자료구조
파이썬이라는 프로그래밍 언어에서는 여러 가지 자료구조를 쉽게 사용할 수 있도록 만들어져 있어요. 그중 가장 기본적인 것 중 하나가 바로 '리스트(List)'라는 자료구조예요. 리스트는 여러 개의 데이터를 순서대로 담아두는 데 사용돼요. 마치 장바구니에 물건을 하나씩 담는 것처럼요.

내장 함수
- 리스트 (List)
정의: 순서가 있는(ordered) 데이터들의 가변적인(mutable) 집합입니다.
특징:
요소의 추가, 삭제, 수정이 자유롭습니다.
인덱스를 사용하여 특정 위치의 요소에 접근할 수 있습니다.
크기가 동적으로 변합니다.
사용 예: 파이썬의 list, 자바의 ArrayList 등. 데이터를 순서대로 저장하고 자주 변경해야 할 때 사용됩니다.

- 튜플 (Tuple)
정의: 순서가 있는(ordered) 데이터들의 불변적인(immutable) 집합입니다.
특징:
한번 생성되면 요소의 변경, 추가, 삭제가 불가능합니다.
리스트보다 메모리 효율이 좋고 처리 속도가 빠를 수 있습니다.
인덱스를 사용하여 특정 위치의 요소에 접근할 수 있습니다.
사용 예: 파이썬의 tuple 등. 변경되지 않아야 하는 데이터의 모음(예: 좌표, 설정값)이나 함수에서 여러 값을 반환할 때 사용됩니다.

- 스택 (Stack)
파이썬 리스트의 append()와 pop() 메소드를 사용하여 스택을 구현할 수 있습니다. append()는 스택의 맨 위에 요소를 추가하는 Push 역할을 하고, pop()은 맨 위의 요소를 제거하고 반환하는 Pop 역할을 합니다.

- 큐 (Queue)
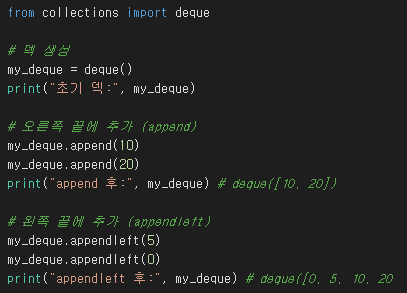
파이썬 리스트로 큐를 구현할 수도 있지만, 리스트의 pop(0) 연산은 효율성(O(n))이 떨어집니다. collections 모듈의 deque는 양쪽 끝에서의 삽입/삭제가 O(1)로 효율적이므로 큐 구현에 더 적합합니다.
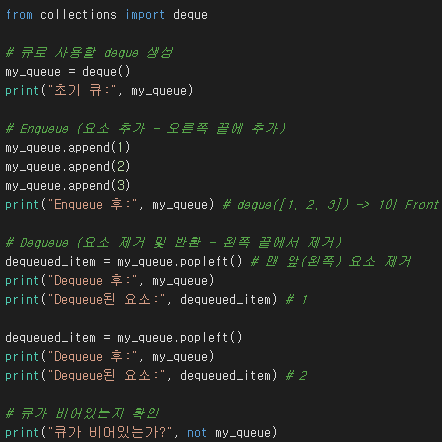
- 테크 (Tech)
collections.deque는 이름 그대로 양쪽 끝에서 삽입/삭제가 가능한 덱을 구현합니다.
시퀀스 자료구조의 주요 특징:
순서 (Ordered): 데이터 요소들이 저장된 순서가 유지됩니다.
인덱스 접근 (Indexed Access): 각 요소는 0부터 시작하는 정수 인덱스를 가지며, 이 인덱스를 사용하여 특정 위치의 요소에 직접 접근할 수 있습니다.
반복 가능 (Iterable): for 루프 등을 사용하여 요소들을 순서대로 하나씩 반복하며 접근할 수 있습니다.
슬라이싱 (Slicing): 인덱스 범위를 지정하여 여러 요소를 한 번에 잘라낼 수 있습니다.
대표적인 시퀀스 자료구조 (주로 파이썬 기준):
리스트 (List):
순서가 있고 인덱스로 접근 가능합니다.
가변(Mutable)입니다. 즉, 생성 후에 요소를 변경, 추가, 삭제할 수 있습니다.
다양한 타입의 데이터를 저장할 수 있습니다.
튜플 (Tuple):
순서가 있고 인덱스로 접근 가능합니다.
불변(Immutable)입니다. 즉, 한번 생성되면 요소를 변경, 추가, 삭제할 수 없습니다.
리스트보다 메모리 사용량이 적고 처리 속도가 빠를 수 있습니다.
문자열 (String):
문자들의 순서 있는 시퀀스입니다.
각 문자는 인덱스로 접근 가능합니다.
불변(Immutable)입니다. 한번 생성된 문자열의 특정 문자를 직접 변경할 수 없습니다.
시퀀스 자료구조에 적용 가능한 주요 연산:
인덱싱 (Indexing): sequence[index] 형태로 특정 위치의 요소에 접근합니다.
슬라이싱 (Slicing): sequence[start:stop:step] 형태로 부분 시퀀스를 얻습니다.
반복 (Iteration): for element in sequence: 형태로 모든 요소를 순회합니다.
길이 확인: len(sequence) 함수로 요소의 개수를 얻습니다.
연결 (Concatenation): + 연산자로 두 시퀀스를 연결합니다 (새로운 시퀀스 생성).
반복 (Repetition): * 연산자로 시퀀스를 반복합니다 (새로운 시퀀스 생성).
멤버 확인 (Membership): element in sequence 형태로 특정 요소가 시퀀스 안에 있는지 확인합니다.
순서 유지 (Order Preservation)란, 데이터 요소들이 자료구조에 저장될 때 특정한 순서대로 배열되고, 그 순서가 유지되는 것을 의미합니다. 그리고 이 순서대로 데이터를 읽거나 접근할 수 있습니다.
선형 자료구조 (Linear Data Structure)나 시퀀스 자료구조 (Sequence Data Structure)가 바로 이 "순서 유지" 특성을 가집니다.
리스트 (List): 요소를 추가한 순서대로 저장되며, 인덱스를 통해 그 순서대로 접근하거나 수정할 수 있습니다.
튜플 (Tuple): 요소를 정의한 순서대로 저장되며, 인덱스를 통해 그 순서대로 접근할 수 있습니다 (불변이라 수정은 안 됨).
문자열 (String): 문자 하나하나가 순서대로 배열되어 있으며, 인덱스를 통해 접근할 수 있습니다.
스택 (Stack): LIFO (Last-In, First-Out)라는 정해진 순서(마지막에 들어온 것이 먼저 나가는 순서)에 따라 데이터가 관리됩니다.
큐 (Queue): FIFO (First-In, First-Out)라는 정해진 순서(먼저 들어온 것이 먼저 나가는 순서)에 따라 데이터가 관리됩니다.
덱 (Deque): 양쪽 끝에서 삽입/삭제가 일어나지만, 내부적으로는 요소들이 순서대로 연결되어 있습니다.
순서 유지가 중요한 이유:
예측 가능한 접근: 데이터를 저장한 순서나 자료구조의 규칙(FIFO, LIFO 등)에 따라 예측 가능한 방식으로 데이터에 접근하고 처리할 수 있습니다.
인덱스 기반 연산: 리스트, 튜플, 문자열처럼 인덱스를 제공하는 자료구조에서는 순서가 유지되므로 특정 위치의 요소에 정확하게 접근하거나 슬라이싱하는 것이 가능합니다.
반복 (Iteration): 순서가 유지되므로 for 루프 등을 사용하여 자료구조의 모든 요소를 정의된 순서대로 순회할 수 있습니다.
인덱싱(index)
특정 위치에 있는 하나의 데이터 요소에 접근하기 위해 사용하는 방법입니다.
쉽게 말해, 자료구조에 저장된 데이터 요소들에게 순서대로 번호(인덱스)를 매겨놓고, 그 번호를 이용해서 원하는 데이터를 찾아내는 것입니다.
주요 특징:
번호 할당: 자료구조의 첫 번째 요소부터 0, 1, 2, 3... 과 같이 정수 번호가 순서대로 할당됩니다. (대부분의 프로그래밍 언어에서 0부터 시작합니다.)
접근 방식: 자료구조 이름 뒤에 대괄호 []를 사용하고 그 안에 접근하려는 요소의 인덱스 번호를 넣어 접근합니다. 예: 자료구조이름[인덱스번호]
단일 요소 접근: 인덱싱은 한 번에 하나의 특정 위치에 있는 요소만을 반환하거나 접근합니다.
음수 인덱스: 파이썬과 같은 일부 언어에서는 음수 인덱스를 지원합니다. -1은 마지막 요소, -2는 뒤에서 두 번째 요소 등을 가리킵니다.

인덱싱이 사용되는 자료구조:
리스트 (List): 요소 접근 및 수정 가능
튜플 (Tuple): 요소 접근만 가능 (불변)
문자열 (String): 요소 접근만 가능 (불변)
(일부 언어의) 배열 (Array) 등 순서가 보장되는 자료구조
주의:
세트(Set)나 딕셔너리(Dictionary)와 같이 순서가 보장되지 않는 자료구조에는 인덱스를 통한 직접적인 요소 접근 방식(인덱싱)이 적용되지 않습니다. 딕셔너리는 키(Key)를 통해 값(Value)에 접근합니다.
존재하지 않는 인덱스에 접근하려고 하면 오류(IndexError 등)가 발생합니다.
인덱싱은 시퀀스 자료구조의 가장 기본적인 접근 방법이며, 특정 위치의 데이터를 읽거나 수정(가변 자료구조인 경우)할 때 필수적으로 사용됩니다.
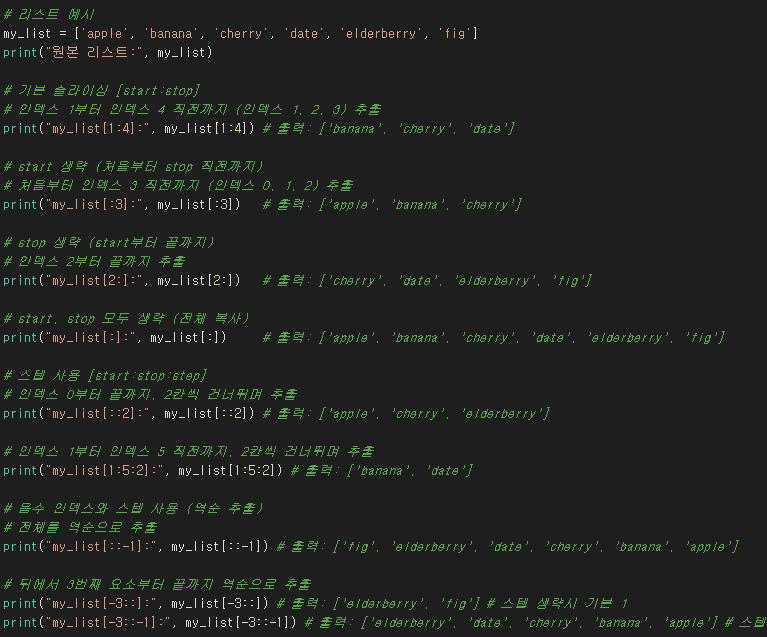
슬라이싱(Slicing)
여러 개의 연속된 데이터 요소들을 부분적으로 추출하여 새로운 시퀀스를 만드는 방법입니다.
앞서 설명한 인덱싱이 특정 위치의 '하나의' 요소에 접근하는 것이라면, 슬라이싱은 '여러 개의' 요소를 범위로 지정하여 가져오는 것입니다.
주요 특징:
범위 지정: 시작 인덱스, 끝 인덱스, 그리고 선택적으로 스텝(간격)을 지정하여 추출할 요소들의 범위를 설정합니다.
문법: 자료구조_이름[start:stop:step] 형태로 사용합니다.
start: 슬라이싱을 시작할 인덱스 (포함). 생략 시 처음부터 시작합니다.
stop: 슬라이싱을 끝낼 인덱스 (미포함). 즉, stop 인덱스 바로 전까지 추출합니다. 생략 시 끝까지 추출합니다.
step: 요소를 건너뛰는 간격 (기본값은 1). 생략 시 1씩 증가하며 추출합니다. 음수 스텝을 사용하면 역순으로 추출할 수 있습니다.
새로운 시퀀스 반환: 슬라이싱 결과는 원본 자료구조의 일부분을 포함하는 새로운 시퀀스 객체로 반환됩니다. 원본 자료구조는 변경되지 않습니다.
적용 대상: 리스트(List), 튜플(Tuple), 문자열(String) 등 순서가 있는 시퀀스 자료구조에 적용됩니다.

리스트의 일반적인 연산 및 메소드:
생성: [] 또는 list()를 사용하여 빈 리스트나 초기값을 가진 리스트를 생성합니다. 예: my_list = [1, 'hello', 3.14]
요소 접근: 인덱싱 my_list[index] 또는 슬라이싱 my_list[start:stop:step]을 사용합니다.
요소 수정: 인덱싱을 사용하여 특정 위치의 요소를 변경합니다. 예: my_list[0] = 100
요소 추가:
append(item): 리스트의 맨 뒤에 요소를 추가합니다.
insert(index, item): 특정 인덱스 위치에 요소를 삽입합니다.
extend(iterable): 다른 시퀀스(리스트, 튜플 등)의 모든 요소를 리스트의 맨 뒤에 추가합니다.
요소 삭제:
remove(value): 리스트에서 첫 번째로 나타나는 특정 값을 가진 요소를 삭제합니다.
pop(index): 특정 인덱스의 요소를 삭제하고 그 요소를 반환합니다 (인덱스를 생략하면 맨 마지막 요소를 삭제하고 반환합니다).
del my_list[index] 또는 del my_list[start:stop]: 특정 인덱스 또는 슬라이스 범위의 요소를 삭제합니다.
요소 검색:
index(value): 특정 값이 처음 나타나는 인덱스를 반환합니다.
count(value): 특정 값이 리스트에 몇 개 있는지 개수를 반환합니다.
value in my_list: 특정 값이 리스트에 있는지 여부를 확인합니다 (True/False).
정렬:
sort(): 리스트를 제자리에서(in-place) 정렬합니다.
sorted(my_list): 리스트의 정렬된 새로운 복사본을 반환합니다 (원본은 변경되지 않음).
뒤집기: reverse(): 리스트의 요소 순서를 제자리에서 뒤집습니다.
길이 확인: len(my_list): 리스트에 포함된 요소의 개수를 반환합니다.
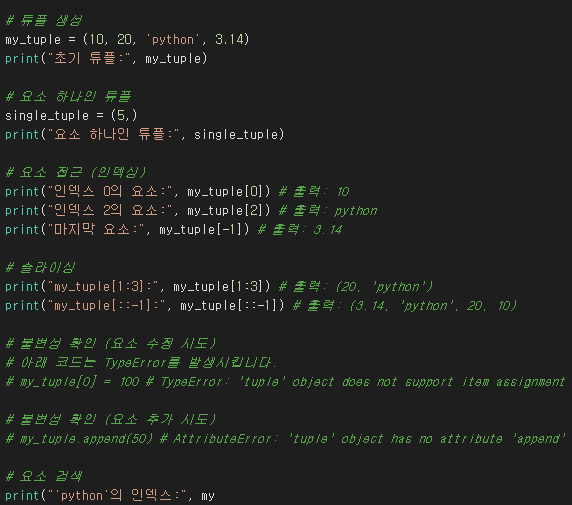
튜플의 연산 사용 방법:
생성: () 또는 tuple()을 사용하여 빈 튜플이나 초기값을 가진 튜플을 생성합니다. 요소가 하나인 튜플을 만들 때는 반드시 요소 뒤에 쉼표(,)를 붙여야 합니다.
빈 튜플: my_tuple = ()
값 있는 튜플: my_tuple = (1, 'hello', 3.14)
요소 하나인 튜플: single_item_tuple = (5,) (쉼표 필수!)
요소 접근: 인덱싱 my_tuple[index] 또는 슬라이싱 my_tuple[start:stop:step]을 사용합니다. (리스트와 동일)
요소 수정/추가/삭제: 불가능합니다. 시도하면 TypeError가 발생합니다. 튜플은 append(), insert(), remove(), pop(), sort(), reverse()와 같은 요소를 변경하는 메소드를 제공하지 않습니다.
요소 검색:
index(value): 특정 값이 처음 나타나는 인덱스를 반환합니다.
count(value): 특정 값이 튜플에 몇 개 있는지 개수를 반환합니다.
value in my_tuple: 특정 값이 튜플 안에 있는지 여부를 확인합니다 (True/False).
연결 (Concatenation): + 연산자를 사용하여 두 튜플을 연결할 수 있습니다. 이때 새로운 튜플이 생성됩니다. 원본 튜플은 변경되지 않습니다. 예: new_tuple = tuple1 + tuple2
반복 (Repetition): 연산자로 튜플을 반복할 수 있습니다. 이때 새로운 튜플이 생성됩니다. 예: repeated_tuple = my_tuple 3
길이 확인: len(my_tuple): 튜플에 포함된 요소의 개수를 반환합니다
데이터베이스 정규화 (Database Normalization)
목적: 데이터베이스의 구조를 체계적으로 분석하고 개선하여 데이터 중복을 최소화하고, 데이터의 일관성과 무결성을 높이며, 이상 현상(Anomaly)이 발생하는 것을 방지하는 과정입니다.
Min-Max 정규화 (Min-Max Scaling): 데이터를 0과 1 사이의 범위로 스케일링합니다. X_scaled = (X - X_min) / (X_max - X_min)
표준화 (Standardization): 데이터의 평균을 0, 표준편차를 1로 만들도록 스케일링합니다. 이는 엄밀히 말해 '정규화'와는 다르지만, 데이터 스케일링 과정에서 함께 다루어집니다. X_scaled = (X - mean) / standard_deviation
이 외에도 Robust Scaling, Max Abs Scaling 등 다양한 방법이 있습니다.
프로세스 (Process):
운영체제로부터 자원(메모리 공간, 파일 핸들 등)을 할당받아 실행되는 독립적인 프로그램 단위입니다.
각 프로세스는 자신만의 독립적인 메모리 공간을 가집니다. 다른 프로세스의 메모리 공간에 직접 접근할 수 없습니다.
프로세스 생성에는 비교적 많은 시간과 자원(오버헤드)이 소모됩니다.
하나의 프로세스가 비정상 종료되더라도 다른 프로세스에게 영향을 주지 않습니다 (격리성이 높습니다).
스레드 (Thread):
하나의 프로세스 내에서 실행되는 실행 단위입니다.
스레드는 자신이 속한 프로세스의 메모리 공간과 자원을 공유합니다. 코드, 데이터, 힙 영역 등을 공유하며, 스택 영역만 스레드별로 독립적입니다.
스레드 생성 및 컨텍스트 스위칭(실행 중인 스레드를 바꾸는 작업)은 프로세스에 비해 훨씬 가볍고 빠릅니다.
하나의 스레드에 문제가 발생하면 같은 프로세스 내의 다른 스레드들에게도 영향을 미쳐 프로세스 전체가 종료될 수 있습니다 (격리성이 낮습니다).
멀티프로세싱 (Multiprocessing)
정의: 여러 개의 독립적인 프로세스를 동시에 실행하는 방식입니다.
특징:
각 프로세스는 독립적인 메모리 공간을 가지므로 데이터 공유를 위해 별도의 프로세스 간 통신(IPC, Inter-Process Communication) 메커니즘(예: 파이프, 큐, 공유 메모리)이 필요하며, 이는 복잡할 수 있습니다.
CPU 바운드(CPU-bound) 작업에 유리합니다. CPU 연산이 많은 작업의 경우, 여러 코어에서 각각의 프로세스가 병렬로 실행되어 성능 향상을 기대할 수 있습니다. (특히 Python에서는 GIL의 영향을 받지 않아 진정한 병렬 처리가 가능합니다.)
프로세스 생성 및 관리에 오버헤드가 있습니다.
하나의 프로세스 오류가 다른 프로세스에 영향을 주지 않아 안정성이 높습니다.
멀티스레딩 (Multithreading)
정의: 하나의 프로세스 내에서 여러 개의 스레드를 동시에 실행하는 방식입니다.
특징:
스레드들은 동일한 메모리 공간과 자원을 공유하므로 데이터 공유가 용이합니다. 하지만 여러 스레드가 동시에 같은 데이터에 접근할 때 동기화(Synchronization) 문제가 발생할 수 있어 락(Lock), 세마포어(Semaphore) 등의 메커니즘으로 제어해야 합니다.
I/O 바운드(I/O-bound) 작업에 유리합니다. 네트워크 통신, 파일 읽기/쓰기 등 외부 장치와의 상호작용으로 인해 스레드가 대기하는 시간이 많은 작업의 경우, 대기하는 동안 다른 스레드가 작업을 수행하여 효율성을 높일 수 있습니다.
스레드 생성 및 컨텍스트 스위칭이 가벼워 오버헤드가 적습니다.
하나의 스레드 오류가 전체 프로세스에 영향을 줄 수 있어 안정성이 상대적으로 낮습니다
이상치(Outlier)
다른 데이터 포인트와 비교했을 때 극단적으로 차이가 나는 값을 가진 데이터 포인트를 의미합니다. 이러한 이상치는 데이터 수집 오류, 측정 오류, 데이터 입력 오류 등으로 인해 발생할 수도 있지만, 때로는 데이터에 포함된 자연스러운 변동성이나 아주 드문(극단적인) 사건을 나타낼 수도 있습니다.
이상치는 데이터 분석 결과나 머신러닝 모델의 성능에 부정적인 영향을 미칠 수 있습니다.
통계 분석 왜곡: 평균, 표준편차 등 기술 통계량에 큰 영향을 주어 데이터의 전반적인 특성을 잘못 이해하게 만들 수 있습니다.
모델 성능 저하:
선형 회귀나 로지스틱 회귀와 같이 이상치에 민감한 모델의 경우, 모델의 학습 결과(예: 계수 값)가 이상치에 의해 크게 왜곡될 수 있습니다.
K-평균 클러스터링이나 K-NN과 같은 거리 기반 알고리즘은 이상치 때문에 군집 중심이나 이웃 정의가 잘못될 수 있습니다.
모델 수렴 방해: 일부 모델의 최적화 과정(예: 경사 하강법)에서 이상치가 수렴을 방해하거나 속도를 늦출 수 있습니다.
이상치 처리 과정:
이상치 처리는 일반적으로 다음과 같은 단계로 이루어집니다.
이상치 탐지 (Outlier Detection): 데이터에서 이상치로 의심되는 값을 식별합니다.
이상치 분석 (Outlier Analysis): 탐지된 이상치가 왜 발생했는지 원인을 파악합니다. (오류인지, 실제 극단값인지)
이상치 처리 (Outlier Treatment): 이상치의 원인과 분석 목적에 따라 적절한 방법으로 이상치를 처리합니다.
이상치 탐지 방법:
시각화 (Visualization):
박스 플롯 (Box Plot): 데이터의 사분위수, 중앙값, 최소/최대값 등을 보여주며, 사분위수 범위(IQR)를 벗어나는 이상치를 시각적으로 쉽게 확인할 수 있습니다.
산점도 (Scatter Plot): 두 변수 간의 관계를 보여줄 때, 다른 데이터 포인트들과 멀리 떨어진 점을 이상치로 의심할 수 있습니다.
히스토그램 (Histogram) / 밀도 플롯 (Density Plot): 데이터 분포의 꼬리 부분에 극단적인 값이 있는지 확인할 수 있습니다.
통계적 방법 (Statistical Methods):
Z-점수 (Z-score): 데이터 포인트가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 나타냅니다. 일반적으로 Z-점수가 특정 임계값(예: 2, 3)을 넘으면 이상치로 간주합니다. (데이터가 정규 분포를 따른다고 가정할 때 유용)
IQR (Interquartile Range): 데이터의 1사분위수(Q1)와 3사분위수(Q3) 사이의 범위(Q3 - Q1)를 사용합니다. 보통 Q1 - 1.5 IQR 보다 작거나 Q3 + 1.5 IQR 보다 큰 값을 이상치로 간주합니다.
레이블 인코딩 (Label Encoding)
레이블 인코딩은 범주형 데이터(Categorical Data)를 수치형 데이터(Numerical Data)로 변환하는 가장 기본적인 방법 중 하나입니다. 머신러닝 알고리즘은 대부분 수치형 데이터만을 처리할 수 있기 때문에, 텍스트 형태의 범주형 데이터를 모델 학습에 사용하기 위해서는 반드시 숫자로 변환하는 과정이 필요합니다.
머신러닝 모델이 범주형 데이터를 이해하고 학습할 수 있도록 변환합니다.
레이블 인코딩 과정
범주형 특성(Feature) 선택: 변환하고자 하는 범주형 데이터 컬럼(또는 특성)을 선택합니다.
고유한 범주 식별: 해당 컬럼에 있는 모든 고유한(Unique) 범주 값들을 찾습니다.
숫자 할당: 각 고유한 범주에 0부터 시작하는 정수 레이블을 순서대로 할당합니다.
값 대체: 원래 컬럼의 각 범주 값을 해당 정수 레이블로 대체합니다.
예시:
'색상'이라는 범주형 특성이 있고, 데이터에 다음과 같은 값들이 포함되어 있다고 가정해 보겠습니다.
['빨강', '파랑', '초록', '빨강', '파랑']
레이블 인코딩 과정은 다음과 같습니다.
범주형 특성: '색상' 컬럼을 선택합니다.
고유한 범주 식별: 고유한 범주는 '빨강', '파랑', '초록' 입니다.
숫자 할당:
'빨강' -> 0
'파랑' -> 1
'초록' -> 2 (할당되는 숫자의 순서는 고유한 범주를 추출하는 순서에 따라 달라질 수 있습니다. 예를 들어, 알파벳/가나다 순으로 정렬 후 할당될 수도 있습니다.)
값 대체: 원래 값들을 할당된 숫자로 대체합니다. ['빨강', '파랑', '초록', '빨강', '파랑'] -> [0, 1, 2, 0, 1]
이제 '색상' 컬럼은 [0, 1, 2, 0, 1] 이라는 수치형 데이터로 변환되었습니다.
Python에서의 구현 (Scikit-learn 사용):
파이썬에서는 sklearn.preprocessing 모듈의 LabelEncoder 클래스를 사용하여 쉽게 레이블 인코딩을 수행할 수 있습니다.

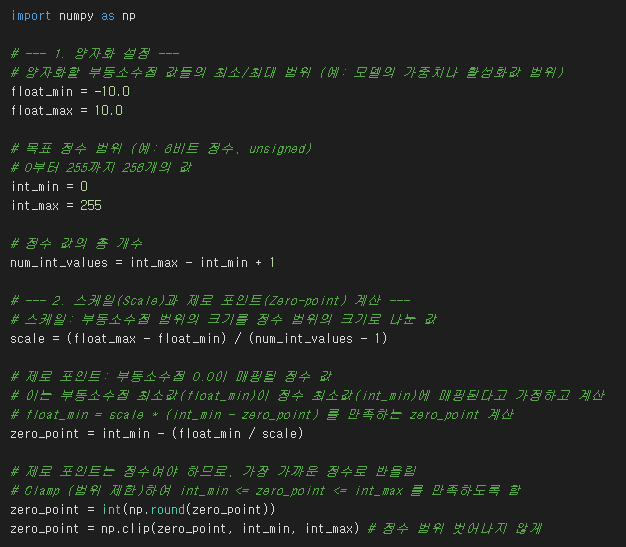
양자화의 기본 개념:
양자화는 신경망 모델의 가중치(Weights)와 활성화값(Activations) 등에서 사용되는 수(Number)의 정밀도를 낮추는 과정을 의미합니다. 일반적으로 모델 학습 시에는 32비트 부동소수점(FP32) 형태로 계산이 이루어지지만, 양자화를 통해 이를 16비트 부동소수점(FP16)이나 8비트 정수(INT8), 심지어 4비트 정수 등으로 변환합니다.
모델 크기 감소 (Reduced Model Size): 32비트 부동소수점을 8비트 정수로 바꾸면 모델 크기가 약 1/4로 줄어듭니다. 이는 저장 공간을 절약하고 모델 로딩 시간을 단축시킵니다. 특히 모바일 장치나 IoT 기기 같은 제한된 환경에 모델을 배포할 때 매우 중요합니다.
추론 속도 향상 (Faster Inference): 낮은 정밀도의 숫자를 사용하면 계산량이 줄어들고, 일부 하드웨어(예: INT8 연산을 지원하는 CPU, GPU, NPU 등)에서는 저정밀도 연산을 더 빠르게 처리할 수 있습니다. 따라서 모델의 예측(Inference) 속도가 빨라집니다.
전력 소비 감소 (Lower Power Consumption): 계산량이 줄어들고 효율적인 하드웨어 연산을 사용하면 모델 실행 시 필요한 전력이 감소합니다. 이는 배터리로 동작하는 엣지 디바이스에서 중요한 장점입니다.
양자화의 과정 및 종류:
양자화는 크게 두 가지 방식으로 나눌 수 있습니다.
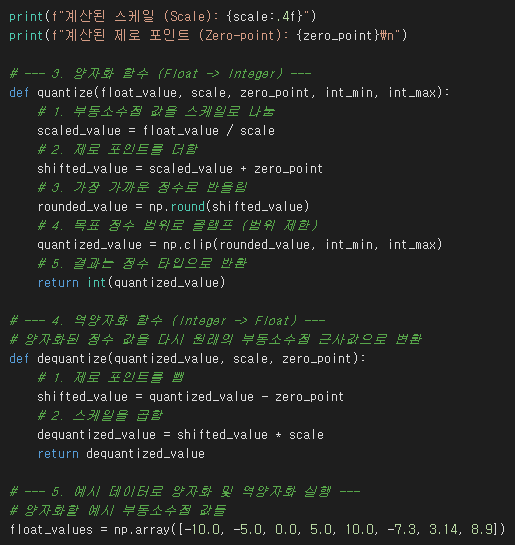
학습 후 양자화 (Post-Training Quantization, PTQ):
방법: 이미 FP32로 학습이 완료된 모델을 가져와서, 추가 학습 없이 가중치와 활성화값을 저정밀도(예: INT8)로 변환합니다.
장점: 구현이 간단하고 빠릅니다. 학습 데이터나 추가적인 학습 과정이 필요 없습니다 (경우에 따라 보정(Calibration)을 위해 소량의 데이터가 필요할 수 있습니다).
단점: 정밀도를 낮추는 과정에서 모델의 정확도 손실이 발생할 수 있습니다. 특히 복잡하거나 민감한 모델의 경우 정확도 하락이 클 수 있습니다.
양자화 인지 학습 (Quantization Aware Training, QAT):
방법: 모델 학습 과정에 양자화 연산을 시뮬레이션하는 '가짜 양자화(Fake Quantization)' 노드를 삽입하여, 모델이 처음부터 저정밀도 환경에 적응하도록 학습시킵니다. 학습은 여전히 FP32로 진행되지만, 가중치 업데이트 시 양자화 효과를 고려합니다.
장점: 학습 과정에서 양자화로 인한 정확도 손실을 최소화하도록 모델이 스스로 조정하기 때문에, PTQ보다 높은 정확도를 유지할 수 있습니다.
단점: PTQ보다 구현이 복잡하고, 학습 데이터가 필요하며, 학습 시간이 더 오래 걸릴 수 있습니다.
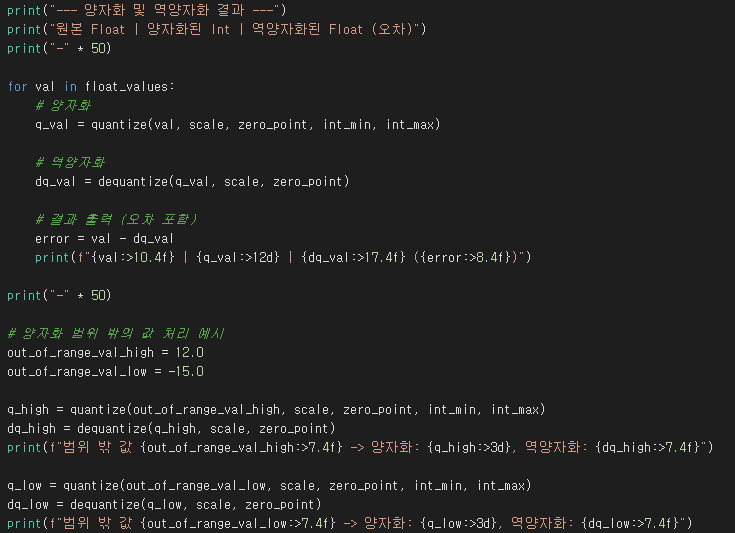
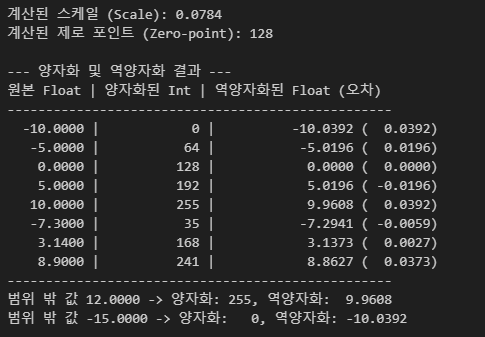
8비트 정수 양자화(INT8)를 가정하고, 특정 부동소수점 범위의 데이터를 0부터 255 사이의 정수로 변환하는 과정