
이 글의 목적?
앞의 정리한 포스팅 글을 작성하기 이전에는 String 자료형에 대해서도, 부동소수점에 대해서도 자세히 알지도 않고 그 동안 이용해왔었다. 마찬가지로 나는 자바를 이용하면서 hashCode() 메소드를 본 적이 있었고, 이 부분에 대해서 한번도 깊게 생각해본 적이 없었다. 오늘 한번 이 내용을 정리해보고자 한다.
보안 관점에서 살펴보자
이전에 보안 교육을 받았을 때, 해시는 암호화 기법이라는 정도로만 가볍게 공부하고 넘어간 적이 있었다. 우선 보안적인 부분에서 접근해보자.
해시는 단방향 암호화 기법으로 해시 함수를 이용하여 고정된 길이의 암호화된 문자열로 바꿔버리는 것을 의미한다. (단방향 암호화 기법은 암호화는 수행하지만 복호화가 불가능한 알고리즘을 의미한다.)
그럼 해시 함수는 뭘까? 해시 함수는 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수다. 이 때 매칭 전 원래 데이터를 키로, 매핑 후 데이터의 값을 해시 값, 매핑하는 과정을 해싱이라고 한다.
SHA256 Hash Generator 사이트에서도 입력값에 따라 쉽게 해시 값을 만들 수 있다. 해시 알고리즘은 종류가 다양하고 해시 길이가 모두 다르지만 모두에게 공개되어있기 때문에 보안적으로 안전하지않다.
(실제로 MD5, SHA-1, HAS-180 해시 함수는 보안이 뚫렸다고 한다! 😡)
왜 안전하지 않은가?
우선 해시 알고리즘은 입력값에 대해 항상 같은 해시 값을 반환한다. 그리고 입력값은 길이 제한이 없기에 무한정으로 만들 수 있으나, 해시 값은 항상 고정된 길이의 값으로 나타내기에 한계가 존재한다. 즉, 고정된 길이의 값으로 표현하기 때문에 다른 입력값이지만 같은 해시 값이 나오는 경우가 있다.
이 특징으로 인해 해커는 무차별적으로 값을 입력하면서 해시 값을 구할 수 있어 안전하지 않다. 대표적인 공격으로는 해시 함수를 이용하여 만들어낼 수 있는 값들을 많이 저장한 표를 이용한 🌈 레인보우 어택이 있다고 한다.
그럼 어떻게 안전해질 수 있을까?
해결 방법으로는 특정 값을 넣고 해시 함수를 여러 번 수행하는 방법이 있다. 임의의 특정 값(문자열)을 솔트라 하고, 해시 함수를 여러 번 수행하는 것을 키 스트레칭이라고 한다. 이 방법을 이용하면 정말 운이 없는 경우가 아닌 이상 거의 피해를 입지 않을 것이라 한다.
본래 해시 함수는 암호화를 위한 용도가 아니라 검색을 위한 목적으로 만들어졌다고 한다. 10만번을 반복해도 1초도 걸리지 않을 정도로 빠르기 때문에, 해커들은 고성능의 컴퓨터를 이용하여 1초에 몇억번 이상을 대입해 뚫는다고 한다. 따라서 앞서 말한 방법으로 솔트를 넣고 함수를 여러 번 수행시켜 강제적으로 1회 대입에 걸리는 시간을 높이는 방법을 사용해야한다고 한다.
개발 관점에서 살펴보자
보안적으로 좋지 않다는 것을 이해했다면, 개발 관점에서 왜 중요하고, 왜 알아야하는지를 살펴보자.
알아보기 전에 내가 참고한 레퍼런스로 해시에 대해서 다시 정리해보자.
해시 테이블
해시 테이블은 기본적으로 key-value 형태로 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조다. 해시 테이블이 빠른 검색 속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다.
해시 테이블은 각각의 키 값에 해시 함수를 적용해 배열의 고유한 인덱스를 생성하고, 이 인덱스를 이용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 혹은 슬롯이라고 한다.
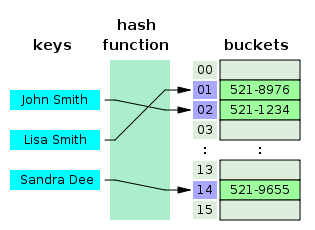
출처: https://mangkyu.tistory.com/102
이미지에서의 ("John Smith", "521-1234") 데이터를 크기가 16인 해시 테이블에 저장한다고 했을 때 일어나는 연산은 다음과 같다.
index = hash_function("John Smith") % 16연산을 통해 인덱스 값을 계산array[index] = "521-1234"를 저장
이 구조로 데이터를 저장할 경우에는 키 값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되기에 매우 빠르게 데이터를 저장/삭제/조회할 수 있다. 즉, 해시 테이블은 O(1)의 시간복잡도를 가지게 된다.
해시 함수
해시 함수는 인덱스 값을 생성하는데 사용된다. 해시 테이블에 사용되는 해시 함수로는 대표적으로 Division Method, Digit Folding, Multiplication Method, Universal Hasing이 있다.
해시 값 충돌
위에서 언급했지만 해시 값이 충돌(중복)되는 경우가 있다. Object 코드를 열어 hashCode() 메소드를 확인해보면 int를 반환하는데, int의 범위를 넘어가면서 충돌이 일어날 수 있다는 것을 예측할 수 있다. (따라서 가변의 길이를 고정된 길이로 변경하는데 손실이 일어나기 때문에 역으로 복호화할 수 없다는 것도 기억해두자! 😜)
해시 테이블에서는 충돌에 의한 문제를 분리 연결법과 개방 주소법으로 해결하고 있다.
분리 연결법
분리 연결법은 동일한 버킷의 데이터에 대해 자료구조를 활용해 추가 메모리를 사용하여 데이터의 주소를 저장하는 방법이다. 하단의 이미지에서의 "John Smith"와 "Sandra Dee"처럼 동일한 버킷으로 접근을 한다면 데이터들을 연결해서 관리해주고 있다.
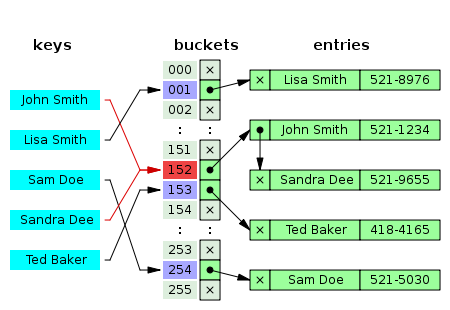
출처: https://mangkyu.tistory.com/102
Java 8의 해시 테이블은 Self-Balancing Binary Search Tree 자료구조를 사용해 체이닝 방식을 구현한다고 한다. 이러한 체이닝 방식은 해시 테이블의 확장이 필요없고 간단하게 구현이 가능하여 손쉽게 삭제할 수 있다는 장점을 가지고 있다. 하지만 데이터의 수가 많아지면 동일한 버킷에 체이닝되는 데이터가 많아지고 그에 따라 캐시의 효율성이 감소한다는 단점이 있다.
개방 주소법
개방 주소법은 추가적인 메모리를 사용하는 체이닝 방식과는 다르게 비어있는 해시 테이블의 공간을 활용하는 방법이다. 개방 주소법을 구현하는 방법으로는 Linear Probing, Quadratic Probing, Double Hasing Probing이 있다.
해시 테이블의 공간을 활용하는 방법이기에 데이터를 삭제하면 삭제된 공간은 Dummy Space로 활용되기 때문에 해시 테이블을 재정리해주는 작업이 필요하다고 한다.
해시 테이블의 시간 복잡도
해시 테이블은 평균적으로 O(1) 의 시간복잡도로 데이터를 조회할 수 있다. 하지만 데이터의 충돌(중복)이 일어날 경우 체이닝에 연결된 리스트들까지 검색해야하기 때문에 O(n) 까지 시간 복잡도가 증가할 수 있다.
충돌을 방지하는 방법들은 데이터의 규칙성을 방지하기 위한 방식이지만 공간을 많이 사용한다는 단점이 있다. 만약 테이블이 가득 차있는 경우라면 테이블을 확장해주어야 하는데, 이는 매우 심각한 성능 저하를 불러오기 때문에 가능하면 확장을 하지 않도록 테이블을 설계해주어야 한다. 내가 참고한 레퍼런스에서는 해시 테이블의 공간 사용률이 70% - 80% 정도가 되면 해시의 충돌이 빈번하게 발생하여 성능이 저하되기 시작한다고 한다.
(추가로 해시 테이블에서 자주 사용하는 데이터를 캐시에 적용하면 효율을 높일 수 있다고 한다. 🥴)
해시 코드
우리는 이미 해시 코드가 무엇인지 알고있다. 해시 코드는 계속 말해왔던 해시 함수의 결과로 나온 해시 값이다. 전문적으로 표현한다면, 자바에서의 객체 해시 코드는 객체를 식별할 하나의 정수 값을 의미한다. 그렇다면 왜 중요할까? 🤔
이유는 equals() 메소드를 재정의한 클래스에서는 hashCode() 메소드도 재정의를 해주어야 하기 때문이다. 직접 코드를 작성해서 차이를 확인해보자.
둘 다 오버라이딩 안함
// HashTest.class
public class HashTest {
private int num;
public HashTest(int num) {
this.num = num;
}
}// Main.class
public class Main {
public static void main(String[] args) {
HashTest hash1 = new HashTest(1);
HashTest hash2 = new HashTest(1);
// 주소값
System.out.println(hash1); // HashTest@3f0ee7cb
System.out.println(hash2); // HashTest@75bd9247
// hashCode()
System.out.println(hash1.hashCode()); // 1057941451
System.out.println(hash2.hashCode()); // 1975358023
// equals()
System.out.println(hash1.equals(hash2)); // false
// HashSet
HashSet<HashTest> hashSet = new HashSet<>();
hashSet.add(hash1);
hashSet.add(hash2);
System.out.println(hashSet); // [HashTest@3f0ee7cb, HashTest@75bd9247]
}
}equals()만 오버라이딩
// HashTest.class
public class HashTest {
private int num;
public HashTest(int num) {
this.num = num;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
HashTest hashTest = (HashTest) o;
return num == hashTest.num;
}
}// Main.class
public class Main {
public static void main(String[] args) {
HashTest hash1 = new HashTest(1);
HashTest hash2 = new HashTest(1);
// 주소값
System.out.println(hash1); // HashTest@3f0ee7cb
System.out.println(hash2); // HashTest@75bd9247
// hashCode()
System.out.println(hash1.hashCode()); // 1057941451
System.out.println(hash2.hashCode()); // 1975358023
// equals()
System.out.println(hash1.equals(hash2)); // true
// HashSet
HashSet<HashTest> hashSet = new HashSet<>();
hashSet.add(hash1);
hashSet.add(hash2);
System.out.println(hashSet); // [HashTest@3f0ee7cb, HashTest@75bd9247]
}
}hashCode()만 오버라이딩
// HashTest.class
public class HashTest {
private int num;
public HashTest(int num) {
this.num = num;
}
@Override
public int hashCode() {
return Objects.hash(num);
}
}// Main.class
public class Main {
public static void main(String[] args) {
HashTest hash1 = new HashTest(1);
HashTest hash2 = new HashTest(1);
// 주소값
System.out.println(hash1); // HashTest@20
System.out.println(hash2); // HashTest@20
// hashCode()
System.out.println(hash1.hashCode()); // 32
System.out.println(hash2.hashCode()); // 32
// equals()
System.out.println(hash1.equals(hash2)); // false
// HashSet
HashSet<HashTest> hashSet = new HashSet<>();
hashSet.add(hash1);
hashSet.add(hash2);
System.out.println(hashSet); // [HashTest@20, HashTest@20]
}
}둘 다 오버라이딩
// HashTest.class
public class HashTest {
private int num;
public HashTest(int num) {
this.num = num;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
HashTest hashTest = (HashTest) o;
return num == hashTest.num;
}
@Override
public int hashCode() {
return Objects.hash(num);
}
}// Main.class
public class Main {
public static void main(String[] args) {
HashTest hash1 = new HashTest(1);
HashTest hash2 = new HashTest(1);
// 주소값
System.out.println(hash1); // HashTest@20
System.out.println(hash2); // HashTest@20
// hashCode()
System.out.println(hash1.hashCode()); // 32
System.out.println(hash2.hashCode()); // 32
// equals()
System.out.println(hash1.equals(hash2)); // true
// HashSet
HashSet<HashTest> hashSet = new HashSet<>();
hashSet.add(hash1);
hashSet.add(hash2);
System.out.println(hashSet); // [HashTest@20]
}
}코드의 결과를 살펴보자
각각 하나만 오버라이딩한 경우만 살펴보자.
- equals()만 오버라이딩: 서로 다른 객체인데 같다고 인식
- hashCode()만 오버라이딩: 서로 동일한 객체인데 다르다고 인식어라? 이상하다. 분명 서로 다른 객체임에도 불구하고 같다고 인식하는 것과 동일한 객체인데도 다르다고 인식하는 것이... 🤨
왜 이런 결과가 나올까?
equals() 메소드와 hashCode() 메소드는 같이 오버라이딩해주어야 한다. 만약 hashCode()를 재정의하지 않으면 같은 값 객체임에도 해시값이 달라 해시 테이블에서 해당 객체가 저장된 버킷을 찾을 수 없게 된다.
반대로 equals()를 재정의하지 않는다면, hashCode()가 만든 해시값을 이용해 객체가 저장된 버킷을 찾을 수는 있지만 해당 객체가 자신과 같은 객체인지 값을 비교할 수 없기 때문에 null을 반환하게 된다.
따라서 객체의 정확한 동등 비교를 위해 모두 재정의할 필요가 있다. (특히 HashSet, HashMap, HashTable과 같은 컬렉션 프레임워크에서는 필수)
참고한 레퍼런스에서 본 두 메소드간의 관계를 보자.
- 자바 프로그램을 실행하는 동안 equals()에 사용된 정보가 수정되지 않았다면, hashCode()의 반환값은 항상 동일한 정수값을 반환해야 한다. 단, 프로그램을 실행할 때마다 달라지는 것은 상관이 없다.
- 두 객체가 equals()에 의해 동일하다면, 두 객체의 hashCode()의 반환값도 일치해야한다.
- 두 객체가 equals()에 의해 동일하지 않다면, 두 객체의 hashCode()의 반환값도 일치하지 않아도 된다.HashTable vs HashMap
HashTable과 HashMap의 자료구조는 공통적으로 key-value 형태로 데이터를 저장한다는 점이다. 하지만 두 자료구조는 동기화 지원 여부에서 차이가 존재한다.
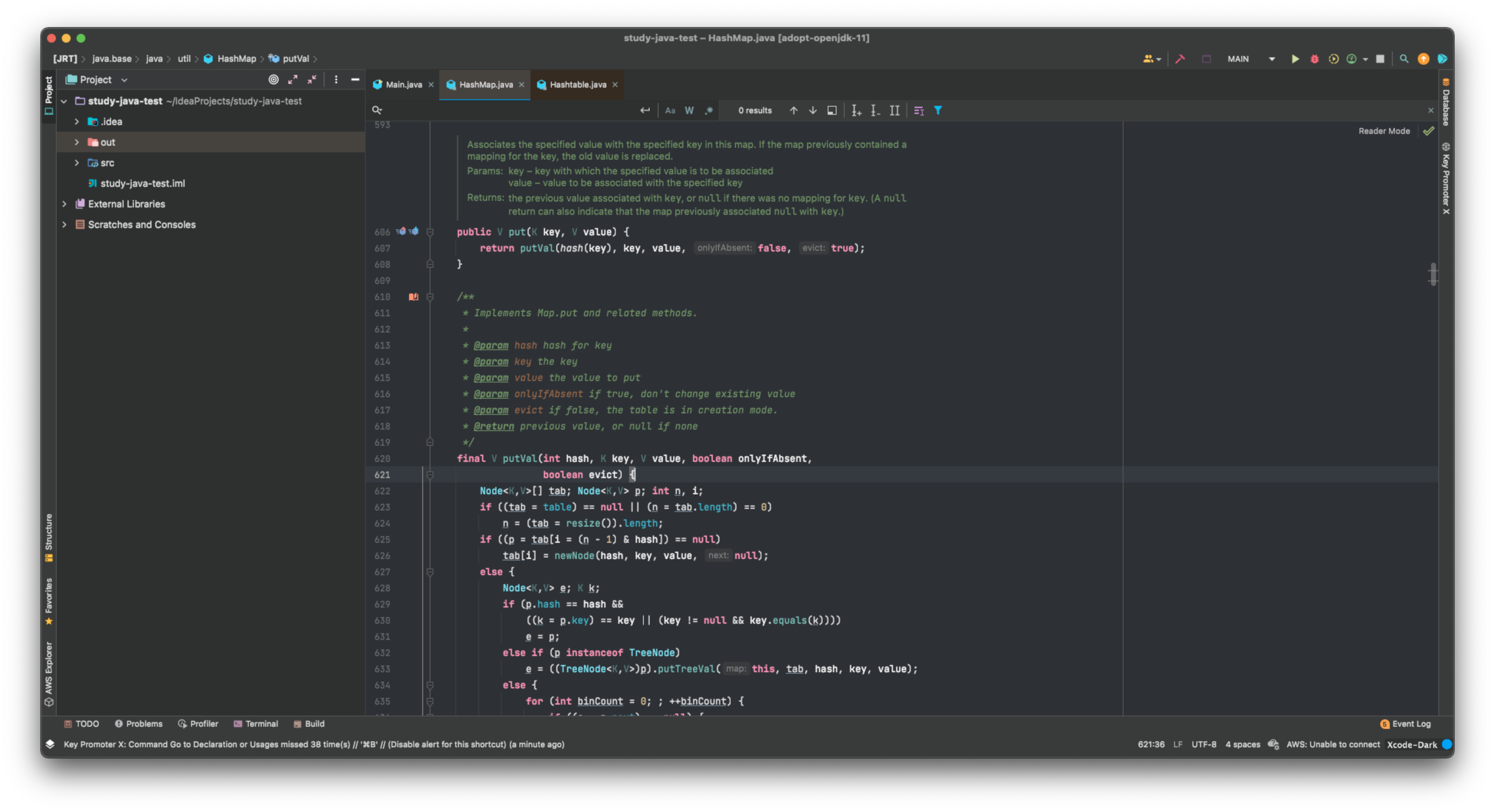
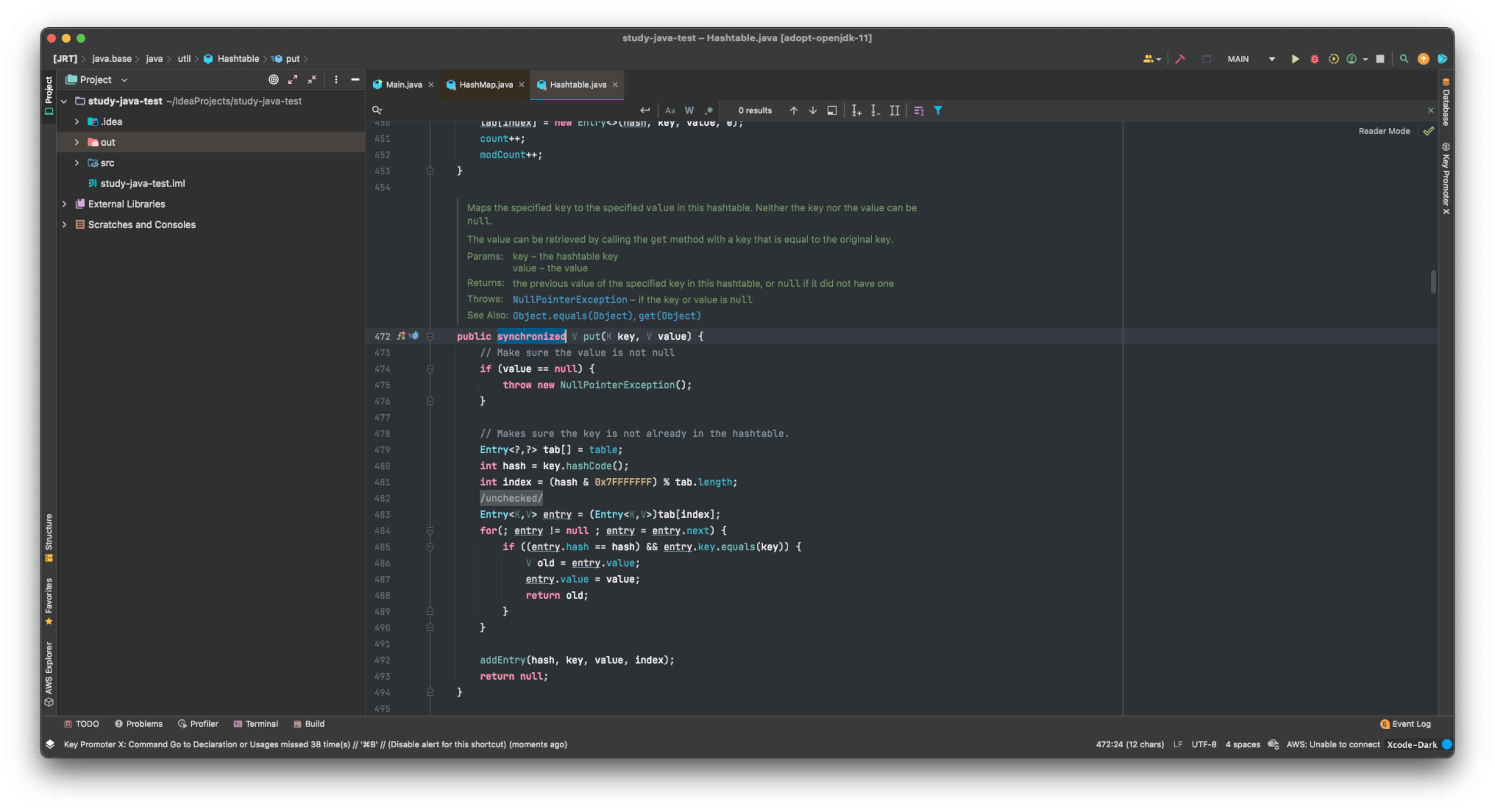
실제로 코드를 열어보면 HashTable에는 syncronized 예약어가 붙어있는 반면 HashMap에는 안붙어있는 것을 볼 수 있다.
이 글의 레퍼런스
- https://mangkyu.tistory.com/101
- https://mangkyu.tistory.com/102
- https://bangu4.tistory.com/179
- https://www.youtube.com/watch?v=xls6jEZNA7Y&t=30s (추천! ⭐️)
- https://jisooo.tistory.com/entry/java-hashcode%EC%99%80-equals-%EB%A9%94%EC%84%9C%EB%93%9C%EB%8A%94-%EC%96%B8%EC%A0%9C-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B3%A0-%EC%99%9C-%EC%82%AC%EC%9A%A9%ED%95%A0%EA%B9%8C
