1. 틀린 코드
// 후위 표기식2
// const question = `1
// AA+A+
// 1`;
const question = `5
ABC*+DE/-
1
2
3
4
5`;
const fs = require("fs");
const input = (
process.platform === "linux"
? fs.readFileSync("/dev/stdin").toString()
: question
).split("\n");
// console.log(3 * 2 + 1 - 4 / 5);
//[A,B,C,*,+,D,E,/,-]
// B * C + A - D / E
let idx = 0,
nStack = [];
const strArr = input[1].split("");
const numArr = input.slice(2).map((n) => +n);
// console.log("strArr", strArr);
// console.log("numArr", numArr);
strArr.map((str) => {
let signal = "";
if (str === "+" || str === "-" || str === "*" || str === "/") {
signal = str;
} else {
nStack.push(numArr[idx] ? numArr[idx++] : numArr[--idx]);
}
// console.log(idx, nStack, signal);
if (signal && nStack.length > 1) {
let second = nStack.pop(),
first = nStack.pop();
if (signal === "+") {
nStack.push(first + second);
} else if (signal === "-") {
nStack.push(first - second);
} else if (signal === "*") {
nStack.push(first * second);
} else {
nStack.push(first / second);
}
signal = "";
}
});
// console.log("nStack", nStack);
console.log(nStack[0].toFixed(2));2. 맞은 코드
// 후위 표기식2
// const question = `1
// AA+A+
// 1`;
const question = `5
ABC*+DE/-
1
2
3
4
5`;
const fs = require("fs");
const input = (
process.platform === "linux"
? fs.readFileSync("/dev/stdin").toString()
: question
).split("\n");
const n = Number(input[0]);
const str = input[1];
const stack = [];
const alpha = [];
alpha.length = n;
const nums = [];
nums.length = n;
for (let i = 0; i < n; i++) {
nums[i] = Number(input[i + 2]);
}
// console.log(nums); //[ 1, 2, 3, 4, 5 ]
let cnt = 0;
for (let i = 0; i < str.length; i++) {
if (str[i].charCodeAt() >= 65) {
const alphaIndex = Number(str[i].charCodeAt() - 65);
if (!alpha[alphaIndex]) {
alpha[alphaIndex] = nums[cnt++];
}
stack.push(alpha[alphaIndex]);
continue;
}
// console.log(stack);
// [ 1, 2, 3 ]
// [ 1, 6 ]
// [ 7, 4, 5 ]
// [ 7, 0.8 ]
const operator = str[i];
const y = stack.pop();
const x = stack.pop();
switch (operator) {
case "+":
stack.push(x + y);
break;
case "-":
stack.push(x - y);
break;
case "*":
stack.push(x * y);
break;
case "/":
stack.push(x / y);
break;
}
}
console.log(stack.pop().toFixed(2));
3. 알고리즘 해결을 위해 필요한 개념정리
1. 유니코드란?
사람이 사용하는 모든 언어를 컴퓨터가 이해할 수 있는 bit로 표현된 숫자로 매핑 해놓은 표준이다.
{ 0x0041: 'A' }
='A'라는 글자는 0x0041이라는 Index를 가진다.
2. UTF란?
사람의 언어를 기계어로 변역해주는 과정을 인코딩이라고 하며,
UTF는 유니코드가 매핑해놓은 표를 보면서 문자열을 인코딩해주는 규칙이다.
UTF 뒤의 숫자는 몇 bit를 사용하여 Index를 표현할 것인가를 알려준다.
UTF-8= 8bit를 사용하여 1개의 Index를 표현한다.
UTF-16= 16bit를 사용하여 1개의 Index를 표현한다.
UTF-32= 32bit를 사용하여 1개의 Index를 표현한다.
3. ASCII란?
American standard code for information interchange code의 약자로 미국 표준 정보교환 코드로 컴퓨터 내부에서 문자를 표현하는데 사용됩니다.
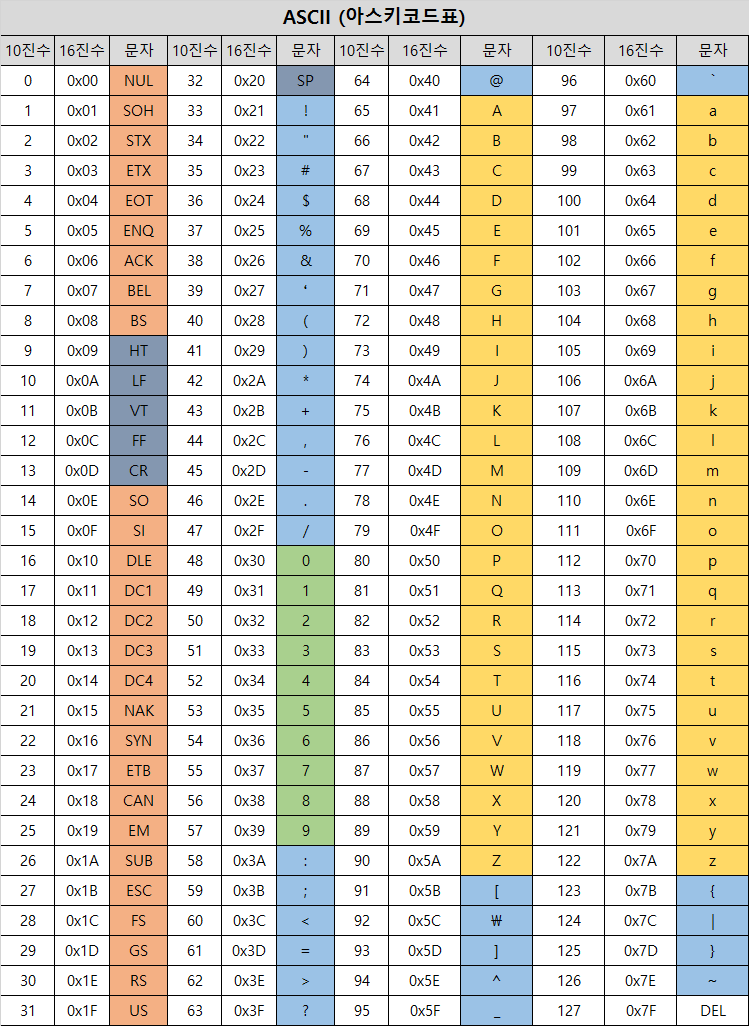
참고:
baekjoon 1935 후위 표기식2 참고 코드
https://raw.githubusercontent.com/Hong-been/Algorithm-study/master/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0/b1935.js
유니코드와 인코딩
https://goodgid.github.io/Unicode-And-UTF-Encoding/
charCodeAt()
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/String/charCodeAt
아스키코드
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=diceworld&logNo=220175224345
https://developer-p.tistory.com/72
