NCE & MIL-NCE
NCE(Noise Contrastive Estimation) loss :
Self-Supervised Learning의 Contrastive Learning에서 나오는 loss 함수로(논문 : A Simple Framework for Contrastive Learning of Visual Representations, SimCLR),
Contrastive Learning을 간단히 설명하자면,
같은 이미지에 augmentation을 가한 뒤, 기준인 anchor와 positive 사이의 positive pair의 embedded vector가 유사해지도록(거리가 가까워지도록=cosine 유사도로 계산=내적하면=유사하면 값이 커짐) 학습을 하고,
다른 이미지에 서로 다른 augmentation을 가한 뒤, 기준인 anchor embedded vector(기준 이미지)와 negative embedded vector 사이의 거리는 멀어지도록 학습을 시키는 것이다.
데이터셋에서 data augmentation(t, t′)을 적용하여 2개의 pair image(하나는 origin, 다른 하나는 augmentation)를 만들고(=positive pair),
나머지 minibatch에서 생성된 image들은 negative sample로 취급한다.(개수 = 2N - (positive)2개)
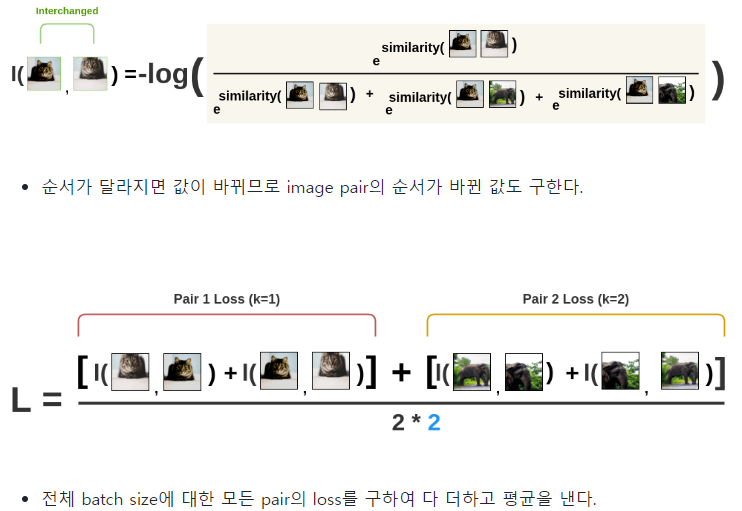
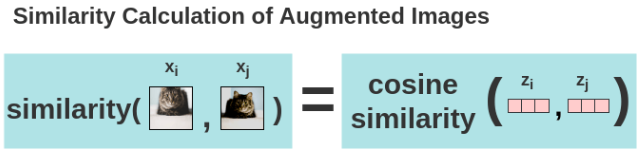
아래는 Positive pair 이미지를 통해 구한 Cosine 유사도
아래는 softmax(softmax 글 참조. softmax는 0~1사이의 실수로, 확률값을 구함. 값이 max이려면 차이가 얼마 안나도 가장 큰 값이 확실하게 구별될 정도로 크게 나타나야하기에, e를 사용하면, 지수승으로 표현이 가능해서 값의 비교가 명확)
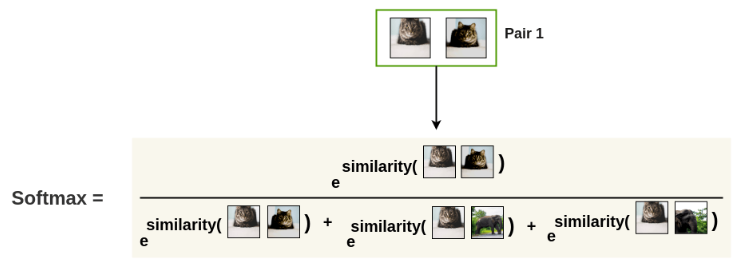
아래는 -log(softmax)로 전체 loss를 구하는 식이다. -log(softmax)전체값인 loss가 최소가 되게하려면, (softmax)의 값이 최대가 되어야하므로, (softmax) 분자값이 크고, 분모값이 작을수록 (softmax)값이 최대가 된다.
즉, (softmax) 분자값인 positive similarity(cosine 유사도 = 내적값)은 커야하고,
(softmax)분모값인 negative similarity(cosine 유사도 = 내적값)은 작아져야한다. 이때, positive는 원본이미지(고양이)에서 어떤 augmentation을 적용한 1개 이미지(다른 모든것들과의 비교 기준이 되는 이미지), 또다른 augmentation을 적용한 나머지 1개 이미지 한쌍으로, negative는 그 외 다른 이미지(코끼리, 기린 등)를 각기 다른 augmentation을 적용한 이미지로 2N-2개를 나타낸다.