RAG 프로세스
1. 문서 로드(Load): pdf
2. 분할(Split): 불러온 문서 chunk단위로 분할
3. 임배딩(Embedding): 문서를 벡터 포현으로 변환
4. 벡터DB(VectorStore): 변환된 벡터를 DB에 저장
RAB 수행
5. 검색(Retrieval): 유사도 검색(Dense)
6. 프롬프트(Prompt): 검색된 결과를 바탕으로 원하는 결과를 도출하기 위한 프롬프트
7. 모델(LLM): 모델선택(UPSTAGE)
8. 결과(Output): 텍스트, Json, 마크다운
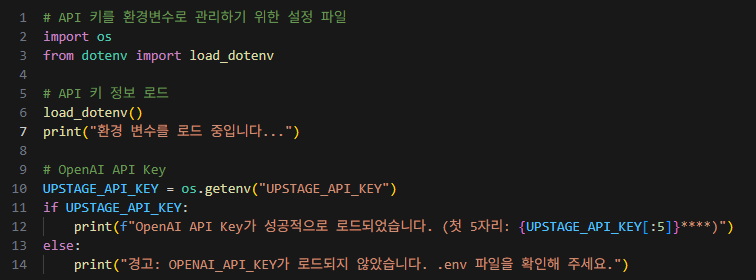
환경설정
-
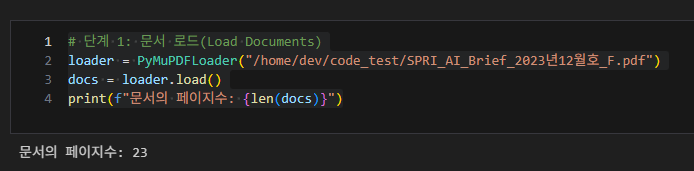
문서로드
-
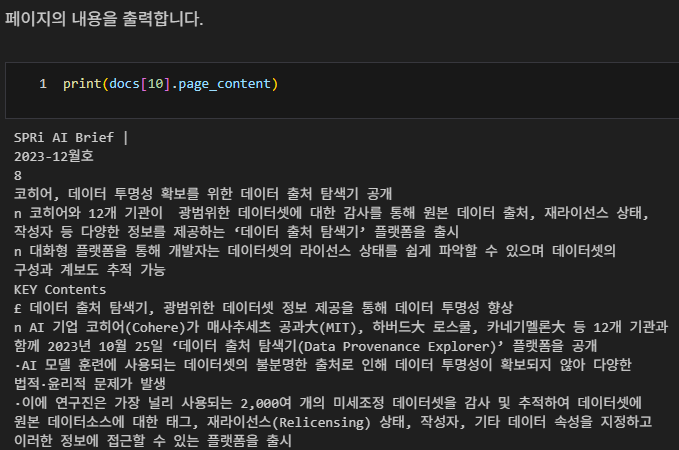
페이지 내용 출력
-
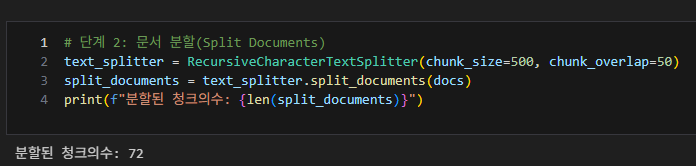
문서분할
-
임베딩생성
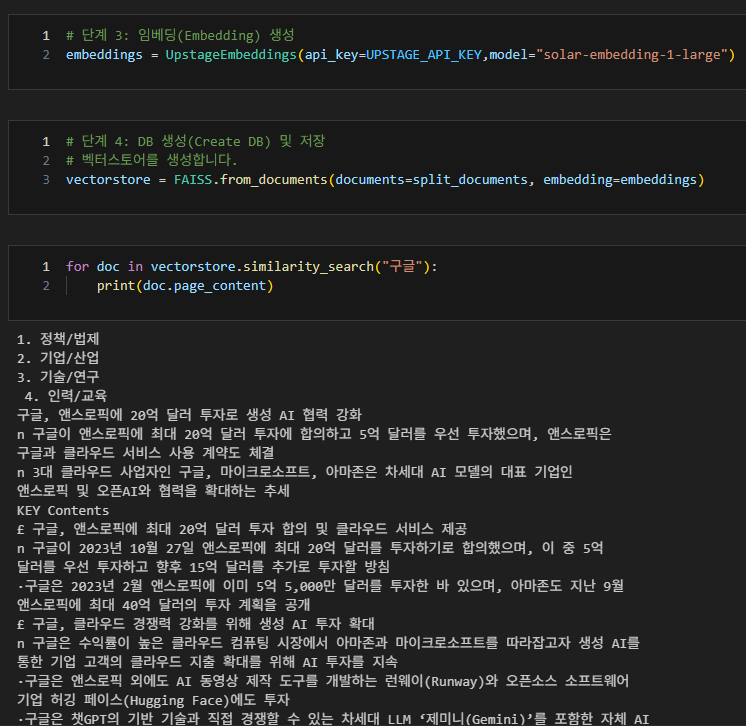
-
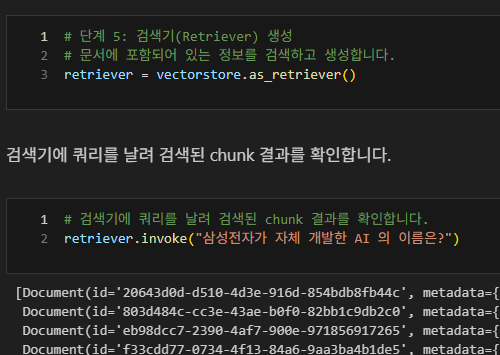
검색기 생성
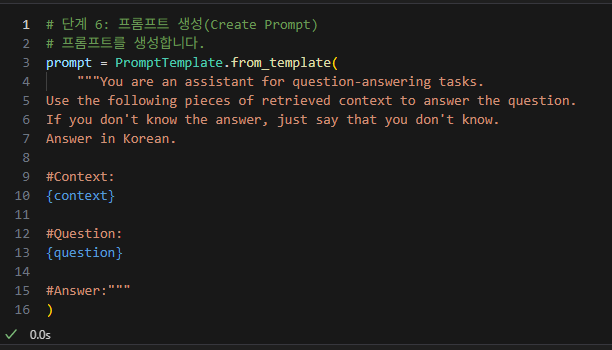
6.프롬프트 생성
-
언어모델 생성
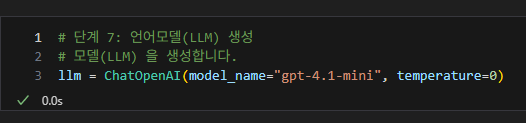
-
체인 생성
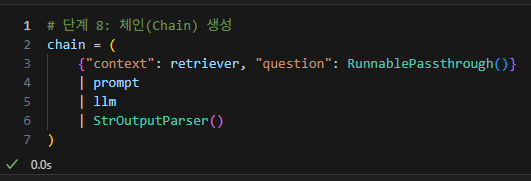
-
검색 테스트
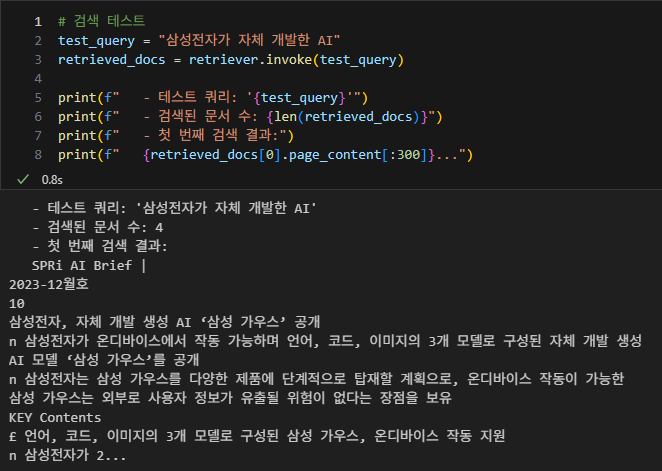
-
모델 초기화
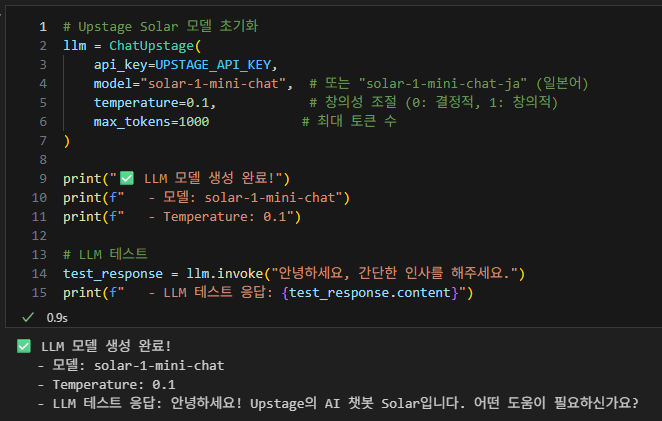
-
RAG 체인 구성
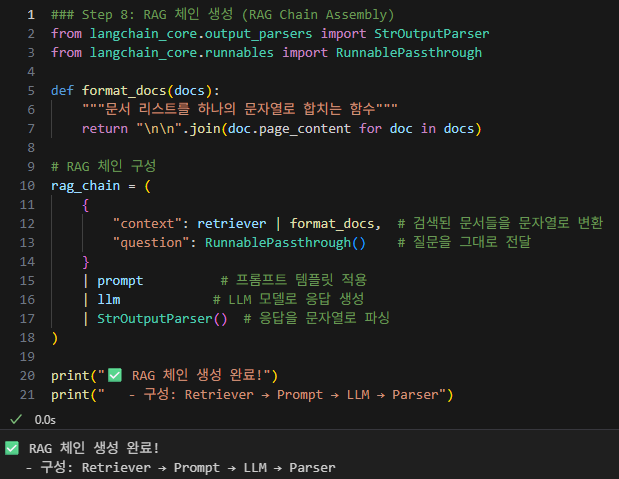
-
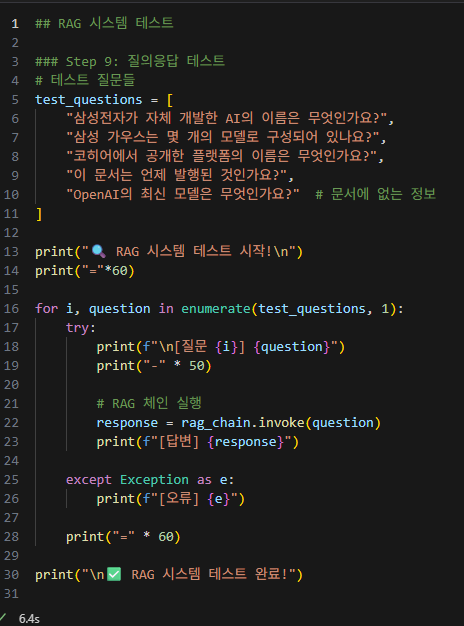
RAG 시스템 테스트

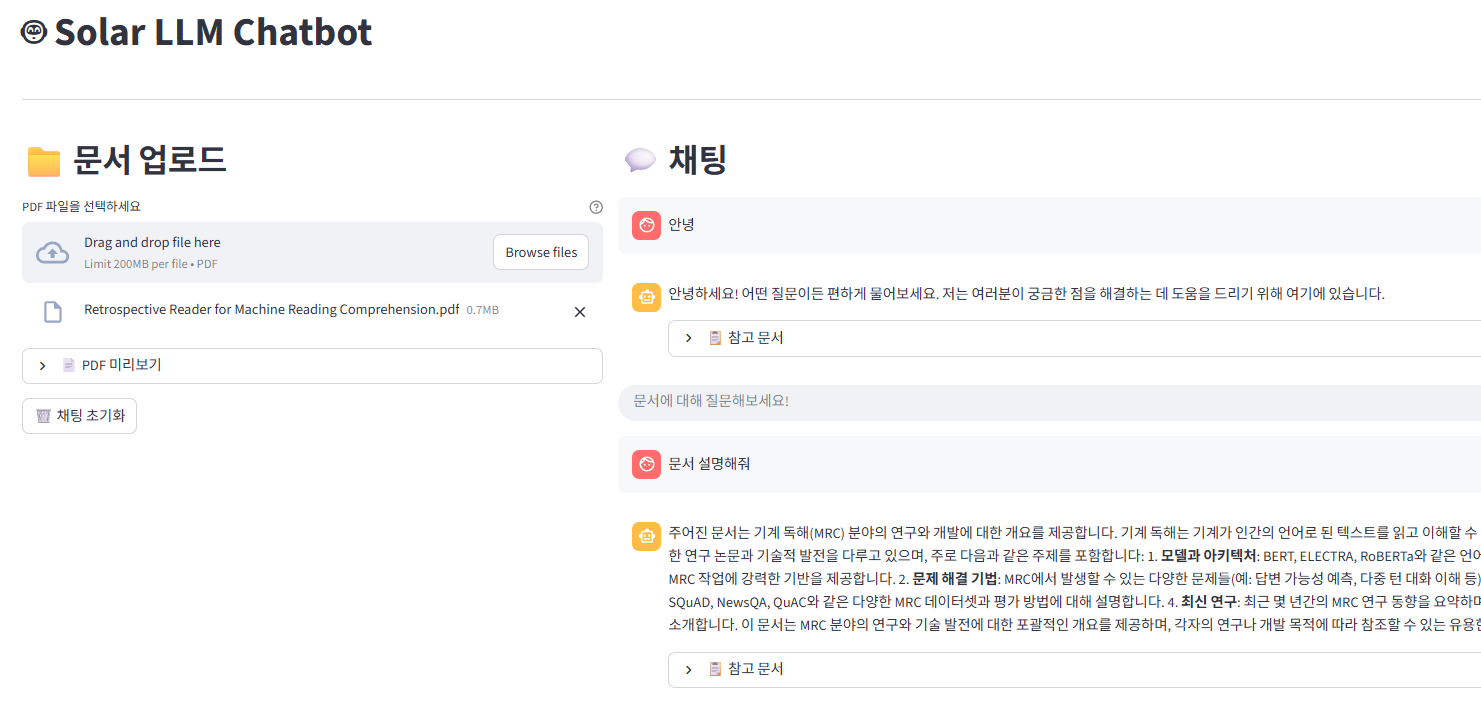
LLM Chatbot
참조자료: https://wikidocs.net/251190
프로젝트 회고:RAG PDF문서 API 불러오는것과 RAG구축하는 방법을 맛을 보았습니다.

함께 세상을 만드는 사람들