
이 글의 목적?
Fork/Join은 부끄럽지만 공부하면서 처음 접해본 내용이다. 워낙 생소한 개념이라 정리해보고자 한다.
Fork/Join 이란?
책에서의 말을 요약하자면 이렇다.
Java 7에 추가된 클래스 중에는 Fork/Join과 관련된 클래스가 존재한다. Fork/Join은 어떤 계산 작업을 할 때 "여러 개로 나누어 계산한 후 결과를 모으는 작업"을 의미한다.
내가 참고한 블로그에서는 다음과 같이 설명했다.
Fork/Join은 효율적인 병렬처리를 위해 Java 7에서 등장한 새로운 기능이다. 자바에서만 사용하는 용어는 아니고 병렬 처리를 위한 공통된 모델이며 분할 정복 알고르짐을 통해 재귀적으로 처리된다.
예를 들어, 100개의 랜덤한 숫자가 있고 이를 합산하는 것을 Fork/Join으로 처리한다면 하단의 이미지처럼 처리된다.
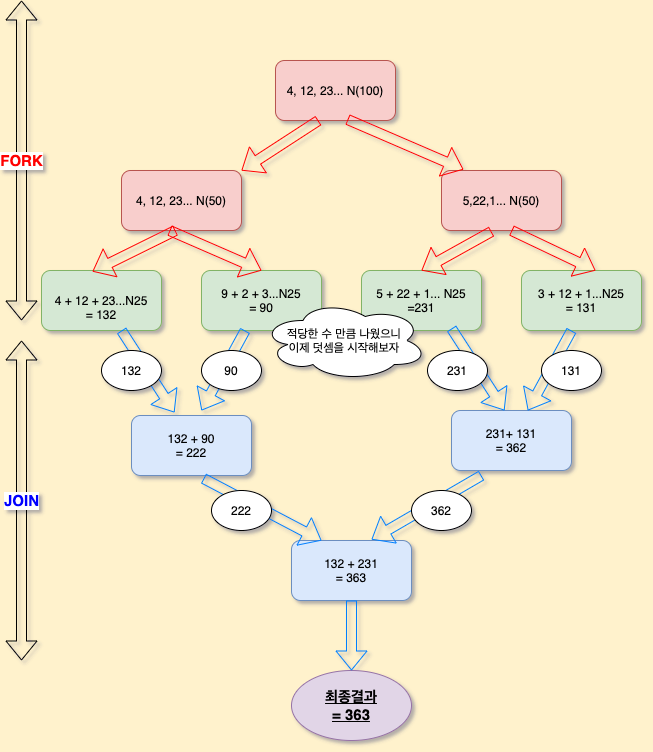
Fork/Join은 별도로 구현하지 않아도 라이브러리에서 Work Stealing 작업을 알아서 수행한다. 따라서 CPU가 많이 있는 장비에서 계산 위주의 작업을 매우 빠르게 해야할 필요가 있을 때 유용하게 사용된다.
if(작업의 단위가 충분히 작을 경우) {
해당 작업을 수행
}
else {
작업을 반으로 쪼개어 두 개의 작업으로 나눔
두 작업을 동시에 실행시키고, 두 작업이 끝날 때 까지 결과를 기다림
}Work Stealing
Fork/Join에서는 Work Stealing이라는 개념이 포함되어있다. Work Stealing은 양쪽 끝에서 넣고 뺄 수 있는 구조인 Dequeue와 관련이 있는 개념이다.
여러 개의 Dequeue에서 일이 진행될 때, 하나의 Dequeue는 바쁘고 다른 Dequeue에서는 여유롭다고 한다면 여유가 있는 Dequeue가 바쁜 Dequeue의 일을 가져가서 해준다.
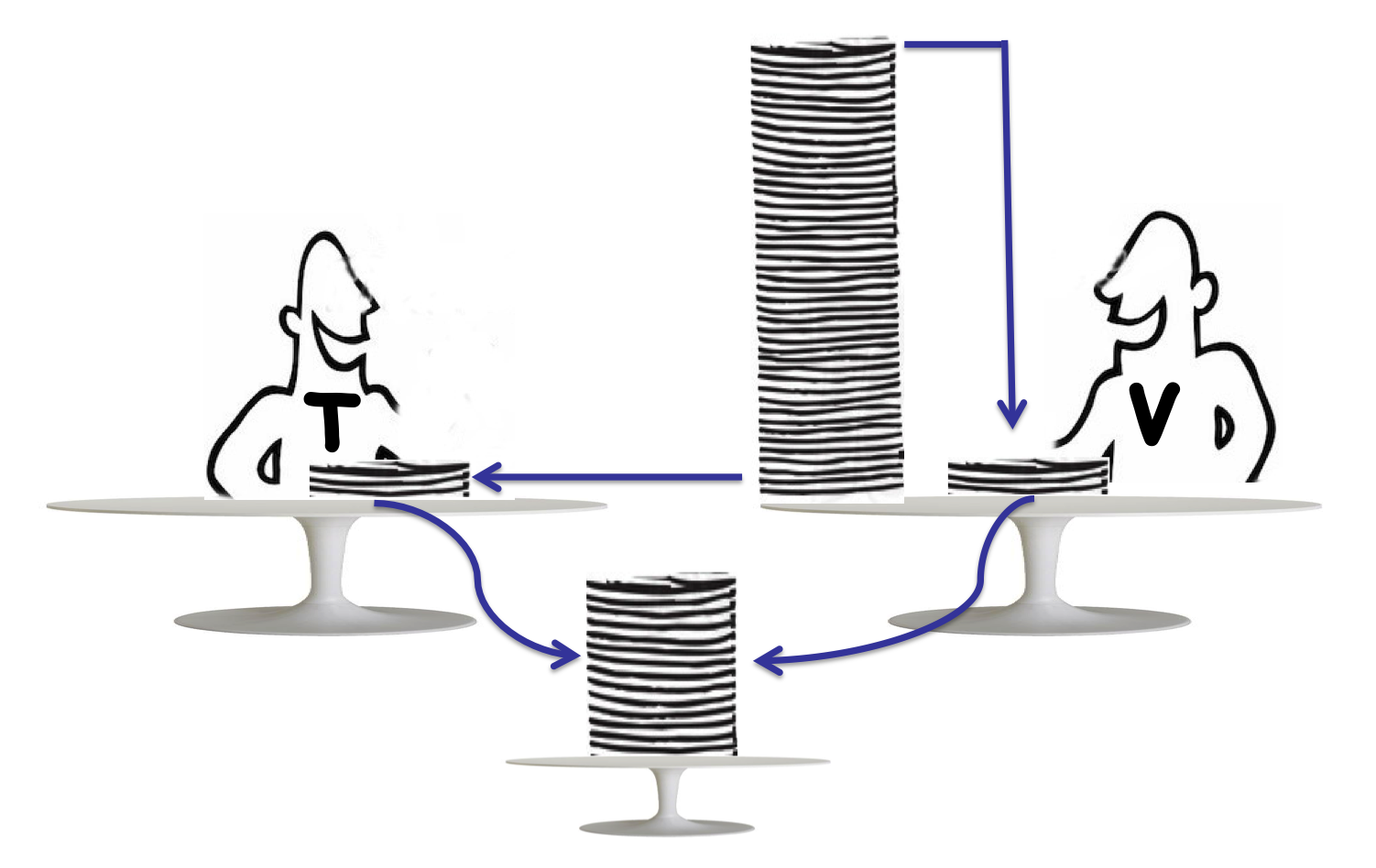
RecursiveAction vs RecursiveTask
Fork/Join 기능을 사용하려면 RecursiveAction 혹은 RecursiveTask를 이용해야한다. 이 두 클래스의 차이는 다음과 같다.
| 구분 | RecursiveAction | RecursiveTask |
|---|---|---|
| Generic | O | X |
| 결과 반환 | O | X |
두 클래스의 확장 관계를 살펴보자.
java.lang.Object
java.util.concurrent.ForkJoinTask<Void>
java.util.concurrent.RecursiveAction
implemented Serializable, Future<Void>
java.lang.Object
java.util.concurrent.ForkJoinTask<V>
java.util.concurrent.RecursiveTask<V>
implemented Serializable, Future<Void>두 클래스 모두 ForkJoinTask라는 추상 클래스를 확장했고 Future 인터페이스를 구현했다. Future 인터페이스는 비동기적인 요청을 하고 응답을 기다릴 때 사용된다.
그럼 이 클래스들에서 Fork/Join 연산을 수행하는 메소드는 뭘까?
재귀호출이 되고 연산을 수행하는 메소드는 바로 compute() 메소드에서 이루어진다. 어떻게 사용하는지는 생략하자. Fork/Join 작업을 수행하려면 RecursiveAction 혹은 RecursiveTask를 확장해서 개발하면 된다 정도로 이해하고 넘어가면 될 것 같다.
예시
책에서의 Fork/Join 예시가 이해하기 굉장히 쉬워서 정리해본다.
from에서 to까지의 합을 구한다고 하면 일반적으로 for문으로 구현한다. for문으로 구현할 경우에는 하나의 스레드로 수행하기에 1개의 CPU만 사용하게 된다.
long total = 0;
for(int loop = from; loop <= to; loop++) {
total += loop;
}위 코드를 Fork/Join으로 구현해보자.
public clas GetSum extends RecursiveTask<Long> {
long from, to;
public GetSum(long from, long to) {
this.from = from;
this.to = to;
}
public Long compute() {
long gap = to - from;
// 작업 단위가 작을 경우
if(gap <= 3) {
long result = 0;
for(int loop = from; loop <= to; loop++) {
result += loop;
}
return result;
}
// 작업 단위가 클 경우
// 두 개의 작업으로 나누어 동시에 실행시키고, 두 작업이 끝날 때 까지 결과를 기다림
long middle = (from + to) / 2;
GetSum prev = new GetSum(from, middle);
prev.fork();
GetSum post = new GetSum(middle + 1, to);
return post.compute() + prev.join();
}
}이를 실행하는 코드도 작성해보자.
public class ForkJoinSample {
static final ForkJoinPool mainPool = new ForkJoinPool();
public static void main(String[] args) {
long from = 0;
long to = 10;
GetSum sum = new GetSum(from, to);
// 계산을 수행하는 객체를 넘겨주어 작업을 실행하고 결과를 받음
Long result = mainPool.invoke(sum);
System.out.println("total:" + result);
}
}이 코드에서 각 연산에 대한 내용에 로그(Thread.currentThread().getName())를 달아보면, 직접 스레드 객체를 만들지 않고 스레드에 작업을 할당하지 않았음에도 연산이 이루어지는 것을 확인할 수 있다. (스레드의 수는 CPU 개수만큼 증가함)
결국, JVM에서 알아서 처리해주기 때문에 우리는 결과가 제대로 나오는지만 신경을 쓰면 된다.
꼭 알아야할까?
Fork/Join을 서비스에서 직접 사용하는 경우는 극히 드믈다. 하지만 내부적으로 Fork/Join으로 구현되어있는 클래스들이 많기 때문에 알아두는게 좋다.
이 글의 레퍼런스
