곱의 법칙
어떤 일이 여러 단계로 나뉘어 일어날 때, 각 단계에서 가능한 경우의 수를 곱하면 전체 경우의 수를 구할 수 있다는 법칙이에요.
예를 들어, 티셔츠 3벌과 바지 2벌이 있다면, 티셔츠와 바지를 '골라 입을 수 있는' 모든 경우의 수는 3 x 2 = 6가지가 되는 거죠.
예시
문제: 동전 1개와 주사위 1개를 동시에 던질 때, 동전은 앞면이 나오고 주사위는 짝수가 나올 확률은 얼마일까요?
풀이: 동전이 앞면이 나올 확률은 1/2, 주사위가 짝수가 나올 확률은 3/6 = 1/2입니다. 따라서 곱의 법칙에 의해 (1/2) x (1/2) = 1/4 입니다.

순열의 수에 대한 수식 표현
순열은 서로 다른 n개의 물건 중에서 r개를 '뽑아서 나열'하는 경우의 수를 말합니다.
nPr로 표현하며, 다음과 같이 계산합니다.
nPr = n x (n-1) x (n-2) x ... x (n-r+1) = n! / (n-r)!
(!는 팩토리얼 기호로, n!은 n부터 1까지의 모든 자연수를 곱한 값입니다. 예를 들어 5! = 5 x 4 x 3 x 2 x 1 = 120)
예시
문제: 5명의 학생 중에서 3명을 뽑아 줄을 세우는 방법은 몇 가지일까요?
풀이: 5P3 = 5 x 4 x 3 = 60. 즉, 60가지 방법이 있습니다.

수학적 확률
수학적 확률은 어떤 사건이 일어날 '가능성'을 숫자로 나타낸 것입니다.
수학적 확률 = (특정 사건이 일어나는 경우의 수) / (전체 가능한 경우의 수)
예를 들어, 주사위를 던져서 짝수가 나올 확률은 3/6 = 1/2 입니다. (짝수는 2, 4, 6으로 3가지 경우, 전체는 1, 2, 3, 4, 5, 6으로 6가지 경우)
예시
문제: 1부터 10까지 숫자가 적힌 공이 들어있는 상자에서 임의로 공을 하나 꺼낼 때, 3의 배수가 적힌 공이 나올 확률은 얼마일까요?
풀이: 3의 배수는 3, 6, 9로 3가지 경우입니다. 전체 경우의 수는 10가지이므로, 확률은 3/10입니다.

조건부 확률
어떤 사건이 일어났다는 '가정 하에' 다른 사건이 일어날 확률을 말합니다.
P(B|A)로 표현하며, 다음과 같이 계산합니다.
P(B|A) = P(A ∩ B) / P(A) (단, P(A) > 0)
(P(A ∩ B)는 A와 B가 동시에 일어날 확률)
예시
문제: 어떤 반 학생 30명 중 안경을 쓴 학생은 10명입니다. 여학생은 15명이고, 여학생 중 안경을 쓴 학생은 6명입니다. 임의로 선택된 학생이 여학생일 때, 이 학생이 안경을 썼을 확률은 얼마일까요?
풀이: P(안경|여학생) = P(안경 ∩ 여학생) / P(여학생) = (6/30) / (15/30) = 6/15 = 2/5

종속사건
두 사건이 서로 '영향을 주는' 경우를 말합니다.
사건 A가 일어나는 것이 사건 B가 일어날 확률에 영향을 미치면, A와 B는 종속사건입니다.
사건 A와 B가 종속사건이라는 것은 P(B|A) ≠ P(B) 라는 의미입니다. 즉, 사건 A가 일어났을 때 사건 B가 일어날 확률이, 사건 A가 일어나지 않았을 때 사건 B가 일어날 확률과 다르다는 것이죠.
예시: 상자 안에 빨간 공 3개와 파란 공 2개가 들어 있습니다. 공을 하나 꺼내고 '다시 넣지 않은' 상태에서 다른 공을 하나 더 꺼낼 때, 두 번째 꺼낸 공이 빨간색일 확률은 첫 번째 꺼낸 공의 색깔에 따라 달라집니다. 따라서 이 두 사건은 종속사건입니다.
신뢰구간
모집단의 진짜 평균(모평균)이 '어느 범위 안에 있을 것이다'라고 추정하는 구간입니다.
예를 들어, "우리 반 학생들의 평균 키는 160cm ~ 170cm 사이에 있을 것이다"와 같이 말하는 것입니다.
신뢰구간은 '신뢰수준'과 함께 제시됩니다. 신뢰수준은 우리가 추정한 구간 안에 실제 모평균이 들어있을 '확률'을 의미합니다. 예를 들어 95% 신뢰구간은, 100번 추정했을 때 약 95번은 실제 모평균이 그 구간 안에 들어있을 것이라고 예상하는 것입니다.
예시
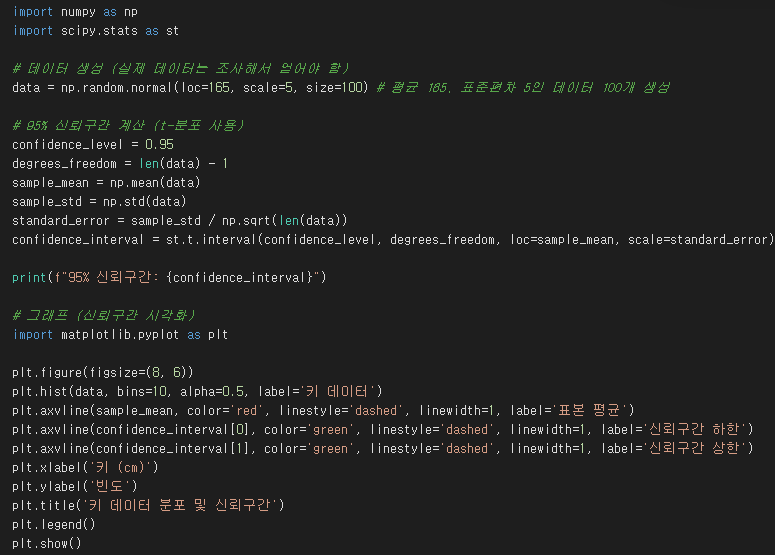
상황: 어떤 학교 학생 100명의 키를 조사했더니 평균이 165cm, 표준편차가 5cm였습니다.
결과: 95% 신뢰구간은 대략 164cm ~ 166cm 입니다. (계산 방법은 복잡하므로 생략)
해석: 이 학교 전체 학생의 평균 키는 95%의 확률로 164cm와 166cm 사이에 있을 것이라고 추정할 수 있습니다.
모평균의 신뢰구간
전체 집단(모집단)의 평균을 '정확히' 알기는 어렵기 때문에, 표본을 뽑아 그 표본의 평균을 이용하여 전체 집단의 평균이 '어느 범위 안에 있을지' 추정하는 것입니다.
모평균의 신뢰구간은 표본평균, 표준편차, 표본 크기, 신뢰수준 등을 이용하여 계산합니다. 신뢰수준이 높을수록 신뢰구간은 넓어집니다. (더 넓은 범위로 추정해야 더 확신할 수 있기 때문입니다.)
예시
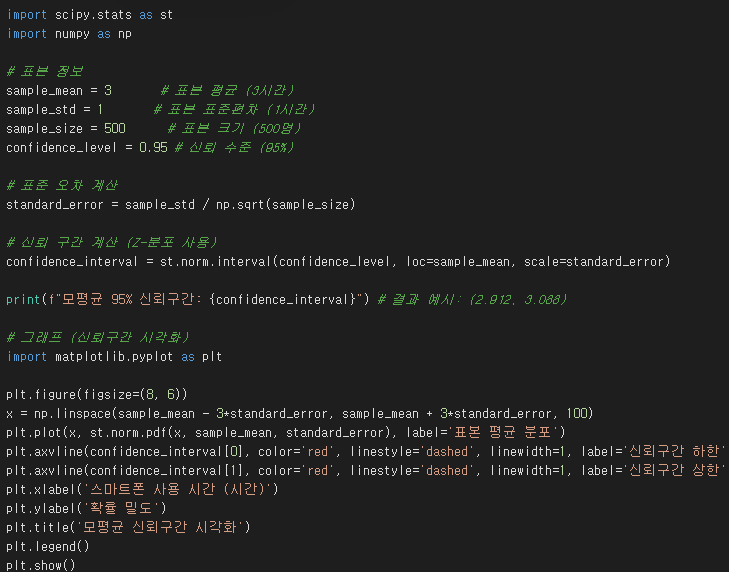
문제: 어떤 도시의 성인 500명의 하루 평균 스마트폰 사용 시간을 조사했더니, 평균 3시간, 표준편차 1시간이었습니다. 이 도시 전체 성인의 하루 평균 스마트폰 사용 시간에 대한 95% 신뢰구간을 구하세요.
풀이: (계산 과정은 복잡하므로 생략). 95% 신뢰구간은 대략 2.9시간 ~ 3.1시간입니다.
해석: 이 도시 전체 성인의 하루 평균 스마트폰 사용 시간은 95%의 확률로 2.9시간과 3.1시간 사이에 있을 것이라고 추정할 수 있습니다.
유의확률 (p-value)
우리가 세운 가설이 '얼마나 말이 안 되는지'를 나타내는 값입니다.
유의확률은 귀무가설이 참이라고 가정했을 때, 관측된 데이터 또는 그보다 더 극단적인 데이터가 나올 확률입니다. 일반적으로 유의수준(α)과 비교하여 가설의 채택 여부를 결정합니다. (유의수준은 보통 0.05로 설정)
예시
가설: "새로운 약이 효과가 없을 것이다" (귀무가설)
실험 결과: 새로운 약을 투여한 환자들의 증상이 많이 호전되었습니다.
유의확률: 0.01 (1%)
결론: 유의확률이 유의수준(0.05)보다 작으므로, 귀무가설을 기각합니다. 즉, 새로운 약이 효과가 없다는 가설은 틀렸을 가능성이 높습니다.
가설검정의 절차
어떤 주장이 맞는지 틀린지 '과학적인 방법'으로 판단하는 과정입니다.
로지스틱 회귀 알고리즘을 도식화
어떤 일이 일어날지 안 일어날지를 예측하는 데 사용하는 방법입니다.
로지스틱 회귀는 입력 변수(설명 변수)를 사용하여 결과 변수(종속 변수)가 특정 범주에 속할 확률을 예측하는 알고리즘입니다. 결과 변수는 주로 0 또는 1과 같은 이진 값으로 표현됩니다.
입력 변수: 예측에 사용되는 정보 (예: 학생의 공부 시간, 광고 클릭 횟수)
선형 결합: 입력 변수와 각 변수에 대한 가중치를 곱하여 모두 더합니다.
시그모이드 함수: 선형 결합의 결과를 0과 1 사이의 값으로 변환합니다. 이 값이 특정 범주에 속할 확률을 나타냅니다.
손실 함수: 예측 값과 실제 값의 차이를 계산하여 모델의 성능을 평가합니다.
최적화: 손실 함수를 최소화하는 가중치를 찾기 위해 반복적으로 가중치를 조정합니다.
예시
문제: 학생의 공부 시간(x)을 이용하여 시험 합격 여부(y: 0 또는 1)를 예측
1단계 (입력 변수): x = 공부 시간
2단계 (선형 결합): z = w * x + b (w: 가중치, b: 절편)
3단계 (시그모이드 함수): p = 1 / (1 + exp(-z)) (p: 합격 확률)
4단계 (손실 함수): 예측 확률 p와 실제 합격 여부 y를 이용하여 손실 계산
5단계 (최적화): 손실을 최소화하는 w와 b를 찾음
시그모이드 함수
어떤 숫자를 0과 1 사이의 값으로 바꿔주는 특별한 함수입니다.
시그모이드 함수는 다음과 같은 수식으로 표현됩니다.
σ(z) = 1 / (1 + exp(-z))
여기서 z는 입력 값이고, exp는 지수 함수(e^z)를 의미합니다. 시그모이드 함수의 출력 값은 항상 0과 1 사이의 값을 가지며, 입력 값이 커질수록 1에 가까워지고, 작아질수록 0에 가까워집니다.
예시
입력 값 (z): -5, 0, 5
시그모이드 함수 출력:
σ(-5) ≈ 0.007
σ(0) = 0.5
σ(5) ≈ 0.993

손실 함수 (Loss Function)
우리가 만든 예측이 '얼마나 틀렸는지'를 숫자로 나타내는 것입니다.
손실 함수 값이 작을수록 예측이 정확하다는 의미입니다.
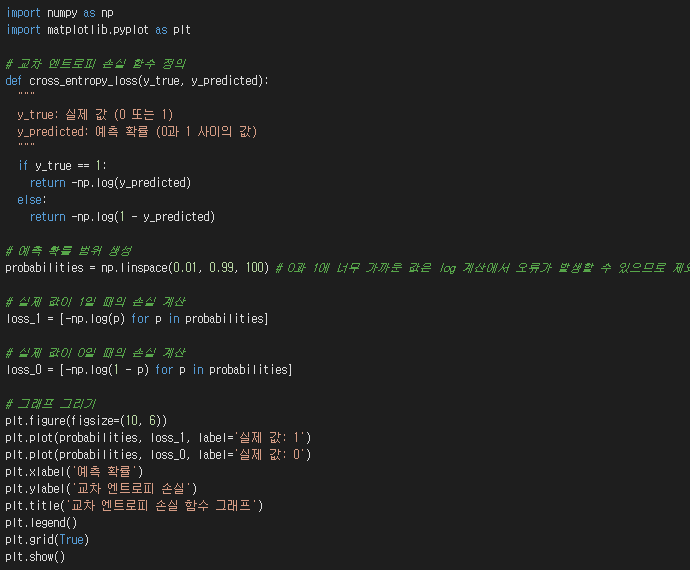
손실 함수는 모델이 예측한 값과 실제 값 사이의 차이를 측정하는 함수입니다. 로지스틱 회귀에서는 주로 '교차 엔트로피 손실 (Cross-Entropy Loss)' 함수를 사용합니다. 교차 엔트로피 손실은 다음과 같이 계산됩니다.
만약 실제 값이 1이라면: -log(예측 확률)
만약 실제 값이 0이라면: -log(1 - 예측 확률)
예측 확률이 실제 값과 가까울수록 손실은 작아지고, 멀어질수록 손실은 커집니다. 목표는 이 손실 함수의 값을 최소화하는 것입니다.
예시
상황: 어떤 학생이 시험에 합격했는지 (1) 또는 불합격했는지 (0)를 예측하는 모델을 만들었습니다.
예측 1: 합격 확률 90% (0.9), 실제 합격 (1)
손실: -log(0.9) ≈ 0.105 (작은 손실)
예측 2: 합격 확률 30% (0.3), 실제 합격 (1)
손실: -log(0.3) ≈ 1.204 (큰 손실)
예측 3: 합격 확률 10% (0.1), 실제 불합격 (0)
손실: -log(1 - 0.1) = -log(0.9) ≈ 0.105 (작은 손실)
예측 4: 합격 확률 80% (0.8), 실제 불합격 (0)
손실: -log(1 - 0.8) = -log(0.2) ≈ 1.609 (큰 손실)
텍스트
