
생각하는 코드, 구조화된 대화
개발하면서 늘 느끼는게 있다. 주어진 상황을 면밀하게, 구조적으로 파악하는 일이 정말 중요하다는 점이다. 상황을 잘 파악한다는 건 단순히 "지금 뭘 하고 있지?"를 아는 게 아니다. 예를 들어보자. 우리가 앱을 만들고 있는데, 특정한 사용자가 특정한 앱을 사용하고 있다고 해보자. 이건 그냥 기능을 구현하는 문제가 아니다. "지금 이 사람이 왜 이 화면에 있고, 무슨 의도로 버튼을 눌렀을까?" 같은 맥락적 질문이 뒤따른다.
결국 개발이란, "문제 해결 과정 전체를 상상해보는 일"이기도 하다.
그저 손만 움직여 코드를 짜는 게 아니라, 지금 무엇을 위해, 왜 이 로직이 필요한지 스스로 설명할 수 있어야 한다. 이건 곧 구조를 정의하는 힘과 맞닿아 있다. "일단 해보고 고친다"는 방식도 좋다. 하지만 무작정 해보는 것보다는, 좋은 문제 해결 방식을 정형화해두는 것이 더 나은 결과를 만든다.
그 기준이 되는 건 결국 맥락의 파악이다. 그리고 이 맥락은 세 가지 요소로 나눠볼 수 있다.
- 상황 : 어떤 화면, 어떤 상태인지
- 주체 : 어떤 사용자인지
- 이벤트 : 어떤 행동이 발생했는지
이 세가지를 기준으로 사고하면, 화면 이동 하나, 버튼 클릭 하나조차 명확한 구조로 설명할 수 있다.
예를 들어, 우리가 '사용자 화면 이력'을 히스토리로 저장한다고 치자. 이건 단순한 기록이 아니라, "미시적인 맥락에서 스택을 쌓겠다"는 선언이다. 왜냐하면 우리는 묻고 있기 때문이다. "지금 어떤 일이 벌어지고 있는가?", "왜 그런가?", "무엇이 문제인가?", "우리는 무엇을 해야 하는가?" 이렇게 맥락을 정의하고 나면, 자연스럽게 데이터 구조와 타입도 달라진다. 예컨대 특정 화면에서 발생하는 이벤트는 (화면 이름, 사용자 ID, 이벤트 타입)처럼 정의할 수 있다.
그리고 이러한 구조는 코드만을 위한 것이 아니다. 컴퓨터와의 소통이기도 하고, 기획자, 디자이너, 다른 개발자와의 소통이기도 하며, 무엇보다 미래의 나 자신과의 소통이기도 하다. 잘 말하는 건 중요하지 않다. "알아듣게 말하는 것", 그리고 "잘 알아듣는 것"이 훨씬 중요하다. 그런 의미에서 구조화는 단순한 기술이 아니다. 소통을 위한 언어 설계다. 결국, 좋은 구조는 좋은 소통을 낳고, 좋은 소통은 더 나은 문제 해결로 이어진다. 이건 너무 자명한 이치다. 그리고 우리가 소프트웨어를 만드는 건, 곧 이런 자명한 이치를 의식적으로 실천하는 과정 아닐까.
ADT
앞서 우리는 개발에서 중요한 개념이 '상황, 주체, 이벤트'라는 세 가지 요소라는 점을 이야기했다. 그렇다면 이걸 코드로 어떻게 깔끔하고 명확하게 표현할 수 있을까? 특히 '상황'과 '이벤트'가 다양할 때 타입 안정성과 가독성을 동시에 높이려면? 결론은 ADT(Algebraic Data Type)을 잘 활용하는 것이다. ADT는 이름이 다소 수학 같지만, 사실 여러 타입을 조합해 더 복잡한 타입을 만드는 기법이다. 크게 두 가지가 있다.
첫 번째는 Sum Type(합 타입)이다. OR 관계로, 여러 타입 중 하나만 선택된다. Kotlin의 sealed class나 enum class가 여기에 속한다.
// Option – 값이 있거나( Some ) 없거나( None )
sealed class Option<out T> {
object None : Option<Nothing>()
data class Some<T>(val value: T) : Option<T>()
}
// Either – 좌(Left) 혹은 우(Right)
sealed class Either<out L, out R> {
data class Left<L>(val value: L) : Either<L, Nothing>()
data class Right<R>(val value: R) : Either<Nothing, R>()
}
// Result – 예외를 포장
fun getLengthSafe(input: String?): Result<Int> =
runCatching { input!!.length }
val result = getLengthSafe(null)
result
.onSuccess { println("Length: $it") }
.onFailure { println("Error: ${it.message}") }위와 같은 Either, Result, Option 같은 타입들도 여기에 속한다.
두 번째는 Product Type(곱 타입)이다. AND 관계로, 여러 값을 모두 품고 있는 하나의 묶음이다. Kotlin의 data class가 해당된다.
data class User(
val id: Long,
val name: String,
val email: String
)결국, Sum Type으로 "경우의 수"를 한정하고 Product Type으로 "데이터 묶음"을 정의해 조합하면 대부분의 복잡한 구조를 표현할 수 있다. 이게 ADT의 핵심이다.
ADT가 가장 빛을 발하는 순간은 상태가 명확히 정해져 있는 도메인을 모델링할 때다. 도메인 모델링이란 현실 세계의 개념을 코드로 명확하게 옮기는 작업인데, 상태가 정해져 있다는 건 객체가 가질 수 있는 모양(경우의 수)이 미리 정의되어 있다는 뜻이다.
예를 들어 로그인 화면 상태가 다음 세 가지뿐이라고 하자.
- 로딩 중
- 성공적으로 로그인됨
- 오류 발생
이럴 땐 이렇게 선언한다.
sealed interface AuthState {
object Loading : AuthState
object Success : AuthState
data class Error(val message: String) : AuthState
}이렇게 하면 AuthState는 반드시 이 세 가지 중 하나다. when 구문에서 exhaustiveness 체크가 이루어지기 때문에 모든 경우를 빠짐없이 처리했는지 컴파일 타임에 검증된다. 실수도 자연히 줄어든다.
정리하자면, 상태가 명확하게 구분되고 그 외 상태는 존재하지 않도록 강제하고 싶다면 ADT만큼 든든한 도구가 없다. sealed와 data class를 적절히 엮어두면 타입 안전성과 가독성을 모두 챙긴 견고한 모델링이 가능하다.
Sealed Class, Sealed Interface
지금부터는 Sealed Class와 Sealed Interface에 대해 더 자세히 알아보자.
Sealed Class와 Sealed Interface가 상태가 정해져 있는 도메인을 모델링할 때 합 타입(Sum Type)을 표현하는 강력한 도구라는 것은 이미 알고 있을 것이다. 그렇다면, 이 둘은 도대체 어떻게 다르고 어떤 상황에 각각 적합한 걸까?
sealed class의 가장 큰 특징은 한마디로 단일 상속이다. 정확히는 단일 상속만 가능하다. 이 말은 다시 말하면, 하나의 상태가 하나의 클래스에 대응된다는 의미다. 예를 들어, Loading, Success, Error를 sealed class로 구성하면, 이 세 가지 상태는 결코 중첩될 수 없다. Loading이면서 동시에 Error일 수는 없다는 얘기다.
그런데 현실을 잘 살펴보면, 이와는 대비되는 경우가 꽤 많다. 가령, 서버에서 데이터를 가져오는 도중에 일부만 내려받다가 네트워크가 끊기는 상황이 있다고 하자. 이건 로딩 중이면서 동시에 에러 상태인 것이다. 이런 복합적인 상태는 sealed class만으로는 표현할 수 없다.
그래서 등장한 것이 sealed interface다.
sealed interface는 이름 그대로 인터페이스이기 때문에 여러 개를 동시에 구현할 수 있다. 예를 들어 아래처럼 상태를 설계할 수 있다:
sealed interface UiState
sealed interface Loading : UiState
sealed interface Error : UiState
sealed interface Success : UiState
data class Retryable(val progress: Int, val message: String) : Loading, Error
여기서 Retryable은 로딩 상태이면서 동시에 오류 상태다. 이처럼 두 상태를 조합해서 새로운 상태로 만들 수 있다. sealed class만 사용해서는 이런 표현이 불가능하다. 그리고 sealed interface 역시 when 구문에서 모든 상태를 다 처리했는지 컴파일러가 체크해주기 때문에 안전성은 그대로 유지된다.
이쯤 되면 이렇게 말할 수도 있다.
“그럼 그냥 sealed interface만 쓰면 되는 거 아닌가?”
근데 꼭 그렇지는 않다. sealed class는 필드나 메서드를 공통 구현으로 넣을 수 있다. 예를 들어, 각 상태마다 공통적으로 로그를 찍는다거나 하는 기능을 추상 함수로 만들고, 구현 클래스에서 각각 다르게 구현할 수 있다. 반면, sealed interface는 구조적으로 그런 기능 자체를 넣을 수가 없다.
정리하자면, 공통 기능이 필요하다면 sealed class, 여러 상태를 조합해야 하는 경우는 sealed interface. 좀 더 다시 정리해보면, sealed interface는 조합 가능한 상태 표현에 강하고, sealed class는 공통 로직과 단순한 상태 표현에 강하다.
Data Class, Val
다음으로는 ADT의 또 다른 중요한 축인 Data Class와 val에 대해 알아보자.
이 둘은 겉으로 보기에는 그냥 Kotlin 문법처럼 보이지만, ADT 관점에서는 굉장히 핵심적인 요소다. sealed class나 sealed interface가 “이 객체가 어떤 종류의 상태인지”를 표현할 수 있게 해줬다면, data class는 그 상태가 가지고 있는 값은 무엇인지 설명해준다.
예를 들어, 로딩은 그냥 로딩일 뿐이지만, 오류라면 “왜 실패했는지”, 성공이라면 “무엇을 성공적으로 가져왔는지”를 알아야 한다. 상태가 의미를 가지려면, 그 안에 실제 데이터가 있어야 한다는 것이다. 이걸 가장 잘 표현할 수 있는 도구가 바로 data class다.
sealed interface UiState
object Loading : UiState
data class Success(val data: String) : UiState
data class Error(val message: String) : UiState여기서 Success와 Error는 단순히 상태를 나타내는 걸 넘어서, 그 상태와 관련된 데이터까지 함께 묶어 표현한다. 이게 바로 ADT에서 말하는 곱 타입(Product Type)의 구조다.
그런데 여기서 중요한 한 가지. data class의 필드는 대부분 val로 선언한다. 왜 그런지 아는가? 불변성 때문이다. 불변성. 잘 생각해보자. 상태 표현에서 한 번 정의된 데이터는 바뀌지 않아야 한다. 왜? 상태의 의미는 "그 순간의 스냅샷"이기 때문이다.
만약 우리가 var로 상태를 정의했다면, 상태가 바뀌는 타이밍을 예측할 수 없게 된다. "지금 이 객체는 정말 '서버 연결 실패' 상태인가?", "언제 바뀔지도 모른다면, 이건 어떤 의미를 가지는 상태인가?" 이런 의문이 들 수밖에 없다. 이런 불확실성은 복잡한 시스템에서 매우 큰 오류의 원인이 된다. 반면 val은 그런 걱정을 없애준다. 상태를 한 번 만들면, 그 값은 변하지 않는다는 걸 보장해 준다.
이런 안정성 덕분에 data class는 sealed class와 함께 ADT를 표현하는 양대산맥이 되어버리는 것이다. 참고로 Kotlin의 data class는 그 자체로도 DTO 목적성을 갖고 만들어졌기 때문에 다음과 같은 기능들을 자동으로 제공한다.
- equals / hashCode — 값 비교가 된다
Error("a") == Error("a") → true - toString() — 디버깅이 편하다
Error("msg") 자체가 로깅 가능한 메시지가 된다 - copy() — 상태를 안전하게 복사해서 새로 만들 수 있다
이런 특성 덕분에 data class는 단순한 구조체 이상의 의미를 가진다. 상태를 담는 그릇이면서도, 새로운 상태를 안전하게 확장할 수 있는 기반이 된다.
ADT를 잘 쓴다는 건 결국 가능한 상태들을 sealed로 열거하고, 각 상태에 필요한 데이터를 data class로 표현하며, 각 필드를 val로 선언해 불변성을 지키는 것이다. 이렇게 만든 상태는 언제든 안전하게 전달되고, 기록되고, 비교되고, 추론될 수 있다. 이게 우리가 이번 시간에 배워야 할 Kotlin Point다.
마무리하자면, 우리는 data class와 val을 단순한 문법처럼 쓰지만, 사실 이 둘은 ADT의 곱 타입을 표현하는 데 없어서는 안 될 도구다. 어떤 상태가 무슨 정보를 포함해야 하는가에 대한 의문을 해소해주고, 그 정보가 절대 바뀌지 않는다는 걸 문법 차원에서 보장해준다. 이런 식의 설계는 코드를 안전하고 명확하게 만드는 기초보수 공사와도 같다. (물 샐 염려가 없어진다.) 앞서 다룬 sealed class가 "종류"를 표현했다면, 이제 우리는 data class와 val을 통해 "내용"까지 명확하게 모델링할 수 있게 됐다.
ADT는 그렇게 하나씩 퍼즐을 맞춰가며, 즐겁게 레고 놀이하듯이 코드를 만들 수 있게 도와주는 도구다.
이건 그냥 레고 놀이
ADT에 대해 어느 정도 감을 잡았다면, 다음으로 살펴볼 주제는 상태 머신과 명령 패턴이다. ADT를 써서 모델링을 하다 보면 결국 "상태를 표현 하고, 그 상태를 바꾸는 로직"을 설계하게 된다. 이때 이 두 개념이 굉장히 강력한 도구가 된다.
상태 머신이란 말 그대로 상태가 여러 개 존재하고, 어떤 이벤트나 조건에 따라 상태가 전이(Transition)되는 구조를 말한다. 우리가 앱을 만들다 보면 사용자의 상태나 앱의 화면 상태가 시간이나 인터랙션에 따라 바뀌는 일이 많다. 그걸 명시적으로 정의하고, 타입으로 안전하게 표현할 수 있는 게 바로 상태 머신이다.
예를 들어, 로그인 프로세스를 생각해보자. 앱을 실행했을 때, 먼저 로그인 여부를 확인한다.
- 로그인 안 되어 있으면 -> 로그인 화면으로
- 로그인 되어 있으면 -> 바로 메인 화면으로
여기서 이미 상태 전이가 한 번 일어난다. 그리고 메인 화면에 들어오면 유저는 여러 동작을 할 수 있다.
- 설정 버튼을 누르면 → 설정 화면으로 전환된다
- 알림 아이콘을 누르면 → 최근 알림 목록 화면이 푸시된다
- 프로필 이미지를 클릭하면 → 프로필 상세 정보가 랜덤한 테마로 표시된다
이 모든 게 상태의 흐름이고, 그 흐름 안에서 상태가 어떤 식으로 이동하는지를 코드로 정확하게 표현하고 싶을 때, sealed class나 sealed interfaace와 함께 쓰는 상태 머신 구조가 정말 강력해진다.
그리고 이 흐름 안에서 "사용자의 의도된 동작"을 더 명확하게 분리하고 싶을 때 등장하는 게 명령 패턴이다. 사용자가 어떤 행동을 했을 때 그걸 단순히 "함수 호출"로만 처리하면 나중에 복잡도가 확 올라간다. 그런데 이 동작 하나하나를 객체로 만들고, 실행하거나 취소하거나 기록할 수 있게 만든다면? 갑자기 앱의 구조가 훨씬 깔끔해진다.
예를 들어, 유저가 콘텐츠를 저장한다 → 이걸 SaveContentCommand로 만든다. 다음에 이 명령을 큐에 넣었다가 나중에 실행할 수도 있고, 실패하면 재시도할 수도 있다. 여기서도 sealed class를 활용하면 다양한 명령 객체를 타입 안전하게 다룰 수 있고, when 문으로 명령을 처리하는 로직도 일관되게 유지할 수 있다.
즉,
- 상태 머신은 상태와 그 전이를 구조적으로 모델링하는 방식이고
- 명령 패턴은 행동을 캡슐화해서 시스템의 동작 흐름을 유연하게 관리하는 방식이다
이 두가지는 sealed class나 data class와 같은 ADT 구조와 궁합이 너무 좋다. 정해진 상태를 나열하고, 그 상태에 필요한 데이터만 잘 묶어서 표현하고, 상태 간의 전이를 함수로 정의해두면, 어느 순간 "앱 전체 흐름이 자연스럽게 타입으로 설계된 구조" 안에 들어오게 된다. 명령 패턴은 이 흐름 위에서 "무엇을 할 것인가"를 객체 단위로 끼워 넣는 느낌이다.
정리하면, ADT를 잘 쓴다는 건 결국 상태와 데이터를 정리하는 것이고, 상태 머신과 명령 패턴은 이 정리된 구조 위에서 어떻게 바뀌고, 어떻게 동작할지를 안전하고 우아하게 설계할 수 있도록 도와주는 개념들이다.
앞으로 어떤 화면에서 어떤 일이 벌어지는지, 어떤 상태로 흘러가는지, 어떤 행동이 있었는지를 하나씩 모델링해보자. sealed class, sealed interface, data class, val, 그리고 상태 머신과 명령 패턴. 이 조합만으로도 꽤 많은 것들을 표현할 수 있게 된다. 마치 레고처럼, 잘 만든 파츠들이 자연스럽게 맞물려서 시스템 전체가 명확해진다.
MVI
이제 마지막으로 앱 아키텍쳐까지 한 번 건드려보자.
모바일 앱을 만들다 보면 결국엔 하나의 질문에 부딪힌다. 화면도 많고 비동기 작업도 많고 라이프사이클도 변덕스러운데, 이 복잡한 상태들을 어떻게 하면 덜 고생하고 관리할 수 있을까?
누군가 내린 결론은 이거다. 앱에 들어오는 이벤트를 전부 상태 머신으로 돌려보자. 상태 머신이면 생각보다 단순해진다. 지금 상태가 뭔지, 다음에 갈 수 있는 상태가 뭔지, 두 가지만 알면 되니까.
이 아이디어는 몇 가지 실익을 준다.
첫 번째로, 라이프사이클 때문에 머리 아플 일이 줄어든다. 백그라운드-포그라운드가 왔다 갔해도 상태 객체가 단일 소스로 남아 있으니 "지금 어디에 있었더라?"를 다시 계산할 필요가 없는 것이다. 상태 전이가 엄격하다는 전제 하에 데이터 꼬임도 확실히 줄어든다. 또, 한 화면에서 수정한 내용이 앱 전체에 즉시 반영된다. 상태를 한 군데에서만 보관하니, 다른 화면들은 그냥 그 상태를 구독하면 끝이다. 벨로그 같은 레거시 앱에서 흔히 보던 "저장은 됐다는데 왜 안 바뀌지?" 같은 현상이 사라진다.
이런 아이디어에서 나온 아키텍처가 바로 MVI다.
MVI의 기본 아이디어는 크게 세 축으로 구성된다. 첫째, 상태를 저장하는 부분. 보통 앞서 말한 것처럼 sealed class로 구현된다. 둘째, 상태 전이. 어떤 조건에서는 B로, 또 다른 조건에서는 C로 바뀌는 식의 규칙을 의미한다. 셋째, 로직 수행. 상태가 바뀌었을 때 실제로 실행되어야 할 동작들이다. 이 세 요소를 적절히 조합해서 단방향 파이프라인 형태로 만든 걸 MVI라고 부른다.
Flux와 Redux는 MVI 아이디어를 구현한 대표적인 라이브러리다. Flux는 페이스북에서 나온 단방향 루프 구조고, Redux는 이 개념을 더 단순하고 예측 가능하게 다듬은 버전이다. 이번엔 Redux를 예시 삼아 MVI 흐름이 실제로 어떻게 돌아가는지 같이 들여다보자.
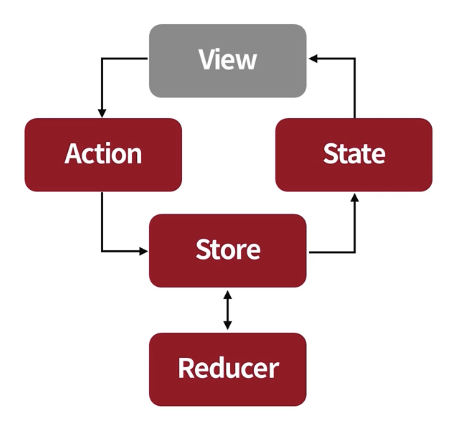
Redux 구조는 대략 위와 같다. 이제 하나씩 짚어보자.
먼저, 이벤트가 상태를 변경한다. 이걸 Action이라고 부른다. 예를 들면, 우리가 탭을 눌러서 메인 화면의 콘텐츠를 바꾸는 경우가 있다. 이 때 정확히는 탭을 눌렀을 때, Store에 그 이벤트를 전달하는 것까지가 Action의 역할이다. 그 이후에는 Store와 연결된 Reducer가 현재 상태를 받아서 새로운 상태로 변경해준다. 그리고 이 새로운 상태가 State로 뷰에 전달되어 반영되는 구조다.
이 네 가지 요소 중에 (혹은 뷰까지 포함하면 다섯 가지) 앞서 말한 상태 전이에 해당하는 부분은 어디일까?
Reducer다. Reducer는 추상적인 말로 “규칙”이다. 어떤 상태에서 어떤 이벤트가 들어오면 이런 규칙이 실행된다, 로 정의할 수 있다. 이런 식의 언어를 사용하면 UX 디자이너나 기획자와 소통할 때도 더 명확해진다. 서문에서도 말했듯이, 결국 생각하는 코드는 구조화된 대화로 이어진다.
다음으로 우리가 생각해봐야할 것은 앞서 얘기한 세 번째 부분. 로직 실행이다. 위 네가지 요소 중에 혹은 다섯가지 어디에서 로직 실행이 일어날까?
정답은 그 무엇도 아니다. 예를 들어, 사용자가 버튼을 눌러서 서버에 데이터를 요청하는 상황을 생각해보자. 이때 버튼 눌림은 액션(Action)이 되고, 상태를 바꾸는 건 리듀서(Reducer)의 역할이다. 그런데 서버 요청 같은 비동기 작업은 어디서 처리할까?
바로 여기서 미들웨어(Middleware)가 등장한다. 미들웨어는 액션이 리듀서에 도달하기 전에 그 액션을 가로채서, 서버에 요청을 보내거나 타이머를 작동시키는 등 부수적인 작업(사이드 이펙트)을 처리한다.
예를 들어, Redux Thunk 미들웨어를 쓰면 이렇게 할 수 있다:
// 액션 생성자 안에서 비동기 작업 수행
fun fetchUserData(userId: String) = thunkAction {
dispatch(showLoading())
val data = api.getUserData(userId)
dispatch(hideLoading())
dispatch(updateUserData(data))
}이렇게 하면 서버 요청은 미들웨어가 담당하고, 리듀서는 오직 상태 변경에만 집중할 수 있다. 이런 구조 덕분에 앱의 상태 관리가 훨씬 명확하고 유지보수가 쉬워진다.
이 과정에서 꼭 짚고 넘어가야 할 중요한 주제가 하나 있다. 바로 ‘이벤트의 취소’ 문제다. MVI에서는 Intent, 즉 사용자의 입력이 시스템 내부에서 하나의 이벤트로 해석되는데, 이 이벤트들이 비동기로 실행되고 실행 순서가 보장되지 않기 때문에 예상치 못한 문제가 발생할 수 있다.
예를 들어, 사용자가 검색창에 글자를 빠르게 여러 번 입력한다고 해보자. Search(query) 이벤트가 계속 들어가게 되는 건데, 각각의 이벤트는 서버에 요청을 보내고 응답을 기다린다. 그런데 나중에 입력한 쿼리보다 먼저 도착한 이전 쿼리 응답이 화면을 덮어씌운다면? 사용자는 “lego”를 검색했는데 화면에는 “leg” 결과가 뜨는 기현상이 생길 수 있다.
그래서 주요한 고민거리는 이거다. “이전에 보낸 요청을 어떻게 취소할 것인가?”, 혹은 “지금 상태에서 이전 이벤트는 무시해야 하지 않을까?”에 대한 기준을 잡는 것이다. 이게 은근히 어려운 문제다.
보편적인 해법은 크게 두 가지다.
첫 번째는 Job 관리다. (코루틴 기준이다.) 각 Intent가 실행되는 Job을 ViewModel이 기억하고 있다가, 새로운 Intent가 들어오면 이전 Job을 cancel()해버리는 방식이다. 예를 들면 다음과 같다:
var currentJob: Job? = null
fun onIntent(intent: Intent) {
currentJob?.cancel()
currentJob = viewModelScope.launch {
// 처리...
}
}두 번째는 이벤트 무시 전략이다. 이건 간단하다. 들어온 이벤트가 과거의 것이라면 그냥 무시하는 방식이다. 보통 응답이 왔을 때, 그게 가장 최근 쿼리인지 확인하고 아니라면 결과를 버린다. Flow를 쓴다면 flatMapLatest 한 줄로 끝낼 수도 있다.
더 나은 세상을 향하여
여기까지, 우리가 그동안 고민했던 것들을 어떻게 앱에 녹일 수 있을지를 정리해봤다.
우리는 종종 아무 생각 없이 코틀린 문법을 쓰지만,
그 뒤에는 나름 정교하게 설계된 논리들이 있다.
우리가 해야 할 일은 그 목소리를 듣고, 잘 판단하는 것이다.
각 문법이 무엇을 위해 존재하는지, 그 메시지를 듣고 결정을 내리는 우리는 일종의 CEO다.
책임감을 갖고, 명확한 구조와 소통을 위해 코드를 짜자.
더 나은 구조는 더 나은 소통을 만들고, 이 명확함은 결국 사용자들이 체감하게 된다.
몇몇 글에서도 언급했듯이, 우리는 세상을 바꾸는 손가락임을 잊지 말자.
오늘도 안드로이드 개발자, 화이팅.
