✨ Hive External 테이블과 Parquet 저장 파일 매핑
회사에서 Spark SQL를 이용해 Postgres RDB 에서 HDFS내의 Parquet형식으로 저장된 컬럼형 데이터들을 HDFS 내부에 적재해놓고
적재한 데이터를 기존에 사용중이던 Hue에서 Hive를 통해 조회하려 Mapping 작업을 진행하였고 이를 간단하게 정리하려고 함
전체 과정 순서
RDB -> Spark ->Hdfs (Parquet) <- Hue(Hive)
📜 RDB -> Spark
먼저 스파크에서 RDB 조회한 테이블 정보를 데이터 프레임으로 받아 날짜데이터를 변경후 을 적재하는 아주아주 간단한 코드
"""
RDB에서 데이터 조회
"""
dataset = spark.read.format("jdbc")\
.option("url","jdbc:mysql://{0}:{1}/{2}".format( ip, port, db ) )\
.option("driver", "com.mysql.cj.jdbc.Driver")\
.option("query", sql)\
.option("user", user)\
.option("password", passwd)\
.load()
"""
Date로 변환한 inserted_date컬럼 추가
"""
dataset = dataset.withColumn("inserted_date",to_date("inserted"))
"""
dataframe을 parquet 포맷으로 inserted_date 파티션을 추가 후 Hdfs로 적재
"""
dataset.write.partitionBy("inserted_date").parquet("hdfs://namenode:9000/kdn/pd_header/")📜 HDFS에서 parquet 포맷으로 저장된것을 확인 (아래 이미지)
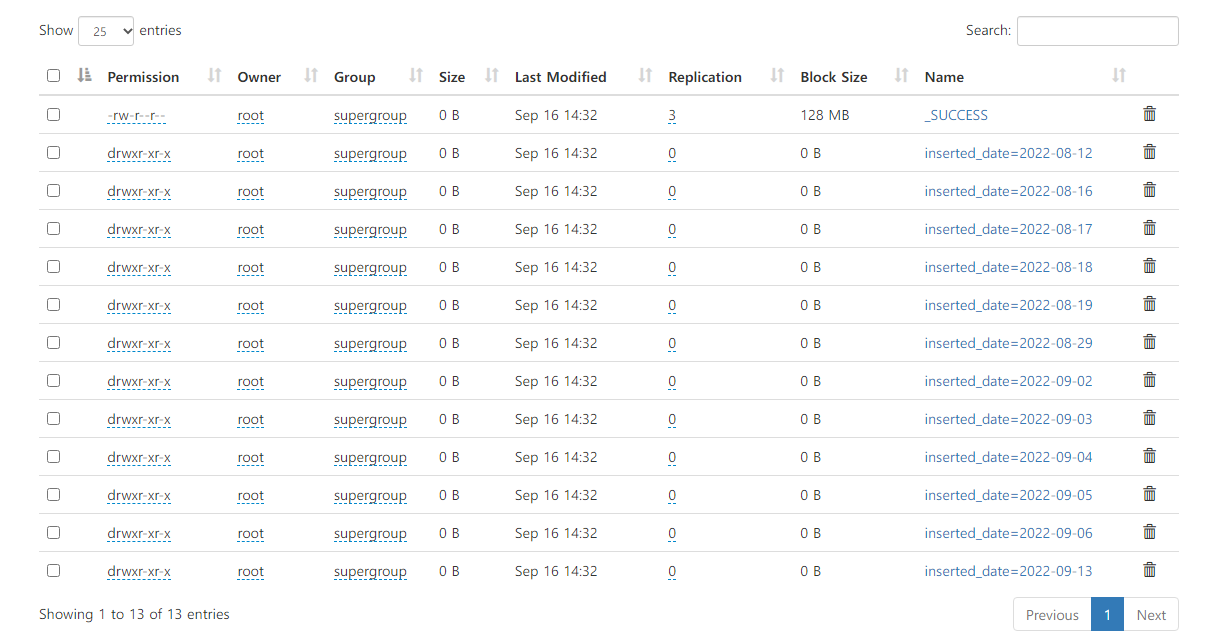
📜 Hive에서 아래와 같이 외부테이블을 생성
CREATE EXTERNAL TABLE example_tbl(
col1 string,
col2 string,
col3 string,
col4 string,
col5 string,
col6 string,
col7 string,
col8 string,
col9 string
)
partitioned by(inserted_date string)
STORED AS PARQUET
LOCATION '/wh/example_dir/';
📜 Alter Table로 적용후 조회
적용
ALTER TABLE example_tbl ADD PARTITION(inserted_date='2022-09-04') 조회
위에선 09월 4월 데이터만 적용했기 때문에 아래와 같이 입력해도 9월4일 데이터만 조회가 됨
SELECT * FROM example_tbl