1. 조건에 맞는 회원수 구하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/131535
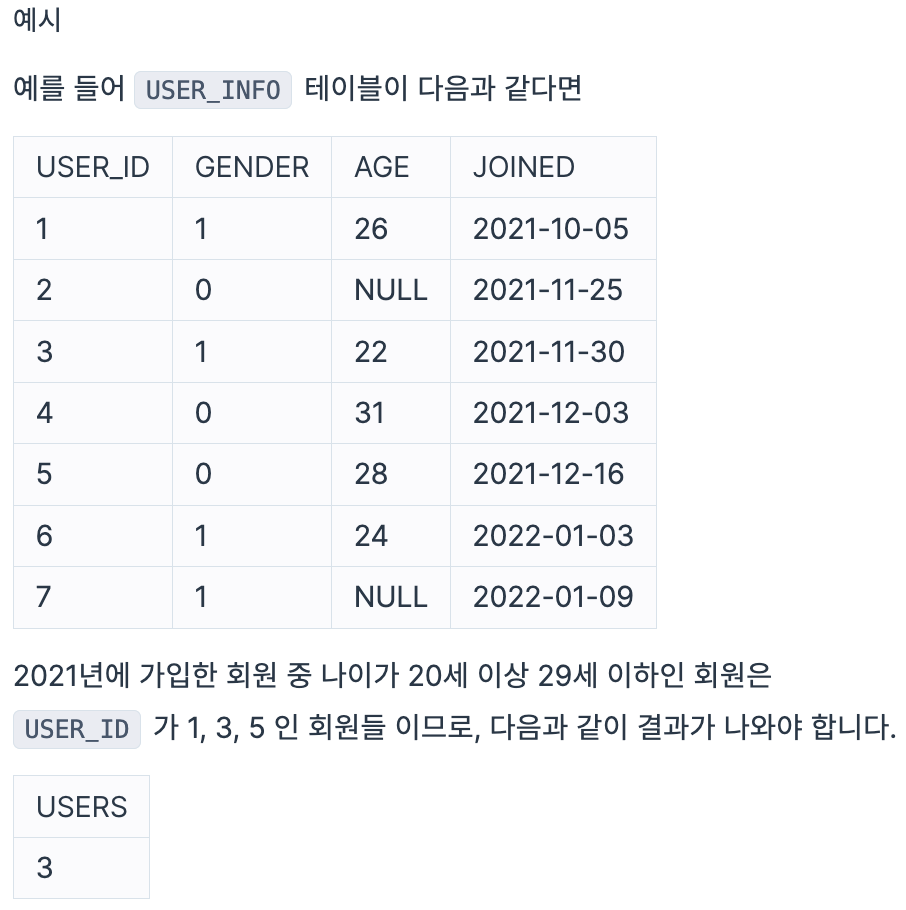
다음은 어느 의류 쇼핑몰에 가입한 회원 정보를 담은 USER_INFO 테이블입니다. USER_INFO 테이블은 아래와 같은 구조로 되어있으며 USER_ID, GENDER, AGE, JOINED는 각각 회원 ID, 성별, 나이, 가입일을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| USER_ID | INTEGER | FALSE |
| GENDER | TINYINT(1) | TRUE |
| AGE | INTEGER | TRUE |
| JOINED | DATE | FALSE |
GENDER 컬럼은 비어있거나 0 또는 1의 값을 가지며 0인 경우 남자를, 1인 경우는 여자를 나타냅니다.
USER_INFO 테이블에서 2021년에 가입한 회원 중 나이가 20세 이상 29세 이하인 회원이 몇 명인지 출력하는 SQL문을 작성해주세요.
구현
SELECT COUNT(USER_ID) AS USERS FROM USER_INFO
WHERE YEAR(JOINED) = 2021 AND AGE >= 20 AND AGE <= 29;2. 업그레이드 된 아이템 구하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/273711
어느 한 게임에서 사용되는 아이템들은 업그레이드가 가능합니다.
'ITEM_A'->'ITEM_B'와 같이 업그레이드가 가능할 때
'ITEM_A'를 'ITEM_B' 의 PARENT 아이템,
PARENT 아이템이 없는 아이템을 ROOT 아이템이라고 합니다.
예를 들어 'ITEM_A'->'ITEM_B'->'ITEM_C'와 같이 업그레이드가 가능한 아이템이 있다면
'ITEM_C'의 PARENT 아이템은 'ITEM_B'
'ITEM_B'의 PARENT 아이템은 'ITEM_A'
ROOT 아이템은 'ITEM_A'가 됩니다.
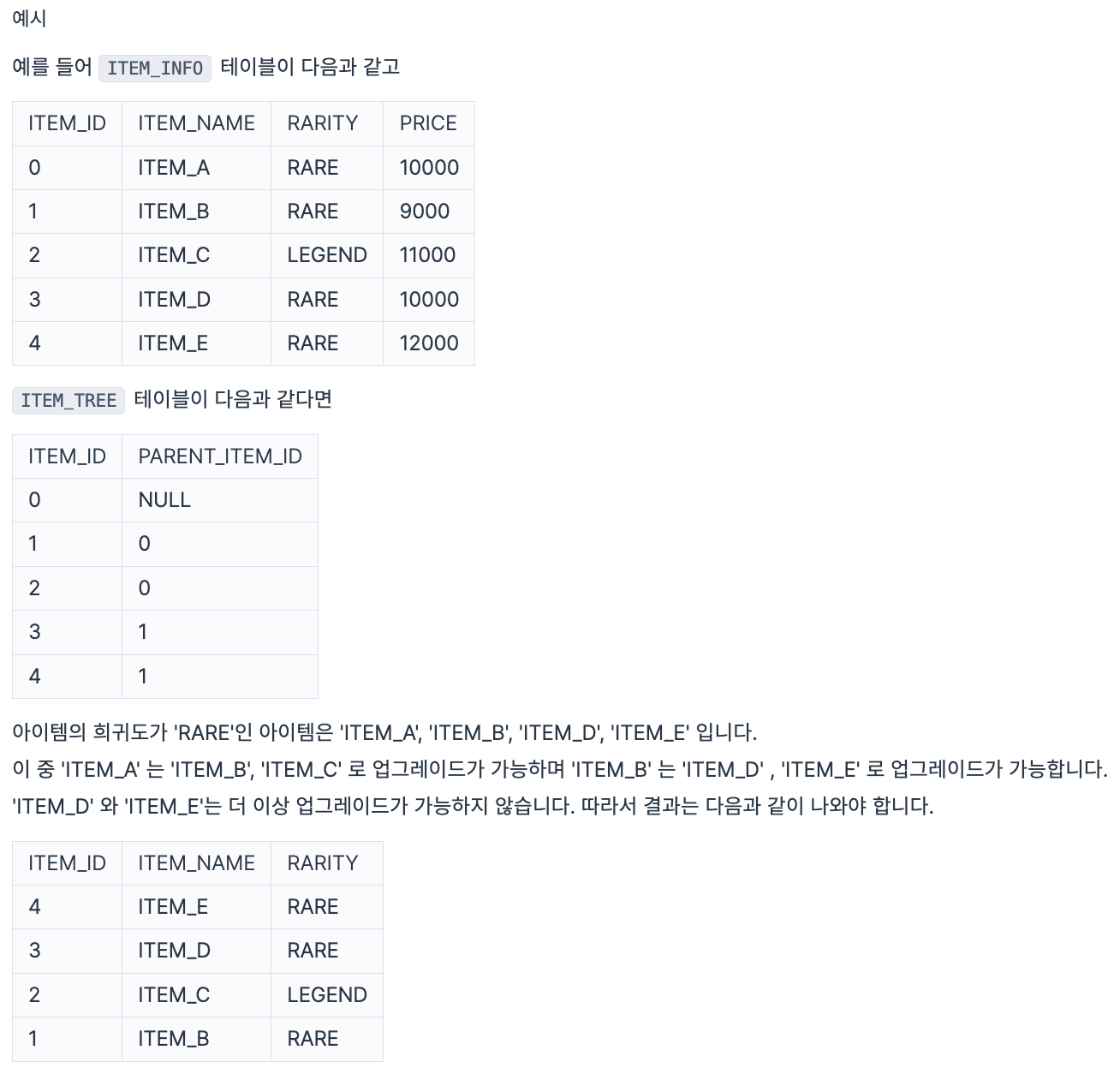
다음은 해당 게임에서 사용되는 아이템 정보를 담은 ITEM_INFO 테이블과 아이템 관계를 나타낸 ITEM_TREE 테이블입니다. ITEM_INFO 테이블은 다음과 같으며, ITEM_ID, ITEM_NAME, RARITY, PRICE는 각각 아이템 ID, 아이템 명, 아이템의 희귀도, 아이템의 가격을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ITEM_ID | INTEGER | FALSE |
| ITEM_NAME | VARCHAR(N) | FALSE |
| RARITY | INTEGER | FALSE |
| PRICE | INTEGER | FALSE |
ITEM_TREE 테이블은 다음과 같으며, ITEM_ID, PARENT_ITEM_ID는 각각 아이템 ID, PARENT 아이템의 ID를 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ITEM_ID | INTEGER | FALSE |
| PARENT_ITEM_ID | INTEGER | TRUE |
단, 각 아이템들은 오직 하나의 PARENT 아이템 ID를 가지며, ROOT 아이템의 PARENT 아이템 ID는 NULL 입니다.
ROOT 아이템이 없는 경우는 존재하지 않습니다.
아이템의 희귀도가 'RARE'인 아이템들의 모든 다음 업그레이드 아이템의 아이템 ID(ITEM_ID), 아이템 명(ITEM_NAME), 아이템의 희귀도(RARITY)를 출력하는 SQL 문을 작성해 주세요. 이때 결과는 아이템 ID를 기준으로 내림차순 정렬주세요.
구현
SELECT II.ITEM_ID, II.ITEM_NAME, II.RARITY FROM ITEM_INFO II
JOIN ITEM_TREE IT ON II.ITEM_ID = IT.ITEM_ID
WHERE IT.PARENT_ITEM_ID IN (
SELECT II.ITEM_ID FROM ITEM_INFO II WHERE II.RARITY = 'RARE'
)
ORDER BY ITEM_ID DESC;다중 조건 지정 (WHERE IN)
1) IN 절에 value 값이 들어가는 경우
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);IN 절에 있는 value 중 어느 하나와 일치하는 레코드들을 조회한다.
예:
SELECT * FROM Customers
WHERE Country IN ('Germany', 'France', 'UK');
# Country의 값이 'Germany' 또는 'France' 또는 'UK'인 데이터들을 조회2) IN 절에 서브 쿼리가 들어가는 경우
SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT STATEMENT);column_name에 지정한 column의 값이 서브 쿼리의 조회 결과 중 어느 하나와 일치하는 레코드들을 조회한다.
예:
SELECT * FROM Customers
WHERE Country IN (SELECT Country FROM Suppliers);
# Customers.Country의 값이 Suppliers.Country에도 존재하는 경우만 조회.NOT IN
SELECT * FROM Customers
WHERE Country NOT IN ('Germany', 'France', 'UK');
# Country의 값이 'Germany'도, 'France'도, 'UK'도 아닌 데이터들을 조회예제 출처: https://www.w3schools.com/mysql/mysql_in.asp
두 테이블을 결합 (JOIN ON)
조만간 별도의 글에 자세하게 다룰 예정이다.
3. Python 개발자 찾기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/276013
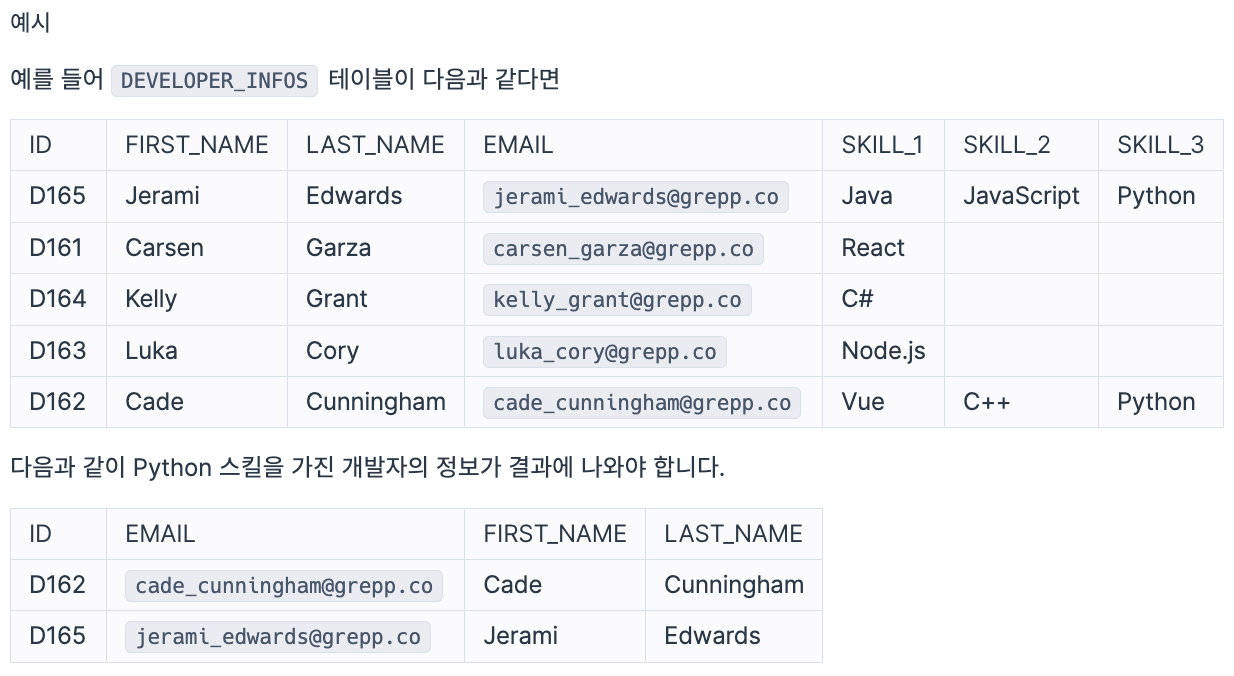
DEVELOPER_INFOS 테이블은 개발자들의 프로그래밍 스킬 정보를 담은 테이블입니다. DEVELOPER_INFOS 테이블 구조는 다음과 같으며, ID, FIRST_NAME, LAST_NAME, EMAIL, SKILL_1, SKILL_2, SKILL_3는 각각 ID, 이름, 성, 이메일, 첫 번째 스킬, 두 번째 스킬, 세 번째 스킬을 의미합니다.
| Column name | Type | Unique | Nullable |
|---|---|---|---|
| ID | VARCHAR(N) | TRUE | FALSE |
| FIRST_NAME | VARCHAR(N) | FALSE | TRUE |
| LAST_NAME | VARCHAR(N) | FALSE | TRUE |
| VARCHAR(N) | TRUE | FALSE | |
| SKILL_1 | VARCHAR(N) | FALSE | TRUE |
| SKILL_2 | VARCHAR(N) | FALSE | TRUE |
| SKILL_3 | VARCHAR(N) | FALSE | TRUE |
DEVELOPER_INFOS 테이블에서 Python 스킬을 가진 개발자의 정보를 조회하려 합니다. Python 스킬을 가진 개발자의 ID, 이메일, 이름, 성을 조회하는 SQL 문을 작성해 주세요.
결과는 ID를 기준으로 오름차순 정렬해 주세요.
구현
SELECT ID, EMAIL, FIRST_NAME, LAST_NAME FROM DEVELOPER_INFOS
WHERE SKILL_1 = 'Python' OR SKILL_2 = 'Python' OR SKILL_3 = 'Python'
ORDER BY ID;4. 조건에 맞는 개발자 찾기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/276034
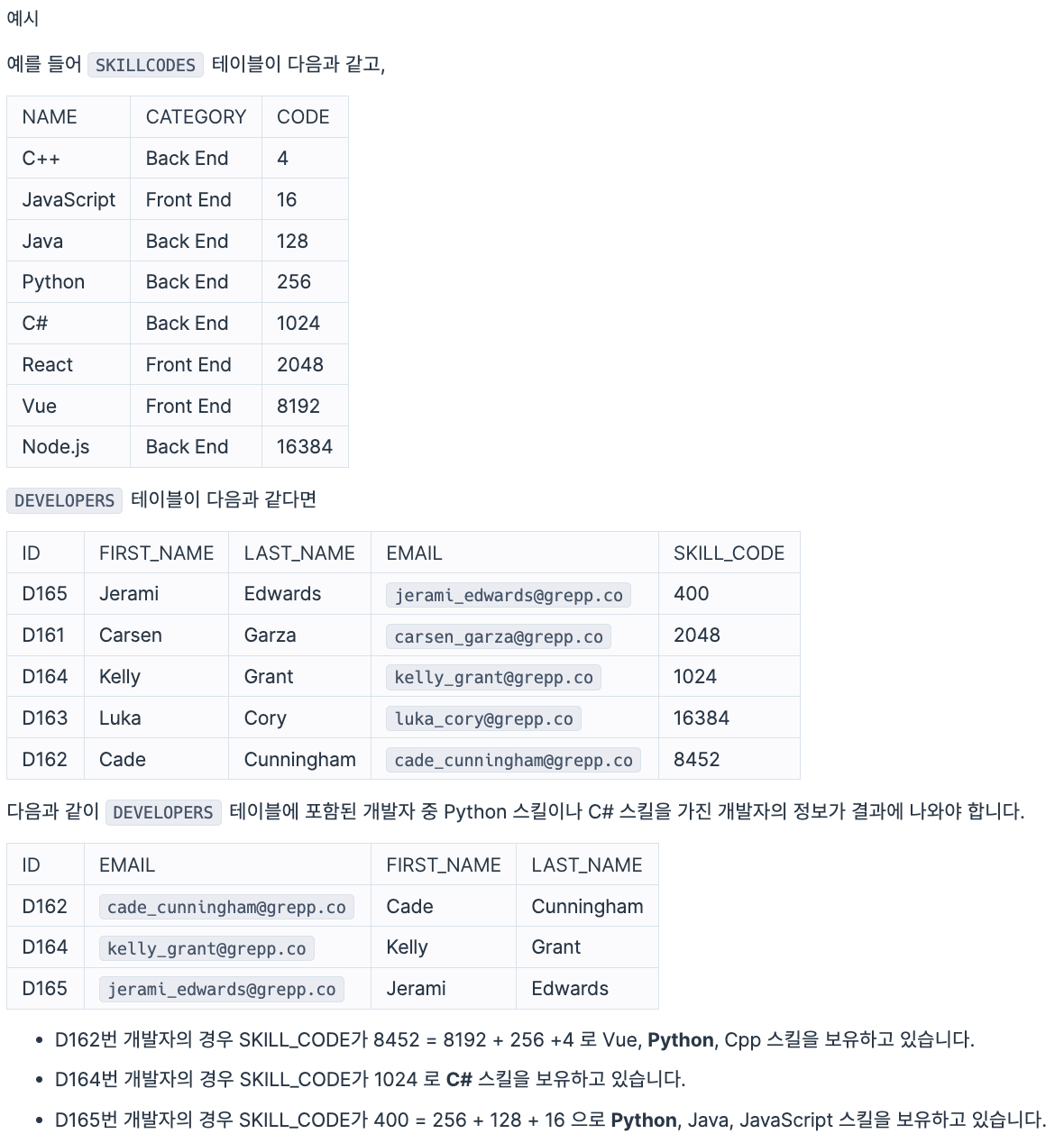
SKILLCODES 테이블은 개발자들이 사용하는 프로그래밍 언어에 대한 정보를 담은 테이블입니다. SKILLCODES 테이블의 구조는 다음과 같으며, NAME, CATEGORY, CODE는 각각 스킬의 이름, 스킬의 범주, 스킬의 코드를 의미합니다. 스킬의 코드는 2진수로 표현했을 때 각 bit로 구분될 수 있도록 2의 제곱수로 구성되어 있습니다.
| Column name | Type | Unique | Nullable |
|---|---|---|---|
| NAME | VARCHAR(N) | TRUE | FALSE |
| CATEGORY | VARCHAR(N) | FALSE | FALSE |
| CODE | INTEGER | TRUE | FALSE |
DEVELOPERS 테이블은 개발자들의 프로그래밍 스킬 정보를 담은 테이블입니다. DEVELOPERS 테이블의 구조는 다음과 같으며, ID, FIRST_NAME, LAST_NAME, EMAIL, SKILL_CODE는 각각 개발자의 ID, 이름, 성, 이메일, 스킬 코드를 의미합니다. SKILL_CODE 컬럼은 INTEGER 타입이고, 2진수로 표현했을 때 각 bit는 SKILLCODES 테이블의 코드를 의미합니다.
| Column name | Type | Unique | Nullable |
|---|---|---|---|
| ID | VARCHAR(N) | TRUE | FALSE |
| FIRST_NAME | VARCHAR(N) | FALSE | TRUE |
| LAST_NAME | VARCHAR(N) | FALSE | TRUE |
| VARCHAR(N) | TRUE | FALSE | |
| SKILL_CODE | INTEGER | FALSE | FALSE |
예를 들어 어떤 개발자의 SKILL_CODE가 400 (=b'110010000')이라면, 이는 SKILLCODES 테이블에서 CODE가 256 (=b'100000000'), 128 (=b'10000000'), 16 (=b'10000') 에 해당하는 스킬을 가졌다는 것을 의미합니다.
DEVELOPERS 테이블에서 Python이나 C# 스킬을 가진 개발자의 정보를 조회하려 합니다. 조건에 맞는 개발자의 ID, 이메일, 이름, 성을 조회하는 SQL 문을 작성해 주세요.
결과는 ID를 기준으로 오름차순 정렬해 주세요.
구현
SELECT ID, EMAIL, FIRST_NAME, LAST_NAME
FROM DEVELOPERS
WHERE SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'Python')
OR SKILL_CODE & (SELECT CODE FROM SKILLCODES WHERE NAME = 'C#')
ORDER BY ID;5. 잔챙이 잡은 수 구하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/293258
낚시앱에서 사용하는 FISH_INFO 테이블은 잡은 물고기들의 정보를 담고 있습니다. FISH_INFO 테이블의 구조는 다음과 같으며 ID, FISH_TYPE, LENGTH, TIME은 각각 잡은 물고기의 ID, 물고기의 종류(숫자), 잡은 물고기의 길이(cm), 물고기를 잡은 날짜를 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| FISH_TYPE | INTEGER | FALSE |
| LENGTH | FLOAT | TRUE |
| TIME | DATE | FALSE |
단, 잡은 물고기의 길이가 10cm 이하일 경우에는 LENGTH 가 NULL 이며, LENGTH 에 NULL 만 있는 경우는 없습니다.
잡은 물고기 중 길이가 10cm 이하인 물고기의 수를 출력하는 SQL 문을 작성해주세요.
물고기의 수를 나타내는 컬럼 명은 FISH_COUNT로 해주세요.
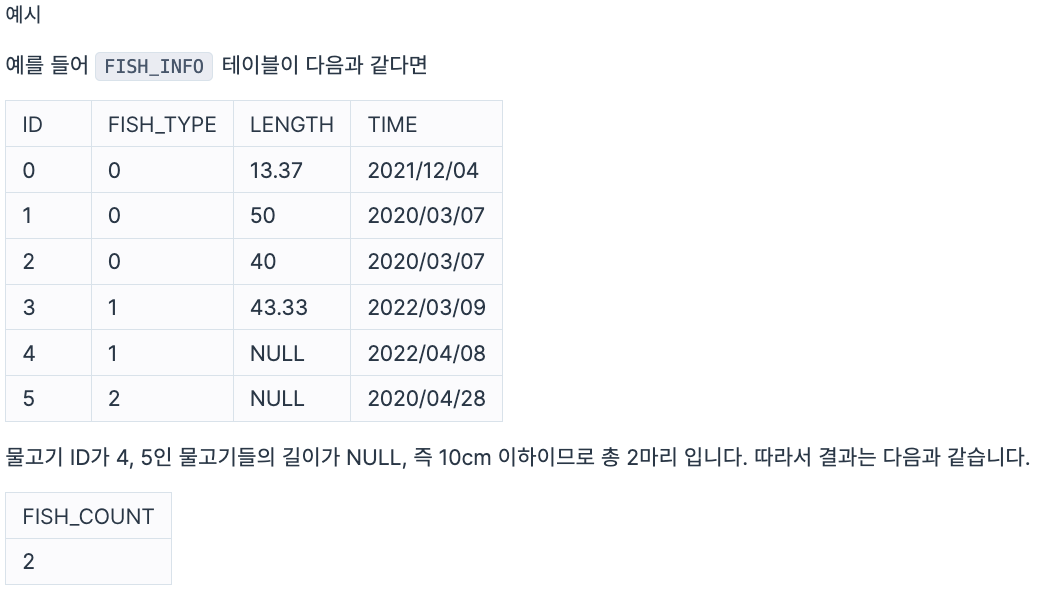
구현
SELECT COUNT(*) AS FISH_COUNT FROM FISH_INFO WHERE LENGTH IS NULL;6. 가장 큰 물고기 10마리 구하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/298517
낚시앱에서 사용하는 FISH_INFO 테이블은 잡은 물고기들의 정보를 담고 있습니다. FISH_INFO 테이블의 구조는 다음과 같으며 ID, FISH_TYPE, LENGTH, TIME은 각각 잡은 물고기의 ID, 물고기의 종류(숫자), 잡은 물고기의 길이(cm), 물고기를 잡은 날짜를 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| FISH_TYPE | INTEGER | FALSE |
| LENGTH | FLOAT | TRUE |
| TIME | DATE | FALSE |
단, 잡은 물고기의 길이가 10cm 이하일 경우에는 LENGTH 가 NULL 이며, LENGTH 에 NULL 만 있는 경우는 없습니다.
FISH_INFO 테이블에서 가장 큰 물고기 10마리의 ID와 길이를 출력하는 SQL 문을 작성해주세요. 결과는 길이를 기준으로 내림차순 정렬하고, 길이가 같다면 물고기의 ID에 대해 오름차순 정렬해주세요. 단, 가장 큰 물고기 10마리 중 길이가 10cm 이하인 경우는 없습니다.
ID 컬럼명은 ID, 길이 컬럼명은 LENGTH로 해주세요.
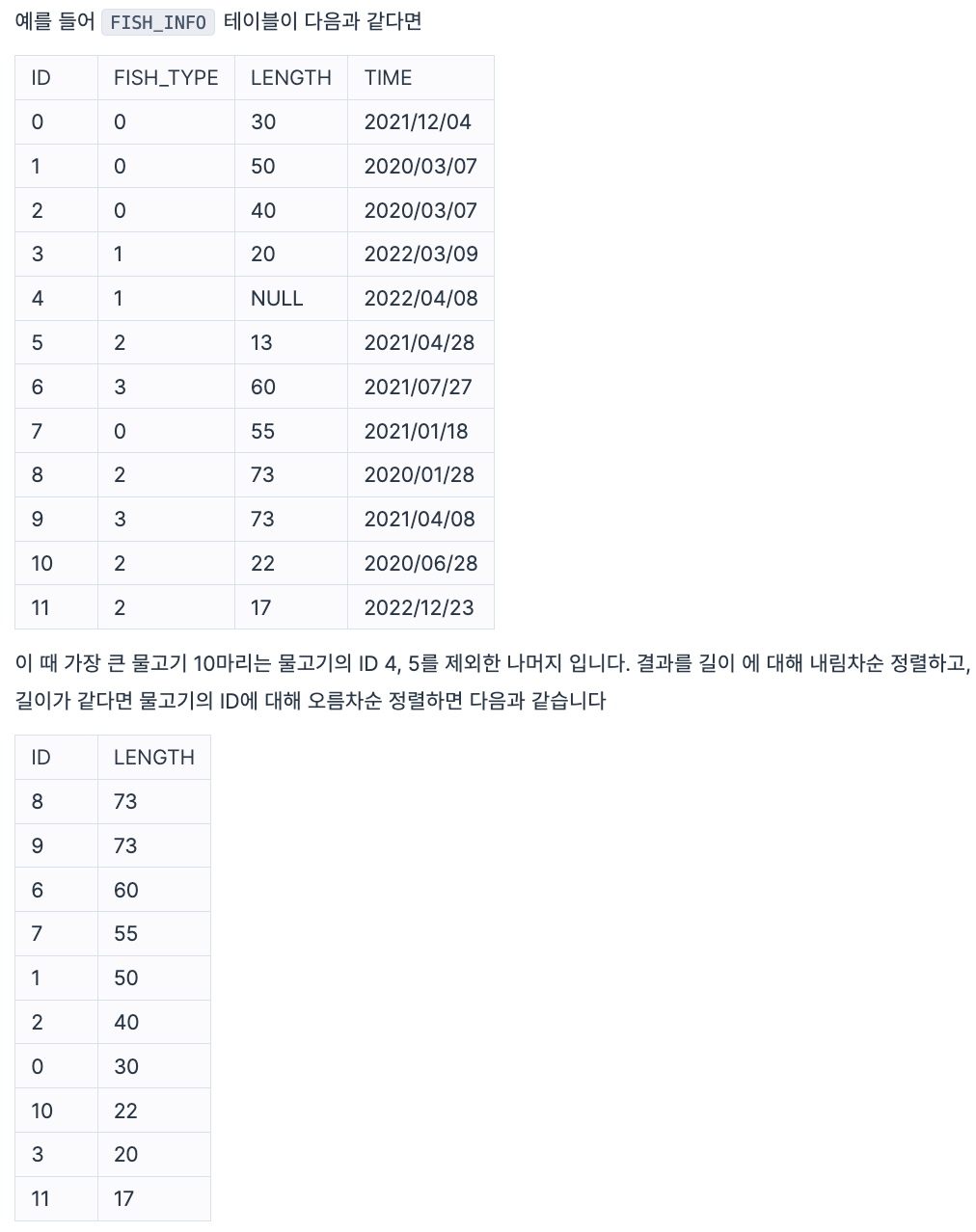
구현
SELECT ID, LENGTH FROM FISH_INFO ORDER BY LENGTH DESC, ID LIMIT 10;7. 특정 물고기를 잡은 총 수 구하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/298518
낚시앱에서 사용하는 FISH_INFO 테이블은 잡은 물고기들의 정보를 담고 있습니다. FISH_INFO 테이블의 구조는 다음과 같으며 ID, FISH_TYPE, LENGTH, TIME은 각각 잡은 물고기의 ID, 물고기의 종류(숫자), 잡은 물고기의 길이(cm), 물고기를 잡은 날짜를 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| FISH_TYPE | INTEGER | FALSE |
| LENGTH | FLOAT | TRUE |
| TIME | DATE | FALSE |
단, 잡은 물고기의 길이가 10cm 이하일 경우에는 LENGTH 가 NULL 이며, LENGTH 에 NULL 만 있는 경우는 없습니다.
FISH_NAME_INFO 테이블은 물고기의 이름에 대한 정보를 담고 있습니다. FISH_NAME_INFO 테이블의 구조는 다음과 같으며, FISH_TYPE, FISH_NAME은 각각 물고기의 종류(숫자), 물고기의 이름(문자) 입니다.
| Column name | Type | Nullable |
|---|---|---|
| FISH_TYPE | INTEGER | FALSE |
| FISH_NAME | VARCHAR | FALSE |
FISH_INFO 테이블에서 잡은 BASS와 SNAPPER의 수를 출력하는 SQL 문을 작성해주세요.
컬럼명은 'FISH_COUNT'로 해주세요.
예를 들어 FISH_INFO 테이블이 다음과 같고
| ID | FISH_TYPE | LENGTH | TIME |
|---|---|---|---|
| 0 | 0 | 30 | 2021/12/04 |
| 1 | 0 | 50 | 2020/03/07 |
| 2 | 0 | 40 | 2020/03/07 |
| 3 | 1 | 20 | 2022/03/09 |
| 4 | 1 | NULL | 2022/04/08 |
| 5 | 2 | 13 | 2021/04/28 |
| 6 | 0 | 60 | 2021/07/27 |
| 7 | 0 | 55 | 2021/01/18 |
| 8 | 2 | 73 | 2020/01/28 |
| 9 | 2 | 73 | 2021/04/08 |
| 10 | 2 | 22 | 2020/06/28 |
| 11 | 2 | 17 | 2022/12/23 |
FISH_NAME_INFO 테이블이 다음과 같다면
| FISH_TYPE | FISH_NAME |
|---|---|
| 0 | BASS |
| 1 | SNAPPER |
| 2 | ANCHOVY |
'BASS' 는 물고기 종류 0에 해당하고, 'SNAPPER' 는 물고기 종류 1에 해당하므로 잡은 'BASS' 와 'SNAPPER' 수는 7마리입니다.
| FISH_COUNT |
|---|
| 7 |
구현
SELECT COUNT(*) AS FISH_COUNT FROM FISH_INFO FI
JOIN FISH_NAME_INFO FNI ON FI.FISH_TYPE = FNI.FISH_TYPE
WHERE FNI.FISH_NAME = 'BASS' OR FNI.FISH_NAME = 'SNAPPER';8. 특정 형질을 가지는 대장균 찾기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/301646
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | FALSE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | INTEGER | TRUE |
| GENOTYPE | DATE | FALSE |
2번 형질을 보유하지 않으면서 1번이나 3번 형질을 보유하고 있는 대장균 개체의 수(COUNT)를 출력하는 SQL 문을 작성해주세요. 1번과 3번 형질을 모두 보유하고 있는 경우도 1번이나 3번 형질을 보유하고 있는 경우에 포함합니다.
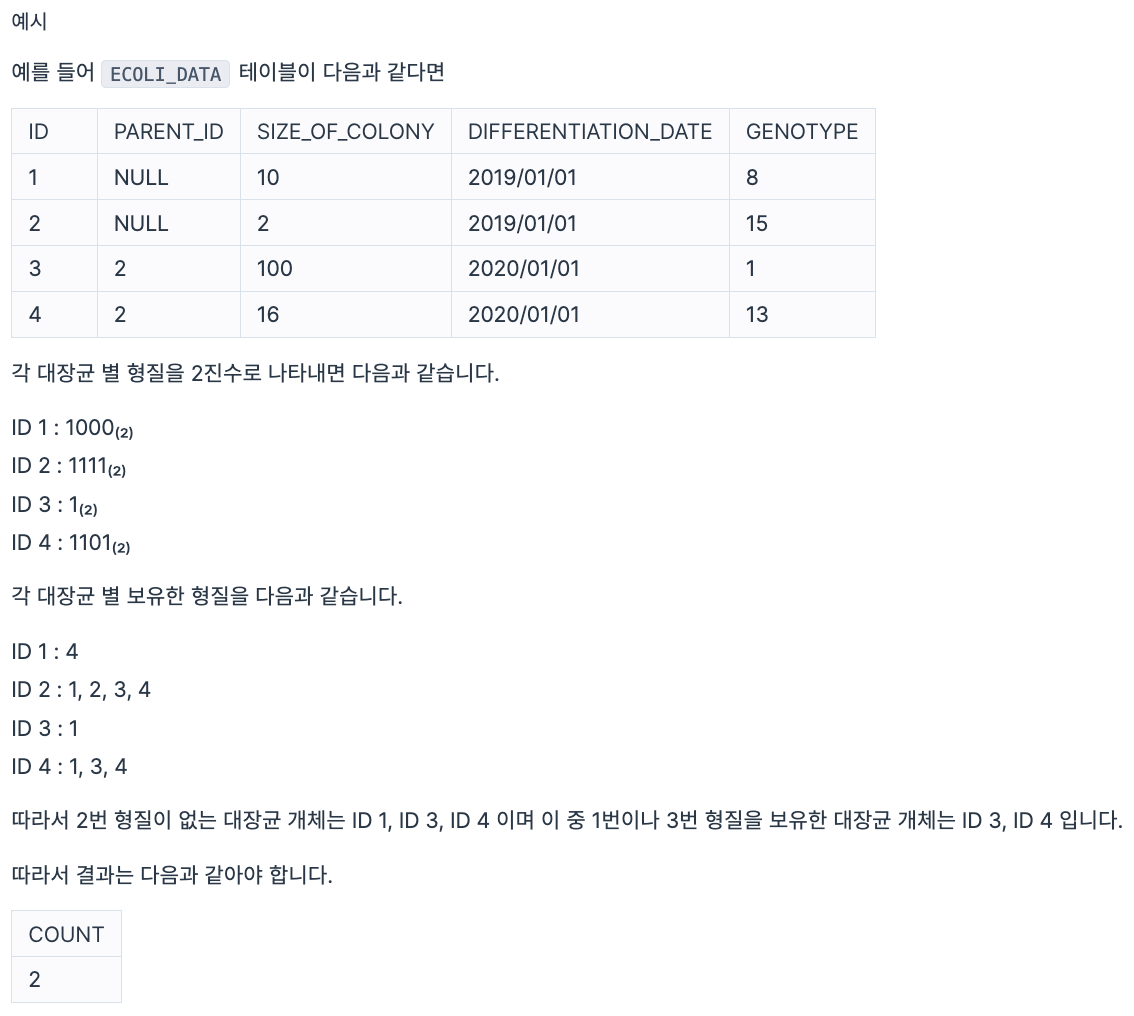
구현
SELECT COUNT(*) AS COUNT FROM ECOLI_DATA
WHERE (GENOTYPE & 2) != 2 AND ((GENOTYPE & 4) = 4 OR (GENOTYPE & 1) = 1)9. 부모의 형질을 모두 가지는 대장균 찾기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/301647
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | FALSE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | INTEGER | TRUE |
| GENOTYPE | DATE | FALSE |
최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
부모의 형질을 모두 보유한 대장균의 ID(ID), 대장균의 형질(GENOTYPE), 부모 대장균의 형질(PARENT_GENOTYPE)을 출력하는 SQL 문을 작성해주세요. 이때 결과는 ID에 대해 오름차순 정렬해주세요.
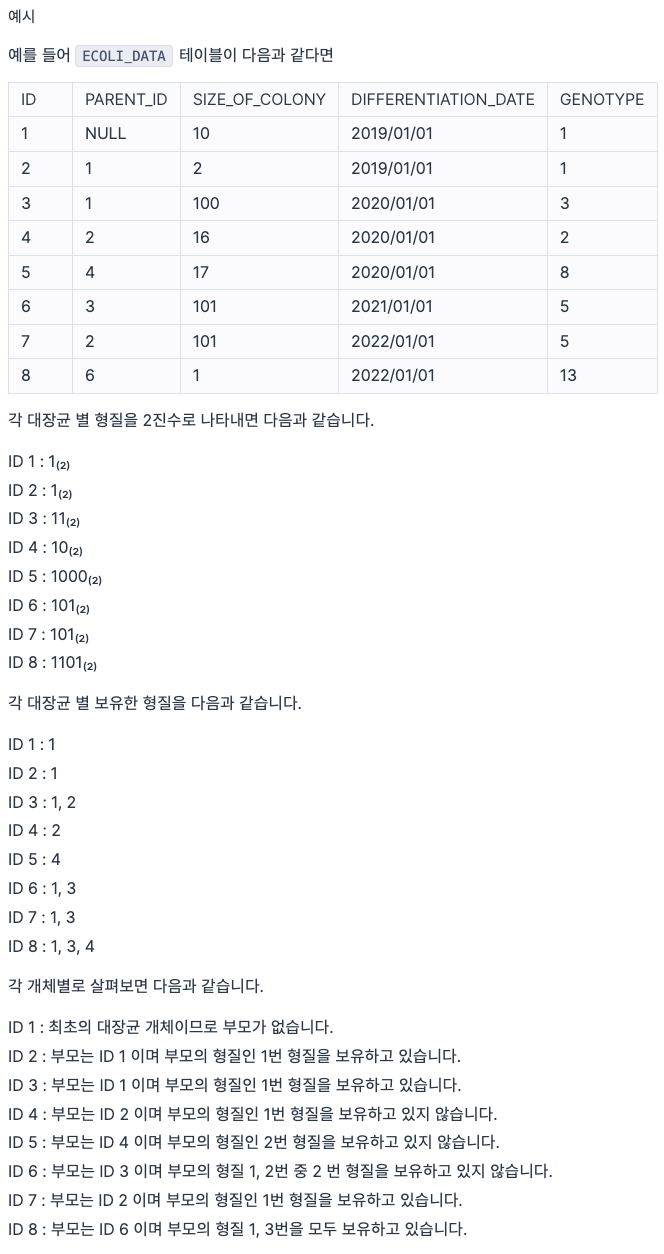

구현
SELECT ED1.ID, ED1.GENOTYPE, ED2.GENOTYPE AS PARENT_GENOTYPE FROM ECOLI_DATA ED1
JOIN ECOLI_DATA ED2 ON ED1.PARENT_ID = ED2.ID
WHERE (ED1.GENOTYPE & ED2.GENOTYPE) = ED2.GENOTYPE
ORDER BY ED1.ID;