캐싱
next.js는 성능 향상과 비용을 줄이기 위해 가능한 많이 캐시를 하는데 4가지의 매커니즘이 있다.
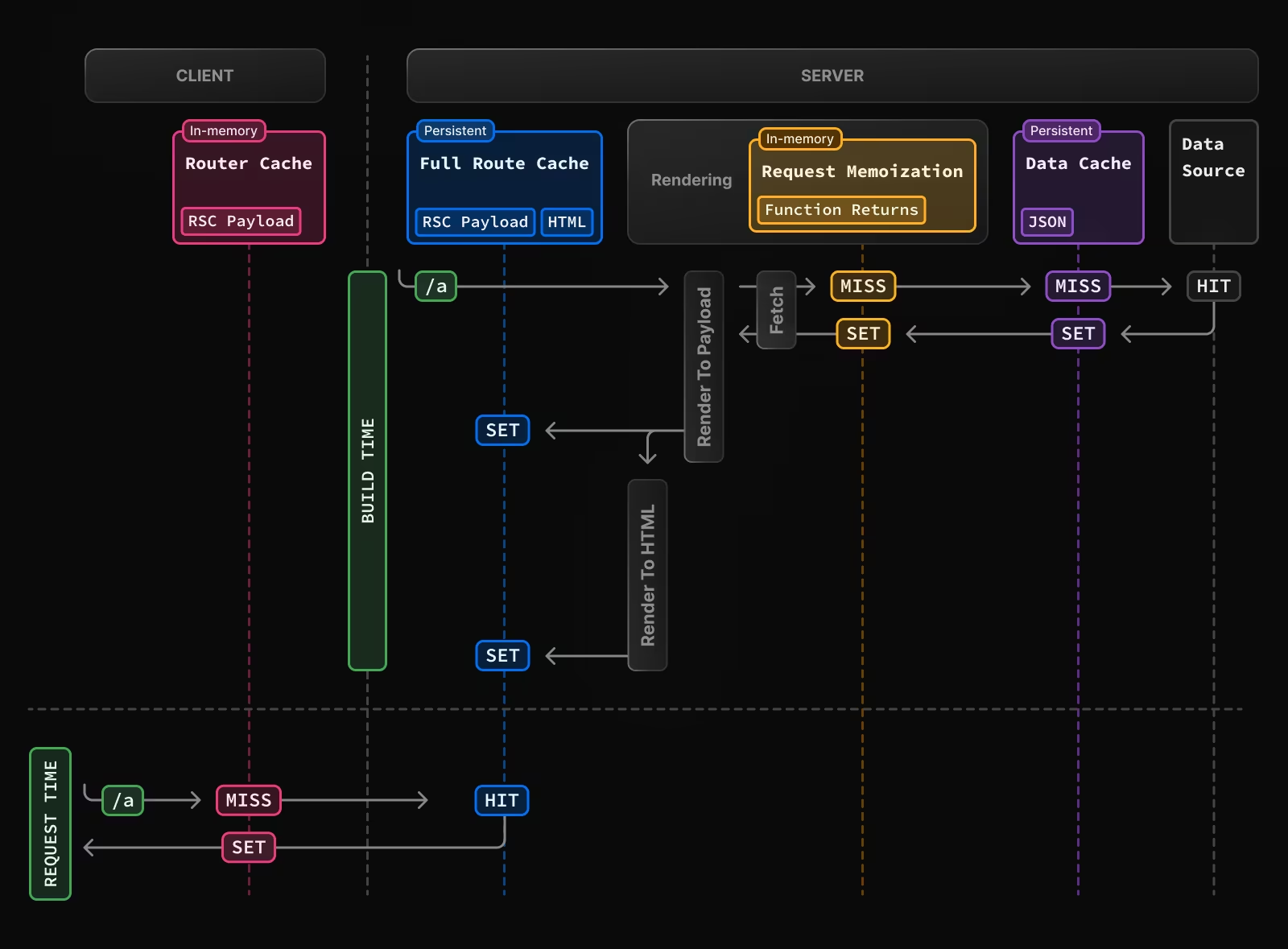
| 매커니즘 | 대상 | 장소 | 목적 | 기간 |
|---|---|---|---|---|
| Request Memoization | fetch 함수의 return 값 | 서버 | React Component tree에서의 data 재사용 | request 생명주기 동안 |
| Data Cache | Data | 서버 | 유저 요청이나 deplyoment 에 의해 저장된 데이터 | 영구적(revalidate 가능) |
| Full Route Cache | HTML,RSC payload | 서버 | 렌더링 cost 감소 및 성능 형상 | 영구적(revalidate 가능) |
| Router Cache | RSC Patload | 클라이언트 | 네비게이션에 의한 서버 요청 감소 | 세션 또는 정해진 기간 동안 |
Router Cache
Router Cacht는 클라이언트 사이드 캐시 또는 프리페치 캐시라고 부른다.
방문한 경로가 캐시되므로 즉시 뒤로/앞으로 이동하고, 프리페칭 및 부분 렌더링을 통해 새 경로로 빠르게 이동할 수 있다.
탐색 간에 전체 페이지를 다시 로드하지 않으며, React 상태와 브라우저 상태가 보존된다.
router cache를 지나갈 때 응답 받으면 뒤에 단계(Full router, request memoization, data cache)는 도달하지도 못함
Router Cache는 클라이언트에서 모든 페이지의 RSC Payload를 임시 캐싱하는 역할을 한다.
React Server Components - React18 에서 도입된 기능으로 서버와 클라이언트 간의 렌더링하는 방식을 변화 시킴 일부 컴포넌트를 서버에서 나머지를 클라이언트에서 렌더링해주는 페이로드 SSR과의 큰 차이점은 RSC payload 라는 JSON 포맷을 서버에서 직렬화하고 클라이언트에 전송한다.
지속
시간이 지나면 자동으로 초기화가 된다. 쿠키를 초기화하거나 온디맨드 재검증(revalidateTag, revalidatePath) 을 해야함
자동으로 지속되는 시간은 최소 30초에서 최대 5분정도이다.
새로고침하면 초기화가 된다.
즉 다른 경로를 갔다가 와도 router cache가 저장이 되었기에 변함이 없다. 새로고침을 하면 router cache 단계를 지나 request memoization , data cache 단계로 나아가는데 data cache 단계에서 처음 호출하는게 아닌 이미 존재하는 요청을 캐시로 저장을 하였다면 이미 캐시로 저장한 데이터를 반환한다.
Full Router Cache
Next.js 에서 자동적으로 빌드 시에 렌더와 캐시 작업을 하는데 이것은 서버에서 처리하는 것보다 로딩을 더욱 빠르게 해주는 매커니즘이다.
렌더링 작업은 경로 세그먼트와 서스펜스 단위에 따라 나눈다. 이때 경로 세그먼트를 캐시하는 것은 Router chach가 하는 작업으로 React Server Client Payload를 브라우저에 저장을 하지만 Full Router Cache는 서스펜스 단위로 작업을 하며 RSC Payload와 HTML을 지속적으로 저장하는 정적 렌더링 경로만 캐시한다.
즉 하이드레이션과 관련 있는 작업을 하는 cache이다.
Request Memoization
Request Memoization의 작동 방식은 경로를 렌더링 하는 동안 처음 호출이면 메모리에 저장되지 않고 캐시가 됩니다 이때 이걸 MISS라 부르고 데이터 소스에 접근하였을때 HIT 상태가 됩니다. HIT 데이터는 함수를 실행하지 않고 메모리에 반환되며, [렌더링]이 완료 되면 메모리가 재성절 되며 모든 요청 메모이제이션이 지워진다.
Request Memoization은 React의 기능으로 GET 요청만 적용되는 기능이다.
e.g) root layout과 a 페이지에서 두번 호출하고 있지만 실제로는 한 번만 호출되고 있다. 만약 b페이지에서도 요청을 하면 data cache를 확인하고 존재하면 캐시된 데이터를 리턴 받는다.
지속
캐시는 React 구성 요소 트리가 렌더링을 완료할 때 까지 서버 요청의 수명 동안 지속 된다. 즉 영구적으로 존재한다.
즉 동일한 URL을 가진 api 요청을 자동으로 Request Memoization 하여 2번 요청할걸 1번으로 줄여주는 역할을 한다.
데이터 캐시(Data Cache)
next.js에는 들어오는 서버 요청 및 배포 전반에 걸쳐 데이터를 가져온 결과를 유지하는 내장 데이터 캐시가 있다.
만약 {cache: 'no-store'} 의 경우 항상 데이터 소스에서 가져와서 메모제이션 된다. 즉 데이터가 캐시가 안되고 즉시 새로운 데이터가 적용이 된다. 그래서 최신의 데이터를 원할 때 사용한다.
우선적으로 router cache에 저장이 된다.
no-store는 data chche를 초기화하는게 아닌 우회한다. 그래서 skip이라 한다.
router cache를 지나갈 때 응답 받으면 뒤에 단계(Full router, request memoization, data cache)는 도달하지도 못함
작동 방식
렌더링 중 fetch가 호출되면 데이터 캐시 응답을 확인하고 캐시가 존재할 경우 즉시 데이터가 반환되고 memoization 됩니다.
데이터 캐시 vs 메모이제이션
두 캐싱 메커니즘은 모두 성능 향상을 위해 도움이 되지만 데이터 캐시는 api 요청 및 배포 전반에 걸쳐 영구적으로 지속되지만 메모이제이션은 요청이 지속되는 기간동안만 지속된다.
재검증(Revalidating) - data cache의 무력화
시간 기반 재검증
일정 시간이 지나고 새로운 요청이 있을때 데이터의 유효성을 다시 검사하는 기능으로 자주 변경되지 않고 최신데이터가 그다지 중요하지 않을때 유용
fetch('https://...', { next: { revalidate: 3600 } })처음으로 api를 요청하면 데이터 소스에 접근하여 데이터 캐시에 저장하고, 지정한 시간내에 예를 들면 5분이면 5분내에 호출되는 모든 요청은 캐시된 데이터를 반환한다. 그리고 시간이 지난 후에는 시간 기반 재검증을 트리거하여 새로운 데이터로 업데이트 한다.
온디맨드 재검증 (서버 액션 캐시 무력화)
이벤트를 기반으로 데이터를 재검증합니다. 태그 기반 검증과 경로 기반 접근 방식으로 나뉘는데 최신 데이터를 빨리 표시하려 할때 사용된다.
- 데이터 경로(revalidatePath)
- 데이터 태그(revalidateTag)
데이터 경로(revalidatePath)
동일한 요청을 각기 다른페이지에서 사용할 때 revalidatePath 을 하게 되면 흐름상 다시 돌아오는게 없는데 내부 구조에 의해 값이 변경된다.
서버에서 데이터가 최신화된 다음 페이지에서 새로고침을 해도 변함이 없는데 revalidatePath을 하게 되면 최신 데이터가 들어온다.
revalidatePath 가 지정한 경로만 최신데이터를 받아온다.
다른 경로는 새로고침시 전에 쓰던 데이터가 들어온다. 그치만 다른 경로를 갔다가 다시 그경로로 들어가면 data cache가 저장이 되어 데이터가 최신데이터로 캐시된다.
데이터 태그(revalidateTag)
revalidateTag는 {next: tags:['태그이름']} 는 태그이름을 담아서 보내기에 어떤 경로든 최신데이터를 받아올 수 있다. revalidatePath 보다 더 광범위한 전략이다.
즉 no-store -> 온디맨드 재검증 -> 시간 기반 재검증 순으로 데이터 최신화가 된다.
페이지 이동시 라우터 캐시
새로고침 데이터 캐시
cache: no-store는 최신 데이터를 받아오는 속도는 빠르지만 전체적으로 캐시를 지우는 것이니 내가 원하는 페이지에서만 캐시를 지우고 싶을 때는 revalidate를 사용하는 것이 더욱 효과적이다.
