1. 서울에 위치한 식당 목록 출력하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/131118
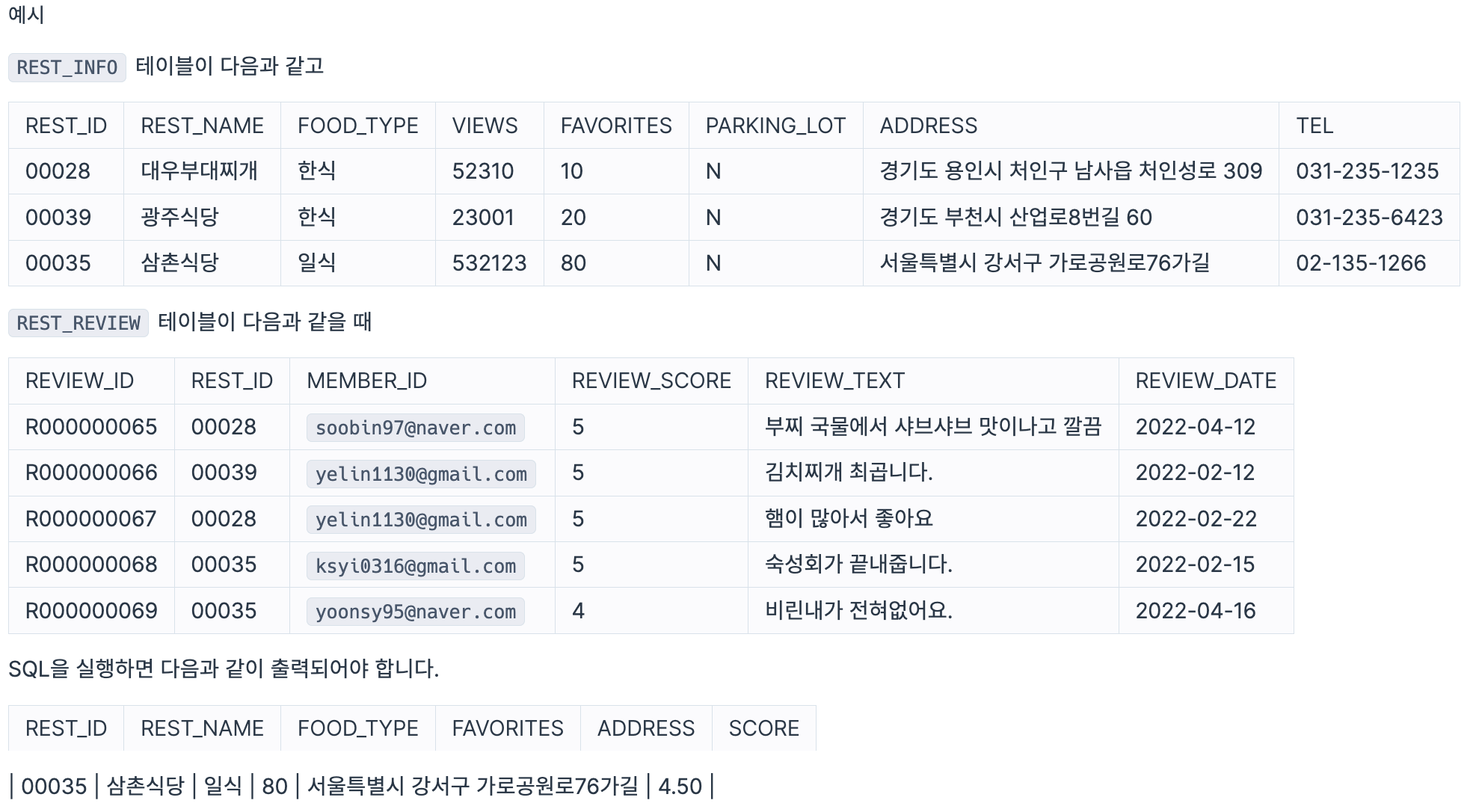
다음은 식당의 정보를 담은 REST_INFO 테이블과 식당의 리뷰 정보를 담은 REST_REVIEW 테이블입니다. REST_INFO 테이블은 다음과 같으며 REST_ID, REST_NAME, FOOD_TYPE, VIEWS, FAVORITES, PARKING_LOT, ADDRESS, TEL은 식당 ID, 식당 이름, 음식 종류, 조회수, 즐겨찾기수, 주차장 유무, 주소, 전화번호를 의미합니다.
| Column name | Type | Nullable |
|---|---|---|
| REST_ID | VARCHAR(5) | FALSE |
| REST_NAME | VARCHAR(50) | FALSE |
| FOOD_TYPE | VARCHAR(20) | TRUE |
| VIEWS | NUMBER | TRUE |
| FAVORITES | NUMBER | TRUE |
| PARKING_LOT | VARCHAR(1) | TRUE |
| ADDRESS | VARCHAR(100) | TRUE |
| TEL | VARCHAR(100) | TRUE |
REST_REVIEW 테이블은 다음과 같으며 REVIEW_ID, REST_ID, MEMBER_ID, REVIEW_SCORE, REVIEW_TEXT, REVIEW_DATE는 각각 리뷰 ID, 식당 ID, 회원 ID, 점수, 리뷰 텍스트, 리뷰 작성일을 의미합니다.
| Column name | Type | Nullable |
|---|---|---|
| REVIEW_ID | VARCHAR(10) | FALSE |
| REST_ID | VARCHAR(10) | TRUE |
| MEMBER_ID | VARCHAR(100) | TRUE |
| REVIEW_SCORE | NUMBER | TRUE |
| REVIEW_TEXT | VARCHAR(1000) | TRUE |
| REVIEW_DATE | DATE | TRUE |
REST_INFO와 REST_REVIEW 테이블에서 서울에 위치한 식당들의 식당 ID, 식당 이름, 음식 종류, 즐겨찾기수, 주소, 리뷰 평균 점수를 조회하는 SQL문을 작성해주세요. 이때 리뷰 평균점수는 소수점 세 번째 자리에서 반올림 해주시고 결과는 평균점수를 기준으로 내림차순 정렬해주시고, 평균점수가 같다면 즐겨찾기수를 기준으로 내림차순 정렬해주세요.
구현
SELECT
RI.REST_ID,
RI.REST_NAME,
RI.FOOD_TYPE,
RI.FAVORITES,
RI.ADDRESS,
ROUND(AVG(RR.REVIEW_SCORE), 2) AS SCORE
FROM
REST_INFO RI
JOIN
REST_REVIEW RR ON RI.REST_ID = RR.REST_ID
WHERE
RI.ADDRESS LIKE '서울%'
GROUP BY
RI.REST_ID, RI.REST_NAME, RI.FOOD_TYPE, RI.FAVORITES, RI.ADDRESS
ORDER BY
SCORE DESC,
RI.FAVORITES DESC;아니... 계속 안 돼서 별 짓 다 했는데 %서울%에서 서울%로 바꾸니까 바로 됨...
2. 오프라인/온라인 판매 데이터 통합하기
문제
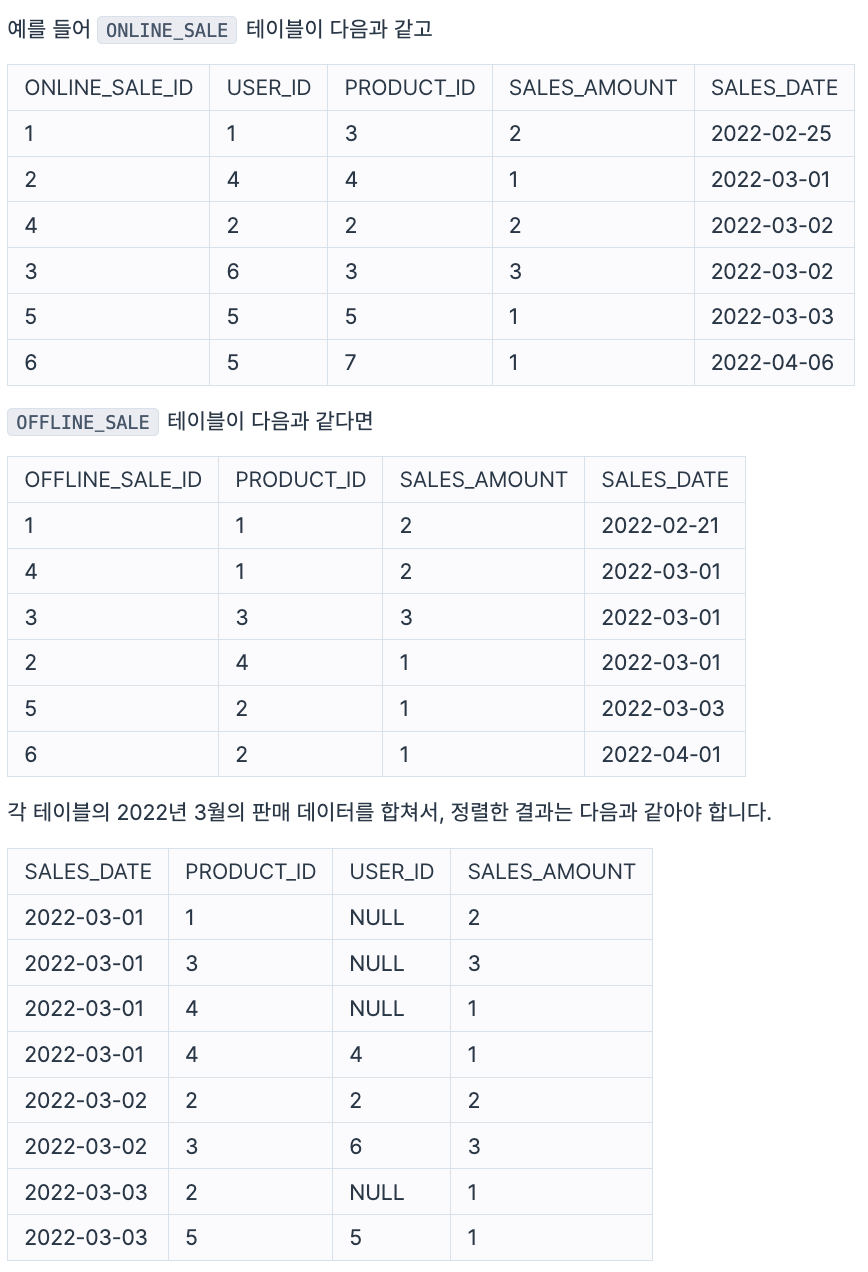
다음은 어느 의류 쇼핑몰의 온라인 상품 판매 정보를 담은 ONLINE_SALE 테이블과 오프라인 상품 판매 정보를 담은 OFFLINE_SALE 테이블 입니다. ONLINE_SALE 테이블은 아래와 같은 구조로 되어있으며 ONLINE_SALE_ID, USER_ID, PRODUCT_ID, SALES_AMOUNT, SALES_DATE는 각각 온라인 상품 판매 ID, 회원 ID, 상품 ID, 판매량, 판매일을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ONLINE_SALE_ID | INTEGER | FALSE |
| USER_ID | INTEGER | FALSE |
| PRODUCT_ID | INTEGER | FALSE |
| SALES_AMOUNT | INTEGER | FALSE |
| SALES_DATE | DATE | FALSE |
동일한 날짜, 회원 ID, 상품 ID 조합에 대해서는 하나의 판매 데이터만 존재합니다.
OFFLINE_SALE 테이블은 아래와 같은 구조로 되어있으며 OFFLINE_SALE_ID, PRODUCT_ID, SALES_AMOUNT, SALES_DATE는 각각 오프라인 상품 판매 ID, 상품 ID, 판매량, 판매일을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| OFFLINE_SALE_ID | INTEGER | FALSE |
| PRODUCT_ID | INTEGER | FALSE |
| SALES_AMOUNT | INTEGER | FALSE |
| SALES_DATE | DATE | FALSE |
동일한 날짜, 상품 ID 조합에 대해서는 하나의 판매 데이터만 존재합니다.
ONLINE_SALE 테이블과 OFFLINE_SALE 테이블에서 2022년 3월의 오프라인/온라인 상품 판매 데이터의 판매 날짜, 상품ID, 유저ID, 판매량을 출력하는 SQL문을 작성해주세요. OFFLINE_SALE 테이블의 판매 데이터의 USER_ID 값은 NULL 로 표시해주세요. 결과는 판매일을 기준으로 오름차순 정렬해주시고 판매일이 같다면 상품 ID를 기준으로 오름차순, 상품ID까지 같다면 유저 ID를 기준으로 오름차순 정렬해주세요.
구현
SELECT
DATE_FORMAT(SALES_DATE, '%Y-%m-%d') AS SALES_DATE,
PRODUCT_ID,
USER_ID,
SALES_AMOUNT
FROM
ONLINE_SALE
WHERE
DATE_FORMAT(SALES_DATE, '%Y-%m') = '2022-03'
UNION ALL
SELECT
DATE_FORMAT(SALES_DATE, '%Y-%m-%d') AS SALES_DATE,
PRODUCT_ID,
NULL AS USER_ID,
SALES_AMOUNT
FROM
OFFLINE_SALE
WHERE
DATE_FORMAT(SALES_DATE, '%Y-%m') = '2022-03'
ORDER BY SALES_DATE, PRODUCT_ID, USER_ID;SELECT 결과 합치기 (UNION, UNION ALL)
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;UNION이나 UNION ON을 사용하면 서로 다른 테이블에서의 조회 결과를 하나로 합쳐 조회할 수 있다.
대신 각 SELECT절에 명시한 컬럼의 수와 컬럼명이 모두 일치해야만 사용할 수 있다.
위 문제에서는 OFFLINE_SALE 테이블에 USER_ID라는 컬럼이 존재하지 않았기 때문에 NULL AS USER_ID라고 작성함으로써 조회 결과에 USER_ID라는 컬럼을 추가해서 NULL 값을 넣어 주었다. 당연히 실제 저장된 테이블에 컬럼이 추가된 것이 아니고 출력 결과에만 영향을 미치는 것이다.
UNION은 두 SELECT의 조회 결과 중 중복되는 것이 있으면 한 번만 출력한다.
반면 UNION ALL은 중복되는 레코드가 있더라도 모두 출력한다.
3. 대장균들의 자식의 수 구하기
문제
https://school.programmers.co.kr/learn/courses/30/lessons/299305
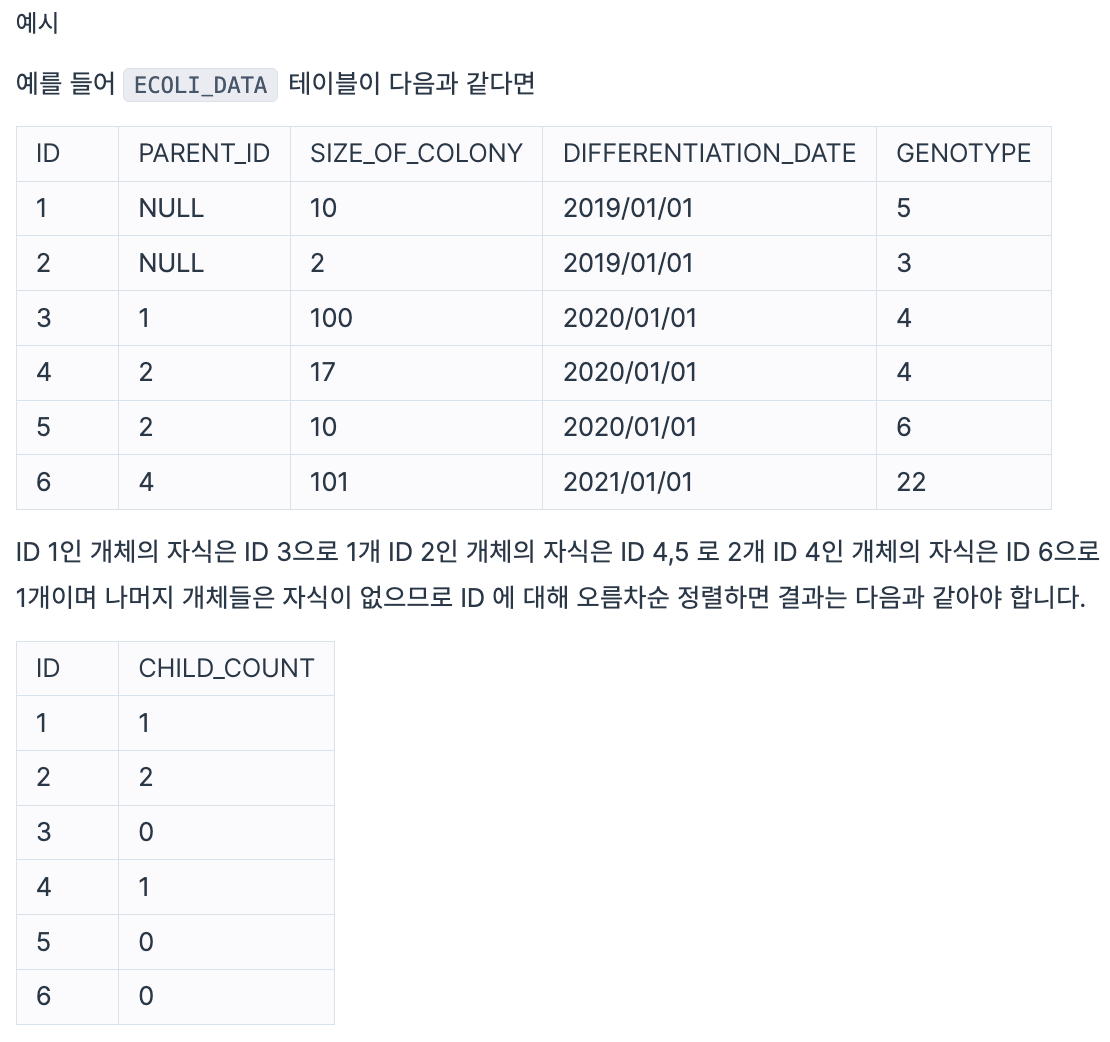
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | TRUE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | DATE | FALSE |
| GENOTYPE | INTEGER | FALSE |
최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
대장균 개체의 ID(ID)와 자식의 수(CHILD_COUNT)를 출력하는 SQL 문을 작성해주세요. 자식이 없다면 자식의 수는 0으로 출력해주세요. 이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요.
구현
SELECT A.ID, COUNT(B.PARENT_ID) AS CHILD_COUNT FROM ECOLI_DATA A
LEFT JOIN ECOLI_DATA B ON A.ID = B.PARENT_ID
GROUP BY A.ID
ORDER BY A.ID;4. 대장균의 크기에 따라 분류하기 1
문제
https://school.programmers.co.kr/learn/courses/30/lessons/299307
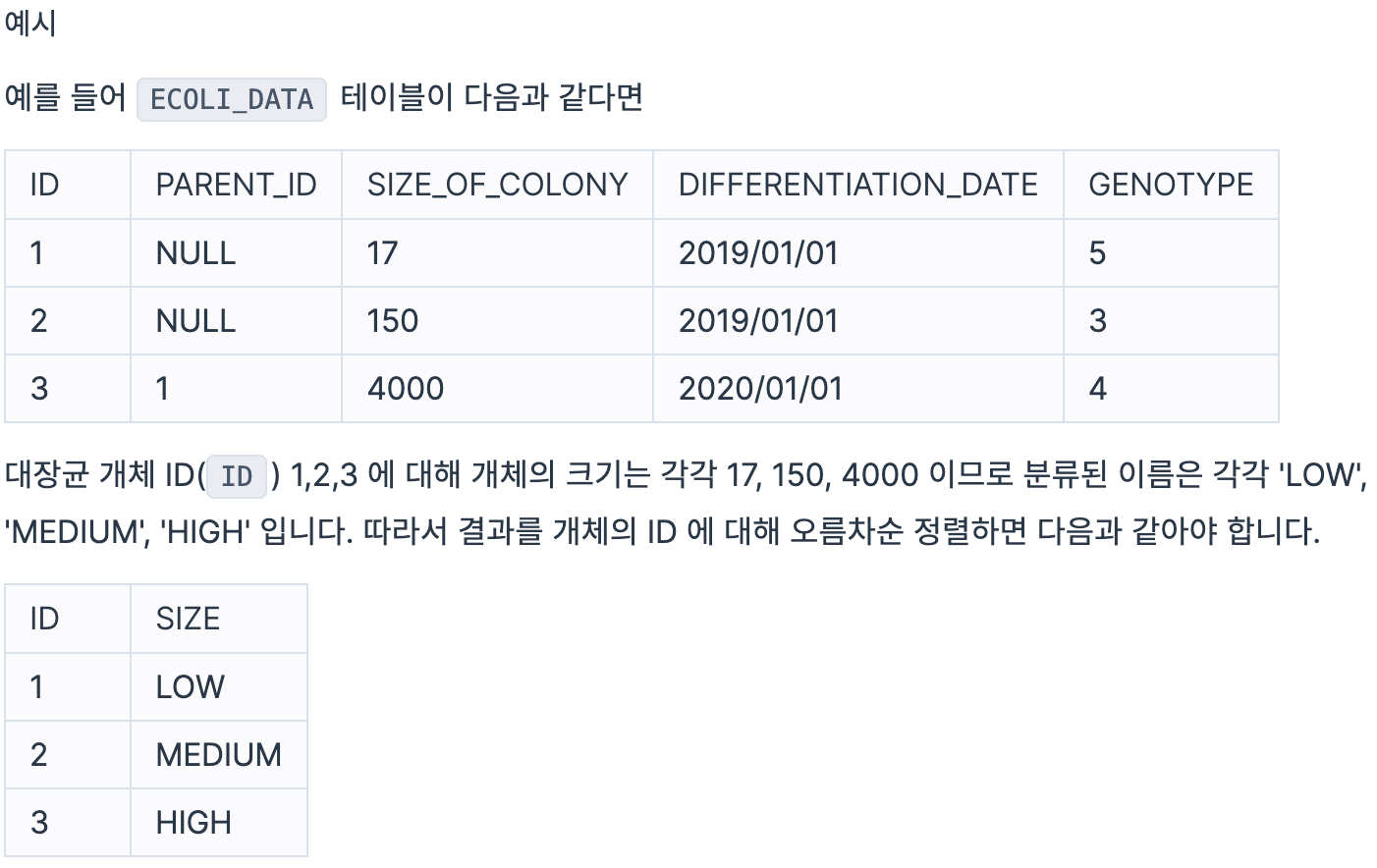
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
| Column name | Type | Nullable |
|---|---|---|
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | TRUE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | DATE | FALSE |
| GENOTYPE | INTEGER | FALSE |
최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
대장균 개체의 크기가 100 이하라면 'LOW', 100 초과 1000 이하라면 'MEDIUM', 1000 초과라면 'HIGH' 라고 분류합니다. 대장균 개체의 ID(ID) 와 분류(SIZE)를 출력하는 SQL 문을 작성해주세요.이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요.
구현
SELECT ID,
CASE
WHEN SIZE_OF_COLONY <= 100 THEN 'LOW'
WHEN SIZE_OF_COLONY > 100 AND SIZE_OF_COLONY <= 1000 THEN 'MEDIUM'
WHEN SIZE_OF_COLONY > 1000 THEN 'HIGH'
END AS SIZE
FROM ECOLI_DATA
ORDER BY ID;조건문 (CASE WHEN THEN END)
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;WHEN절 뒤에는 반드시THEN절이 나와야 한다.- 컬럼 값이
WHEN절의 조건 중 어느 것도 만족하지 않고,ELSE절이 없는 경우 NULL을 반환한다.
SELECT OrderID, Quantity,
CASE
WHEN Quantity > 30 THEN 'The quantity is greater than 30'
WHEN Quantity = 30 THEN 'The quantity is 30'
ELSE 'The quantity is under 30'
END AS QuantityText
FROM OrderDetails;SELECT CustomerName, City, Country
FROM Customers
ORDER BY
(CASE
WHEN City IS NULL THEN Country
ELSE City
END);THEN절 뒤에 위와 같은 식으로 테이블명이 들어갈 수도 있는 것 같다.
