핵심원칙
* 등분산성
실험하고자 하는 변수 이외에 모든 통제가 필요한 변수들은 다 독립적으로 유지
* OEC
Overroll Evalution Criterion
조직은 데이터 중심의 의사결정을 내리기 위해 OEC를 공식화
실험목적에 맞는 정량적 측정
의사결정 - 개발 - 평가 단계를 거침
고려해야할 요소는
1. 단기간 측정 (1~2주)
2. 개선 변화 차이에 민감
3. 장기 목표 예측 가능
* 인프라와 실험
신뢰 확인을 위해 인프라와 실험에 투자를 아끼지 말아야 한다.
* 아이디어 가치 평가
조직은 아이디어 가치 평가에 서툴다는 것을 인식해야한다.
아이디어 중 70%~90% 폐기된다고 생각해야 한다.
필수통계
개요
A/B 테스트는 전체 모집단을 샘플링 하여 샘플링 된 그룹을 통해 가설을 검증한다.
시간,비용 문제로 일부 표본을 사용하여 AB테스트를 진행한다.
이 표본은 모집단 전체에 대한 대표성을 가지고 있어야 한다.
표본추출방법
1. 확률표본추출
-> 모집단에서 임의로 샘플을 추출할 때, 각 개체가 선택될 확률이 동일한 방법
1). 단순임의추출
- 모집단에서 표본 추출함에 있어 어떠한 임의적 개입이 없음
ex) 제비뽑기, 로또
2). 층화임의추출
- 집단을 일정한 기준으로 분류, 분류된 집단의 비율만큼 표본추출
3). 체계적추출
- 표본 추출을 함에 있어서 일정한 체계를 가지고 표본 추출
ex) 정렬 후, k번째 줄 추출
4). 집락추출
- 모집단을 서로 동질적인 집단으로 구분, 집단 자체를 표본으로 추출하는 방식
2. 비확률 표폰추출
-> A/B테스트에서는 적용하기가 어려움
1). 편의표본추출
- 알고있는 사람, 간단한 설문조사 환경에서 적용
2). 판단표본추출
- 모집단의 의견을 잘 반영할 수 있을것이라 판단되는 특정 집단을 표본으로 선정
3). 할당표본추출
- 설문조사를 할 사람들의 인원을 미리 설정, 목표한 샘플수에 도달하면 설문조사 중단
1. P-Value(유의확률)
-> 귀무가설이 맞다고 가정할 때 관찰된 결과가 일어날 확률
A 그룹 1000명 평균매출 20,000 VS B 그룹 1000명 평균매출 21,000
이 경우라면 B 그룹이 매출이 더 좋은건가?
답은 아직 알 수 없다.
각 그룹의 매출은 표본평균 매출이지, 실제 모집단의 평균 매출은 아니다. 즉 통계적 검증이 필요.
그렇다면 검증 방법이
-> 하나씩 모든 데이터 검증? X
-> 히스토그램으로 비교? X
위 두가지는 엄밀성이 없다.
이 엄밀성을 보장하기 위한 방법이
검정통계량(t value)
t = a그룹평균 - b그룹평균 / 불확실도 (SE)
이다.
하지만 t-value는 표본수에 따라 모양이 달라지므로 한계가 있다.
이걸 보완하기 위해 P-Value가 있다.
P-Value는 표본수와 상관없는 확률을 말하며, 어떤 사건이 우연히 발생할 확률이다.
P-Value의 유효성 검증을 위해 귀무가설, 대립가설이 나온다.
귀무가설 : A그룹과 B그룹간 매출차이가 없다.
대립가설 : A그룹과 B그룹간 매출차이가 있다.
P-Value: 0.04 (보통 5% 이내면 우연히 발생할 가능성이 낮다고 본다)
귀무가설을 기각하고 대립가설을 채택한다.
즉 A 그룹과 B 그룹간 매출 차이가 있다.
2. 신뢰구간
A/B 테스트에서 신뢰구간은 실험 결과가 얼마나 신뢰할 수 있는지를 나타내는 통계적 수치입니다. 이는 일반적으로 A/B 테스트의 결과가 우연에 의한 것이 아니라 실제 효과에 기인하는지를 판단하는 데 사용됩니다.
2-1). 신뢰구간의 기본 개념
- 정의: 신뢰구간은 특정 통계적 추정치(예: 평균, 비율)가 주어진 신뢰 수준(보통 95%나 99%)에서 실제 값이 포함될 범위를 나타냅니다.
- 해석: 예를 들어, 95% 신뢰구간이 [a, b]라면, 실제 값이 이 범위 안에 있을 확률이 95%라는 것을 의미합니다.
2-2).A/B 테스트에서의 신뢰구간 계산
A/B 테스트의 경우, 신뢰구간은 보통 두 그룹(예: A 그룹과 B 그룹)의 성과 차이에 대해 계산됩니다. 여기서는 변환율(Conversion Rate)과 같은 비율에 대한 신뢰구간 계산을 예시로 들겠습니다.
-
변환율 계산:
- A 그룹 변환율 = A 그룹의 변환 수 / A 그룹의 총 사용자 수
- B 그룹 변환율 = B 그룹의 변환 수 / B 그룹의 총 사용자 수
-
표준 오차 계산: 각 그룹의 변환율에 대한 표준 오차를 계산합니다.
- 표준 오차(SE) = √[p(1 - p) / n]
- 여기서 p는 변환율, n은 샘플 크기입니다.
-
신뢰구간 계산:
- 신뢰구간 = 변환율 ± Z * 표준 오차
- Z 값은 신뢰 수준에 따라 달라집니다(예: 95% 신뢰 수준에서 Z ≈ 1.96).
2-3).예시
A 그룹과 B 그룹에서 각각 1000명의 사용자를 대상으로 테스트를 수행했다고 가정해 봅시다. A 그룹에서 100명, B 그룹에서 120명이 변환되었다고 합시다.
-
변환율:
- A 그룹 = 100/1000 = 10%
- B 그룹 = 120/1000 = 12%
-
표준 오차:
- A 그룹의 SE = √[0.1(1 - 0.1) / 1000] ≈ 0.00949
- B 그룹의 SE = √[0.12(1 - 0.12) / 1000] ≈ 0.01037
-
95% 신뢰구간:
- A 그룹: 10% ± 1.96 * 0.00949
- B 그룹: 12% ± 1.96 * 0.01037
이를 통해 각 그룹의 변환율이 실제로 어느 범위 내에 있을지 추정할 수 있으며, 이 범위들이 서로 겹치지 않는 경우, 두 그룹 간의 차이가 통계적으로 유의미하다고 판단할 수 있습니다.
귀무가설 (Null Hypothesis, ( H_0 ))
- 정의: 귀무가설은 기본적으로 "효과가 없다"거나 "차이가 없다"는 가설입니다. 이는 검증하려는 가설의 반대되는 주장을 나타냅니다.
- A/B 테스트에서의 예시: A/B 테스트에서 귀무가설은 일반적으로 "A 그룹과 B 그룹 간의 성과 차이가 없다"는 것을 의미합니다. 예를 들어, 두 웹사이트 디자인 사이에 사용자의 반응에 유의미한 차이가 없다는 주장일 수 있습니다.
대립가설 (Alternative Hypothesis, ( H_1 ))
- 정의: 대립가설은 귀무가설에 대한 대안입니다. 이는 검증하고자 하는 주장을 나타내며, 보통 "효과가 있다"거나 "차이가 있다"는 가설입니다.
- A/B 테스트에서의 예시: A/B 테스트에서의 대립가설은 "A 그룹과 B 그룹 간의 성과에 차이가 있다"는 것을 의미합니다. 예를 들어, 한 디자인이 다른 디자인보다 사용자의 반응을 더 잘 이끌어낸다는 주장일 수 있습니다.
통계적 검정
- 실행 방법: 실험 데이터를 사용하여 귀무가설이 맞을 확률을 계산합니다. 이는 p-값(p-value)을 통해 표현되며, 이 값이 사전에 설정한 유의 수준(예: 0.05)보다 작으면 귀무가설을 기각하고 대립가설을 채택합니다.
- 결과 해석: 만약 p-값이 0.05보다 작으면, 우리는 5%의 오류 확률 내에서 귀무가설(즉, A 그룹과 B 그룹 간에 차이가 없다는 주장)을 기각할 수 있습니다. 이는 A 그룹과 B 그룹 간에 통계적으로 유의미한 차이가 있다는 것을 의미합니다.
예시
- 귀무가설 ( H_0 ): A 그룹과 B 그룹의 변환율은 동일하다.
- 대립가설 ( H_1 ): A 그룹과 B 그룹의 변환율은 다르다.
여기서, 통계적 검정을 통해 얻은 p-값이 매우 낮다면(예: 0.01), 우리는 귀무가설을 기각하고 대립가설을 채택할 수 있습니다. 이는 A 그룹과 B 그룹 간의 변환율에 실제로 차이가 있다는 것을 의미합니다. 반대로, p-값이 유의 수준보다 크면 귀무가설을 기각할 수 없으며, 두 그룹 간에 유의미한 차이가 없다고 결론짓습니다.
A/B 테스트에서 t-검정(t-test)은 두 집단 간의 평균 차이가 통계적으로 유의미한지를 판단하는 데 사용되는 통계적 방법입니다. 이 방법은 특히 샘플 크기가 작거나 모집단의 분산이 알려져 있지 않을 때 유용합니다.
3. t-검정의 종류
- 독립 표본 t-검정 (Independent t-test): 서로 다른 두 집단(예: A 그룹과 B 그룹) 간의 평균을 비교할 때 사용됩니다.
- 쌍체 표본 t-검정 (Paired t-test): 같은 대상에 대해 두 번의 측정(예: 시간 전후)을 비교할 때 사용됩니다.
3-1). A/B 테스트에서의 독립 표본 t-검정
A/B 테스트에서는 주로 독립 표본 t-검정이 사용됩니다. 이는 A 그룹과 B 그룹이 서로 독립적이며, 각각의 평균 성과(예: 클릭률, 전환율)를 비교하는 데 사용됩니다.
3-2). t-검정의 계산 과정
- 평균과 표준 편차 계산: 두 그룹 각각의 평균과 표준 편차를 계산합니다.
- t-값 계산: 다음 공식을 사용해 t-값을 계산합니다.
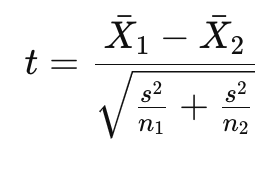
여기서 (\bar{X}_1)과 (\bar{X}_2)는 각 그룹의 평균, (s^2)는 풀링된 분산, (n_1)과 (n_2)는 각 그룹의 샘플 크기입니다.
3. 자유도 계산: 두 그룹의 샘플 크기를 고려하여 자유도(df)를 계산합니다.
4. p-값 결정: 계산된 t-값과 자유도를 사용하여 p-값을 찾습니다. 이는 표준 t 분포 테이블 또는 소프트웨어를 통해 확인할 수 있습니다.
3-3). 결과 해석
- p-값: p-값이 사전에 정한 유의 수준(예: 0.05)보다 작으면, 두 그룹 간의 평균 차이가 통계적으로 유의미하다고 할 수 있습니다.
- 통계적 유의미성: 이는 A/B 테스트에서 한 변형(예: 새로운 웹페이지 디자인)이 다른 변형보다 유의미하게 다른 결과를 가져온다는 것을 의미합니다.
t-검정은 A/B 테스트의 결과를 해석하는 데 있어 중요한 도구로,
두 그룹 간의 차이가 우연에 의한 것이 아니라 실제 차이임을 입증하는 데 사용됩니다.
4. 카이제곱 검정
A/B 테스트에서 카이제곱 검정(Chi-square test)은 두 개 이상의 범주형 변수 간의 독립성을 테스트하는 데 사용되는 통계적 방법입니다. 이 검정은 특히 두 범주형 변수 간의 연관성이나 독립성을 파악하는 데 유용하며, A/B 테스트에서는 주로 두 그룹 간의 반응이나 선호도의 차이를 평가하는 데 사용됩니다.
4-1). 카이제곱 검정의 기본 개념
- 목적: 두 범주형 변수 간의 연관성을 검증합니다. 예를 들어, 사용자가 A 그룹 또는 B 그룹에 속하는지와 특정 제품을 구매하거나 구매하지 않는지 사이의 연관성을 검사할 수 있습니다.
- 데이터 구조: 보통 2x2의 분할표(Contingency Table) 형태로 데이터를 배열합니다. 이 표는 각 그룹에 대한 두 가지 결과(예: 구매/비구매)를 나타냅니다.
4-2). 카이제곱 검정의 계산 과정
(1). 관찰 빈도(Observed Frequencies): 각 카테고리에 대한 실제 관찰 횟수를 기록합니다.
(2). 기대 빈도(Expected Frequencies): 각 카테고리에서 기대되는 빈도를 계산합니다. 이는 전체 관찰 횟수와 각 행과 열의 합계를 고려하여 계산됩니다.
(3). 카이제곱 통계량 계산: 다음 공식을 사용하여 카이제곱 통계량을 계산합니다.
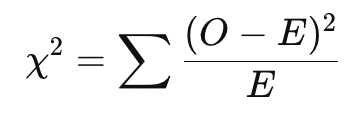
여기서 ( O )는 관찰 빈도, ( E )는 기대 빈도입니다.
(4). 유의성 판단: 계산된 카이제곱 통계량과 자유도를 사용하여 p-값을 결정합니다. 이는 카이제곱 분포 테이블 또는 소프트웨어를 통해 확인할 수 있습니다.
4-3). 결과 해석
- p-값: p-값이 사전에 설정한 유의 수준(예: 0.05)보다 작으면, 두 변수 간에 통계적으로 유의미한 연관성이 있다고 할 수 있습니다. 즉, A/B 테스트의 두 그룹 간에 반응이나 선호도에 차이가 있다는 것을 의미합니다.
- 독립성 여부: p-값이 유의 수준보다 크면, 두 변수 간에 유의미한 연관성이 없다고 결론지을 수 있습니다. 즉, A/B 테스트의 두 그룹이 서로 독립적인 반응을 보인다고 볼 수 있습니다.
A/B 테스트에서 카이제곱 검정은 주로 클릭률, 구매 여부, 사용자 선호도와 같은 범주형 데이터를 분석하는 데 사용되며, 두 그룹 간의 차이가 우연에 의한 것인지, 아니면 통계적으로 유의미한 차이인지를 판단하는 데 중요한 도구입니다.
물론이죠. 카이제곱 검정을 A/B 테스트에 적용하는 구체적인 예시를 통해 설명해 드리겠습니다.
4-4). 카이제곱 검정의 적용 예시
-
클릭률 (Click-Through Rate, CTR):
- 상황: 웹사이트에 두 가지 다른 광고 디자인(A와 B)을 테스트하고 있습니다.
- 목표: 각 디자인이 사용자의 클릭률에 미치는 영향을 평가하고자 합니다.
- 데이터 구조: 2x2 분할표를 사용하여, 각 그룹(A와 B)에서 클릭했거나 클릭하지 않은 사용자 수를 기록합니다.
- 분석: 카이제곱 검정을 사용하여 두 광고 디자인이 클릭률에 유의미한 차이를 가져오는지 분석합니다.
-
구매 여부 (Purchase Decision):
- 상황: 온라인 스토어에서 두 가지 다른 프로모션 전략(A와 B)을 시험하고 있습니다.
- 목표: 각 프로모션 전략이 구매 결정에 어떤 영향을 미치는지 알아보고자 합니다.
- 데이터 구조: 각 그룹(A와 B)에서 구매한 사용자와 구매하지 않은 사용자의 수를 2x2 분할표로 정리합니다.
- 분석: 카이제곱 검정을 통해 두 프로모션 전략 간에 구매 결정에 대한 차이가 통계적으로 유의미한지를 평가합니다.
-
사용자 선호도 (User Preference):
- 상황: 두 가지 다른 웹사이트 레이아웃(A와 B)에 대한 사용자의 선호도를 조사합니다.
- 목표: 어떤 레이아웃이 사용자에게 더 선호되는지 파악하고자 합니다.
- 데이터 구조: 사용자에게 두 레이아웃 중 어떤 것을 더 선호하는지 물어본 후, 그 결과를 2x2 분할표에 기록합니다.
- 분석: 카이제곱 검정을 사용하여 두 레이아웃에 대한 사용자의 선호도에 통계적으로 유의미한 차이가 있는지를 검증합니다.
이러한 예시들에서 카이제곱 검정은 각 경우에 대한 두 그룹(A와 B) 간의 차이가 우연히 발생한 것인지, 아니면 실제로 통계적으로 유의미한 차이인지를 판단하는 데 사용됩니다.
5. 가설 검정 방식
A/B 테스트에서 가설 검정은 실험 결과가 우연에 의한 것인지 아니면 통계적으로 유의미한 차이를 나타내는지를 결정하는 데 사용됩니다.
가설 검정은 주로 양측 검정(Two-tailed test)과 단측 검정(One-tailed test) 두 가지로 나뉩니다.
5-1). 양측 검정 (Two-tailed Test)
- 목적: 두 그룹 간의 성과가 서로 다른지 여부를 확인합니다. 이는 A 그룹이 B 그룹보다 더 좋거나 혹은 더 나쁠 수 있는 모든 가능성을 고려합니다.
- 가설 설정:
- 귀무가설 (( H_0 )): 두 그룹 간에 차이가 없다 (예: ( \mu_A = \mu_B )).
- 대립가설 (( H_1 )): 두 그룹 간에 차이가 있다 (예: ( \mu_A \neq \mu_B )).
- 해석: p-값이 유의 수준보다 작으면, 두 그룹 간의 차이가 통계적으로 유의미하다고 할 수 있습니다. 여기서, 유의미한 차이는 A 그룹이 B 그룹보다 더 나은 성과를 보이거나 혹은 더 나쁜 성과를 보이는 것 모두를 포함합니다.
5-2). 단측 검정 (One-tailed Test)
- 목적: 한 방향으로의 차이만을 검증합니다. 예를 들어, A 그룹이 B 그룹보다 더 나은 성과를 보일 것이라는 특정 방향의 가설을 검정합니다.
- 가설 설정:
- 귀무가설 (( H_0 )): A 그룹의 성과가 B 그룹보다 나쁘거나 같다 (예: ( \mu_A \leq \mu_B )).
- 대립가설 (( H_1 )): A 그룹의 성과가 B 그룹보다 낫다 (예: ( \mu_A > \mu_B )).
- 해석: p-값이 유의 수준보다 작으면, 미리 정한 방향으로의 차이가 통계적으로 유의미하다고 할 수 있습니다. 이 경우, 검정은 더 구체적인 방향성을 가지고 있기 때문에, 양측 검정보다는 더 강한 주장을 할 수 있습니다.
5-3). A/B 테스트에서의 적용
- 양측 검정의 적용: A/B 테스트에서는 일반적으로 양측 검정이 사용됩니다. 이는 두 그룹 간에 어떤 차이가 있는지, 그리고 그 차이가 유의미한지를 확인하는 데 중점을 둡니다.
- 단측 검정의 적용: 특정한 방향의 효과를 예측하는 경우 단측 검정을 사용할 수 있습니다. 예를 들어, 새로운 광고 캠페인이 기존 캠페인보다 더 나은 성과를 낼 것이라고 예측하는 경우에 적합합니다.
가설 검정은 A/B 테스트의 결과를 해석하는 데 중요한 도구로, 실험적 조치가 실제로 효과가 있는지, 아니면 단순한 우연에 의한 것인지를 구분하는 데 사용됩니다.
5-4). 검정 예시
(1). 양측 검정 (Two-tailed Test) 예시
상황: 웹사이트에서 두 가지 다른 버튼 디자인(A와 B)을 테스트하고 있으며, 클릭률을 측정하고 있습니다.
- 귀무가설 (( H_0 )): A 버튼과 B 버튼의 클릭률은 동일하다 (( \mu_A = \mu_B )).
- 대립가설 (( H_1 )): A 버튼과 B 버튼의 클릭률은 다르다 (( \mu_A \neq \mu_B )).
- 결과 해석: 통계적 검정을 통해 얻은 p-값이 0.05보다 작으면, 두 버튼 디자인 간의 클릭률 차이가 통계적으로 유의미하다고 볼 수 있습니다. 이 경우, 클릭률이 높은 것이 낮은 것보다 우수하거나 그 반대일 수 있습니다.
(2). 단측 검정 (One-tailed Test) 예시
상황: 동일한 웹사이트에서, 새로운 버튼 디자인(A)이 기존 디자인(B)보다 클릭률을 증가시킬 것이라고 가정하고 있습니다.
- 귀무가설 (( H_0 )): A 버튼의 클릭률은 B 버튼보다 낮거나 같다 (( \mu_A \leq \mu_B )).
- 대립가설 (( H_1 )): A 버튼의 클릭률은 B 버튼보다 높다 (( \mu_A > \mu_B )).
- 결과 해석: 통계적 검정에서 p-값이 0.05보다 작으면, A 버튼이 B 버튼보다 클릭률이 높다는 가설을 지지합니다. 이 경우, 결과 해석은 클릭률이 더 높은 쪽으로만 한정됩니다.
(3). 검정 예시 그래프
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
# 정규 분포의 PDF 생성
x = np.linspace(-4, 4, 1000)
y = stats.norm.pdf(x, 0, 1)
# 양측 검정의 유의 영역
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(x, y, label="Normal Distribution")
plt.fill_between(x, y, where=np.abs(x)>1.96, color='orange', alpha=0.5)
plt.title("Two-tailed Test")
plt.xlabel('Z Score')
plt.ylabel('Probability Density')
plt.axvline(x=-1.96, color='red', linestyle='--')
plt.axvline(x=1.96, color='red', linestyle='--')
plt.text(2, 0.05, 'Critical Region', horizontalalignment='center', color='red')
plt.text(-2, 0.05, 'Critical Region', horizontalalignment='center', color='red')
plt.legend()
# 단측 검정의 유의 영역
plt.subplot(1, 2, 2)
plt.plot(x, y, label="Normal Distribution")
plt.fill_between(x, y, where=x>1.64, color='blue', alpha=0.5)
plt.title("One-tailed Test")
plt.xlabel('Z Score')
plt.axvline(x=1.64, color='green', linestyle='--')
plt.text(2, 0.05, 'Critical Region', horizontalalignment='center', color='green')
plt.legend()
plt.tight_layout()
plt.show()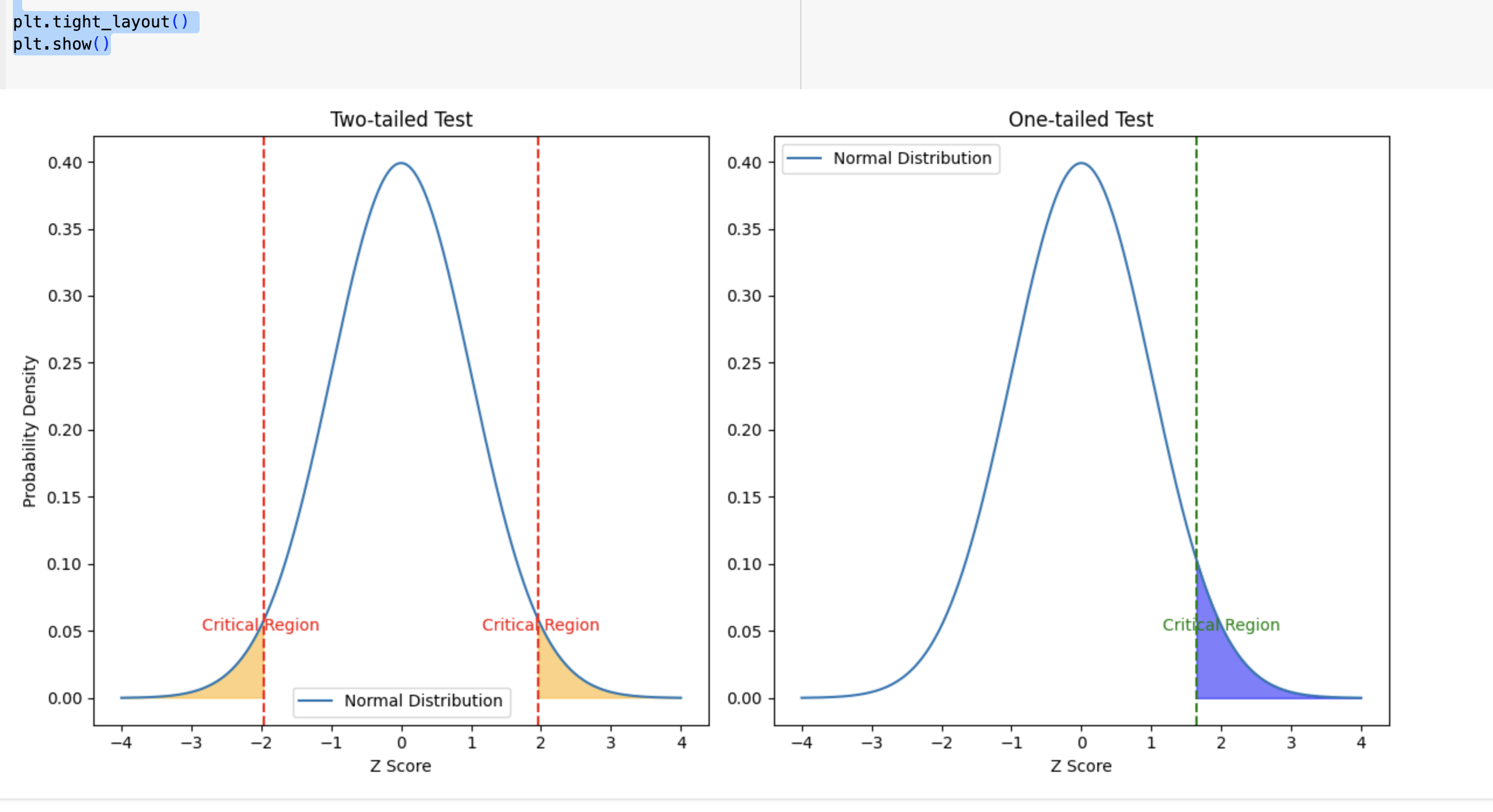
위 그래프는 양측 검정과 단측 검정의 유의 영역을 보여줍니다.
양측 검정 (Two-tailed Test)
- 그래프 (왼쪽): 정규 분포에서, 양 끝의 "Critical Region"은 양측 검정의 유의 영역을 나타냅니다. 여기서는 Z 점수가 -1.96보다 작거나 1.96보다 큰 경우를 유의미하다고 판단합니다.
- 해석: 이 영역은 두 그룹 간에 차이가 있을 때, 그 차이가 양 방향 모두에서 통계적으로 유의미할 수 있음을 나타냅니다.
단측 검정 (One-tailed Test)
- 그래프 (오른쪽): 여기서는 오른쪽 끝의 "Critical Region"만을 고려합니다. 이 경우 Z 점수가 1.64보다 큰 경우를 유의미하다고 판단합니다.
- 해석: 단측 검정은 특정 방향으로의 차이만을 고려합니다. 이 예시에서는 Z 점수가 높은 방향으로의 유의미한 차이를 검사합니다.
양측 검정은 양방향 모두에서 차이를 고려하는 반면, 단측 검정은 한 방향으로의 차이만을 검사합니다. 이는 A/B 테스트의 목적과 가설에 따라 선택되어야 합니다.
6. Type I Error & Type II Error (1종오류 & 2종오류)
P-Value가 가설에 대한 의사결정에 결정적인 고정 지표는 아닙니다.
P-Value 또한 전체모수가 아닌 표본에서 계산된 값이며 항상 결과에 대한 오차가 발생할 수 있으며 이 오차로 오류가 발생할 가능성이 있습니다.
A/B 테스트에서 1종 오류(Type I error)와 2종 오류(Type II error)는 통계적 가설 검정에서 발생할 수 있는 두 가지 주요 오류 유형입니다.
6-1). 1종 오류 (Type I Error)
- 정의: 1종 오류는 귀무가설이 사실일 때 이를 잘못 기각하는 오류입니다. 즉, 실제로는 차이가 없는데 차이가 있다고 잘못 결론지을 때 발생합니다.
- 표현: "False Positive"라고도 불립니다.
- 유의 수준과의 관계: 1종 오류의 확률은 유의 수준(α)으로 설정됩니다. 예를 들어, 유의 수준이 0.05인 경우, 1종 오류를 범할 확률은 5%입니다.
예시
- 상황: 웹사이트에서 A/B 테스트를 실시하여 새로운 레이아웃(B)이 기존 레이아웃(A)보다 더 나은 성과를 보인다고 결론지었습니다.
- 1종 오류 발생: 사실상 두 레이아웃 간에 성과 차이가 없음에도 불구하고, 통계적 검정 결과 이를 잘못해서 B 레이아웃이 더 나은 것으로 잘못 판단한 경우입니다.
6-2). 2종 오류 (Type II Error)
- 정의: 2종 오류는 귀무가설이 거짓일 때 이를 잘못 채택하는 오류입니다. 즉, 실제로는 차이가 있는데 차이가 없다고 잘못 결론지을 때 발생합니다.
- 표현: "False Negative"라고도 불립니다.
- 통계적 검정력과의 관계: 2종 오류의 확률은 (1 - 검정력)로 표현됩니다. 여기서 검정력은 대립가설이 사실일 때 이를 올바르게 인식할 확률입니다.
예시
- 상황: 동일한 A/B 테스트에서 새로운 레이아웃(B)과 기존 레이아웃(A)을 비교했습니다.
- 2종 오류 발생: 사실상 B 레이아웃이 A 레이아웃보다 더 나은 성과를 보이지만, 통계적 검정 결과 이를 인식하지 못하고 두 레이아웃 간에 차이가 없다고 잘못 결론지은 경우입니다.
1종 오류와 2종 오류는 통계적 검정에서 서로 상충하는 관계에 있습니다. 일반적으로 1종 오류의 확률을 줄이면 2종 오류의 확률이 증가하고, 반대로 2종 오류의 확률을 줄이려면 1종 오류의 확률이 증가합니다. 따라서 A/B 테스트를 설계할 때는 이 두 오류 사이의 균형을 고려해야 합니다.
6-3). 예시 그래프
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
# 정규 분포 설정
mu1, mu2 = 0, 2 # 두 정규 분포의 평균
sigma = 1 # 표준 편차는 동일하다고 가정
x = np.linspace(-4, 6, 1000)
y1 = stats.norm.pdf(x, mu1, sigma)
y2 = stats.norm.pdf(x, mu2, sigma)
# 1종 오류와 2종 오류 영역 표시
critical_value = stats.norm.ppf(0.95, mu1, sigma) # 유의 수준 0.05에서의 임계값
plt.figure(figsize=(12, 6))
# 1종 오류 (False Positive)
plt.fill_between(x, y1, where=(x > critical_value), color="orange", alpha=0.5, label="Type I Error (False Positive)")
plt.plot(x, y1, label="Null Hypothesis (True)", color="blue")
# 2종 오류 (False Negative)
plt.fill_between(x, y2, where=(x < critical_value), color="green", alpha=0.5, label="Type II Error (False Negative)")
plt.plot(x, y2, label="Alternative Hypothesis (True)", color="red")
plt.axvline(x=critical_value, color='black', linestyle='--', label=f"Critical Value (Z = {critical_value:.2f})")
plt.legend()
plt.title("Type I and Type II Errors in Hypothesis Testing")
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.show()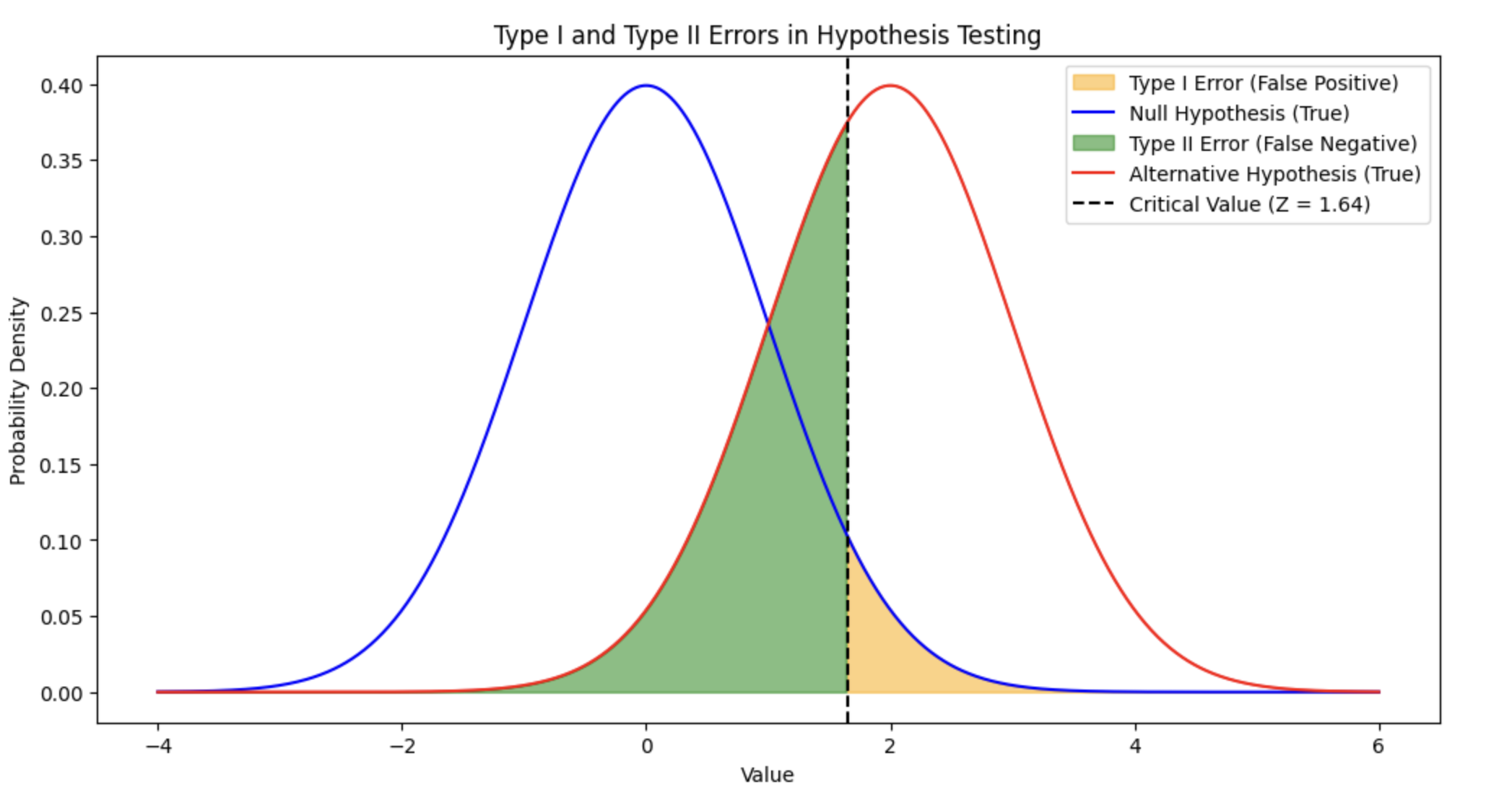
위 그래프는 1종 오류(Type I Error)와 2종 오류(Type II Error)를 시각적으로 보여줍니다.
- 파란색 곡선: 귀무가설이 사실일 때의 분포를 나타냅니다.
- 빨간색 곡선: 대립가설이 사실일 때의 분포를 나타냅니다.
- 주황색 영역: 1종 오류의 영역입니다. 이 영역은 귀무가설이 사실임에도 불구하고 잘못 기각하는 경우를 나타냅니다.
- 녹색 영역: 2종 오류의 영역입니다. 이 영역은 대립가설이 사실임에도 불구하고 잘못 채택하지 못하는 경우를 나타냅니다.
- 검은색 점선: 임계값을 나타냅니다. 이 값은 귀무가설을 기각하는 데 사용되는 경계를 정의합니다.
이 그래프를 통해, 1종 오류와 2종 오류가 어떻게 발생하고 서로 상충할 수 있는지를 이해할 수 있습니다. A/B 테스트에서 이러한 오류들을 최소화하는 것이 중요합니다.
실험계획
1. 1Pager 작성가이드
1). 대상 사용자 (Target User)
- 예시: 웹사이트의 젊은 성인 사용자 (18-35세)
2). 관찰 (Observation)
- 예시: 이 대상 사용자 그룹은 웹사이트의 메인 페이지에서 머무는 시간이 짧고, 클릭률이 낮다.
3). 문제 진술 (Problem Statement)
- 예시: 메인 페이지의 현재 디자인은 젊은 성인 사용자의 참여를 높이기에 충분히 효과적이지 않다.
4). 벤치마크 (Benchmarks)
- 예시: 유사 웹사이트의 젊은 성인 대상 평균 클릭률은 5%, 페이지당 평균 머문 시간은 3분이다.
5). 가설 (Hypothesis)
- 예시: 메인 페이지에 동적 요소와 강렬한 색상을 추가하면 젊은 성인 사용자의 참여를 증가시킬 수 있다.
6). 실험 그룹 (Experiments Group)
- 예시:
- A 그룹 (대조군): 현재 메인 페이지 디자인을 유지
- B 그룹 (실험군): 동적 요소와 강렬한 색상을 추가한 메인 페이지 디자인
7). 메트릭 (Metric)
- 예시: 메인 페이지의 클릭률과 페이지당 평균 머문 시간
8). 트레이드오프 (Trade-off)
- 예시: 새로운 디자인은 더 많은 참여를 유도할 수 있지만, 일부 사용자에게는 혼란스럽거나 부담스러울 수 있다.
9). 안돈 (Andon)
- 예시: 만약 새로운 디자인이 페이지 성능 문제를 일으키거나 사용자 불만이 급증한다면, 실험을 즉시 중단할 것.
2. 집단 크기 설정
A/B 테스트에서 집단 크기(샘플 크기) 설정은 실험의 유효성과 정확성을 결정하는 중요한 요소입니다. 집단 크기가 적절하게 설정되어야 통계적으로 유의미한 결과를 얻을 수 있습니다.
1).집단 크기 설정의 중요성
- 통계적 검정력: 충분한 샘플 크기는 테스트가 실제 차이를 감지할 수 있는 충분한 검정력을 가지게 합니다.
- 유의 수준과 오류율: 적절한 샘플 크기는 1종 오류(귀무가설이 참인데 기각하는 오류)와 2종 오류(대립가설이 참인데 받아들이지 않는 오류)의 균형을 잡는 데 도움이 됩니다.
- 결과의 일반화 가능성: 더 큰 샘플 크기는 일반 인구에 대한 결과의 일반화 가능성을 높입니다.
2). 집단 크기 결정 방법
-
기본 고려 사항:
- 기대되는 효과의 크기: 더 작은 효과를 감지하려면 더 큰 샘플 크기가 필요합니다.
- 유의 수준(α): 일반적으로 0.05로 설정합니다.
- 검정력(1-β): 통상적으로 0.8 또는 0.9를 목표로 합니다.
- 변동성 또는 표준 편차: 예상되는 결과의 변동성이 클수록 더 큰 샘플 크기가 필요합니다.
-
샘플 크기 계산기 사용:
- 샘플 크기 계산기 또는 통계 소프트웨어를 사용하여 필요한 샘플 크기를 추정할 수 있습니다.
3). 예시
- 상황: 웹사이트의 새로운 레이아웃(A)이 기존 레이아웃(B)보다 사용자 참여를 10% 더 증가시킬 것으로 예상합니다.
- 목표: 유의 수준 0.05와 검정력 0.8로 설정하여 샘플 크기를 결정합니다.
- 계산: 기존 데이터를 바탕으로 사용자 참여의 표준 편차를 추정하고, 이를 샘플 크기 계산기에 입력합니다. 결과적으로, 각 그룹(A와 B)에 대해 약 500명의 사용자가 필요하다고 추정됩니다.
이 예시처럼, 집단 크기를 설정할 때는 기대되는 효과의 크기, 유의 수준, 검정력, 그리고 결과의 변동성을 고려해야 합니다. 이를 통해 A/B 테스트의 결과가 통계적으로 유의미하고 신뢰할 수 있는지 확인할 수 있습니다.
A/B 테스트에서 최소 샘플 크기를 결정하기 위한 공식은 다음 요소들을 고려합니다: 효과 크기(effect size), 통계적 검정력(power), 유의 수준(significance level), 그리고 결과의 표준 편차입니다. 일반적인 공식은 다음과 같습니다:
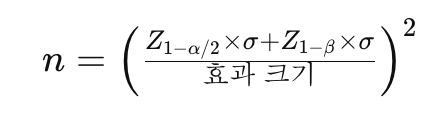
여기서:
- ( n )은 각 집단(대조군과 실험군)에 필요한 최소 샘플 크기입니다.
- ( Z{1-\alpha/2} )은 유의 수준 (\alpha)에서 양측 검정의 임계값입니다. 예를 들어, (\alpha = 0.05)일 경우 ( Z{1-0.05/2} )는 1.96입니다(표준 정규 분포에서).
- ( Z{1-\beta} )는 검정력 (1-\beta)에서의 임계값입니다. 예를 들어, 검정력이 0.8이면 ( \beta = 0.2 )이고, ( Z{1-0.2} )는 대략 0.84입니다.
- ( \sigma )는 결과의 표준 편차입니다.
- "효과 크기"는 예상되는 평균 차이입니다.
이 공식은 두 가지 중요한 가정을 합니다: 데이터는 정규 분포를 따르며, 두 집단의 표준 편차가 동일합니다. 실제 상황에서는 이러한 가정이 항상 유효하지 않을 수 있으므로, 샘플 크기 계산 시 주의가 필요합니다.
