Memory Visibility는 싱글 스레드 환경에서는 발생할 일이 없기 때문에 다음 코드를 처음 보게 되면 혼동을 빚을 수 있다.
다음 코드의 실행 결과를 예상해보자.
선택지를 4개 정도 만들어 봤는데 정답은 1개이다.
- 1초 뒤 프로그램이 정상적으로 종료된다.
- 1초 뒤 프로그램에서 예외가 발생한다.
- 프로그램이 시작되자마자 종료된다.
- 무한 루프에 걸린다.
package thread;
public class MemoryVisibility {
static boolean shouldRun = true;
public static void main(String[] args) throws InterruptedException {
System.out.println("main thread launched");
Thread task = new Thread(() -> {
System.out.println("task launched");
while (shouldRun) {
// 여기서 무언가 특정 작업을 수행한다고 가정
// 이 코드에서는 아무 것도 하지 않음
}
System.out.println("task ended");
});
// task를 worker thread에서 시작
task.start();
// 1초를 기다린 뒤, shouldRun을 false로 변경
Thread.sleep(1_000);
shouldRun = false;
// task가 끝날 때까지 대기
task.join();
System.out.println("main thread ended");
}
}코드 양이 얼마 되지 않으므로, 정답을 보기 전에 코드를 직접 실행시켜보고 추론해보는 것도 나쁘지 않다.
그러나 멀티 스레드에 관한 이해가 부족하다면 정답을 추론하는 것이 상당히 어려울 것이다.
정답은 뒤에서 보기로 하고, 위 예제해서 단 한 줄이 변경된 다른 예제를 살펴보겠다.
package thread;
public class MemoryVisibility {
static boolean shouldRun = true;
public static void main(String[] args) throws InterruptedException {
System.out.println("main thread launched");
Thread task = new Thread(() -> {
System.out.println("task launched");
while (shouldRun) {
// *stdout 출력 한 줄 추가됨*
System.out.println("running");
}
System.out.println("task ended");
});
// task를 worker thread에서 시작
task.start();
// 1초를 기다린 뒤, shouldRun을 false로 변경
Thread.sleep(1_000);
shouldRun = false;
// task가 끝날 때까지 대기
task.join();
System.out.println("main thread ended");
}
}변경된 부분은 task의 루프 안에 출력문을 하나 넣은 것 뿐이다.
그러나 이로 인해서 두 코드의 결과는 완전히 달라지게 된다.
이번에도 한 번 결과를 추론해보자.
2번째 코드의 결과는 어떠할까
- 1초 뒤 프로그램이 정상적으로 종료된다.
- 1초 뒤 프로그램에서 예외가 발생한다.
- 프로그램이 시작되자마자 종료된다.
- 무한 루프에 걸린다.
코드를 직접 돌려 봤다면 이미 알고 있겠지만,
첫 번째 예제의 정답은 4번, 무한 루프에 걸리는 것이고
두 번째 예제의 정답은 1번, 1초 뒤 프로그램이 정상적으로 종료된다는 것이다.
이는 Multi Threading 환경에서의 Memory Visibility에 기인한다.
Shared Memory between different threads
첫 번째 예제에서 무한 루프가 발생하는 이유에 대해 생각해보자.
이유 자체는 매우 간단하다.
task의 루프는 shouldRun에 의해 결정되며, 초기값은 true다.
shouldRun이 1초 뒤에 main thread에 의해 false로 변경되기 때문에, 1초 뒤에 종료될 것이라고 예상한 경우가 대부분일 것이다.
그런데 실제로는 무한 루프를 돌기 때문에, task를 돌리고 있는 쓰레드는 여전히 shouldRun을 변경되기 전의 값인 true로 보고 있다는 것이다.
그리고 그것이 영원히 변경되지 않는 상황으로 인해 무한 루프가 발생한 것이다.
이유는 shouldRun이 갱신이 되지 않는다는 것이지만, 원리는 조금 복잡하다.
그림으로 순서대로 살펴보겠다.
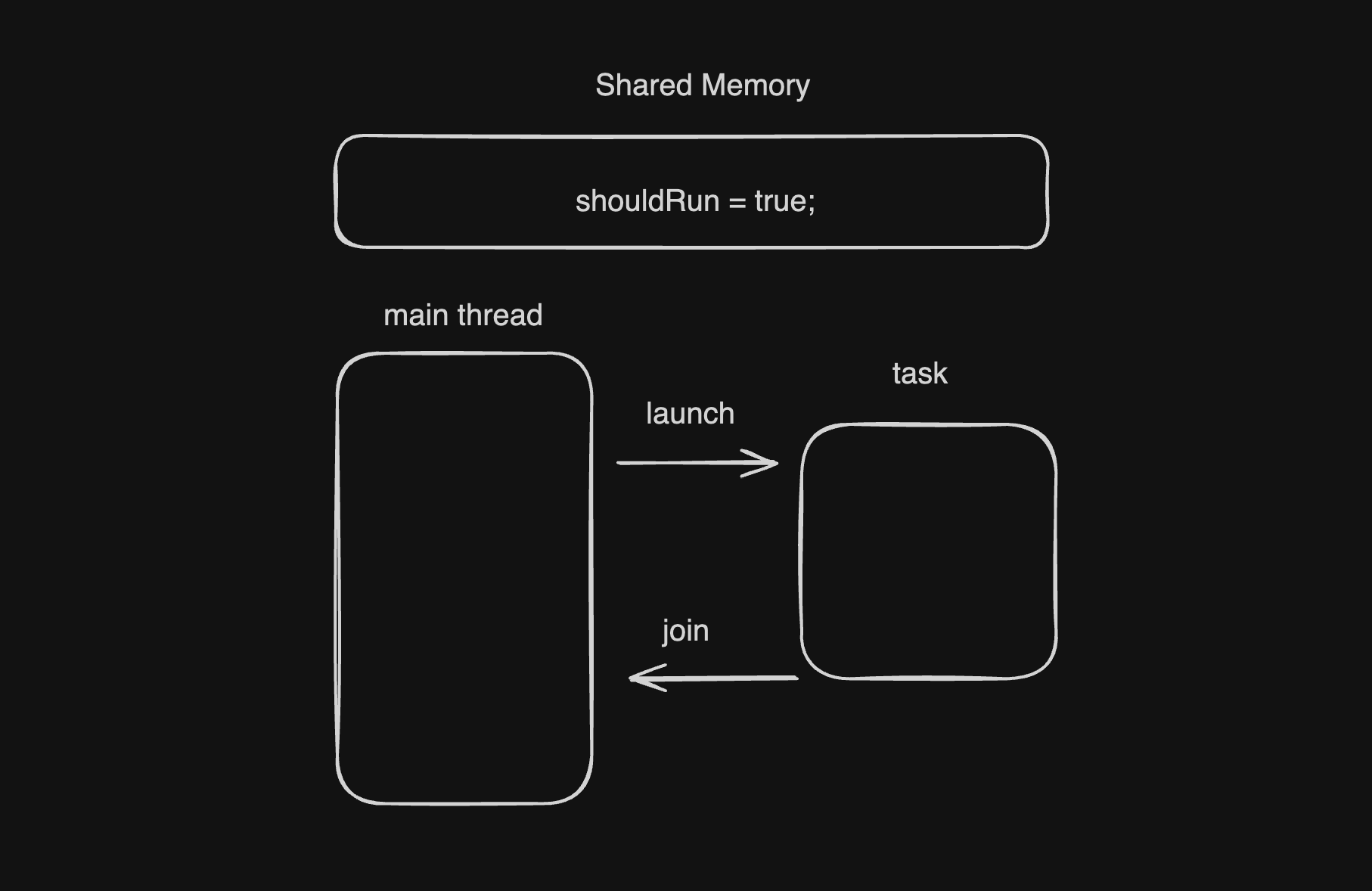
task가 실행된 직후의 초기 상태이다.
공유 메모리 내에 shouldRun을 두 쓰레드가 모두 true로 인지하고 있다.
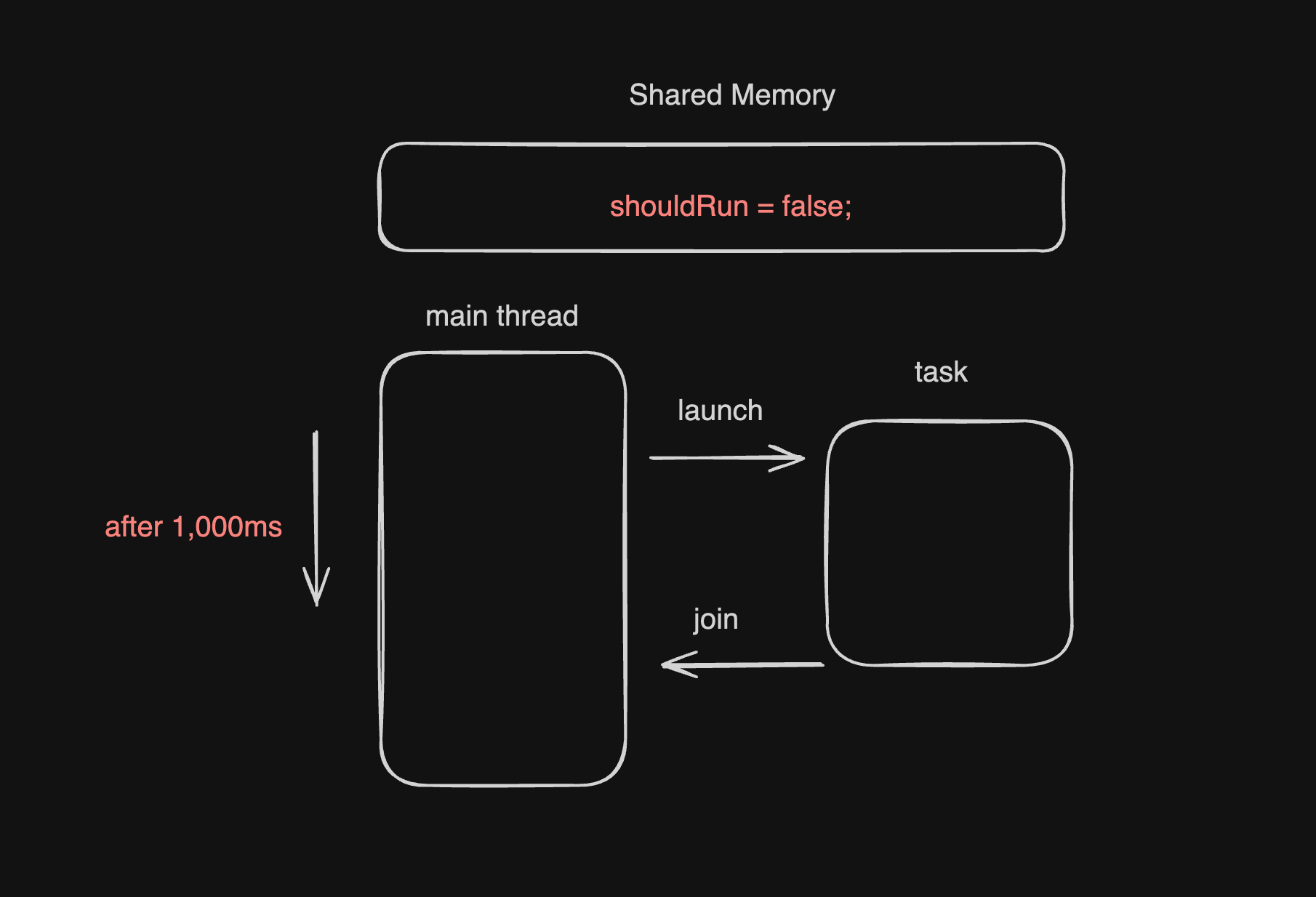
그리고 1초 뒤, shouldRun이 main thread에 의해 false로 변경된 상태다.
여기까지만 보면 역시 전혀 맥락을 파악할 수 없을 것이다.
Shared Memory는 말 그대로, 두 thread가 공유하는 영역이기 때문에 task가 shouldRun의 변화를 인지하지 못하고 무한 루프에서 벗어나지 못한다는 사실 자체에 괴리감이 느껴질 것이다.
여기서 바로 Cache Line이 등장하며, 이를 통해 모든 것을 설명할 수 있다.
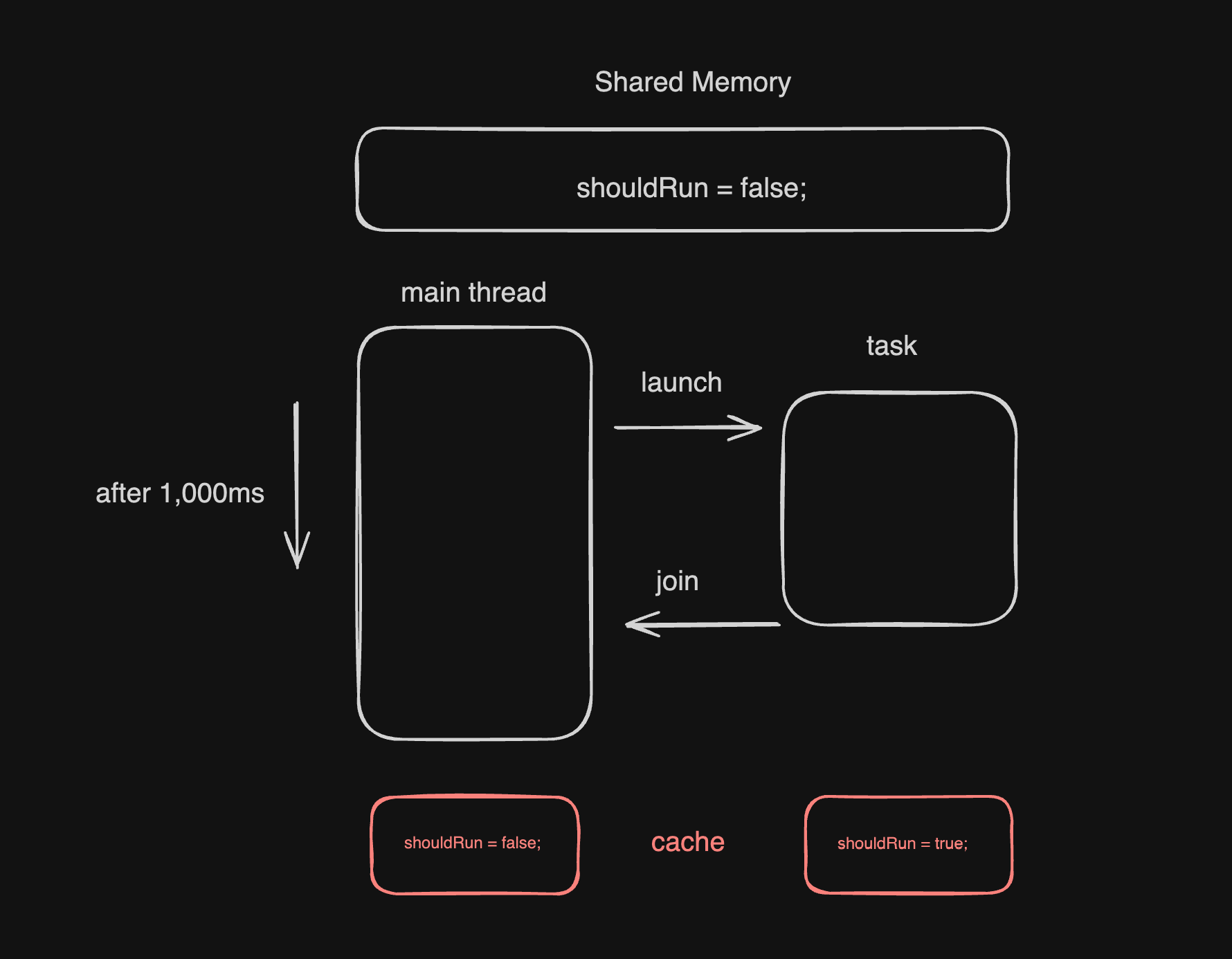
바로 위와 같은 상태였기 때문에 task와 main thread가 shouldRun이라는 동일한 변수를 다른 값으로 읽고 있었던 것이다.
Cache
CPU에 독립적인 메모리 공간인 L1, L2, L3 Cache가 존재한다는 것을 들어본 적이 있을 것이다.
Latency Numbers you Should Know from bytebytego.com
도표를 살펴보면, RAM이라 불리는 Main Memory는 Access Latency가 100ns, 1억분의 100초인 데 반해 L1, L2 Cache는 1ns, 10ns 뿐이 되지 않는다.
CPU Core가 4.0GHz라고 가정하면, 초당 40억 번 연산이 가능하므로 L1 기준, 4 cycle만에 끝난다고 볼 수 있다.(1ns)
수치상으로 보면 RAM에 접근하는 대신 L1 Cache에 접근하는 것으로 100배의 성능 향상을 이룰 수 있는 것이다.
Main Memory와 L3은 여러 Core가 공유하는 리소스지만, L1, L2는 CPU Core 독립적이다.
여기까지의 정보를 토대로 이전 예제에서 main thread와 worker thread의 shouldRun은 각각 core-independent 한, L1 또는 L2 Cache에 저장되었기 때문에 서로 다른 값을 바라보고 있었다. 라고 추론할 수 있을 것이다.
항상 속도가 느려지면 Caching을 하게된다.
유튜브 동영상이 외국 서버에 저장되어 있어서 느리다면 한국 리전으로 캐싱한다.(CDN)
넷플릭스 동영상 스트리밍을 하다가 자꾸 끊긴다면 로컬에 다운로드한다. 이것도 캐싱이라 볼 수 있다.
데이터베이스에서 읽어오는 데 너무 느리다면 Main Memory에 캐싱한다.
그리고 Main Memory마저 느리다면 CPU Cache에 캐싱하는 것이다.
대상만 다를 뿐 지금까지 했던 짓들과 별반 다르지 않다.
CacheLine
지금까지의 정보를 토대로 원인은 알았으나 원리까지는 깨우칠 수 없는 상태다.
Thread에 대한 약간의 지식이 있다는 가정하에, CacheLine이라는 개념을 알게 되면 모든 것을 이해할 수 있게 된다.
비교 분석을 위해 Memory부터 살펴보겠다.
보통 Main Memory는 다음과 같은 형태로 표현된다.
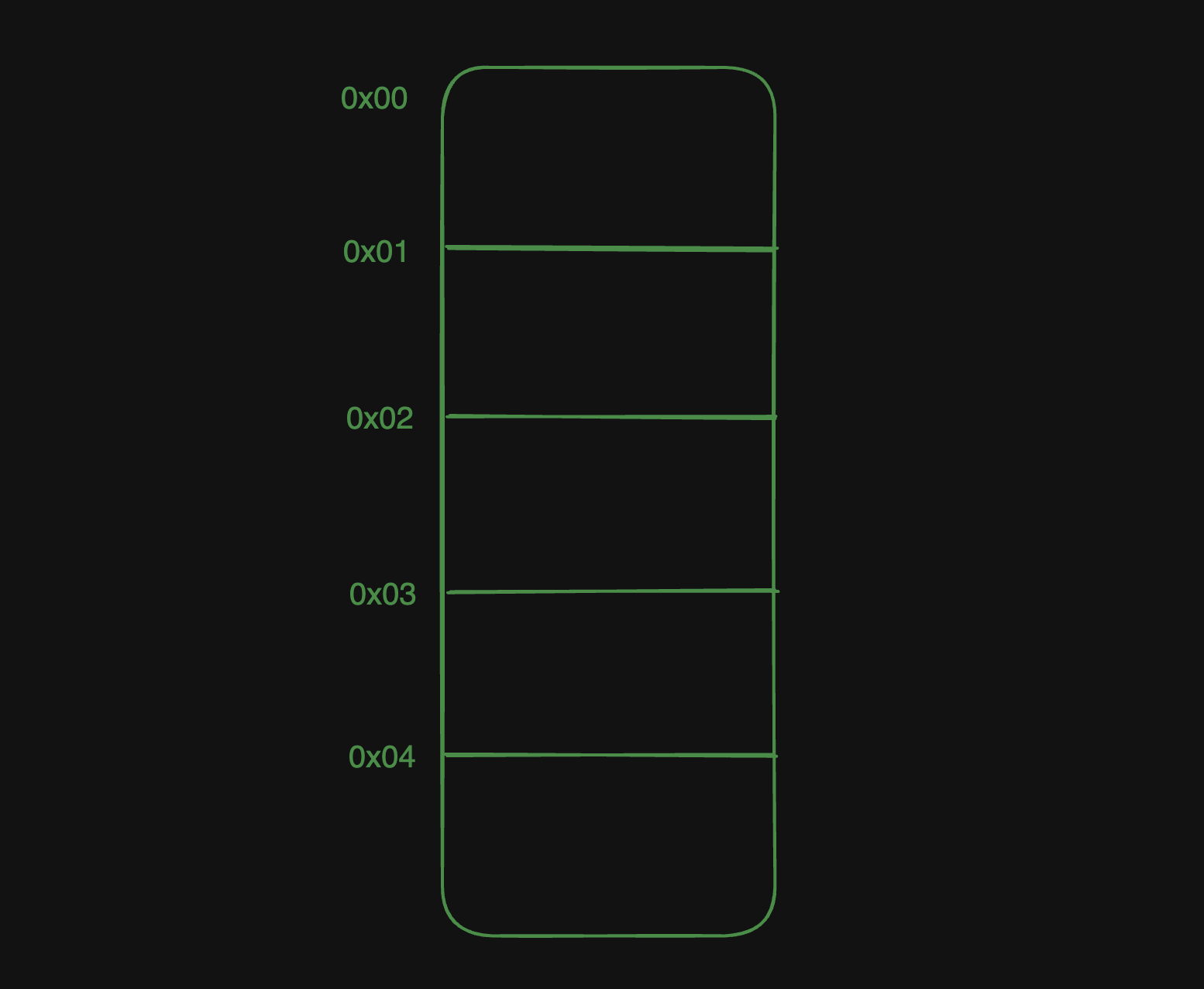
16GB 기준, 약 160억byte이므로 160억 개의 칸으로 이루어져 있으며, 각 칸이 메모리의 최소 단위인 Memory Cell이다.
각 메모리 셀은 1byte다.
그래서 원하는 시작 주소 ~ 가져 오려는 데이터의 크기만큼 칸을 지정해서 읽고 쓰기가 가능하다.
CPU Cache는 메모리와는 조금 다른 형태인데, 대략 다음과 같은 형태로 이루어져 있다.
https://computationstructures.org/lectures/caches/caches.html
Main Memory가 다루는 최소 단위는 1byte이며, 이를 Memory Cell이라고 부르는 것과 달리,
CPU Cache는 최소 단위를 CacheLine이라고 부르며, [Valid bit(1bit), Tag(27bits), Data(32bits) ]로 이루어져 있다.
오래된 자료라 그런지 Data가 32bits로 표기되어 있는데, 64bit Platform이 주류가 된 현재는 Data를 64bits라고 생각하면 된다.
도표의 첫 줄에 Each word in memory maps into a single cache line라고 나오는데,
각 CacheLine은 Main Memory 내의 동일한 크기의 공간에 매핑된다는 이야기다.
도표 제목인 Direct-Mapped Caches가 이러한 Cache의 구조적 명칭인데, 최근에는 N-Way Set Associative Cache 등의 방식이 사용된다.
Set 0:
+-------------+---------------+---------------+------------------+
| Tag | Valid | State | Data |
+-------------+---------------+---------------+------------------+
| 0x00123 | 1 | 10 | [Data Block] |
| 0x00456 | 1 | 01 | [Data Block] |
| 0x0789A | 1 | 00 | [Data Block] |
| ... | ... | ... | ... |
+-------------+---------------+---------------+------------------+
Set 1:
| 0x00123 | 1 | 10 | [Data Block] |
| 0x00456 | 1 | 01 | [Data Block] |
| 0x0789A | 1 | 00 | [Data Block] |
| ... | ... | ... | ... |
+-------------+---------------+---------------+------------------+
... 생략Direct-Mapped Caches가 한 CacheLine 당 하나의 Data Field를 가진 것과 달리, N-Way Set Associative Cache 방식은 N개의 CacheLine이 모여서 Set을 이루고 있는 구조라는 것이다.
아마 90년대 즈음에 Direct-Mapped Caches는 사장된 듯 하다.
그러나 원리는 비슷하며, Direct-Mapped Caches가 좀 더 간단한 구조이므로 어떻게 동작하는지 간단히 알아보겠다.
하나의 CacheLine은 Valid Bit/Tag/Data, 3가지 요소로 이루어져 있다.
Main Memory에서 shouldRun이라는 bool을 읽어오면, 우선 CacheLine에 저장된다.
32bit Platform 기준이므로, shouldRun이 저장된 주소가 0x12345678이라고 가정할 수 있다.
이를 binary로 바꾸면 00010010001101000101011001111000이 된다.
1개의 CacheLine을 이 주소와 매핑해야 하는데, Tag는 27bits 뿐이므로,
뒷부분인 5bits만 빼고 저장할 수 있다. 000100100011010001010110011
그리고 남은 5bits는 11000 index, offset으로 채운다.
그러나 index, offset은 실제로 저장되는 데이터는 아니다.
+-----TAG-----+---Valid Bit---+-------Data-------+
+-------------+---------------+------------------+
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
+-------------+---------------+------------------+처음에 모든 CacheLine이 다 비어있다고 생각하고, 시뮬레이션을 해보자.
예제를 간결하게 하기 위해 TAG의 앞 22bits를 생략하여 27bits가 아닌, 5bits로만 표현하겠다.
0x12345678에 저장된 shouldRun을 메인 메모리에서 읽고, 적절한 CacheLine을 선택해야 한다.
이 때, 00010010001101000101011001111000에서 22bits를 제거하면
1001111000이 된다.
여기서 앞부분 5bits를 잘라서 TAG로 사용한다.
즉, TAG는 10011이 된다.
뒷부분 5bits는 11000인데, 이 부분은 저장할 필요가 없다.
현재 8개의 CacheLine이 존재하고, 이를 배열이라 생각하면 총 index를 3bits로 나타낼 수 있다.
000 ~ 111까지
그리고 Data Block은 32bits이며, 4byte 라고 생각하면, 각 byte 별 offset을 00 ~ 11로 표현할 수 있다.
고로 이들은 저장할 필요 없이 '매핑'하면 된다.
11000에서 index는 110, offset은 00이 된다.
110은 6이므로, 8개의 CacheLine 중, 7번째가 자동으로 선택된다.
+-----TAG-----+---Valid Bit---+-------Data-------+
+-------------+---------------+------------------+
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 00000 | 0 | [Data Block] |
| 10011 | 1 | [Data Block] |
| 00000 | 0 | [Data Block] |
+-------------+---------------+------------------+고로 위와 같이 7번째 CacheLine을 업데이트 하고, 유효하다는 의미로 Valid Bit도 1로 설정한다.
이런 식으로 업데이트가 가능하며,
Direct-Mapped Block의 문제는, 매핑하려는 주소의 일부 비트가 동일할 경우, 원래 사용하던 CacheLine을 덮어쓴다는 것이다.
index가 동일하면 충돌이 나는 것이다.
이전에 0x12345678의 뒷부분 5bits는 11000이었는데
이 부분이 동일한 0x00000078, 0x00001A78, 0x00039A78 등은 모두 index 7에 위치한 CacheLine을 사용하게 되기 때문이다.
이러한 충돌이 너무 많이 나기 때문에 Set 형태로 바뀌게 된 것이다.
volatile
-
shouldRun이true인 상태에서t1,t2가 각각 CacheLine에 저장했다. -
main thread인
t1이shouldRun을false로 변경했지만, CacheLine은 CPU Core 독립적이며, thread 별로 공유가 되지 않기 때문에t2는 자신의 Cache Memory에true로 설정된shouldRun을 보고 있는 상태다. -
고로
t2는 무한 루프를 돈다.
문제의 흐름을 정리해 봤는데, 원인을 이해했다면 이를 해결하는 방법은 매우 간단하다.
static volatile boolean shouldRun = true;공유할 변수에 volatile 키워드만 붙여주면 된다.
이는 Memory Visibility를 강제하는 키워드인데,
변경 시, CPU Cache Memory에 flush를 하게 만드는 것이다.
Core 1, 2가 있고 shouldRun을 각각 true, true라는 같은 값을 Cache에 가지고 있는 경우,
현재는 자신의 Cache만 업데이트 하여 변경 시 true, false와 같이 불일치가 생겨나지만,
volatile을 붙이면 다른 Core의 Cache에도 flush를 강요하여 변경 시 false, false로 Cache가 동기화 된다.
mutex, atomic operation 등을 사용했다면 이러한 문제를 만날 일이 없었을텐데, 이런 동작을 내부적으로 이미 해주기 때문이다.
Context Switching
마지막으로 2번째 예제는 대체 왜 정상 동작 되었는지 살펴보자.
2번째 예제에서 추가된 것은 Prinln 한 줄이다.
그러나 이는 I/O Operation이기 때문에 Context Switching이 발생한다.
Context Switching은 Thread Block을 전환하며, 필연적으로 CPU Cache도 전부 전환 되어야 한다.
그래서 Cache에 대한 flush 효과가 있기 때문에 마치 volatile을 사용한 것처럼 동기화가 자동으로 맞춰진 것이다.
그런데 프로그램을 여러 개 실행 중이어서 자동으로 Context Switching이 발생하는 것이 당연한 것 아닌가, 그렇다면 아무 것도 안해도 무한 루프를 돌면 안 되고, 여러 프로그램이 자동으로 ms 단위로 Context Switching 되는 상황 속에서 알아서 무한 루프가 풀려야 하지 않을까 하는 생각이 들 수 있지만,
CPU Cache도 Thread Context처럼 저장해뒀다가 다시 복원하는 개념이기 때문에 그렇게 되지는 않는다.
게다가 IO는 Println이라는 한줄의 간단한 코드처럼 보이지만, 내부적으로 복잡하고 여러 변수들을 Cache에 저장하기 때문에 이전에 사용하던 CacheLine들이 덮힐 수 밖에 없겠다.
