한 정보도 가지고 있지 않다는 것이다.
user : post는 1 : N 관계이므로 논리적으로 생각하면, user가 N개의 post에 대한 정보를 가지고 있거나, 모든 post가 1개의 user를 가지고 있어야 한다.
user가 N개의 post를 가져도 되는 것 아닌가, 라고 생각할 수도 있다.
그럴 경우 다음과 같은 모양이 될 것이다.
id | name | post_ids |
----|-------|----------|
1 | John | [1, 2, 3]|결론부터 말하자면 이는 불가능하다.
(MySQL은 배열 미지원, PostgreSQL은 '배열' 자체는 지원하지만, FK를 요소로 갖는 배열은 만들 수 없다.)
Java에서 객체가 다른 객체를 참조하는 경우, 내부적으로는 '해당 객체의 주소'만 갖는다.
그러나 DB Record는 그것이 불가능하기 때문에, 참조하려는 객체의 id만 갖는 식으로 구현을 했던 것이다.
(DB에서 다른 객체를 참조하는 주소는 id로 대체된다고 생각하자.)
성능적인 문제로 이러한 설계를 하게 된 것이라고 추측된다.
간단하게만 알아보겠다.
DB가 FK 배열을 만들 수 없도록 설계된 이유(추론)
DB가 FK 배열을 가질 수 있다고 가정해보자.
id | name | post_ids |
----|-------|-----------------------------|
1 | John | [1, 2, 3, 4, 5, 6, ... 1000]|그렇다면 1000개의 post_id를 가진 user가 존재할 수 있게 된다.
이 때, 배열의 맨 끝에 새로운 post_id, 1001을 추가하면 어떻게 될까.
DB Record는 HDD, SDD에 저장된다.
Stack과 달리 순서대로 쌓이는 것이 아니라, Heap과 비슷하게 여기 저기 Record가 퍼져있다.
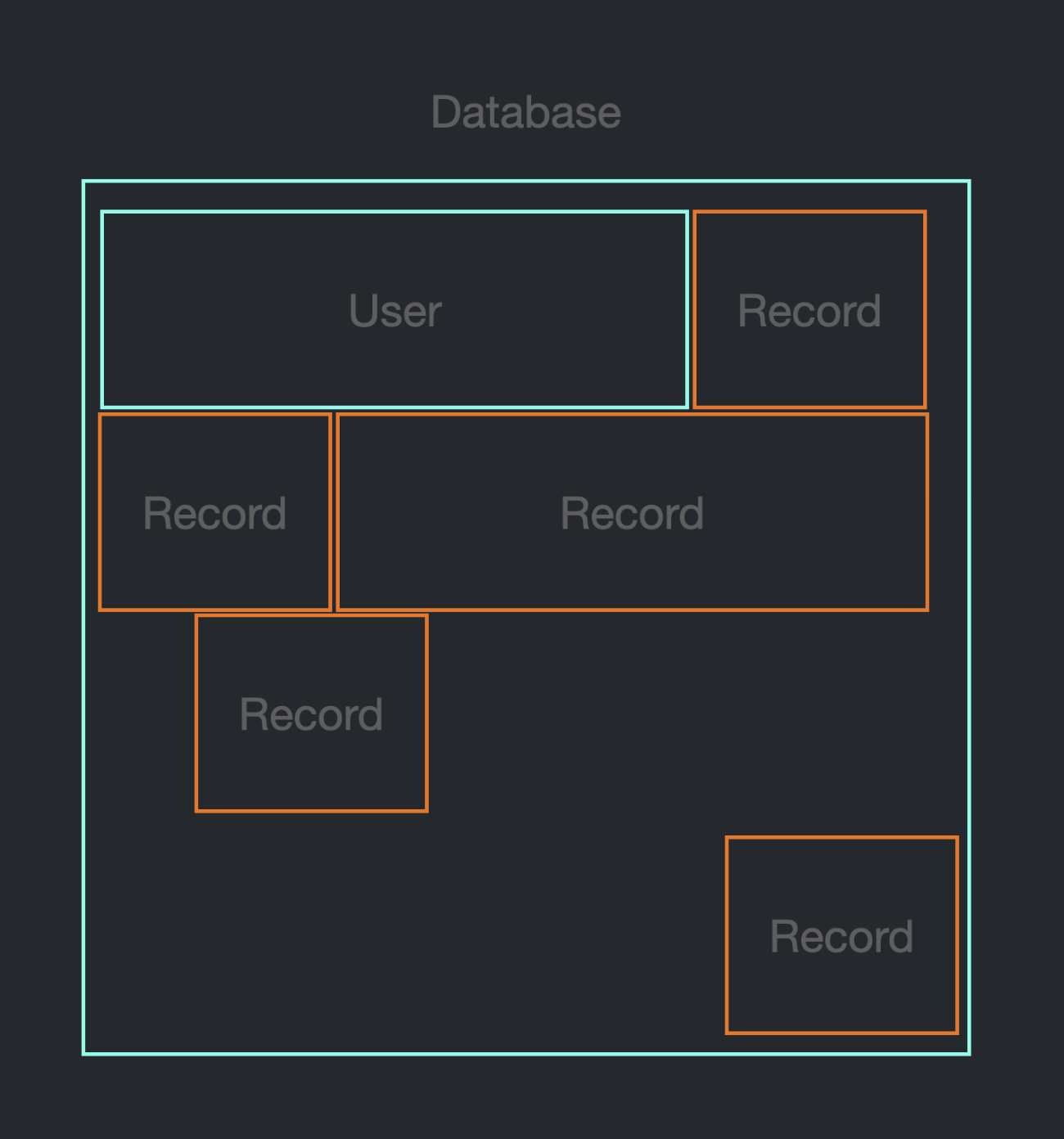
만약 위와 같은 상황이라면, User에 새로운 id를 추가하기에는 뒤에 저장할 공간이 부족하다.
즉, User Record 전체를 다른 공간으로 완전히 이동시켜야 한다.
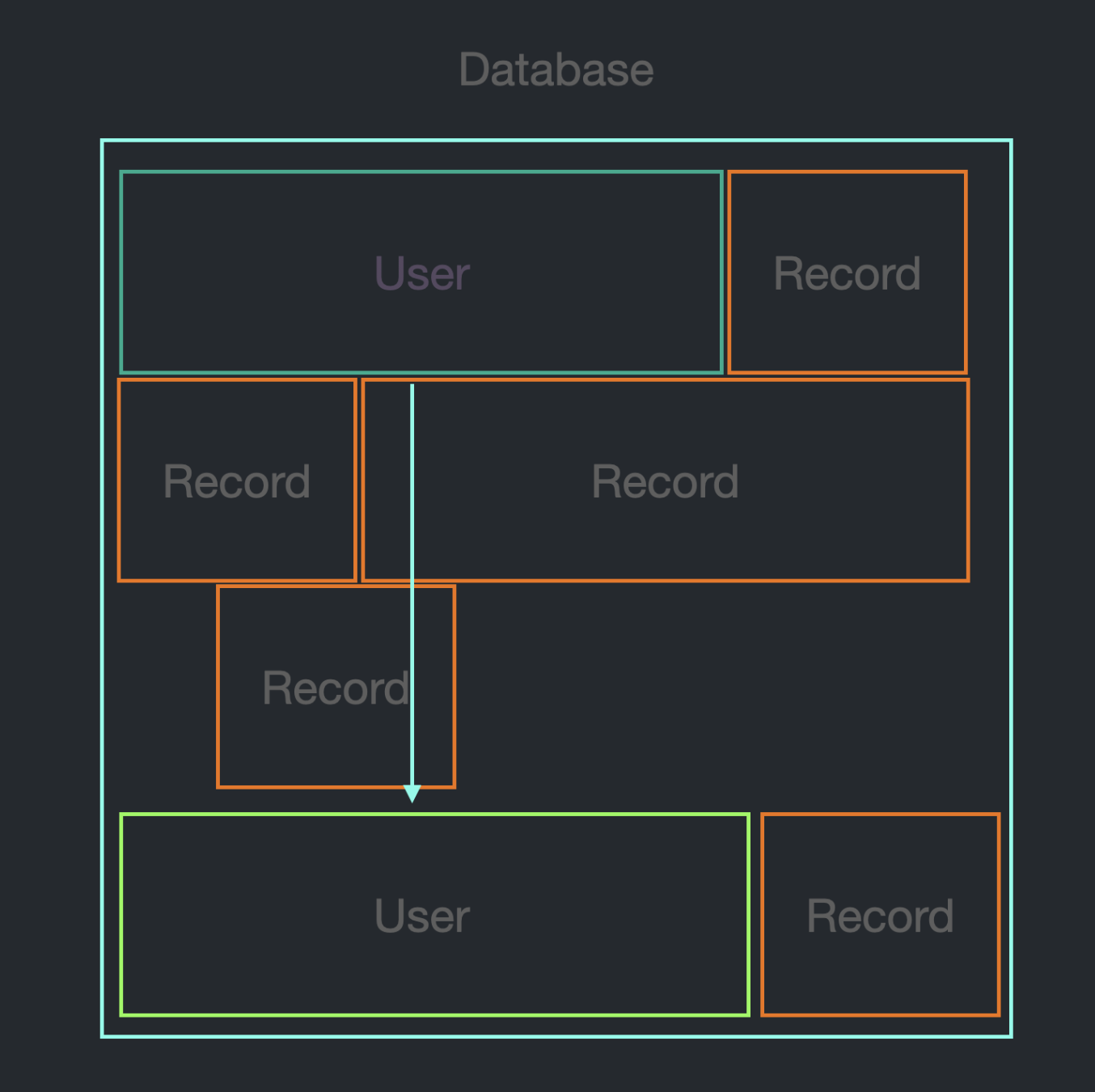
id 하나가 8byte라고 생각하면, 고작 8byte를 추가하기 위해서 8000byte의 읽기/쓰기가 일어나야 하는 것이다.
반면, User가 아닌 Post에 author_id를 저장한 경우에는 User의 크기가 매우 작아진다.
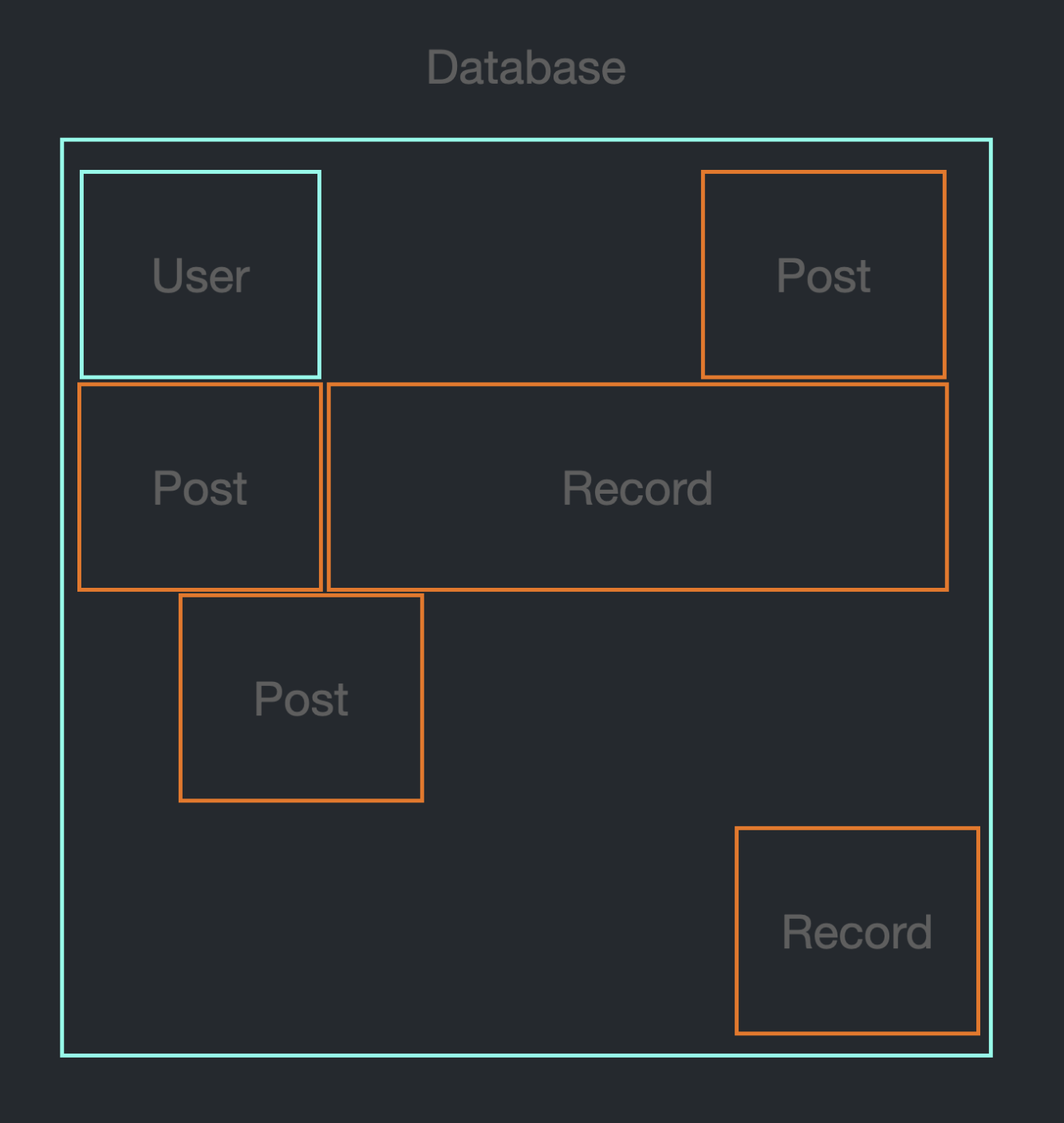
post_id 1000개가 줄어들었으니, 이전보다 8000byte 작은 크기일 것이다.
이제 post_id를 추가할 때, user를 변경할 필요가 없다.
post_id를 추가한다는 것은 곧 새로운 post가 생성된다는 의미이므로,
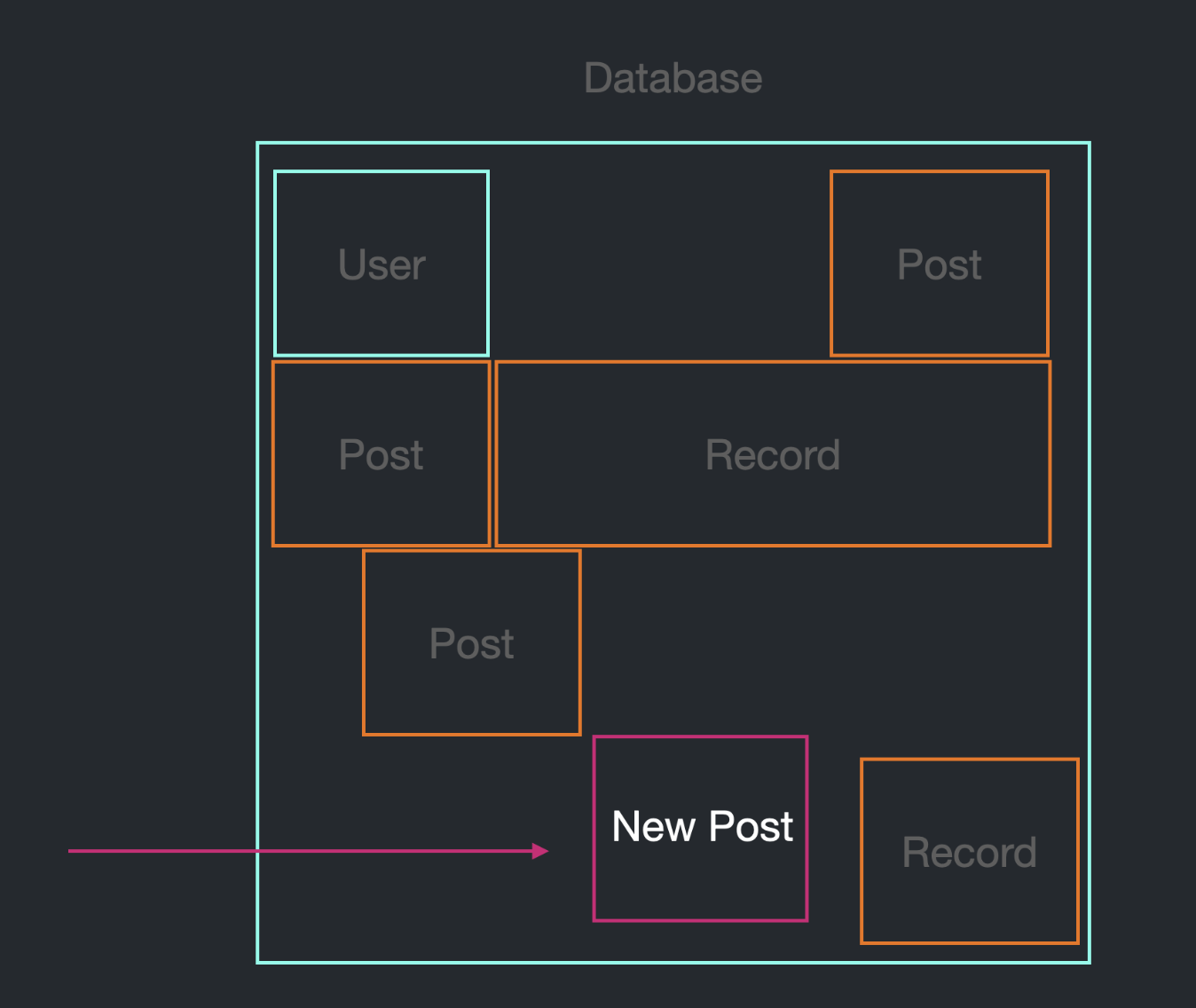
post를 하나 삽입하고, 해당 post의 author_id만 넣어주면 된다.
8000byte를 move할 필요가 없기 때문에 훨씬 경제적이다.
이러한 연유로 RDB에서 배열로 FK를 사용하지 못하도록 막아둔 것이라 생각된다.
1000개도 사실 적다. 댓글이 수 만, 수 십만개인 Youtube, Instagram 영상 등을 생각해보라.
그런 게시물이 몇 개나 되는지, 얼마나 자주 업데이트 되는지를 생각해보면 비용 당초 예상보다 훨씬 더 클 것이라는 생각이 들 것이다.
Owning Side, Not-Owning Side
DB가 FK 배열을 가질 수 없는 이유는 충분히 이해했을 것이라고 생각한다.
1:N 관계를 맺기 위해 남은 방법은 FK를 N쪽이 갖는 것이다.
즉, User : Post 관계에서는 FK를 Post가 가질 수 밖에 없는 구조인 것이다.
덕분에 단순하게 사고할 수 있다.
@ManyToOne Annotation이 존재하는 Entity를 보면 FK를 갖는다고 생각하면 되니 말이다.
이렇게 FK를 갖는 Entity를 Owning Side(연관 관계 주인)라고 부른다.(반대편은 Non-Owning Side)
Post Entity를 다시 살펴보자.
// Post.java
@Entity
@Getter
@Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
// Many가 앞에 붙으므로, Post가 N임을 의미 -> FK를 가짐 -> Owning Side
@ManyToOne
private User author;
}위 주석과 같이 사고의 흐름을 전개하면 된다.
Many가 앞에 붙으므로 해당 객체가 N이고, 뒤에 One이 오므로 상대 객체가 1
RDB에서 배열 FK는 존재할 수 없으므로 1이 아닌 N쪽이 FK를 가짐
FK를 가지므로 Owning Side.
참고로 @ManyToOne이 붙은 필드명이 author인데,
테이블에는 User 객체가 아닌, 순수 id만 저장되기 때문에 실제 Column 명은 author_id가 된다.
Java의 네이밍 컨벤션은 lowerCamelCase지만, 테이블은 lower_camel_case이므로 이 부분까지 자동으로 맞춰서 변환된다고 보면 된다.
다음은 User Record를 보자
@Entity
@Getter
@Setter
@Table(name = "\"user\"")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// One이므로 FK는 반대편에 있을 것
@OneToMany(mappedBy = "author")
private List<Post> posts = new ArrayList<>();
}OneToMany니까 One이 User 객체를 뜻하고, Many는 Post 객체를 뜻한다.
DB Record는 FK 배열을 가질 수 없으므로, FK는 반드시 반대편인 Post에 존재해야 할 것이다.
이렇게 넘어가면 나중에 혼란을 빚을 수도 있기 때문에 확실하게 정리하겠다.
1:N 관계에서 반드시 N 쪽에 FK가 있어야 하는 것은 맞다.
이는 앞서 살펴본 DB의 설계 상의 한계 때문이었다.
그러나 Jpa에서 반드시 Many 쪽이 연관 관계의 주인이 되는 것은 아니다.
One 쪽이 연관 관계의 주인이 될 수도 있다.
다시 한 번 말하지만, One을 연관 관계의 주인으로 설정하더라도 DB 테이블 상에서는 Many 쪽에 FK가 존재한다.
약간의 흑마법을 써야 하고, 무엇보다 인간의 직관에 반하는 방법이기 때문에 좋은 방법은 아니라고 생각한다.
최대한 Java Instance와 DB Record를 동기화 시키기 위해 FK를 가지는 Many 쪽을 연관 관계의 주인으로 두는 것이 바람직하다고 생각한다.
One을 연관 관계 주인으로 설정하는 방법은 여기서 자세히 설명하지는 않겠다.
