우연히 유튜브에 뜬 영상에 대해 번역 해보았습니다.(영어실력이 좋은편은 아니라 파파고의 도움을 받아)
올라온 날짜는 무려 2월 28일.. 따끈따끈한 영상입니다.
어그로성 높은 제목답게 레딧이나 일부 커뮤니티에서도 당연히 핫한 반응이고 유튜브 조회수도 상당하네요.
제가 처음 이 영상을 본게 3월 4일인데 그때 조회수가 32만이었던거같은데 4일만에 36만... 하루단위로 1만씩 늘어났군요
아래글은 영상의 내용을 전부 싸그리 번역한것입니다.
열심히 스샷찍어가며 번역했는데 너무나도 슬프게, 요약 포스팅글이 있다는걸 너무 늦게 깨달아버렸습니다 ㅠㅠ
이분이 말씀하시는 클린코드는 주로 로버트 마틴의 저서인 클린코드책의 내용인것 같습니다.
...
초보 프로그래머들에게 특히 반복해서 강조되는 프로그래밍 조언 중 일부는
그들이 깨끗한코드(클린코드)를 써야 한다는 것이고 클린코드는 당신의 코드가 깨끗해지기 위해 당신이 무엇을 해야 하는지 알려주는 규칙의 긴 목록을 동반합니다.
이러한 클린코드를 측정하는 벤치마크는 없지만, 무엇을 해야하는지 알려주는 몇가지 규칙이 있습니다.
이러한 규칙 중 많은부분은 특히 컴파일된 경우에 런타임에 영향을 미치지 않아서, 우리는 클린코드에 대해 좋은것인지 나쁜것인지 객관적으로 평가할 방법이 없습니다. 그리고 꼭 그렇게 할 필요도 없는데, 그시점에서 꽤나 임의적인면이 있기 때문입니다.
하지만 클린 코드중 몇 가지는 사실 우리가 객관적으로 측정할 수 있는것들 입니다. 왜냐하면 그것들은 당신이 쓰고 있는 프로그램의 실행 시간에 영향을 미치기 때문입니다.
만약 당신이 클린코드 규칙목록을 보고 그것들을 수행한다면 그 클린코드가 컴파일되고, 최종사용자(end user)의 머신에서 실행되는데, 이때 영향을 주는것들이 몇가지 있다.
- 다형성 is good, if else / switch is bad
그러므로 가능하면, 항상 다형성을 사용한다. - no internals, 당신이 작업중인 어떤것의 내부를 알면 안된다(캡슐화?)
예를들어, 당신이 무언가를 하는 함수를 작성하면, 그것은 항상 객체의 다형성함수를 호출해야하고, 실제로 그 객체가 무엇을 하는지, 내부에대해서는 몰라야 합니다.(추상화된 인터페이스의 메서드를 호출하는것을 말하는것 같습니다.) - 함수는 작아야합니다.
- 함수는 한번에 한가지일을 해야합니다.
한가지일은 특정한 방식으로 정의되지 않고, 나는 실제로 그렇게 동작가능하지 않다고 생각합니다.
하지만 코드를 구조화하는 방법에 영향을 미치는 것은 일종의 일반적인 경험 규칙입니다. 함수를 작게 하는 것은 아마도 가능한 한도에서 가장 작은 것일 수 있습니다.
마지막으로
5.don't repeat yourself 혹은 DRY원칙
어떤 특정한 코드가 어떻게해야 클린해지는지에 대해 꽤 구체적입니다. 그래서 내가 묻고싶은것은 이 규칙에 의해 생성된 코드를 만들고, 그것이 어떻게 수행되는지 입니다. 내가 생각하기에 가장 좋은 코드구성은, 그들자신(클린코더)들의 예시를 사용하는것입니다.
내가 무언가를 만드는것은 아니라고 생각했기 때문에, 나는 그냥 그들이 실제로 예시로 들고있는 클린코드를 어떻게 해야하는지에 대한 예를 사용할것이기 떄문에, 클린코드 예제에서 자주 반복되는 예제인
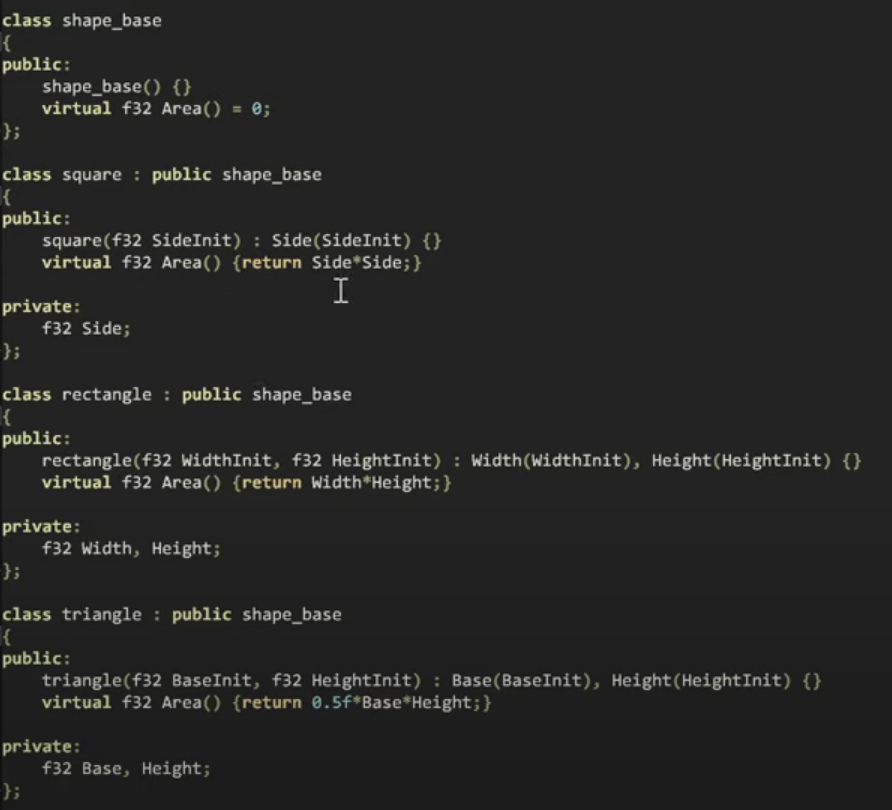
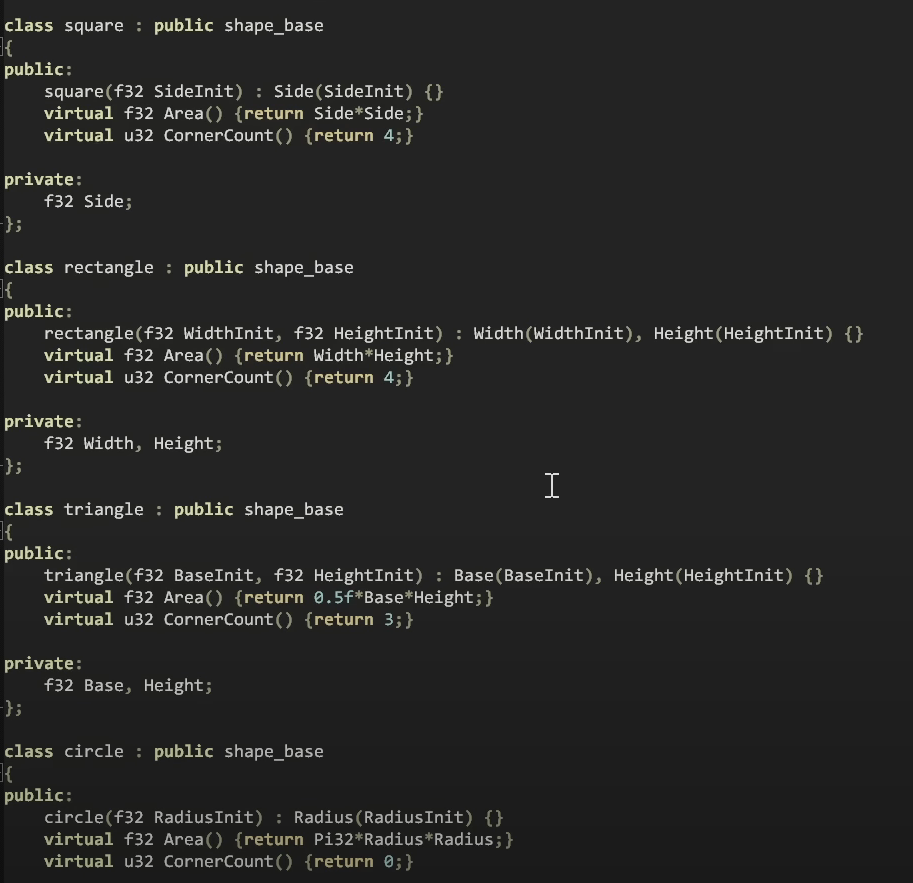
기본클래스로 Shape, 그리고 몇가지 Shape로 부터 파생된 Circle, Triangle, Rectangle, Square, 그외 몇개 더 추가할수있습니다.
우리는 면적을 계산하는 기능을 하는 가상함수를 가지고있고,
기본적으로 가지는 생각은, 다형성을 선호하는것입니다. 그리고 함수가 한가지의 기능만을 하고, 작아야합니다. 이제 우리는 이 작은 면적계산함수가 파생클래스 의존하는것을 알수있습니다. 이제 우리는 정사각형, 직사각형, 삼각형 또는 원에 대해 다른 면적 계산을 할 것입니다.
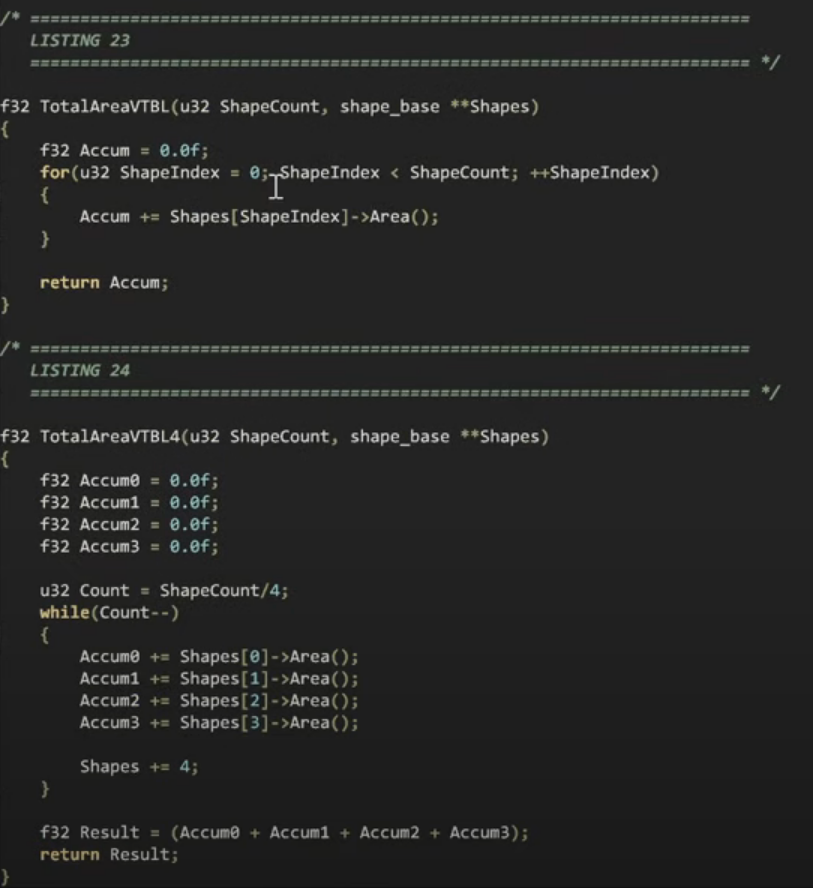
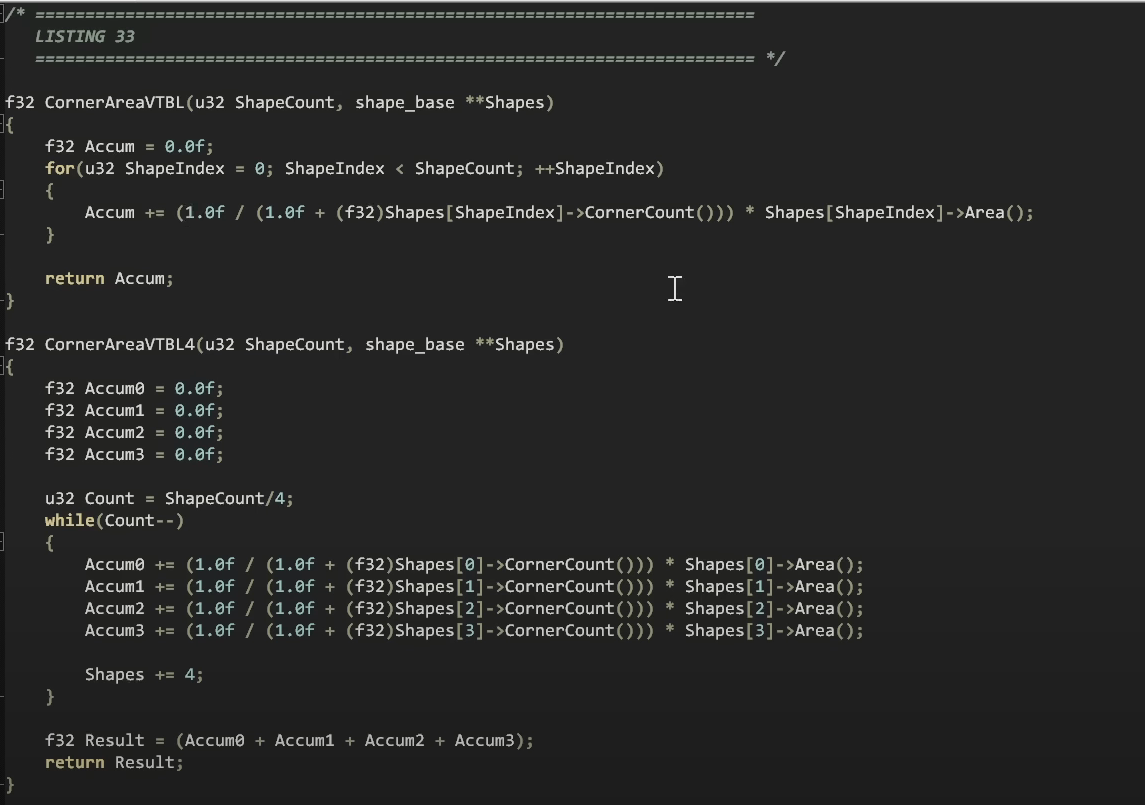
이 코드를 돌리는걸 상상해보면, 만약 우리가 이 도형들의 면적을 알고싶으면 이렇게 코드를 돌릴것입니다. 이터레이터가 없는것을 눈치챌수 있을텐데요, 이것은 클린코드에서는 이터레이터를 사용하라는 제안이 없기 떄문에, 의심거리를 주지않기 위해 컴파일러에 혼란을 주지않는 기본 for루프를 사용합니다.
이를위해 누적합산값을 만듭니다. 그리고 모든 도형의 배열을 루프를 돌며 누적합니다. 이 각각의 도형 크기를 모르기 떄문에 포인터 배열이여야 하는것에 주의해야합니다. 도형의길이를 파싱하고, skip procedure을 사용하지 않는한 도형이 어디있는지 알아보기 위해 포인터를 사용해야하고,
루프 종속성 - 루프의 각 반복이 이전 반복의 결과에 의존한다는 것을 의미합니다. 이는 성능 문제를 일으킬 수 있는데요. CPU는 다음 반복을 시작하기 전에 이전 반복의 결과를 기다려야 하기 때문입니다
이 있으므로 이 누적값은 매번 더해집니다. 따라서 루프의 결과가 어떤 예기치않은 동작의 영향을 받은게 아니라는것을 보장하기 위해, CPU가 덧셈에 대해 충분한 시간을 시간을 제공하기위해 4회, 각 4개의 별도 누적합산값을 사용해서 dependency chain을 깨뜨렸습니다.
만약 여기서 주어진 코드를 실행한다면, 우리는 각 도형에 대해 필요한 전체 사이클 수(도형당 필요한 CPU 클럭주기)를 얻을 수 있습니다. 예를 들어, 우리는 큰 도형 배열을 제공하고 한 도형을 처리하는 데 걸리는 시간을 계산할 수 있습니다. 이를 위해 반복 횟수가 1인 경우와 캐시를 조금 더 프라임한 경우를 포함하여 두 가지 방법으로 시간을 측정합니다. 이를 통해 캐시의 영향을 확인할 수 있습니다.
결과적으로, 이 코드에서는 각 도형 처리에 약 35개의 사이클이 소요됩니다. 이는 다형성을 사용하고 코드를 깨끗하게 유지하며, DRY(Do not Repeat Yourself) 원칙을 준수하는 경우입니다.
하지만 만약 우리가 다형성을 사용하지 않고 if-else 문을 사용하여 처리한다면 성능이 어떻게 변화할까요? 다형성을 사용하지 않고 가장 기본적인 방법인 if-else 문을 사용하면 코드의 성능이 어떻게 변할지 살펴볼 수 있습니다.
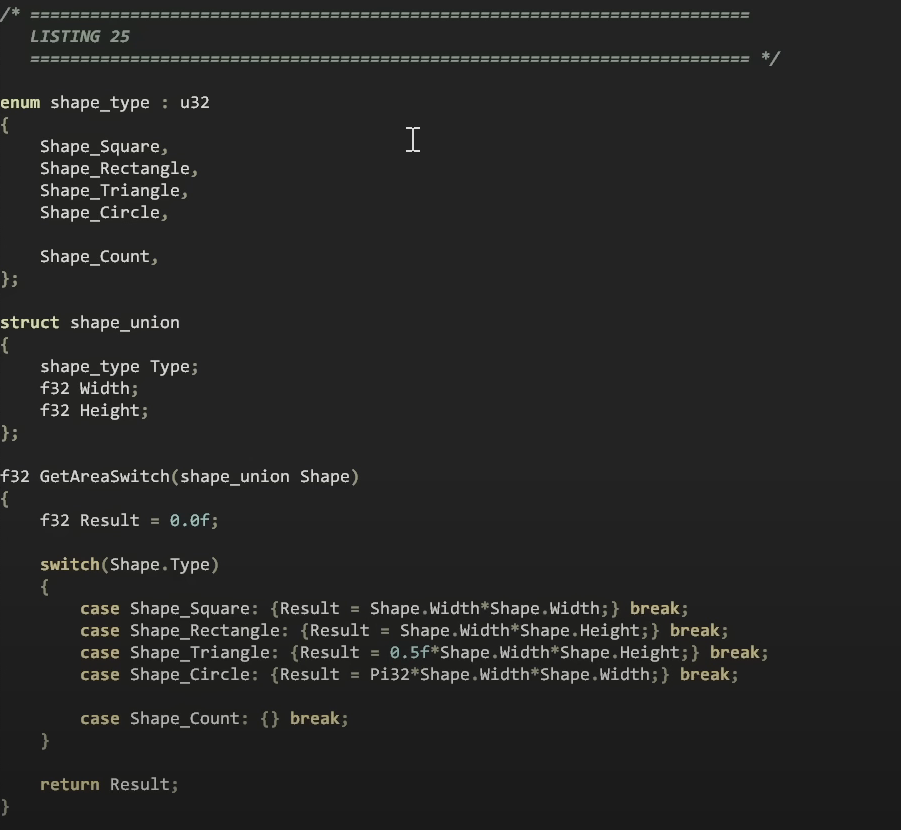
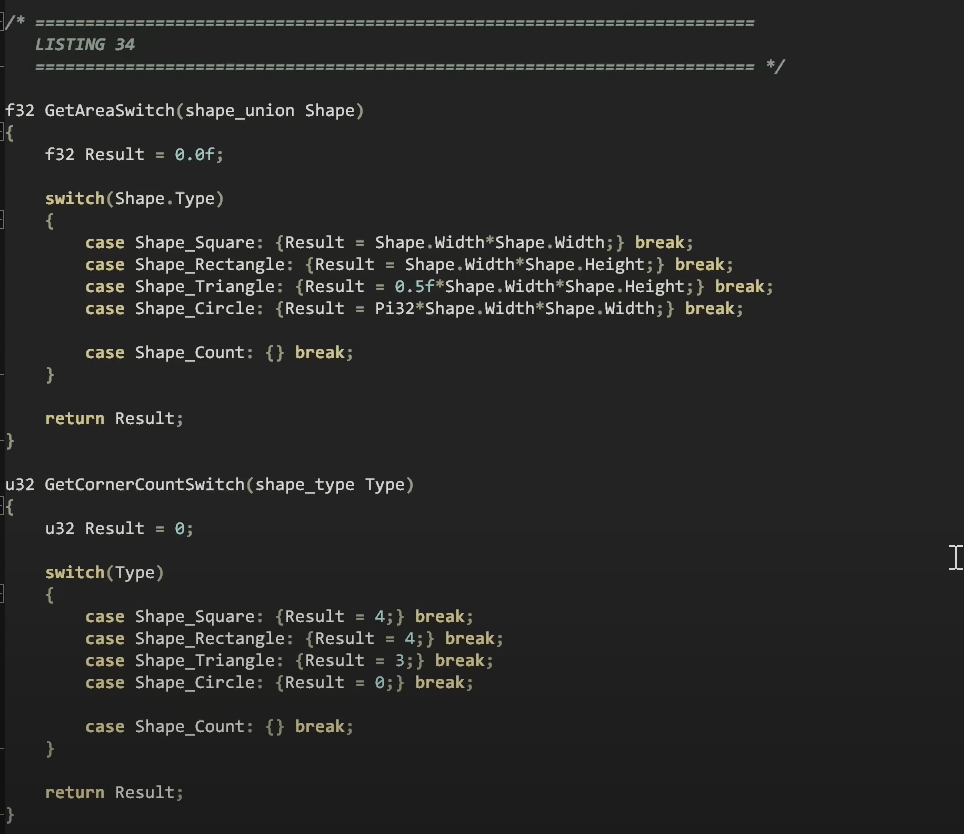
여기에서는 C++ 클래스와 가상 함수를 사용하여 다형성 방식으로 작성한 코드와 정확히 동일한 코드를 enum과 shape 유형을 사용하여 기존 방식으로 작성한 것으로 바꿔서 작성하였습니다.
예를 들어 높이가 없는 경우에도 (매개 변수가 하나뿐인 경우) 높이를 가지게 만듭니다.
그런 다음 가상 함수에서 영역을 가져오는 대신에 스위치 문에서 가져오도록합니다.
이것은 깨끗한 코드 강의에서 절대로 해서는 안 된다는 것과 정확히 일치하는 것입니다.
이제 타입을 스위치하고 해당 유형에서 도출 된 동일한 함수를 계산하도록하면 다형성을 사용하여 파생 클래스에서 계산 한 것과 정확히 동일한 계산을 수행합니다.
이제 우리는 정확히 동일한 코드를 가지고 있습니다.
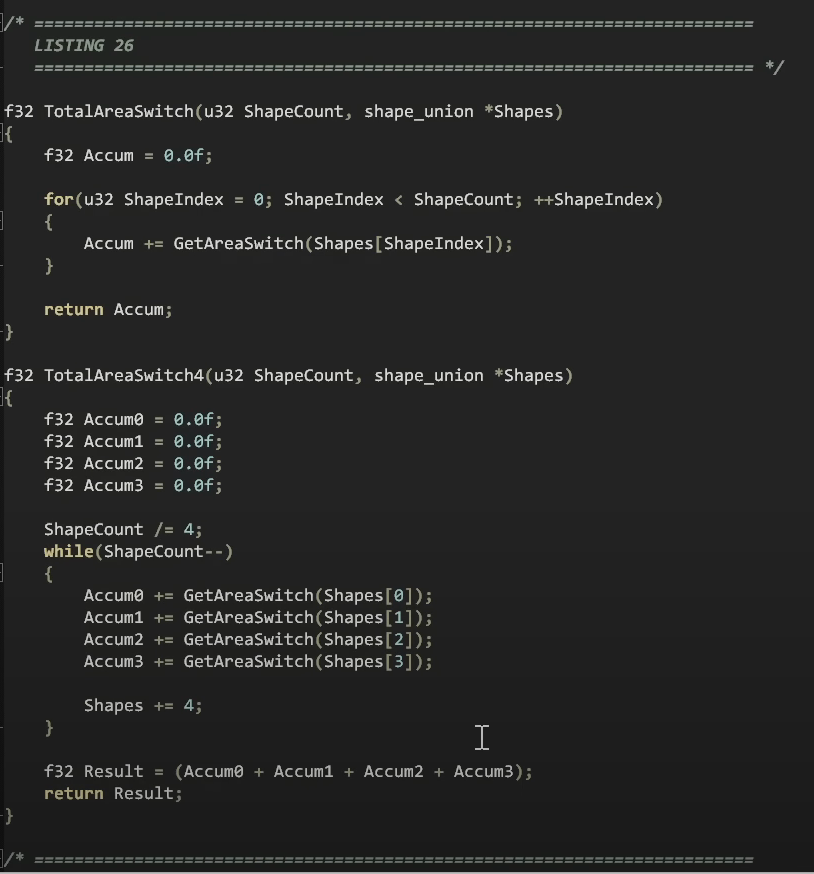
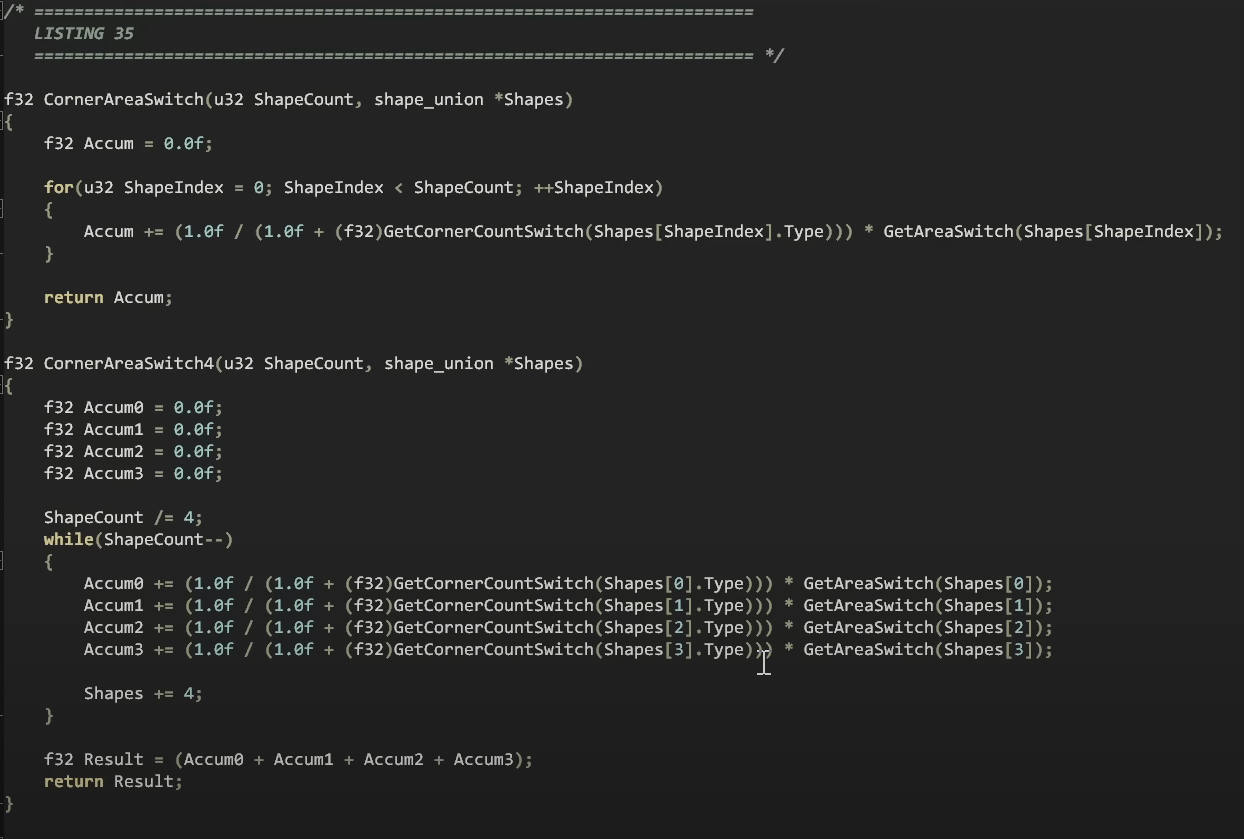
여기에는 이전에 보았던 다형성 버전의 정확히 동일한 루프에 대한 스위치 문 버전이 포함되어 있으며, 우리는 루프를 반복하고 포인터에서 함수를 호출하는 대신 get area switch 함수를 호출합니다.
이제 모양들은 배열에 있을 수 있으므로 포인터 간접 참조가 없으므로 동일한 크기를 가진 모양이 모두있는 이점을 얻게됩니다.
또한 기본 클래스에서 파생 된 유형이 어떤 것인지 궁금해 할 필요가 없으므로 컴파일러는 이 코드에 포함 된 모든 것을 볼 수 있습니다.
만약 우리가 C++ 클래스와 가상 함수를 사용하여 다형성을 구현한 버전과 기본 switch 문을 사용하여 구현한 버전 간의 성능 차이를 비교한다면, 이 두 버전의 성능 차이를 볼 수 있습니다.
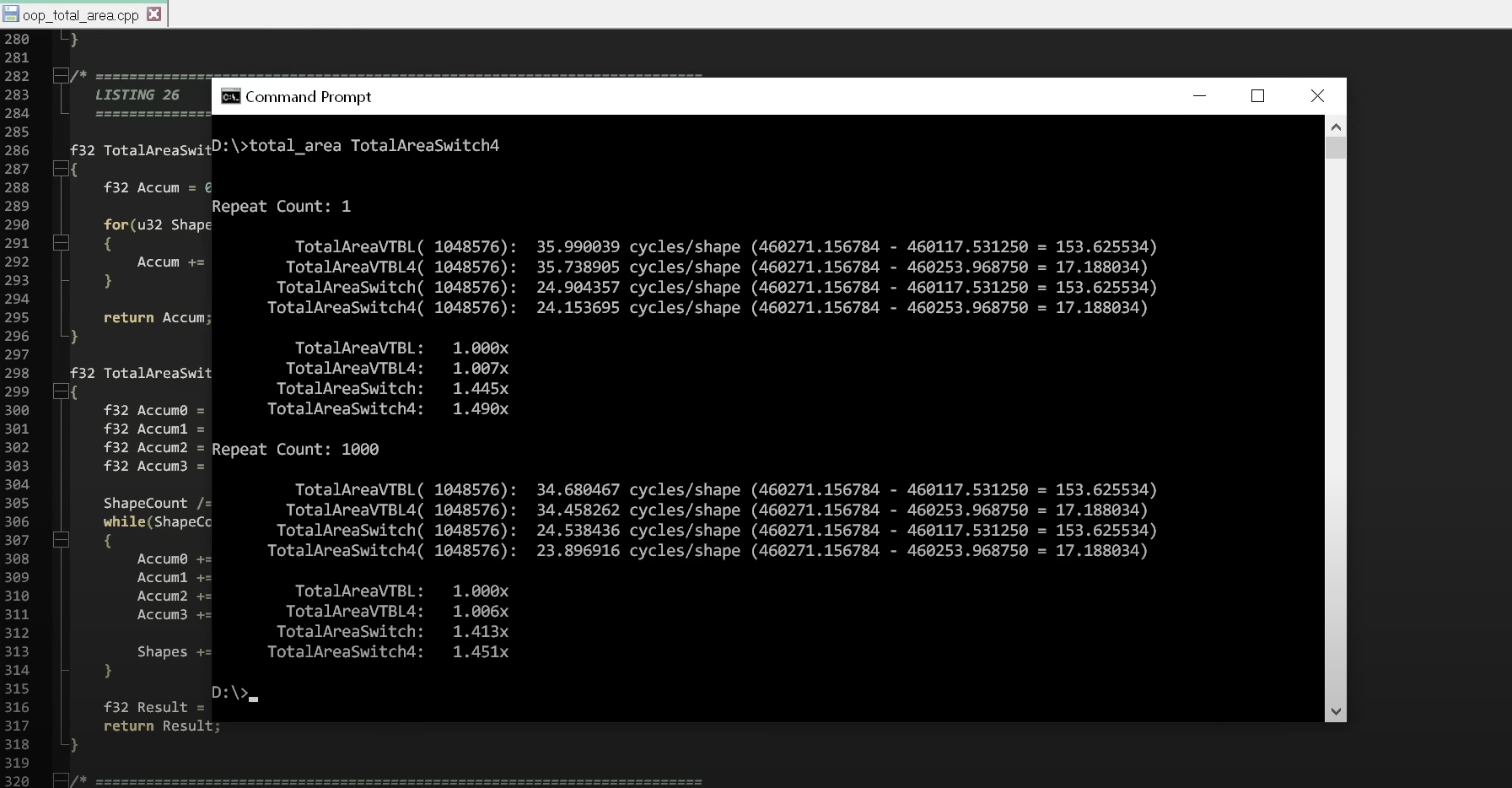
성능 테스트를 기다리지 않도록 비디오를 건너뛸게요. 결과를 살펴보면, 기존의 청결한 코드를 작성하는 방식 대신에 옛날 방식으로 작성한 것만으로도 효과적으로 1.5배의 성능 향상을 쉽게 얻을 수 있었습니다.
C++ 다형성을 사용하는 데 필요한 모든 잡다한 요소를 제거했을 뿐이었는데, 이를 위반하는 것으로 깨끗한 코드의 중요한 규칙 중 하나를 어겼음에도 불구하고 성능이 향상되었습니다.
이로 인해, 첫 번째 규칙을 따르는 깨끗한 코드 버전은 대략 1.5배 느립니다.
즉, 하드웨어적으로 이를 비유하면 iPhone 14 pro Max를 iPhone 11 Pro Max로 강등시키는 것과 같으며, 이는 하드웨어 발전의 약 3~4년치에 해당하는 것입니다.
왜냐면, 누군가가 다형성 대신 스위치문을 사용하도록 권유했기 때문입니다.
우리는 아직 시작에 불과합니다. 만약 우리가 이 네 가지 규칙을 따르는 것이 아니라 이 규칙 중 두 번째 규칙(캡슐화)도 깨본다면? 우리의 함수가 실제로 무엇을 조작하고 있는지 알고, 함수를 더 효율적으로 조작할 수 있을까요?
get area switch 문을 다시 살펴보면, 이들은 모두 다른 계수를 가진 동일한 함수를 계산하고 있습니다.
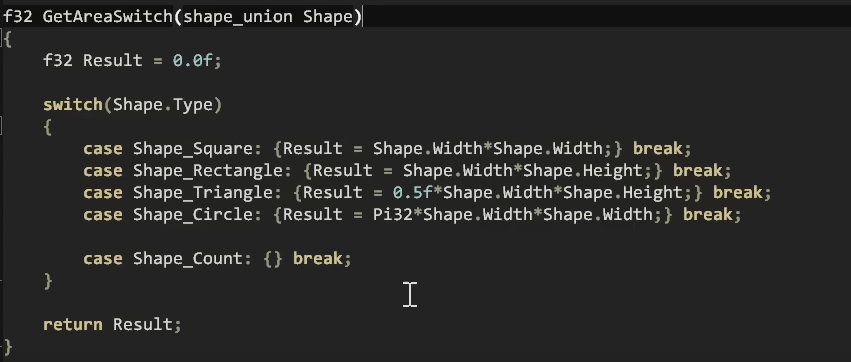
그들은 모두 width x height 또는 width x width와 같은 작업을 수행하고, 삼각형의 경우 절반으로, 원의 경우 Pi와 곱합니다.
switch 문은 이러한 공통 패턴을 쉽게 보여주기 때문에 함수별로 함께 묶여 있는 것보다 함수별로 살펴보면 공통 패턴을 추출하기가 매우 쉽습니다.
상대적으로, 클래스 버전을 다시 살펴보면 각각 다른 파일에 놓여져 있고 서로 상당한 유사점이 있음에도 불구하고 이러한 패턴을 발견하기 어렵습니다.
일반적으로 나는 이러한 구조를 아키텍처적으로 잘못되었다고 생각하지만, 그것은 별개의 문제입니다.
문제는 우리가 매우 간단하게 이를 단순화 할 수 있다는 것입니다. 이 예시는 제가 선택한 예시가 아니라 Clean Code 지지자들이 사용하는 예시입니다.
그러므로 이러한 패턴을 추출할 수 있음은 특정 예시에서만 가능한 것이 아니라, 일반적으로 코드에서 발생하는 일입니다.
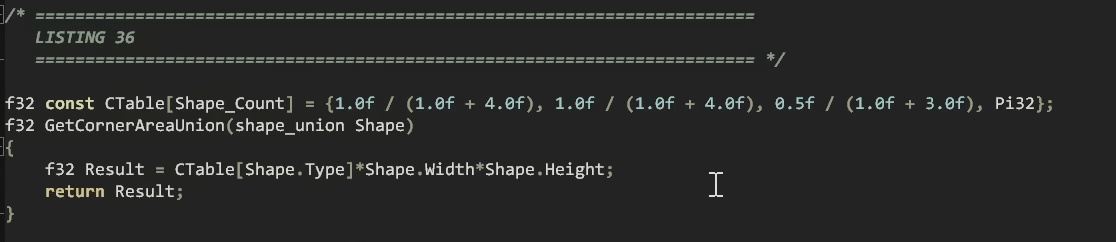
따라서 우리가 할 수 있는 것은 간단한 테이블을 도입하여 사용해야 할 계수를 나열한 다음, 너비와 높이가 항상 같은 값을 가지도록하여 너비를 두 번 사용하는 경우에도 높이를 채울수 있습니다.
이러면 여전히 동작할 것이며, 이를 통해 우리는 스위치 문을 하나의 간단한 식으로 축소할 수 있습니다.
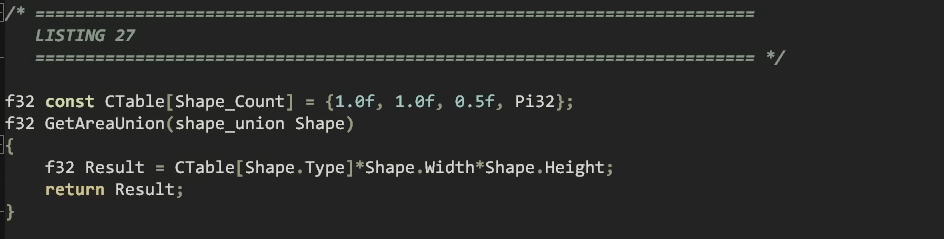
이 식은 작업에서 다른 것만 테이블에서 확인할 뿐이죠. 이제 이를 사용하여 우리의 면적을 얻는데 이전과 같은 두 함수를 수정할 필요가 없습니다.
이제 타입 자체보다 더 중요한 기능을 수행하도록 함수를 변환하고 투명한 상태로 유지하여 실제 유형에 대한 이해를 활용함으로써 대규모의 속도 향상을 얻을 수 있습니다.
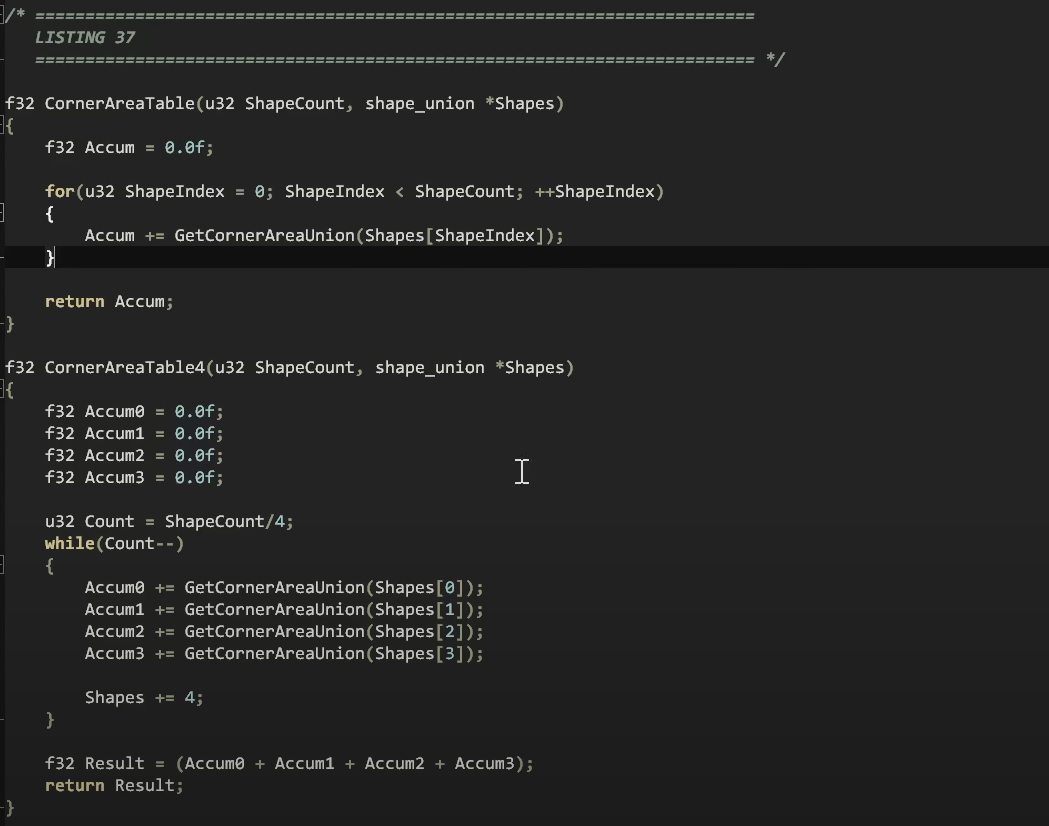
이제 우리는 매우 간단한 테이블 기반 계산을 사용하며 이전과 동일한 문제에서 단순히 1.5배 빠른 것이 아닌 최대 10배 이상 빠른 것으로 전환했습니다.
이 코드에서 실제 패턴을 함수별로 생각해보면서 내부 동작을 함수가 알 수 있도록 허용하면 실제로 패턴을 쉽게 관찰할 수 있으므로
저희가 원래 해야 할 방식대로 데이터 모델과 실제 코드를 결합시켜서, 클린 코드가 생기기 전에 하던 방식으로 코드를 작성하면서, 함수들이 자신이 작업하고 있는 것의 내부를 알 수 있도록 허용함으로써, 우리는 모든 도형에 대해 3.5 사이클로 단축시켰습니다.(~35(다형성버전), ~24(if else/switch 버전)
이것은 첫 번째 두 규칙을 따르는 클린코드 버전보다 10 배 이상의 속도 향상입니다. 이 중요한 것은 10 배는 너무나 큰 성능 향상이므로 iPhone 용어로 표현하기가 어렵다는 것입니다.
아이폰 벤치마크는 충분히 과거까지 돌아가지 않기 때문에, 만약 아이폰 6까지 돌아간다면 일반적인 벤치마크 사이트에서 확인할 수 있는 것처럼, 성능은 지금보다 3배 정도 느릴 것입니다.
따라서 10배 개선은 더 이상 핸드폰에 대입해서 설명할 수 없다. 데스크탑을 대상으로 본다면, 10배 속도 향상은 오늘날의 평균 CPU 성능을 2010년 평균 CPU 성능으로 되돌리는 것과 같다.
즉, 클린 코드의 첫 번째 두 규칙만으로도, 하드웨어 제조 업체들이 노력해서 제공하는 12년간의 하드웨어 개선을 제거하는 데 충분하다는 것 입니다.
하지만 중요한 점은 우리가 가장 간단한 작업만 수행하고 있다는 것입니다.
우리는 기본적으로 두 가지 작업을 수행하고 있습니다.
왜냐하면 우리가 하는 것은 면적을 계산하는 것뿐이며, 면적을 계산하는 것으로 큰 함수를 만드는 것이 매우 어렵기 때문입니다.
왜냐하면 그것은 곱셈이나 덧셈만 수행하기 때문입니다.
하지만 우리는 문제에 하나의 추가적인 속성을 추가하여 이 두 가지 규칙을 따르는 클린코드와 클린코드가 아닌 코드 간의 차이를 보고, 클린코드가 얼마나 더 나쁜 성능을 보일지 확인할 것입니다.
이전과 동일한 계층 구조가 있는데, 이번에는 코너의 카운트를 가져오는 하나의 추가 가상 함수를 추가했습니다. 즉, 직사각형은 네 개의 코너를 가지고 있으며 삼각형은 세 개, 원은 없습니다.
그런 다음 총 면적을 계산하지만 꼭지점 수에 1을 더한 값으로 가중치를 주어 곱하여 계산합니다. 이것을 하는 목적은 딱히 없습니다.
우리는 단순히 원래의 예제와 가능한 한 가까운 두 번째 속성을 포함한 계산할 것이 필요했기 때문에 이 작업을 수행하기로 결정했습니다.
Clean code 방식으로 이 작업을 수행할 때, 우리는 물론 Corner count와 area를 별개의 가상 함수로 호출한 다음 원하는 것을 계산합니다.
이를 더 나아가 다른 함수로 분리할 수도 있겠지만, 우리는 두 함수를 하나로 통합할 수 없다는 것을 분명히 알고 있습니다.
왜냐하면 그렇게 하면 클린코드의 규칙을 따르지 않게 되는데, 이는 모든 것이 가능한 최소기능 함수에서 시작하여 자신을 구성해야 한다는 것을 의미합니다.
그래서 우리가 할 수 있는 최선은 이것이며, 최악의 경우에는 이것을 더 다른 함수로 분리해야 할 수도 있습니다.
이렇게 남겨두는 것으로부터 이점을 얻을 수 있습니다. 일반적인 방법과 루프 캐리어 종속성을 깨는 버전 모두 사용할 때 깨끗한 코드 버전을 사용한 경우와 그렇지 않은 경우를 비교해 보면,
일반 버전에서는 매우 적은 변화가 있습니다. 단지 코너의 개수를 알려주는 추가적인 switch 문을 추가하고 동일한 것을 계산하기만 하면 됩니다.
클래스 케이스와 스위치 케이스 사이의 코드는 거의 동일하게 보입니다.
두 값을 가져오는 방법만 다릅니다. 가상 함수 호출을 통해 v 테이블을 통해 가져오거나 스위치 문을 통해 가져오는 것입니다. 그런 다음 테이블 드리븐 케이스가 있습니다.
테이블 드리븐 케이스는 데이터에 대한 지식과 우리가 하는 일에 대한 지식을 혼동해서 사용하기 때문에 멋집니다. 테이블 자체만 변경하면 됩니다.
테이블에 가중치 값을 직접 내장시킬 수 있기 때문에 우리는 모양에 대한 정보를 얻을 필요가 없습니다.
테이블에서 하나의 값을 조회하는 것 외에는 어떤 정보도 필요하지 않습니다.
이것이 바로 테이블 주도 방식이 효과적인 이유이며 무엇을 하는지를 아는 것이 왜 중요한지에 대한 이유입니다.(캡슐화를 비판중인것 같네요.)
그리고 그것을 수행하는 유형을 알고 있다면 컴퓨팅에서 합리적인 성능을 얻는 핵심 요소입니다.
이전과 같이 두 함수는 정확히 같습니다. 여기서는 다른 함수를 호출하지만 정확히 같은 계산을 수행합니다.
사실, 우리는 단지 우리가 사용하는 테이블을 변경하고 정확히 같은 것을 할 수 있었을 것입니다.
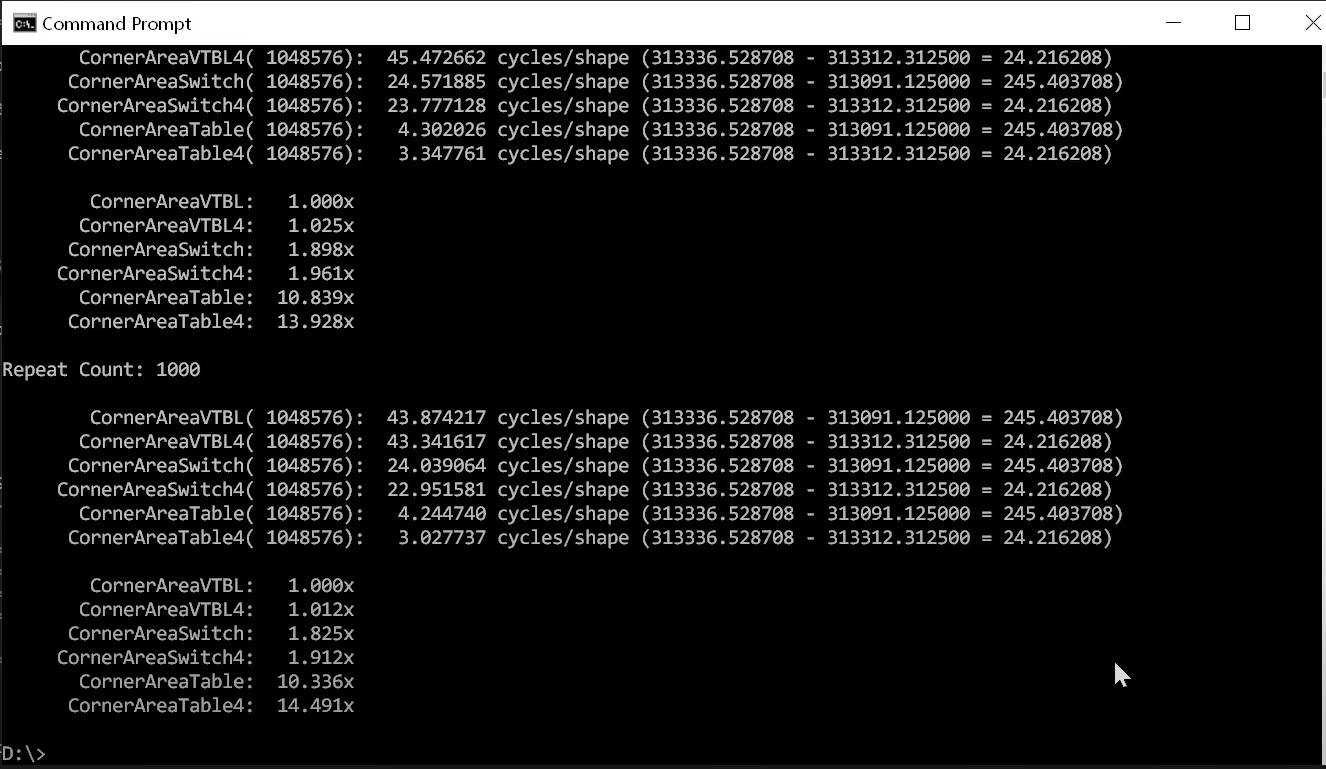
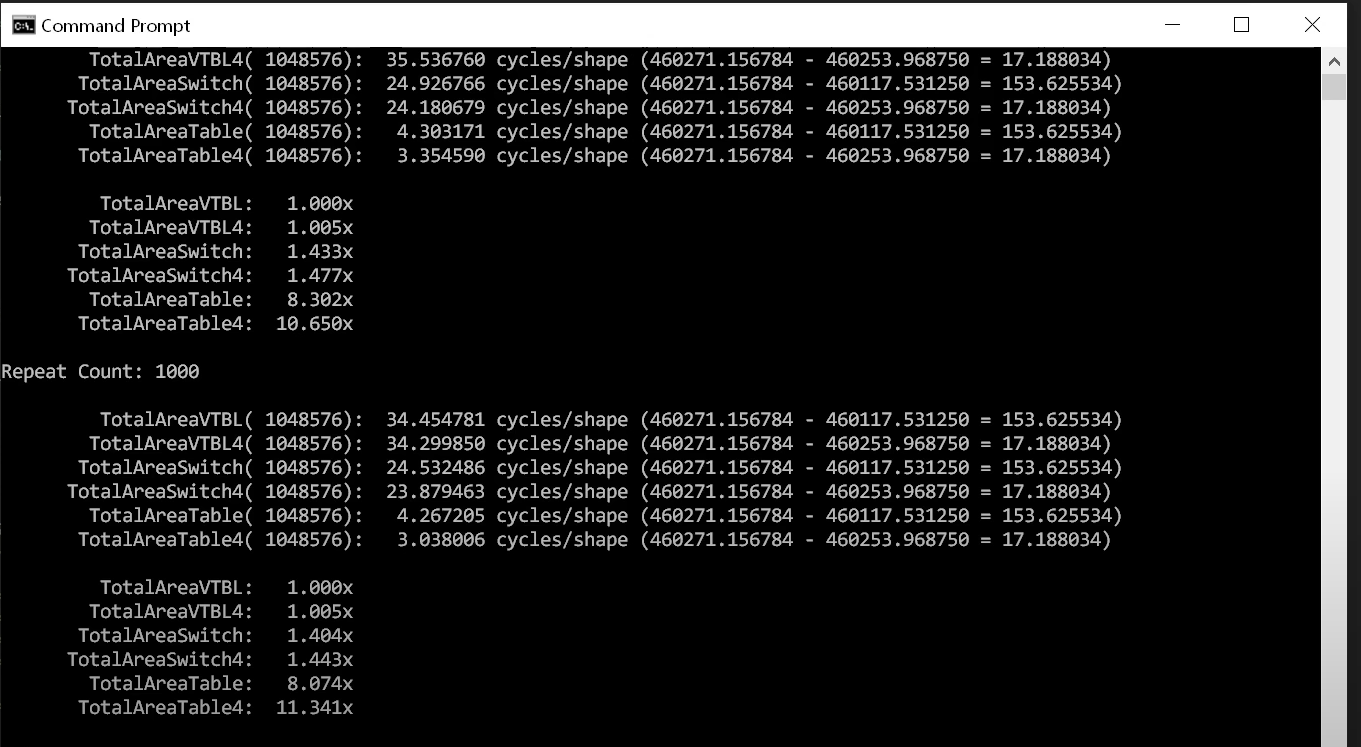
결과를 살펴보면 클린코드 버전은 더욱 나쁩니다. switch 문 버전은 거의 2배 빠르고 조회 테이블 버전은 거의 15배 빠릅니다. 이것은 말도 안 되는 일이며, 상황은 더욱 나빠집니다.
클린 코드 방법론을 사용할수록 컴파일러가 코드를 인식하기 어려워집니다. 모든 것이 가상 함수 호출과 그런 유형의 가려움으로 인해 불투명해져 컴파일러가 그 역할을 하기가 점점 더 어려워집니다.
물론 당신도 일을 잘 할 수 없습니다. 예를 들어 테이블에서 정보를 추출할 수 없으므로 코드가 그렇게 구성되지 않습니다.
문제를 더 복잡하게 만들면 클린 코드 솔루션이 이득이 아니라 오히려 손해입니다. 10배의 속도 차이에서 15배의 속도 차이로 갔습니다. 이는 하드웨어를 2008년으로 돌리는 것과 같습니다.
이제 문제의 정의에 하나의 새로운 파라미터만 추가했을 뿐인데 12년이 아니라 14년을 지웠습니다. 이는 그 자체로 끔찍한 일입니다.
하지만 여기서 실제로 최적화를 하지 않았음을 유의하십시오. 저는 SSE와 같은 현대 CPU 기능을 심지어 사용하지 않았습니다.
이는 컴파일러에 가장 기본적인 코드를 제공하고 깨끗한 코드 지침을 따르지 않기만 했기 때문에 15배까지 성능을 얻을 수 있었습니다.
물론 최적화된 버전을 작성하면 더 나빠질 것입니다. 실제 AVX 루틴을 포함한 모든 루틴을 실행하는 것이 어떻게 보이는지 여기에 나와 있습니다.
AVX 명령어 세트를 사용하여 루프에서 더 많은 성능을 얻기 위한 것입니다. 다시 말하지만 시간이 오래 걸리지 않도록 앞부분은 건너 뜁니다.
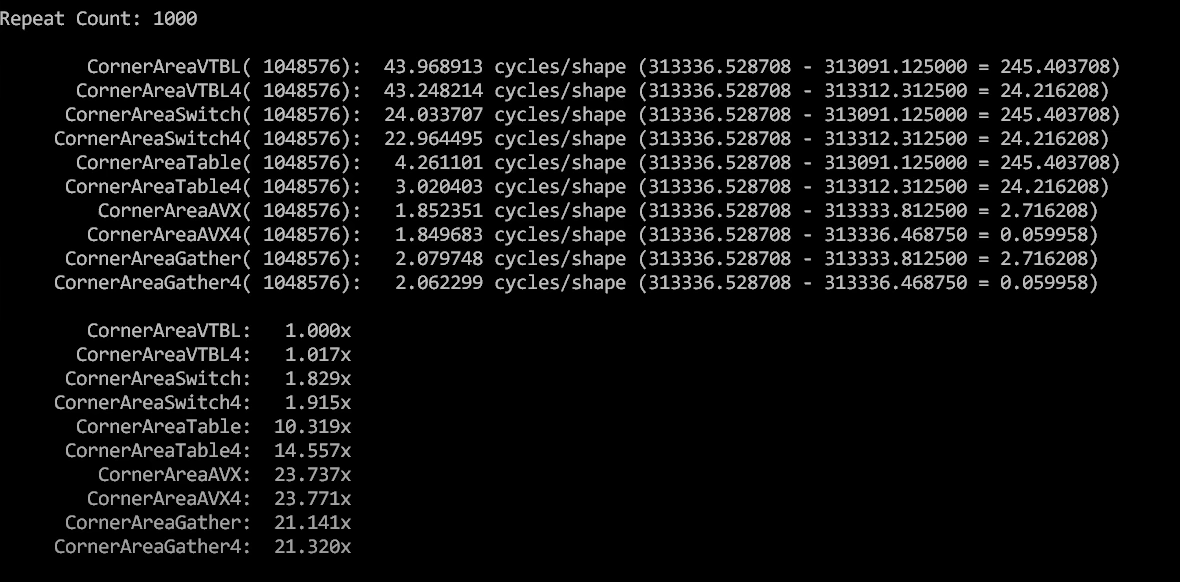
위의 결과를 보면 최상의 경우 AVX 최적화 루틴과 C++ v 테이블 버전 간에 21 배 이상의 속도 차이가 있으며 최악의 경우 24 배 이상입니다.
따라서 이 코드를 실제로 최적화하려는 경우를 가정하면, 내가 노력한 정도보다 더 나은 최적화 버전을 작성하려면 계수 선택과 같은 것을 위한 select style 및 계수를 table driving하는 루틴을 입력하기만 해도 20 배 이상의 속도 향상이 이루어집니다.
당신이 어떤 데이터를 AVX로 조직할지 결정하는 것과 같이 AVX를 위한 코드를 최적화하기 위해서는 clean code 원칙을 따르는 것이 불가능합니다.
클린코드를 지키는 것은 결국 최적화나 문제에 대한 특정 플랫폼의 CPU를 타겟팅하는 것을 시도할 때 항상 불가능합니다. 이러한 최적화를 수행하기 위해서는 이러한 규칙을 깨야만 할 것입니다.
따라서 실제로 최적화된 코드 또는 적어도 약간 최적화된 코드를 보려면 15배보다 더 나쁩니다. 15배는 아직 최적화를 수행하지 않았거나 문제에 대한 특정 플랫폼의 CPU를 타겟팅하지 않았을 때의 성능 차이입니다.
이 클린 코드 원칙 다섯 가지 중에서는, 다시 하지 말라(Don't repeat yourself) 라는 규칙은 그다지 문제가 없다는 것을 말씀드리고 싶습니다.
이 규칙이 두 개의 동일한 데이터를 인코딩하는 두 가지 서로 다른 테이블을 만들라는 것을 의미한다면, 이에 대해서는 동의하지 않습니다. 왜냐하면 더 나은 성능을 위해서는 이러한 것을 수행할 수 있어야 할 수도 있기 때문입니다.
하지만 일반적으로는 똑같은 코드를 두 번 작성하지 말고 필요에 따라 코드를 조합하라는 것에 동의합니다. 그래서 깨끗한 코드를 따라갈 필요가 없는 이유는, 소프트웨어가 하드웨어에 비해 매우 느리기 때문입니다.
소프트웨어 성능 저하의 원인은 여러 가지가 있지만, 일부 컴퓨팅 산업에서는 클린 코드라는 것이 소프트웨어 성능 저하의 원인 중 하나라고 말할 수 있습니다.
이러한 조언들은 성능에 대해 절대 좋지 않습니다. 따라서 이러한 원칙을 따라 할 필요는 없습니다.
이러한 권고 사항들은 모두 성능에 대해서 절대적으로 좋지 않습니다. 이러한 권고 사항들은 유지 보수 가능한 코드 베이스를 더 많이 생산할 것이라는 누군가의 생각에 따라 설계되었습니다.
그러나 그것이 실제로 유지 보수 가능한 코드 베이스를 더 많이 생산한다고 하더라도, 그 비용이 무엇인지 생각해야합니다.
프로그래머의 일은 우리가 제공된 하드웨어에서 실제로 잘 실행되는 프로그램을 작성하는 것입니다.
하드웨어 성능의 10 년 이상을 포기하여 프로그래머의 일을 조금 더 쉽게하는 것은 절대 허용될 수 없습니다.
그리고 이러한 규칙들이 소프트웨어 기반을 더 잘 유지보수할 수 있다고 생각한 사람이 디자인했지만, 실제로 그들이 소프트웨어를 느리게 만드는 주요 요인 중 하나라는 것을 생각해봐야 합니다.
이러한 조언들은 성능 면에서 절대적으로 형편없으며, 이러한 조언을 따르면 안 됩니다.
우리는 여전히 코드를 잘 조직화하고 유지보수하기 쉽게하고 읽기 쉽게하는 규칙을 생각해볼 수 있습니다.
이러한 목표들은 나쁘지 않지만, 이러한 규칙들은 그러한 것이 아니며, 이러한 규칙들이 소프트웨어가 15배 이상 느려지는 결과를 가져온다면, 큰 별표와 함께 이러한 규칙을 전달해야합니다.
=====================끝
뭔가 내용이 전반적으로 C기반 코드라 java 같은 언어면 JVM이 최적화 해주지 않을까라는 생각이 들었는데요
위 코드에 대한 Kotlin(JVM)에 대한 결과 by reddit 입니다 잘 최적화 해주는거같네요.
시간나는대로 현재 제 주력언어인 typescript로도 실험해봐야겠습니다...
Using polymorphism, 1 iterations:
Total area: 439595.0 - Time: 24.713600ms
Using switch (method), 1 iterations:
Total area: 439595.0 - Time: 17.631500ms
Using switch (global), 1 iterations:
Total area: 439595.0 - Time: 47.904600ms
Using polymorphism, 100 iterations:
Total area: 2.9979842E7 - Time: 1.074556200s
Using switch (method), 100 iterations:
Total area: 2.9979842E7 - Time: 967.910600ms
Using switch (global), 100 iterations:
Total area: 2.9979842E7 - Time: 972.801800ms
Using polymorphism, 1000 iterations:
Total area: 6.7108864E7 - Time: 9.945101600s
Using switch (method), 1000 iterations:
Total area: 6.7108864E7 - Time: 10.149413s
Using switch (global), 1000 iterations:
Total area: 6.7108864E7 - Time: 10.134583200s
제 개인적으로도 최근 switch를 보면 다짜고짜 다형성으로 별 생각 없이 변환한적이 많았는데요
성능 때문이라기보단, switch나 if else를 썼을때가 더 명확하게 이해가 되고 가독성이 좋은 경우도 있는것 같습니다.
데이터 테이블 이라는 관점도 조금 신기했고...
클린코드책에서 제시하는 내용들이 쓸모없다고 생각하진 않지만
개발자는 기본적으로 비판적인 시각을 가지는게 좋다고 생각해서 한번쯤 생각해볼만한 주제인것 같습니다.
