
이 글의 목적?
최근 나는 String을 선언하는 2가지 방법중 하나만을 고집해서 사용하고 있음을 깨닫고 String을 사용하면서 과연 내가 제대로 알고 사용하는지에 대해 고민하게 되었다. 그래서 오늘String에 대해 정리해보고자 한다.
String 선언 방식
자바에서 String은 참조 자료형이다. String 객체는 자바에 내장된 클래스로 new 예약어로 새로운 객체를 생성할 수 있고, ""를 이용해 선언할 수 있다.
String str1 = new String("hello");
String str2 = "world";
String str3 = new String(byte[] bytes);
String str4 = new String(byte[] bytes, int offset, int length);String의 두 가지 선언 방식은 String 객체를 생성한다는 부분에서 동일하지만 JVM이 관리하는 메모리 구조상에서는 다르게 동작한다.
비효율적인 String 객체 생성
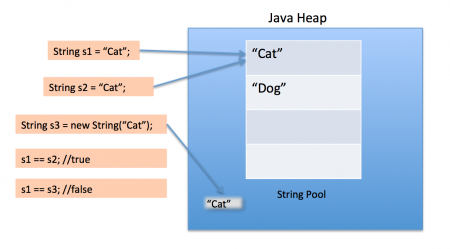
출처: https://marrrang.tistory.com/53
String은 참조 자료형이다. 따라서 new 예약어로 인스턴스를 생성한 뒤, 힙에서 메모리 관리가 이루어진다. 하지만 다른 참조형과는 다르게 변하지 않는다는 특징을 가지고 있다.
한 번 저장된 String 객체의 값은 변하지 않는다. 따라서 상단의 이미지에서 s3 = s3 + s3;를 수행하면 String 객체를 새로 생성하고 s3는 새로운 인스턴스를 참조하게 된다.
String Pool
결과적으로는 String 객체들의 연산이 이루어지면 새로운 객체를 만들기 때문에 메모리 관리 측면에서 상당히 비효율적이게 된다. 이러한 비효율적인 방식을 해결하기 위해 만들어진것이 String Pool 이다.
String Pool은 기존에 만들어진 문자열 값이 저장되어 있고, 이미지의 s1, s2 처럼 리터럴로 생성된 같은 값을 가진 객체는 같은 레퍼런스를 가지게 된다.
이해가 되었다면 하단의 코드에서 생성되는 객체의 수는 2개가 되는 것을 알 수 있다.
String str1 = new String("hello");
String str2 = "world";
String str3 = "world";이미지와 예시가 아닌 글로 접근해보자! 👊
String Pool은 HashMap 형태로 되어있으며 리터럴을 사용하여 String 객체를 생성하면 String Pool 내에서 기존의 같은 값을 가지는 객체가 있는지 검사 후 있다면 그 객체의 참조값을 반환하고 없다면 새로운 String 객체를 생성 후 그 참조값을 반환한다. 이러한 과정을 intern 이라고 하며, 리터럴로 생성시 intern() 메서드를 수행함을 알 수 있다.
리터럴 방식으로 생성된 String 객체의 참조값은 모두 String Pool 주소값을 지정하고 있고 값을 찾는 방식은 String Pool로 찾아간 후 String Pool에서 intern 과정을 거쳐 찾는 값과 같은 값을 가진 부분의 주소값을 반환해주는 방식이다.
이 방법은 위에서 언급했듯 new라는 예약어로 객체를 생성하는 비효율적인 방법에 비해, Pool을 이용해 캐싱을 통해 메모리 공간적 측면에서 더 효율적으로 관리할 수 있게 된다.
왜 String 만?
다른 참조 타입들과는 다르게 String 만 특별 대우를 해주는 이유는 앞에서 말했듯이 불변성을 가진 타입이라는 점을 반드시 기억해야한다. 다른 참조 타입들은 객체를 할당하고 이에 대한 값을 변경하면 같은 주소 값의 객체의 실제 값이 변경되지만 String은 그렇지 않다는 것이다.
문자열을 처리한다면?
문자열을 다루는 메소드들과 객체는 정말 많다. 이 메소드들과 객체를 사용하면 어떻게 될지 정리해보자.
1. concat
String a = "hello";
String b = " world";
String c = a.concat(b);
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}concat 내부 메소드를 확인해보면 다음과 같은 순서로 진행된다.
1. 파라미터로 들어온 String 길이를 검사 (otherLen)
2. concat 메소드를 수행하는 String의 길이를 검사 (len)
3. 두 길이를 합한 길이 만큼의 char 형 배열(buf)을 생성하여 String의 값을 삽입
4. 파라미터로 들어온 문자열을 만들어 두었던 buf에 len 만큼 offset 이후에 삽입 (value 이후)
5. 해당 char 배열을 new String()을 통해 String으로 만들어 반환결국 concat는 String 객체를 생성해주는 것을 확인할 수 있다.
2. "+" 연산자
"+" 연산자는 Java 1.5 이전에는 내부적으로 concat 메소드와 동일하게 수행되었고 이후에는 StringBuilder로 변환하여 처리하게 되었다.
String str = "hello" + "world" + "!";3. StringBuilder
StringBuilder는 불변하지 않다는 점에서 큰 차이를 가지고 있다. 따라서 하나의 메모리를 차지하고 그 메모리 내부의 값을 계속 변경해 가면서 진행하기 때문에 시간 및 공간적으로 효율적이다.
StringBuilder sb = new StringBuilder();
sb.append("hello");
sb.append("world");
sb.append("!");4. StringBuffer
StringBuilder와 비슷한 StringBuffer를 사용하는 이유는 Thread Safe 하기 때문이다.
StringBuilder가 메소드 내부에서 선언이 된다면 메소드가 실행될 때 객체가 생성되므로 큰 문제는 없다. 하지만 하단의 코드처럼 클래스 내부의 메소드들이 여러 곳에서 호출되면 StringBuilder로 원하는 결과를 보장할 수 없게 된다.
public class StringClass {
StringBuilder sbuilder = new StringBuilder();
StringBuffer sbuffer = new StringBuffer();
public void sbMethod1(String value) {
sbuilder.append(value);
sbuffer.append(value);
}
public void sbMethod2(String value) {
sbuilder.append(value);
sbuffer.append(value);
}
}왜 원하는 결과를 얻지 못할까? 그 이유는 append 메소드에 synchronized 선언이 되어있지 않기 때문에 발생한다.
public StringBuilder append(String str) {
super.append(str);
return this;
}반면 StringBuffer의 경우 synchronized가 선언되어있어 Thread Safe하게 동작하게 되므로 원하는 결과를 얻어낼 수 있다.
public synchronized StringBuffer append(String str) {
super.append(str);
return this;
}5. split
split 메소드는 정규식 코드로 인해 살짝 복잡하다.
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
int last = length();
list.add(substring(off, last));
off = last;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, length()));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result); 간단하게 살펴보면 다음과 같다.
1. List를 이용하여 String을 잘라낸 것을 각각 저장
2. 자르는 기준에 부합하지 않으면 기존 String을 새로 할당해 반환
3. result라는 String 배열을 생성 후 결과값을 넣어 반환7. equals
==는 주소값이 같은지를 비교한다. equals도 내부적으로 주소값을 비교하지만 String 클래스에서는 equals를 재정의해 내용을 비교하게 되어 문자열을 비교할 때는 == 보다 equals를 사용해야 한다고 한다.
==은 객체를 비교하는 연산자이기 때문에 두 객체가 다르다면 false를 반환하지만, equals는 객체가 다르더라도 문자열 값만 비교하므로 원하는 결과를 얻을 수 있다.
String str1 = "hello";
String str2 = new String("hello");
System.out.println(str1 == str2); // false
System.out.println(str1.equals(str2)); //true그렇다면 왜 주소값이 다를까? 이 이유는 앞에서 설명한 것처럼 new를 이용한 선언과 리터럴을 이용한 선언 방식에 따라 참조하는 주소가 달라지기 때문이다.
String str1 = "hello";
String str2 = "hello";
String str3 = new String("hello");
System.out.println(System.identityHashCode(str1)); // 주소값: 640070680
System.out.println(System.identityHashCode(str2)); // 주소값: 640070680
System.out.println(System.identityHashCode(str3)); // 주소값: 1510467688 동일성(
==)은 두 개의 오브젝트가 완전히 같을 경우를 의미하고, 동등성(equals)은 두 개의 오브젝트가 같은 정보를 가지고 있을 경우를 의미한다.
6. 속도 차이
concat, StringBuilder, StringBuffer의 속도 차이는 하단의 그래프로 확인할 수 있다.
"+" 연산이 StringBuilder와 동일한 연산을 했음에도 차이가 발생하는데, 이는 "+" 연산을 할 때마다 StringBuilder 객체를 생성하기 때문이다.
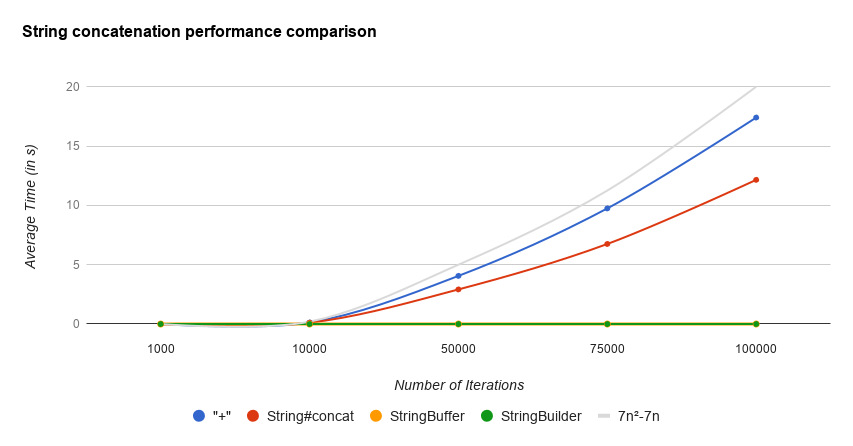
출처: https://marrrang.tistory.com/53
이 글의 레퍼런스
