아키텍처 스타일 소개
아키텍처 스타일은 반복적으로 등장하는 소프트웨어 구조 유형을 추상화한 것으로,
구성 요소(Elements)와 이들 간의 관계(Relations) 및 제약 조건(Constraints)으로 정의됨.
- 예시: Layered Style

아키텍처 스타일은 소프트웨어 엔지니어가 품질 속성(QA: Quality Attribute)에 대해 논리적으로 사고하고 판단하는 데 도움을 줌

→ OOAD(Object-Oriented Analysis & Design) 과정 중에서 설계 초기에 스타일을 결정 w. Domain Model, System Sequence Diagram
→ 이어서, 이 스타일을 가지고 다양한 아키텍처 View (C&C View, Module View, Deployment View)를 작성
디테일한 내용은 2. Architecture style에서...
1. Quality Attributes
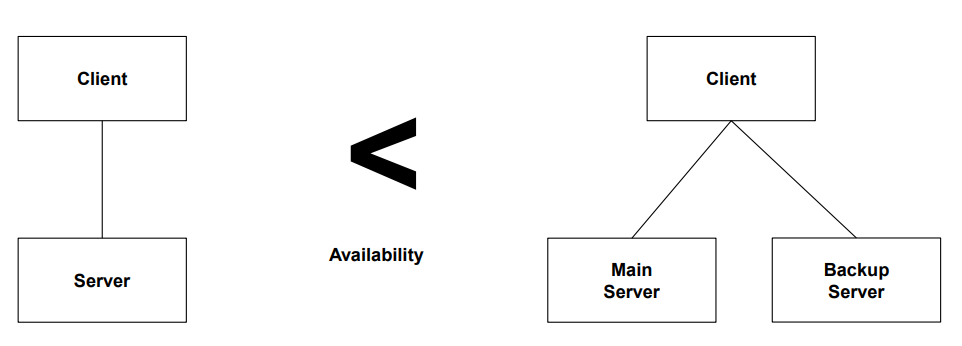
1.1 가용성 (Availability)
- 정의: 시스템이 언제든 요청에 대해 작동 가능한 상태로 존재하는 정도
- 예시: 미션 시작 시 시스템이 정상적으로 동작 중이어야 함
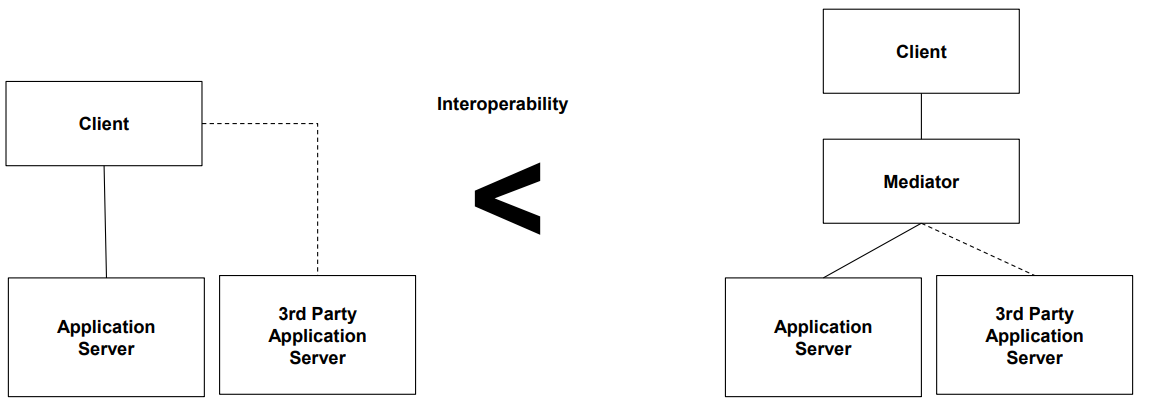
1.2 상호운용성 (Interoperability)
- 정의: 서로 다른 시스템이 의미 있는 정보를 주고받을 수 있는 능력
- 예시: 클라이언트 앱이 외부 서버나 제3자 앱과 문제없이 연동되는 구조
Interoperability vs Compatibility:
- Interoperability: 서로 다른 시스템이나 플랫폼 간에 정보를 주고받고 이를 효과적으로 활용할 수 있는 능력 (예: 스마트 홈 연동 시스템)
- Compatibility: 특정 시스템이나 환경 내에서 소프트웨어나 장치가 충돌 없이 정상적으로 동작할 수 있는 능력 (예: 하나의 프로그램이 다양한 운영체제에서 문제 없이 실행되는 경우)
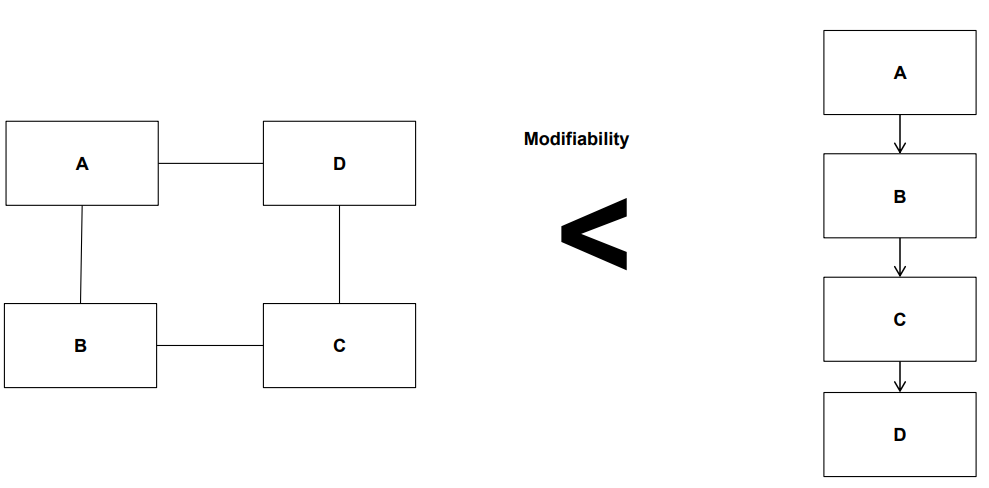
1.3 수정 용이성 (Modifiability)
- 정의: 시스템에 변경을 가할 수 있는 용이성
- 예시:
- 특정 모듈을 수정해도 다른 모듈에 영향이 없는 구조
- 각 컴포넌트 간 의존성이 낮은 구조가 유리
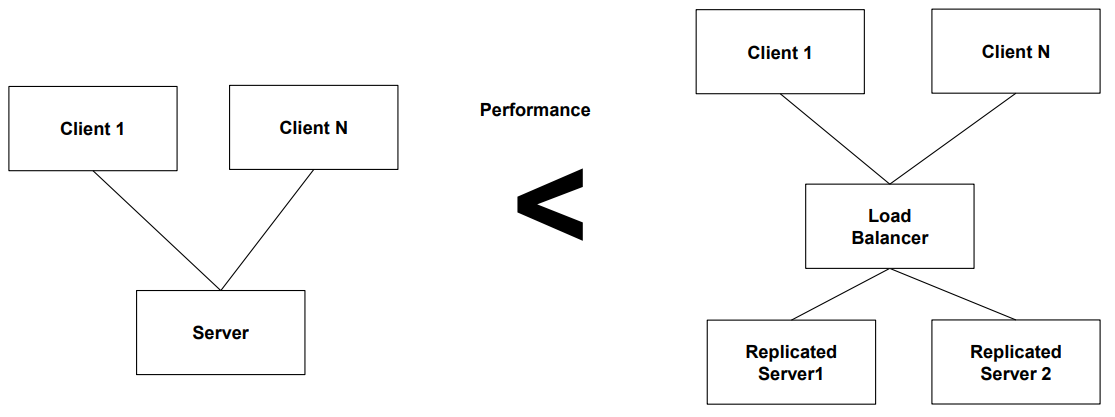
1.4 성능 (Performance)
- 정의: 이벤트 발생 시 시스템이 작업을 수행하는 시간
- 예시: 로드 밸런서(부하 분산 시스템), 병렬 서버 구조
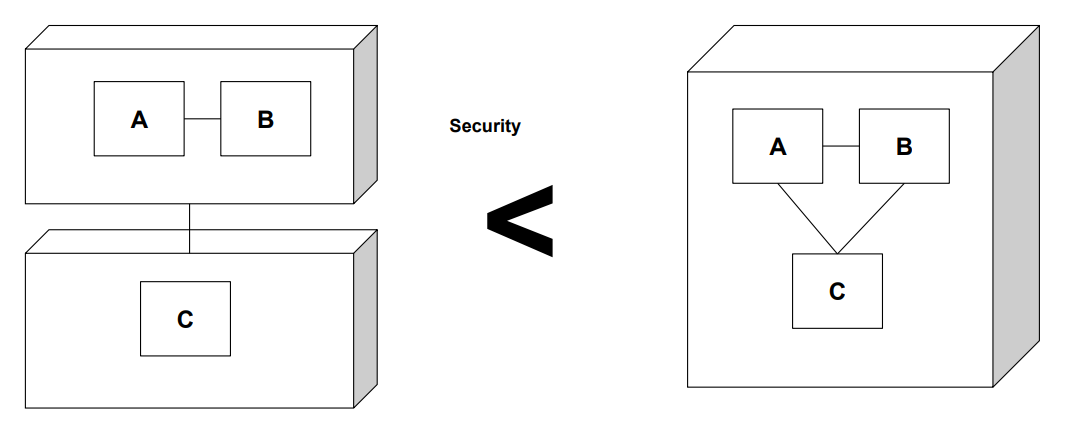
1.5 보안성 (Security)
- 정의: 시스템이 악의적 공격 및 정보 유출 위험을 방지하는 능력
- 예시: 단일 시스템화, 인증, 암호화, 접근 제어 등
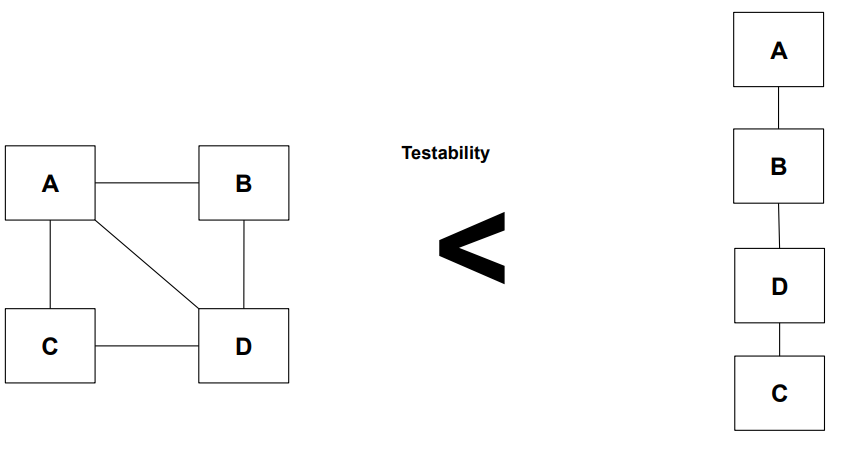
1.6 테스트 용이성 (Testability)
- 정의: 단위, 통합 테스트 용이성
- 예시: 유닛 단위로 테스트 가능한 구조, 독립성이 높은 컴포넌트
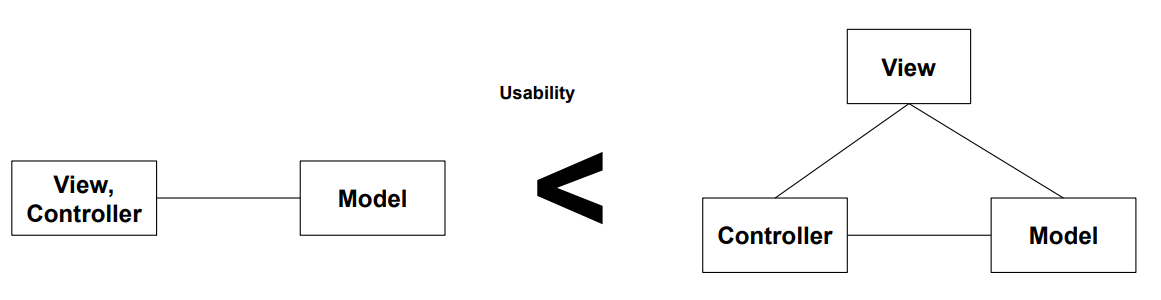
1.7 사용성 (Usability)
- 정의: 사용자가 원하는 작업을 쉽게 수행할 수 있는 정도
- 예시: 직관적인 UI, 명확한 피드백, 빠른 응답성
각 품질 속성은 아키텍처 설계 시 상충 관계가 존재할 수 있음
→ 어떤 속성을 우선할지에 따라 선택해야 할 아키텍처 스타일도 달라짐
2. Architecture style
아키텍처 스타일(Architectural Style): 유사한 구조를 갖는 소프트웨어 아키텍처들의 추상화
아키텍처 스타일은 다음으로 정의됨:
- 요소의 유형(Element Types)
- 요소 간의 관계(Relations)
- 구조 및 동작에 대한 제약 조건(Constraints)
- 아키텍처 스타일에는 완전하고, 유일하며, 서로 겹치지 않는 건 없음
→ 일부 스타일은 서로 중첩되기도 함 - 하나의 시스템은 동시에 여러 가지 스타일을 나타낼 수 있음
→ 현실의 시스템은 보통 단일한 스타일만 사용하는 것이 아니라, 상황에 따라 다양한 스타일이 혼합되어 사용됨 - 하나의 아키텍처 스타일은 여러 품질 속성에 긍정 또는 부정적인 영향을 줄 수 있음
→ 아키텍트가 서로 상충되는 스타일들을 잘 혼합하여 우선순위 별 QA를 만족하는 최적의 설계안을 도출해낼 수 있음
아키텍처 스타일 분류표 (Architectural Style Categories)
Garlan and Shaw compiled a catalog of architectural styles in 1995
| Category | Style | Sub-style |
|---|---|---|
| Data Flow | Batch Sequential | |
| Pipe and Filter | ||
| Process Control | ||
| Data Centered | Shared Repository | |
| Blackboard | ||
| Implicit Invocation | Event Based | |
| Message Based | ||
| Interaction-Oriented | Model-View-Controller (MVC) | |
| Presentation-Abstraction-Control (PAC) | ||
| Hierarchical | Main-Subroutine | |
| Master-Slave | ||
| Layered | Virtual Machine, Microkernel | |
| Distributed | Multi-tier | Client-Server |
| Broker | Dispatcher | |
| Service-Oriented | Microservice | |
| Edge-Based |
2.1 데이터 흐름 아키텍처 (Data Flow Architecture
- 정의
- 데이터를 순차적으로 변환하며 흐르게 하는 구조로, 각 컴포넌트는 입력을 받아 출력으로 변환하고, 데이터 전달은 채널을 통해 이루어짐.
- 구성 요소:
- Component(Data Transformer): 데이터를 변환하는 모듈
- Connector(Data Channel): 컴포넌트 간 데이터 전달 모듈
- 스타일 선택 가이드
상황 적합한 아키텍처 스타일 문제를 순차적인 단계로 나눌 수 있을 때 Batch Sequential 또는 Pipeline 각 단계가 증분 처리 가능하고, 동시 실행 가능할 때 Pipeline 연속적인 데이터 스트림을 점진적으로 변환해야 할 때 Pipe-and-Filter 외부 환경의 예측 불가능한 변화에 따라 출력을 제어해야 할 때 Process Control (Closed loop)
Batch Sequential Style
| 항목 | 내용 |
|---|---|
| 정의 | 각 처리 단계가 전체 데이터를 한 번에 받아 실행을 완료한 뒤, 다음 단계로 순차적으로 넘기는 구조 |
| Elements (구성 요소) | - Components: 독립적인 프로그램 - Connectors: 파일 (I/O 파일 등) |
| Relations (관계) | 한 프로그램이 생성한 파일이 다음 프로그램의 입력으로 사용됨 |
| Constraints (제약 조건) | 각 프로그램은 이전 단계가 완료된 후에만 실행됨 (동시 실행 불가) |
| 장점 | - 구성 단순 - 대용량 처리 효율적 - 처리 단계 재사용 가능 - 입출력 형식만 맞으면 교체 용이 |
| 단점 | - 비대화형(Non-interactive) - 동시성 없음 - 처리 지연·처리량 낮음 - 가용성 제한 |
| 예시 | 데이터 전처리 알고리즘 |
| 그림 | 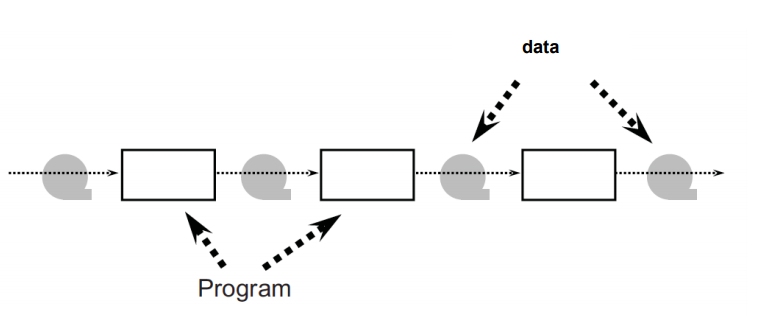 |
Pipe-and-Filter Style
| 항목 | 내용 |
|---|---|
| 정의 | 데이터를 한 방향으로 흐르게 하며, 각 단계(필터)가 데이터를 점진적으로 변환하는 구조. 필터는 독립적으로 실행되며 루프, 병렬 처리 및 증분 실행이 가능함. |
| Elements (구성 요소) | - Component: 필터(Filter) – 데이터를 점진적으로 변환 - Connector: 파이프(Pipe) – 데이터를 보존하며 한 방향으로 순서대로 전달 |
| Relations (관계) | 파이프의 출발점(source)은 필터의 출력에, 도착점(sink)은 다음 필터의 입력에 연결됨 |
| Constraints (제약 조건) | - 각 필터는 독립적인 엔티티여야 함 - 활성 필터(필터가 능동적) 또는 수동 필터(파이프가 능동적)를 구성할 수 있음 |
| 장점 | - 단순한 구성 - 필터의 재사용 용이 - 유지보수 및 확장 용이 - 분산 병렬 처리를 통한 성능 향상 |
| 단점 | - 상호작용 I/O 처리에 부적합 - 많은 필터 구성 시 계산 자원 소모 증가 - 장시간 실행하는 작업에는 부적합 - 내결함성(Fault Tolerance) 낮음 |
| 예시 | Pipes and Filters in Unix |
| 그림 | 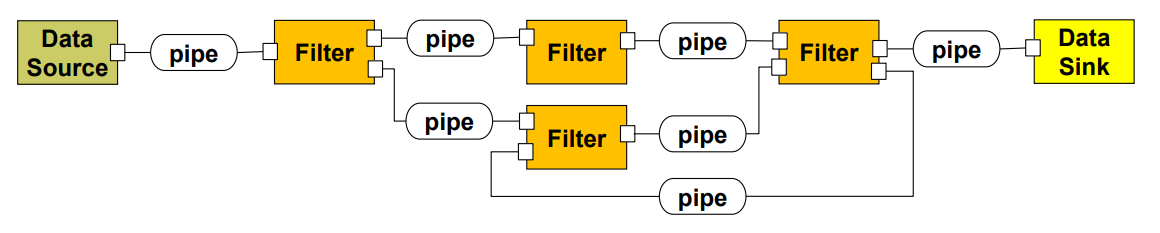 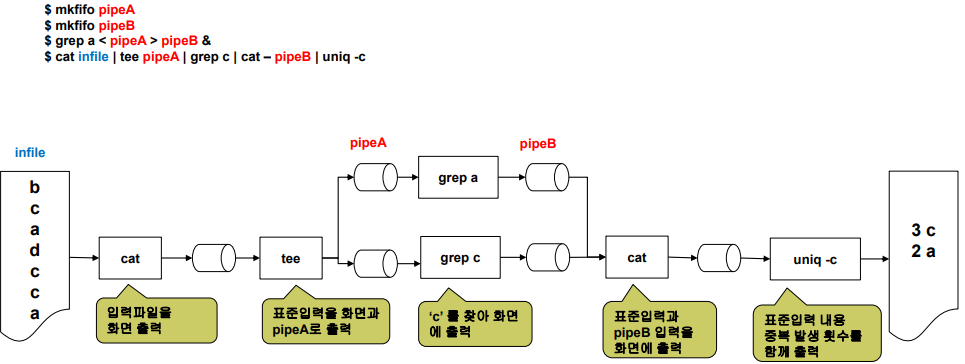 |
- Variant
- Pipeline
- 필터들이 직선형으로 연결된 일련의 처리 단계로 구성된 구조
- 파이프는 필터 사이 단방향 통신만 처리

- Pipeline
Process Control Style
| 항목 | 내용 |
|---|---|
| 정의 | 제어 변수를 원하는 값(Set Point)으로 유지하기 위해, 입력 변수와 조작 변수를 제어 유닛이 감시·조정하는 구조. 안정적인 처리 결과를 위해 반복적으로 환경 상태를 감시하고 조절함. |
| Elements (구성 요소) | - Components: 제어 유닛(Control Unit), 처리 유닛(Processing Unit) - Connectors: 제어 변수 세트 (Set Point, Manipulated Variable, Input Variable, Controlled Variable) |
| Relations (관계) | 제어 유닛은 입력값과 현재 상태를 기반으로 조작 변수를 조정하고, 처리 유닛은 이를 이용해 원하는 결과(Controlled Variable)를 유지함 |
| Constraints (제약 조건) | Controlled Variable의 값은 Set Point에 최대한 근접하게 유지되어야 함 |
| 장점 | - 출력 데이터의 안정적인 유지 - 신뢰성 및 견고성 향상 - 최적의 처리 조건 유지 |
| 단점 | - 설계 복잡도 증가 - 제어 유닛 또는 처리 유닛의 오작동/해킹/오류 시 전체 시스템 교란 가능성 |
| 예시 | - 자동차의 크루즈 컨트롤 시스템 - 네트워크의 QoS 제어 시스템 |
| 그림 | 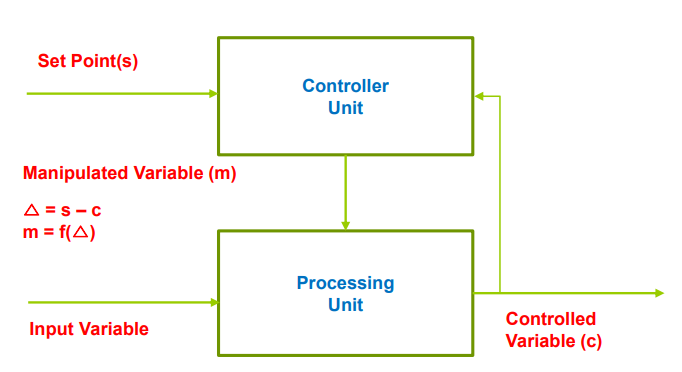 - Set Point: 목표값(Controlled Variable이 도달해야 할 이상적인 값) - Set Point: 목표값(Controlled Variable이 도달해야 할 이상적인 값) - Manipulated Variable: 제어 유닛이 조정하는 변수, 목표값을 유지하기 위해 변경됨 - Input Variable: 처리 유닛에 입력되는 외부 데이터 - Controlled Variable: 실제 시스템의 출력값, 센서로 측정되며 Set Point와 비교 대상이 됨 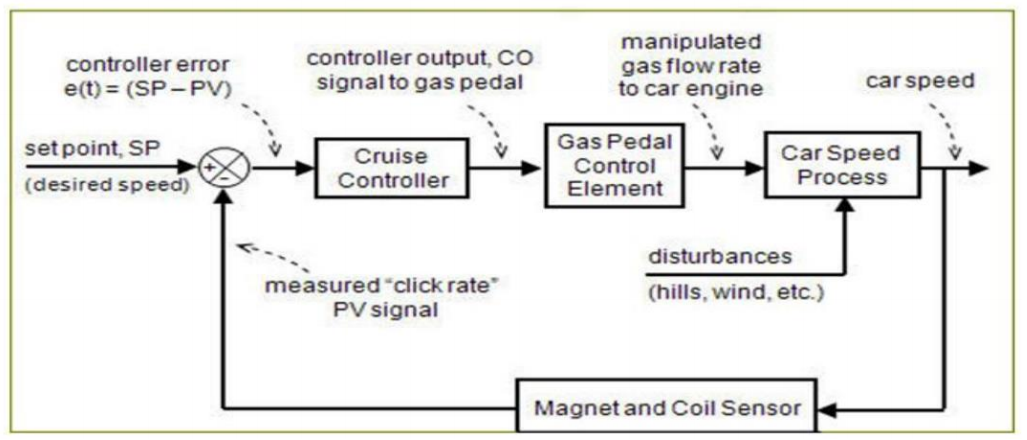 |
2.2 Data Centered Architecture
- 정의
- 중앙 데이터 저장소를 중심으로, 독립적인 컴포넌트들이 데이터를 공유하고, 저장소를 통해 간접적으로 통신하는 구조
- 구성 요소:
- Data Client: 데이터를 읽고 쓰는 독립적인 소프트웨어 컴포넌트 또는 에이전트
- Data Store: 중앙 집중형 데이터 저장소 (독립적인 요소이며 모든 데이터의 흐름이 이곳을 중심으로 이루어짐)
- 스타일 선택 가이드
스타일 설명 예시 Repository Style 데이터 저장소는 수동(passive), 클라이언트가 능동(active) DBMS, 정보 시스템 Blackboard Style 데이터 저장소는 능동(active), 클라이언트는 수동(passive) 지식 기반 AI, 음성·영상 인식 시스템
Repository Style
| 항목 | 내용 |
|---|---|
| 정의 | 하나의 중앙 데이터 저장소(Data Store)를 중심으로 여러 컴퓨팅 프로세스(Data Client)들이 데이터를 읽고 쓰는 구조. 데이터 저장소는 수동적(passive)이며, 컴포넌트 간 직접 통신은 없음. |
| Elements (구성 요소) | - Component: 하나의 메모리(중앙 데이터 저장소), 여러 계산 프로세스(데이터 클라이언트) - Connector: 데이터 저장소와 클라이언트 간 직접 접근 또는 프로시저 호출 |
| Relations (관계) | 각 데이터 클라이언트는 중앙 데이터 저장소를 통해 간접적으로 데이터를 공유하며, 클라이언트 간 직접 통신은 없음 |
| Constraints (제약 조건) | - 데이터 저장소는 수동적으로 동작 - 데이터 클라이언트 간 직접 상호작용 금지 |
| 장점 | - 새로운 클라이언트/데이터 저장소 추가 용이 (확장성, Scalability) - 특정 클라이언트의 기능 변경이 쉬움 - 클라이언트 재사용 가능 - 클라이언트 간 임시 데이터 전달 오버헤드 감소 |
| 단점 | - 데이터 저장소 장애 또는 공격 시 시스템 전체의 가용성·보안성 저하 - 클라이언트가 데이터 구조에 높게 의존 - 분산 저장소일 경우 데이터 이동 비용 발생 |
| 예시 | DBMS 기반의 정보 시스템, 중앙 집중형 파일 서버 시스템 등 |
| 그림 | 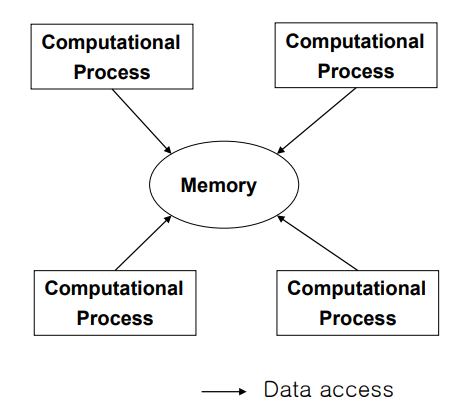 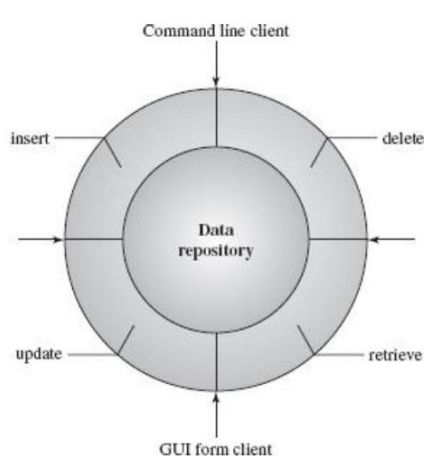 |
Blackboard Style
| 항목 | 내용 |
|---|---|
| 정의 | 중앙 블랙보드(Blackboard)에 데이터를 공유하고 갱신하며, 컨트롤러가 이를 감시하고 지식 소스(Knowledge Source)를 활성화시키는 구조. 클라이언트는 수동적으로 동작하고, 블랙보드와 컨트롤러는 능동적으로 동작함. |
| Elements (구성 요소) | - Component: Knowledge Source (데이터 클라이언트), Blackboard (중앙 데이터 저장소), Controller (Blackboard 상태 감시 및 Knowledge Source 실행 제어) - Connector: 데이터 접근 또는 프로시저 호출 |
| Relations (관계) | 컨트롤러가 블랙보드 상태를 모니터링하며, 조건에 따라 적절한 Knowledge Source를 활성화함 |
| Constraints (제약 조건) | - 블랙보드와 컨트롤러는 능동적, 클라이언트(Knowledge Source)는 수동적 - Knowledge Source 간에는 직접 상호작용 없음 |
| 장점 | - 클라이언트/블랙보드 확장 용이 (확장성) - 클라이언트 기능 변경 및 재사용 용이 - 병렬성 지원 (독립된 지식 소스들 간) - 다양한 가설 실험 가능 |
| 단점 | - 블랙보드 장애 시 전체 시스템 가용성·보안성 저하 - 클라이언트와 데이터 구조 간 높은 의존성 - 정리 조건이 명확하지 않아 종료 판단 어려움 - 테스트 어려움 |
| 예시 | 음성 인식 시스템, 이미지 인식 시스템, 지식 기반 AI 시스템 |
| 그림 | 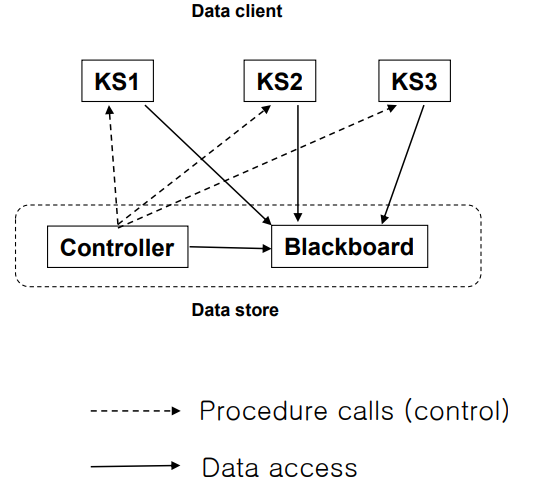  |
2.3 Implicit Invocation Architecture
- 정의
- 모듈 간 직접 호출 없이, 이벤트 발생을 통해 암시적으로 다른 모듈의 프로시저가 호출되는 구조로, 구성 요소 간의 느슨한 결합(loose coupling)을 특징으로 함
- 구성 요소
- Publisher (또는 Producer, Sender, Source): 이벤트를 발생시키는 컴포넌트
- Subscriber (또는 Consumer, Receiver, Target): 이벤트를 수신하고 반응하는 컴포넌트
- 통신 특성
- 통신은 동기(synchronous) 또는 비동기(asynchronous) 방식일 수 있음
- 이벤트 전파 방식은 다음 중 하나로 구성됨:
- One-to-One
- One-to-Many
- Many-to-One
- 스타일 선택 가이드
스타일 설명 예시 Non-buffered Event-Based Style 이벤트 발생 시 즉시(버퍼 없이) 다수 리스너에게 전달되는 구조
주로 Observer Pattern 기반UI 이벤트 처리, MVC 모델 Buffered Message-Based Style 이벤트가 버퍼/큐에 저장되어 전달됨
발신자와 수신자가 시간적으로 독립적메시지 큐 시스템, Kafka, RabbitMQ • (Buffered) Point-to-Point 발신자 1 → 수신자 1 (One-to-One) 구조 RPC, Direct Queue • (Buffered) Publish-Subscribe 발신자 1 → 수신자 N (One-to-Many) 구조, 구독 기반 메시징 시스템 Kafka Topic, MQTT
Non-buffered Event-Based Style
| 항목 | 내용 |
|---|---|
| 정의 | 이벤트가 발생하면 즉시(Synchronous) 등록된 리스너들이 순차적 호출 없이 반응하는 구조로, 암시적 호출(Implicit Invocation)의 대표적 방식이며 Observer 패턴 기반 구조임. |
| Elements (구성 요소) | - Event Source(Subject): 이벤트 리스너 등록 및 알림 전송 기능 제공 - Event Listener(Observer): handleEvent() 메서드로 이벤트에 반응 |
| Relations (관계) | 이벤트 소스는 리스너를 등록받고, 이벤트 발생 시 모든 리스너에 즉시 알림을 전송함 |
| Constraints (제약 조건) | - 동기적(Synchronous) 처리: 이벤트 발생 시 리스너들이 즉시 실행되며 대기 없이 처리됨 |
| 장점 | - 다양한 프레임워크 지원 (Java AWT, Swing 등) - 컴포넌트 재사용 용이 - 유지보수 및 시스템 확장성 우수 - 런타임 중 동적 연결/해제 가능 (유연성) |
| 단점 | - 리스너의 반응 순서가 예측되지 않아 테스트/디버깅 어려움 - 간접 호출(Source에서 이벤트 리스너로, 이벤트 리스너에서 직접 처리하는 모듈로)로 인한 오버헤드 발생 가능 - 이벤트 소스와 리스너 간 결합도가 메시지 기반 구조보다 높음 |
| 예시 | - IDE에서 소스 파일 저장 시 자동 컴파일/링크 - 디버깅 중 Breakpoint 도달 시 에디터 자동 전환 - 주식 경고 시스템에서 특정 임계값 도달 시 자동 알림 및 반응 |
| 그림 | 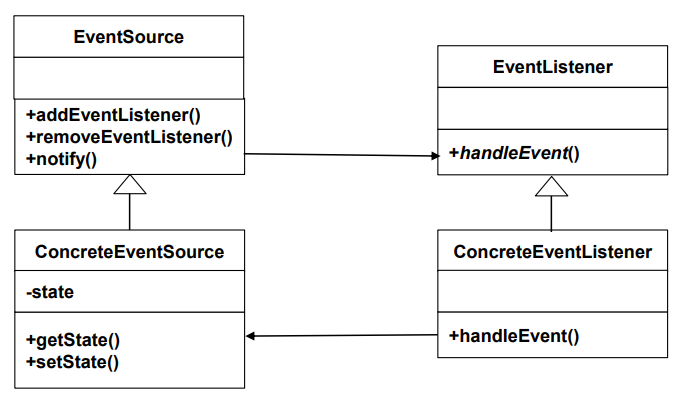 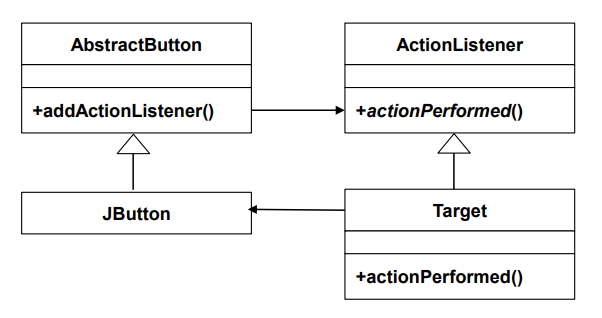 |
Buffered Message-Based Style
| 항목 | 내용 |
|---|---|
| 정의 | 메시지 기반 소프트웨어 아키텍처로, 생산자(Producer)가 메시지를 생성해 버퍼(큐 또는 pub-sub)에 보내고, 소비자(Consumer)는 그 메시지를 비동기적으로 수신하는 구조. 생산자와 소비자는 서로를 알 필요 없이 독립적으로 동작함. |
| Elements (구성 요소) | - Message Producer: 메시지를 생성하여 버퍼에 전송하는 컴포넌트 - Message Consumer: 버퍼에서 메시지를 꺼내 처리하는 컴포넌트 - Buffer (Queue 또는 Pub-Sub Connector): 메시지를 저장하고 수신자에게 전달하는 비동기적 매개체 |
| Relations (관계) | 생산자는 메시지를 버퍼에 전송하고, 소비자는 해당 버퍼로부터 메시지를 꺼내 처리함. 생산자와 소비자는 시간적으로 분리되어 독립적으로 동작 |
| Constraints (제약 조건) | - 비동기적 메시지 처리 - 생산자와 소비자는 동시에 활성 상태일 필요 없음 |
| 장점 | - 익명성 (소비자는 생산자를 알 필요 없음) • 사용자 독립성 • 위치 독립성 • 시간 독립성 - 생산자-소비자 간 및 소비자 간 병렬성 보장 - 메시지 전송 신뢰성 보장 (ack, 우선순위, 만료 설정 등) |
| 단점 | - 큐의 용량 제한 문제 (메모리 기반 한계) - 간접성 증가로 인한 오버헤드와 디버깅 어려움 |
| 예시 | Kafka, RabbitMQ, Azure Service Bus, AWS SQS 등 |
| 그림 |  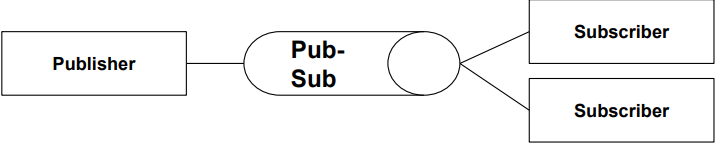 |
2.4 Interaction-Oriented Architecture
- 정의
- 사용자 인터페이스(입출력)와 데이터 추상화 및 비즈니스 로직을 분리하여, 상호작용 중심의 소프트웨어 구조를 구현하는 아키텍처 스타일
- 구성 요소
- View Presentation Module:
• 사용자 입력을 받고, 시각적·청각적으로 출력을 제공- Control Module:
• 시스템 흐름과 구성 제어를 담당- Data Module:
• 데이터 추상화 및 모든 비즈니스 로직을 처리- 특징
- 사용자 인터페이스, 제어 로직, 데이터 로직 간의 관심사 분리 (Separation of Concerns)
- 사용자 중심의 상호작용 환경(UI/UX) 구현에 적합
- 각 모듈은 명확히 역할이 분리되며, 변경 및 유지보수가 용이함
- 스타일 선택 가이드
스타일 설명 예시 Model-View-Controller (MVC) 중앙 집중식 제어 구조: 사용자 인터페이스(View), 제어 로직(Controller), 데이터 로직(Model)을 명확히 분리한 구조 웹 프레임워크 (Django, Rails 등) Presentation-Abstraction-Control (PAC) 에이전트 기반 계층적·분산형 제어 구조: View, Abstraction, Control을 묶은 단위를 계층적으로 구성함 분산 UI 시스템, 복잡한 인터랙션 애플리케이션
Model-View-Controller (MVC) Style
| 항목 | 내용 |
|---|---|
| 정의 | 사용자 인터페이스(View)와 데이터 및 비즈니스 로직(Model), 그리고 그 사이의 제어 역할(Controller)을 분리한 아키텍처 스타일로, 상호작용 애플리케이션(UI 중심)에서 널리 사용됨. |
| Elements (구성 요소) | - Model: 데이터 및 비즈니스 로직을 캡슐화하며, View나 Controller에 의존하지 않음 - View: 사용자에게 정보를 표시하고, 로직을 포함하지 않음 - Controller: View로부터 사용자 입력을 받아 Model에 전달하며, 애플리케이션 흐름 제어 및 로직 담당 |
| Relations (관계) | - View는 Controller를 생성하고, Model에 연결됨 - Controller는 사용자 입력을 받아 Model을 조작하고, 그 결과에 따라 View를 갱신 - Model은 Observer 패턴을 통해 View에 변경 사항을 알림 (notify → update) - 각 구성 요소는 명확히 역할이 분리되며, 간접 연결을 통해 느슨한 결합 구조를 유지함 |
| Constraints (제약 조건) | - 초기화 과정: Main Program이 먼저 Model과 View를 생성하고, View는 Controller를 생성함 → View와 Controller는 Model에 연결되며, Observer로 등록됨 - 이벤트 처리: 사용자의 입력은 Controller에서 처리되며, Model의 상태를 변경하고 notify 발생 → View는 notify를 통해 변경을 감지하고 update 및 display 수행 |
| 장점 | - 동기화된 다중 View 지원 (하나의 Model에 여러 View) - View/Controller의 플러그인 가능성 (런타임 교체 가능) - Look & Feel 분리로 플랫폼 이식성 우수 - 역할이 분리되어 팀 개발에 용이 (UI, 로직, DB 별로 분담 가능) |
| 단점 | - 구조적 복잡성 증가 (단순 UI에 과한 설계일 수 있음) - 업데이트 과다 발생 가능 - View가 데이터를 얻기 위해 다수의 요청을 해야 할 수 있음 - 일부 UI 툴킷과의 부적합성 |
| 예시 | 웹 프레임워크 (Django, Spring MVC, Ruby on Rails 등) |
| 그림 | 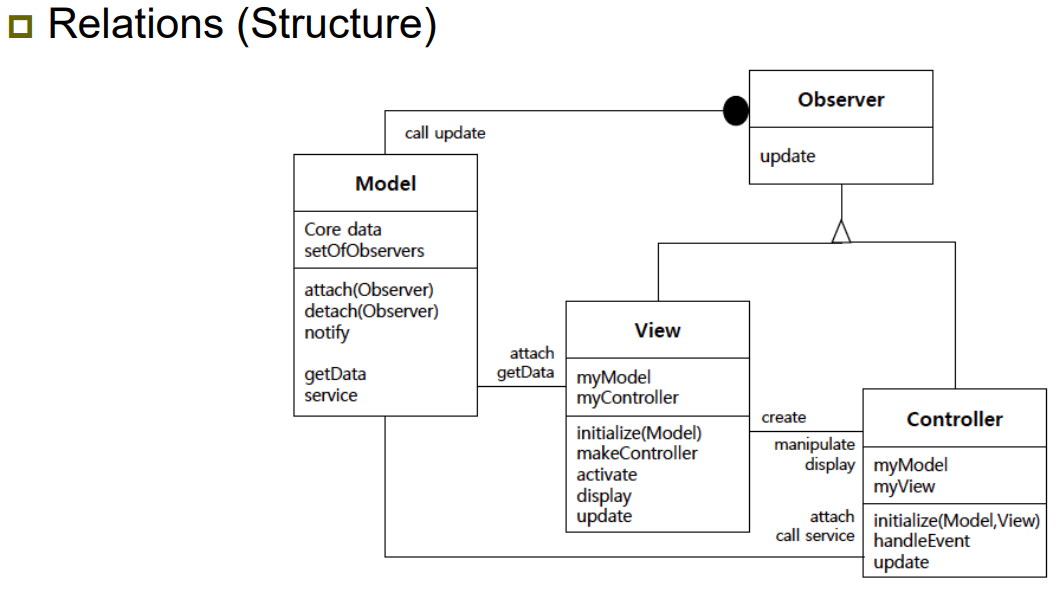 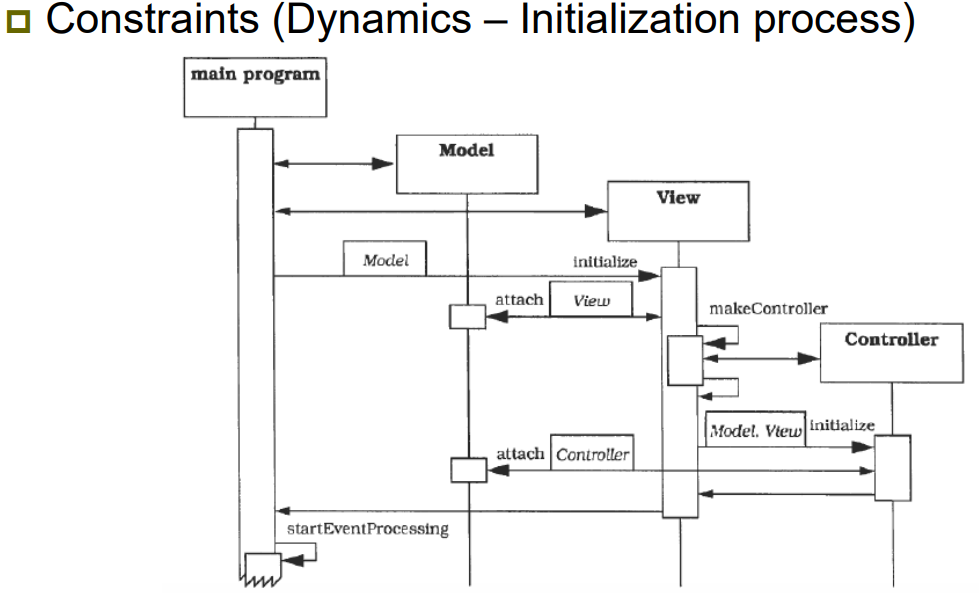 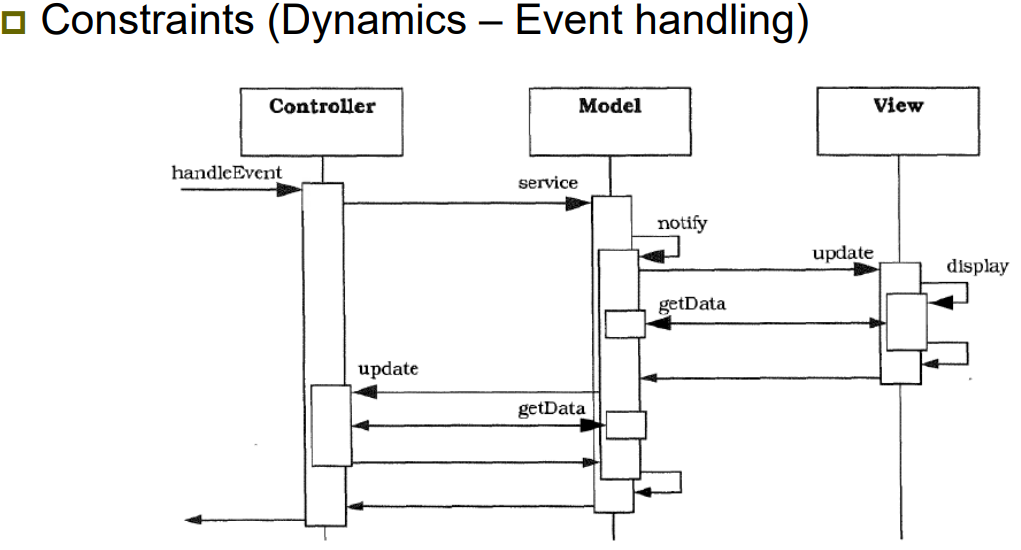 |
- Variant
- Document-View Style
- MVC 구조를 단순화하여, 시스템을 두 개의 주요 하위 시스템으로 나눈 아키텍처 스타일
- Document(Model): 데이터를 보관하고 도메인 로직 제공
View(View + Controller): 사용자 입력/출력을 처리 - Observer 패턴을 통해 View는 Document의 변경을 자동으로 감지

- Document-View Style
Presentation–Abstraction–Control (PAC) Style
| 항목 | 내용 |
|---|---|
| 정의 | 상호작용 애플리케이션을 계층적 트리 구조의 에이전트 집합으로 구성하며, 각 에이전트는 Presentation, Abstraction, Control 세 요소로 구성됨. 각 에이전트는 애플리케이션의 기능 일부를 책임지고 독립적으로 동작함. |
| Elements (구성 요소) | - Presentation: 사용자 인터페이스(UI) 담당 - Abstraction: 애플리케이션 데이터와 그에 대한 로직 처리 - Control: Presentation과 Abstraction 사이의 중재 역할을 하며, 다른 에이전트와의 통신도 담당 |
| Relations (관계) | - Control은 에이전트 간 통신을 담당하고, 상위–하위 에이전트 계층 구조에서 흐름을 조율함 |
| Constraints (제약 조건) | - Presentation과 Abstraction은 직접 연결되지 않음 - 에이전트 간 통신은 Control 컴포넌트를 통해서만 이루어짐 |
| 장점 | - 관심사의 분리: 각 의미 단위(semantic concept)를 독립적인 에이전트로 설계 가능 - 변경 및 확장 용이성: 특정 에이전트 내부 변경이 다른 에이전트에 영향 없음 - 멀티태스킹 지원: 에이전트를 스레드, 프로세스, 분산 시스템 단위로 배포 가능 |
| 단점 | - 구조적 복잡성 증가: 모든 의미 단위를 PAC 에이전트로 구현하면 복잡해질 수 있음 - 에이전트 간 통신 오버헤드로 인해 성능 저하 가능성 |
| 예시 | 대화형 멀티에이전트 UI, 분산 처리 기반 그래픽 편집기, 협력 기반 소프트웨어 시스템 |
| 그림 | 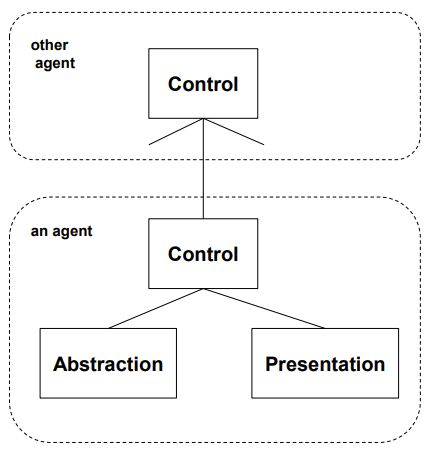 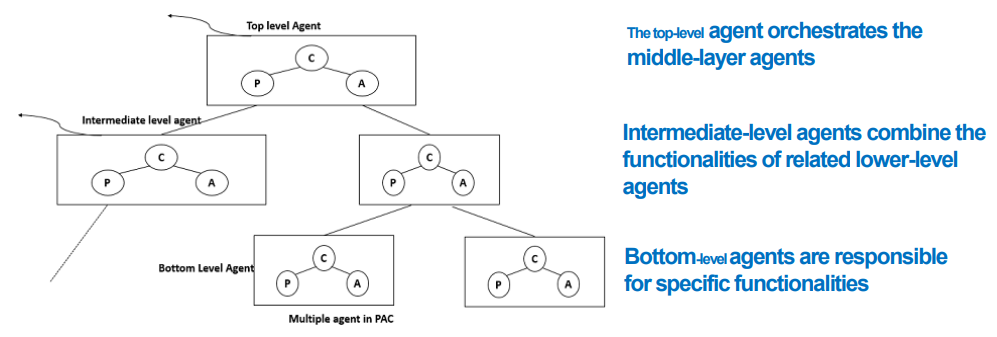 |
2.5 Hierarchical Architecture
- 정의
- 전체 시스템을 계층 구조(hierarchy)로 분해하여, 상위 모듈이 하위 모듈의 서비스를 호출(call-and-return)하는 방식으로 구성된 구조
- 모듈 간 호출 방향이 명확하며, 상하 관계가 존재하는 계층적 설계를 특징으로 함
- 구성 요소
- Upper-level Module: 하위 모듈의 기능을 호출해 사용하는 클라이언트 역할
- Lower-level Module: 상위 모듈에 서비스를 제공하는 서버 역할
- Interface (Explicit/Implicit Call): 명시적 호출 또는 암시적 호출로 계층 간 연결됨
- 특성
- 일반적으로 call-and-return 방식의 명시적 호출 사용
- 계층 간 상하 방향성 보장, 하위 모듈은 상위 모듈을 호출하지 않음 (단방향 제어 흐름)
- 스타일 선택 가이드
스타일 설명 예시 Main-Subroutine 프로그램을 상위-하위 루틴으로 나누는 구조
상위 루틴이 하위 루틴을 호출전통적인 절차적 언어 구조 Master-Slave Master가 작업을 분배하고, Slave가 작업을 처리하는 구조
동시성과 분산성에 강점분산 처리 시스템, 병렬 컴퓨팅 Layered 수직 계층 구조로, 상위 계층은 하위 계층의 인터페이스만 사용
하위는 상위를 몰라도 됨OS 구조, 네트워크 계층 모델 • Virtual Machine 하드웨어 또는 운영체제 추상화를 제공하는 논리적 계층 JVM, Python 인터프리터 • Microkernel 핵심 기능만 커널에 넣고, 서비스는 외부 모듈로 분리하여 계층화 OS 커널 설계 (ex. Minix, QNX)
Main-Subroutine Style
| 항목 | 내용 |
|---|---|
| 정의 | 소프트웨어 시스템을 기능 단위로 계층적 분해하여, 상위 루틴(Main)이 하위 루틴(Subroutine)을 순차적으로 호출하는 방식의 아키텍처 스타일. 절차지향 언어에서 널리 사용되며, 중앙 집중식 흐름 제어가 특징임. |
| Elements (구성 요소) | - Components: 개별적인 기능을 수행하는 프로시저(Procedure) 또는 함수 - Connectors: 함수 호출(Call) |
| Relations (관계) | 각 컴포넌트는 상위 컴포넌트로부터 제어 흐름을 넘겨받아, 필요한 처리를 수행한 후 다시 상위로 제어를 반환함. |
| Constraints (제약 조건) | - 중앙 집중적 제어 흐름 - 단일 제어 스레드(single thread of control) - 부모 루틴이 자식 루틴을 호출하는 계층적 호출 구조 유지 |
| 장점 | - 단순성: 구조가 간단하고 이해하기 쉬움 - 테스트 용이성: 모듈화되어 있어 각 루틴을 독립적으로 테스트 가능 |
| 단점 | - 전역 데이터에 의존할 경우 보안성과 안정성 저하 - 컴포넌트 간 강결합(tight coupling)으로 인해 변경 영향 범위가 큼 |
| 예시 | C, Pascal 등 절차지향 언어 기반 프로그램, 초기 시스템 유틸리티 |
| 그림 | 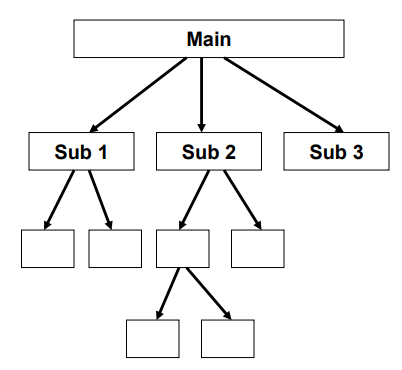  |
Master-Slave Style
| 항목 | 내용 |
|---|---|
| 정의 | 마스터(Master)가 전체 작업을 관리하고, 여러 슬레이브(Slave)에게 작업을 분산하여 처리하게 하는 계층적 구조의 아키텍처 스타일. 주로 내결함성(fault tolerance)과 병렬 처리를 위해 사용됨. |
| Elements (구성 요소) | - Master: 전체 흐름을 관리하며, 슬레이브들에게 작업을 분배하고 결과를 수집 및 선택 - Slaves: 마스터로부터 작업을 받아 동일하거나 서로 다른 방식으로 처리 후 결과 반환 |
| Relations (관계) | 마스터는 복수의 슬레이브에게 동일/다양한 방식으로 작업을 위임하고, 결과들을 수집한 뒤, 선택 전략에 따라 최종 결과를 결정함 |
| Constraints (제약 조건) | - 중앙 집중형 제어 구조 (마스터 중심) - 슬레이브는 독립적 실행 가능, 병렬 처리 가능 - 마스터는 모든 슬레이브와 통신 필요 |
| 장점 | - 내결함성(fault tolerance): 슬레이브 장애 시 다른 슬레이브로 대체 가능 - 병렬 처리 가능: 슬레이브들이 동시에 작업 수행 - 확장성: 슬레이브 수를 늘려 처리량 증가 가능 - 정확도 향상: 여러 결과 중 다수결 등으로 정확도 확보 |
| 단점 | - 단일 실패 지점(SPoF): 마스터 장애 시 시스템 전체가 영향을 받음 - 통신 오버헤드: 마스터-슬레이브 간 통신이 많은 경우 성능 저하 가능 |
| 예시 | 분산 병렬 처리 시스템, Hadoop MapReduce, 비동기 미러링 시스템 등 |
| 그림 | 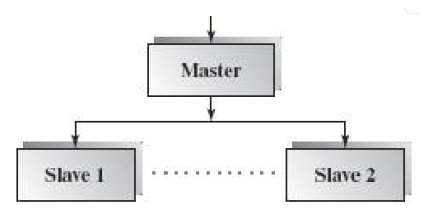 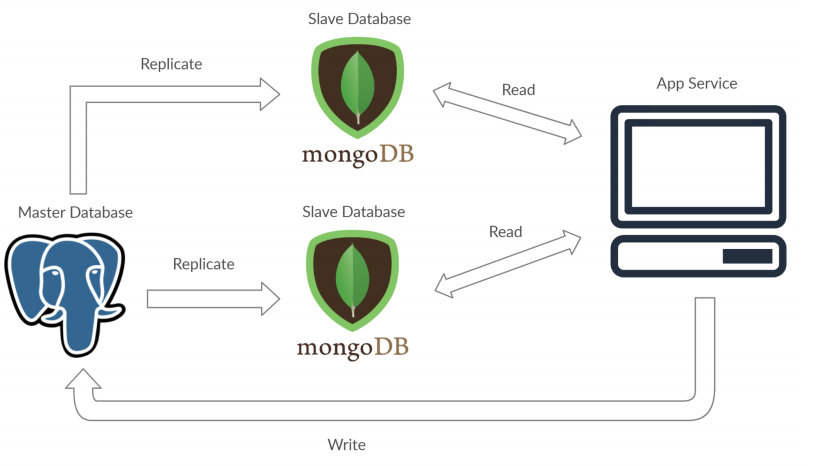 |
Layered Style
| 항목 | 내용 |
|---|---|
| 정의 | 소프트웨어 시스템을 기능에 따라 수직 계층(Layers)으로 분리한 아키텍처 스타일. 상위 계층은 하위 계층의 서비스만을 이용하며, 계층 간 의존성과 정보 은닉을 통해 모듈성과 유지보수성을 높임. |
| Elements (구성 요소) | - Layer: 동일한 수준의 추상화와 역할을 가지는 컴포넌트 집합. 예: Presentation Layer, Business Logic Layer, Data Access Layer 등 |
| Relations (관계) | - Allowed-to-use: 상위 계층은 직접 아래 계층에만 접근 가능 - 계층 간의 관계는 "depends-on" 관계의 특수화 형태 |
| Constraints (제약 조건) | - Allowed-to-use 관계는 순환 참조 불가 (계층 간 의존이 순환되지 않아야 함) - 최소한 두 개 이상의 계층 필요 |
| 장점 | - 독립성: 계층별로 독립적 배포·업데이트·유지보수 가능 - 병렬 개발 용이: 팀 단위 병렬 작업 가능 - 보안성: 상위/하위 계층 간 정보 은닉 가능 - 재사용성: 하위 계층은 높은 응집성과 낮은 결합도로 재사용·교체 용이 |
| 단점 | - 성능 저하: 계층이 많을수록 호출 및 전달 과정에서 성능 저하 발생 - 적절한 계층화 설계의 어려움: • 계층이 너무 적으면 재사용성과 변경 용이성을 제대로 활용하지 못함 • 계층이 너무 많으면 불필요한 복잡성과 오버헤드 초래 - 단순한 애플리케이션에는 과도한 구조가 될 수 있음 |
| 예시 | OS 계층 구조, 웹 애플리케이션 아키텍처 (3-tier: Presentation, Logic, Data) |
| 그림 | 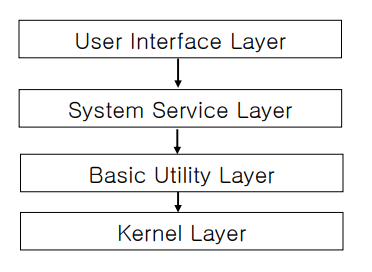 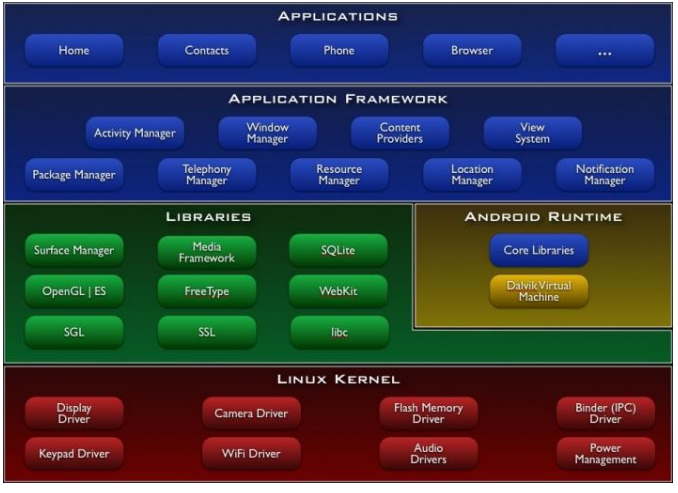  |
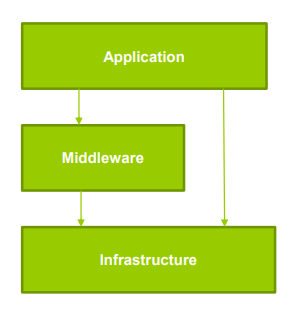
- Variant
- Relaxed Layered System
- Performance와 Maintainability의 Tradeoff 관계에서, Performance에 조금 더 가중치를 둔 구조
- 유닉스, X 윈도우 시스템
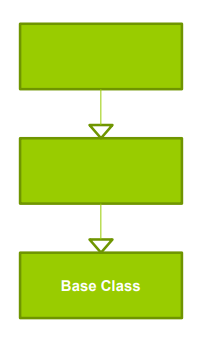
- Layering Through Inheritance
- 상위 계층이 하위 계층의 서비스를 상속한 구조
- 상위 계층이 하위 계층의 서비스를 수정 가능하지만, 기본 클래스 변경 시 모든 서브 클래스가 recompiled 되어야 함
- Relaxed Layered System
Virtual Machine Style
| 항목 | 내용 |
|---|---|
| 정의 | 기존 시스템 위에 가상 머신(Virtual Machine)을 구축하여, 하드웨어 또는 플랫폼으로부터 추상화된 실행 환경을 제공하는 아키텍처 스타일. VM은 고유의 속성과 연산(operations)을 제공하며, 독립적 소프트웨어 실행이 가능함. |
| Elements (구성 요소) | - Application: VM 위에서 실행되는 응용 소프트웨어 - Virtual Machine (VM): 추상화된 실행 환경, 인터프리터 또는 런타임 포함 - Existing Platform: 실제 하드웨어 또는 호스트 OS 등 기반 시스템 |
| Relations (관계) | - Application은 Virtual Machine 위에서 동작 - VM은 기존 플랫폼 위에서 구축되어 하드웨어와 Application 사이를 중개함 |
| Constraints (제약 조건) | - VM은 플랫폼 상에 추가 계층으로 존재하며, VM 없이 Application은 실행되지 않음 - VM이 플랫폼 독립성 제공을 목표로 설계됨 |
| 장점 | - 이식성(Portability): 다양한 플랫폼에서 동일한 응용 프로그램 실행 가능 - 개발 용이성: 복잡한 시스템 인터페이스를 단순화해 소프트웨어 개발 단순화 - 시뮬레이션 가능: 실패 상황이나 테스트 모델을 가상으로 구현 가능 |
| 단점 | - 실행 성능 저하: 인터프리터 방식 등으로 인해 실행 속도가 느림 - 계층 추가로 인한 오버헤드 발생 (메모리·처리 성능 부담) |
| 예시 | Java Virtual Machine (JVM), Python Interpreter, .NET CLR, Android Dalvik/ART |
| 그림 | 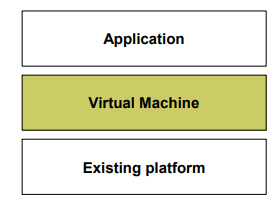 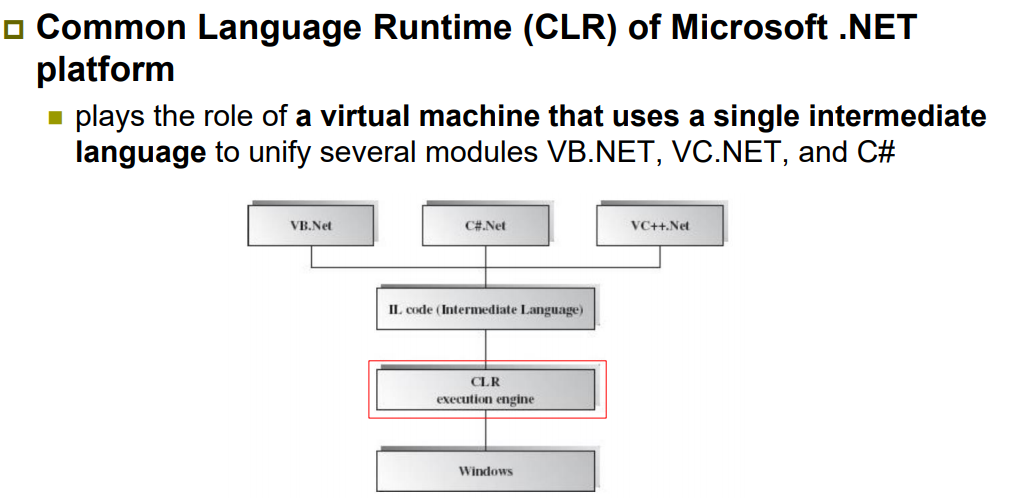 |
Microkernel Style
| 항목 | 내용 |
|---|---|
| 정의 | 최소한의 핵심 기능(Core System)을 갖춘 경량 커널 구조로, 주요 기능은 외부 또는 내부 서버 컴포넌트로 분리하고 확장 가능한 구조. 운영체제 또는 복잡한 시스템에서 유연성과 이식성, 신뢰성을 확보하기 위해 사용됨. |
| Elements (구성 요소) | - Microkernel: 시스템의 기본 및 핵심 메커니즘을 담당하는 최소 기능(예: 프로세스 생성, 메모리 복사 등) - Internal Server Component: 마이크로커널을 보조하며, 내부적으로 기능 확장 - External Server Component: 외부에서 독립적으로 실행되며, 애플리케이션 도메인 서비스를 제공 - Client & Adapter Component: 클라이언트 및 클라이언트와 외부 서버 간 인터페이스 제공, 접근 포터블성 보장 |
| Relations (관계) | - Microkernel은 핵심 서비스를 제공하며, 내부/외부 서버는 이를 통해 동작 - Internal Server는 커널 요청에 응답하며, 하드웨어 의존성을 캡슐화 - External Server는 별도 프로세스로 동작하며, 어댑터를 통해 클라이언트 요청을 직접 수신 후 커널의 기능을 활용 - Adapter는 클라이언트가 외부 서버를 간접적으로 접근할 수 있게 함 |
| Constraints (제약 조건) | - Minimality: 마이크로커널은 필수 기능만 포함해야 함 |
| 장점 | - 유연성 & 확장성: 새로운 외부 서버 추가만으로 기능 확장 가능 - 가용성 향상: 동일 서버를 여러 머신에 분산 실행 가능 - 이식성(Portability): 새로운 하드웨어 환경에서도 마이크로커널만 수정하면 시스템 이전 가능 |
| 단점 | - 단일 커널보다 느림 (“monolithic system에 비해 성능 저하) - 설계 및 구현의 복잡성 증가 (컴포넌트 간 통신, 설계 명확화 필요) |
| 예시 | QNX, MINIX, L4, MacOS X Kernel (XNU), Windows NT (부분 마이크로커널 구조) |
| 그림 | 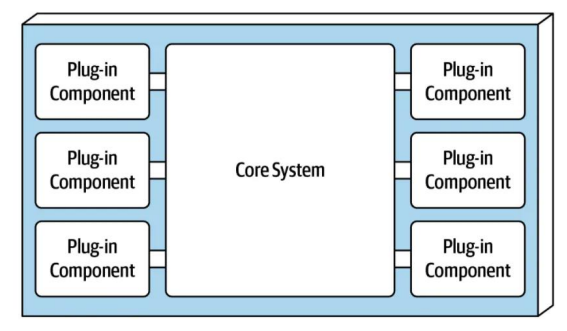  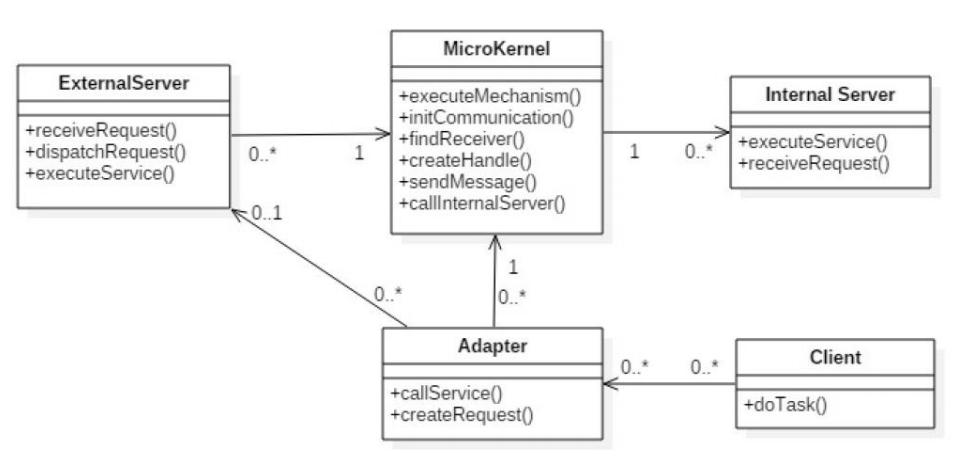 |
|
2.6 Distributed Architecture
- 정의
- 계산 및 저장 장치들이 통신 네트워크로 연결되어 하나의 시스템처럼 동작하는 아키텍처. 각 장치는 메시지 전달(message passing), 원격 프로시저 호출(RPC), 원격 메서드 호출(RMI) 등을 통해 상호작용하며, 지리적으로 분산된 환경에서도 협업이 가능함.
- 구성 요소
- Node (컴포넌트): 독립 실행 단위. 예: 클라이언트, 서버, DB 등
- Communication Channel: 노드 간 메시지를 주고받는 통신 경로
- 특성
- 통신 메커니즘은 message passing, RPC, RMI 등 다양함
- 스타일 분류 가이드
스타일 설명 예시 Multi-tier 프리젠테이션, 애플리케이션, 데이터 계층 등으로 분리된 구조 3-Tier Web App, ERP Client-Server 클라이언트가 요청하고 서버가 응답하는 전통적인 구조 Web Browser – Web Server Broker 중재자(Broker)가 요청을 적절한 서버에 전달하는 구조 CORBA, Java RMI Dispatcher 요청을 다수의 워커에 분산 처리하는 구조 Load Balancer 기반 시스템 Service-oriented Architecture (SOA) 재사용 가능한 서비스들을 조합하여 시스템을 구성 SOAP, WSDL 기반 서비스 Microservice 독립 배포 가능한 작은 서비스들의 집합 Netflix, Amazon 시스템 Edge-based 클라우드 서버 외에 단말 또는 엣지에서 데이터 처리를 수행 IoT 게이트웨이, MEC (Mobile Edge Computing)
Multi-tiers Architecture Style
| 항목 | 내용 |
|---|---|
| 정의 | 시스템을 여러 기능적 단위(계층, tiers)로 분해하여 각 계층이 특정 책임을 수행하고 서로 상호작용 하도록 구성된 아키텍처 스타일. |
| Elements (구성 요소) | - Client (Presentation Tier): 사용자 인터페이스와 사용자 요청 입력을 처리 - Middleware (Application Tier): 비즈니스 로직 수행, 클라이언트와 서버 간 중재자 역할 - Server (Data Management Tier): 데이터 저장, 검색, 관리 담당 - Request/Reply Connector: 요청/응답 방식의 통신 연결자 |
| Relations (관계) | 클라이언트는 Middleware에 요청을 전송하고, Middleware는 비즈니스 로직을 처리 후 서버에 데이터 요청을 전달. 서버는 결과를 반환하며 각 계층은 명확히 분리된 책임과 인터페이스를 가짐 |
| Constraints (제약 조건) | - 각 계층은 물리적으로 독립 배포 가능해야 함 - 클라이언트는 Application 또는 Data Tier에 직접 접근하지 않음 - 적절한 계층 분리 기준이 필요 (과도한 계층화는 복잡성 증가 유발) |
| 장점 | - 모듈화 및 재사용성: 계층 간 변경이 서로 영향을 최소화함 - 보안 강화: 민감한 데이터와 로직은 Application/Data Tier에 격리시킴으로써 end-user의 직접 접근 제한 - 확장성: Middleware는 멀티스레딩 및 로드 분산 가능 |
| 단점 | - 계층 간 통신 및 분산 구조로 인한 복잡성과 오버헤드 증가 - 통합 테스트가 어려움 (적절한 테스트 툴 부족) - 서버 장애 시 전체 시스템 신뢰도에 영향 |
| 예시 | 3-tier 웹 애플리케이션 (React/Flask/PostgreSQL), ERP 시스템, 클라우드 기반 API 서비스 |
| 그림 | 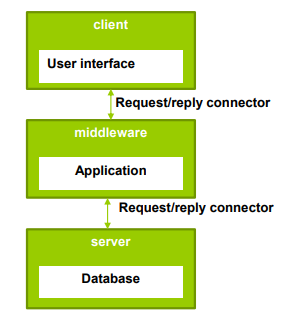  |
Layer vs Tier
- Layer: 소프트웨어 솔루션을 구성하는 요소들을 논리적으로 구조화하는 방식
- Tier: 시스템 인프라를 물리적으로 구조화하는 방식
Client-Server Style
| 항목 | 내용 |
|---|---|
| 정의 | 시스템을 클라이언트(Client)와 서버(Server)라는 두 구성 요소로 분리하는 구조. 클라이언트는 서버에 요청을 보내고, 서버는 요청을 처리하여 응답을 반환하는 요청/응답(request/reply) 기반의 구조임. |
| Elements (구성 요소) | - Client: 서버에 요청을 전송하는 컴포넌트 (ex. 사용자 UI) - Server: 클라이언트 요청을 수신, 처리하고 결과를 반환하는 컴포넌트 (ex. DB, 파일 처리 등) - Request/Reply Connector: 클라이언트와 서버 간 통신을 담당하는 프로토콜 또는 인터페이스 |
| Relations (관계) | 클라이언트는 서버에 요청(Request)을 보내고, 서버는 이를 수행한 뒤 응답(Response)을 반환함. |
| Constraints (제약 조건) | - 요청/응답 기반 통신 방식을 따름 - 클라이언트와 서버는 다른 티어로 분리될 수 있음 - 일반적으로 서버는 다수의 클라이언트를 동시에 처리할 수 있도록 설계됨 |
| 장점 | - 책임 분리: UI와 비즈니스 로직이 명확히 분리됨 - 서버 재사용성: 다양한 클라이언트에서 동일 서버 기능 사용 가능 - 확장성 및 병렬성: 서버 성능 확장을 통해 다수 클라이언트 대응 가능 - 고성능 서버로 자원 효율적 활용 가능 |
| 단점 | - 보안 이슈: 클라이언트와 서버 간 민감 정보 전송 시 보안 취약 - 서버 병목 현상: 클라이언트 수 증가 시 서버가 성능 저하될 수 있음 - 단일 장애점(SPOF): 서버 장애 시 전체 서비스 불가 - 테스트 한계: 네트워크 및 서버 상태에 따라 테스트 복잡도 증가 |
| 예시 | 웹 브라우저(클라이언트) ↔ 웹 서버, 이메일 클라이언트 ↔ 메일 서버, FTP 클라이언트 ↔ FTP 서버 |
| 그림 |  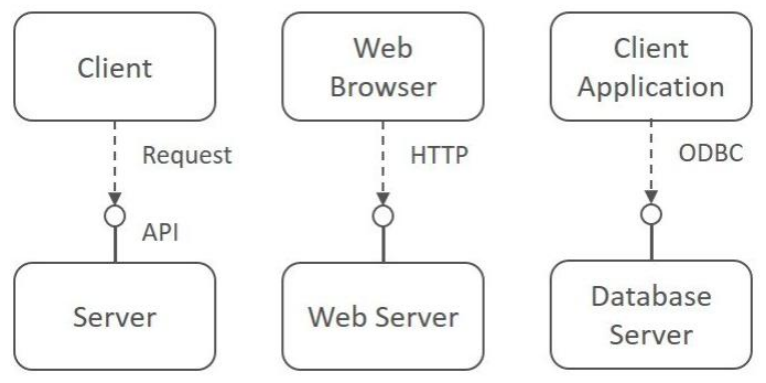 |
- Variant
- Thin vs. Thick Client
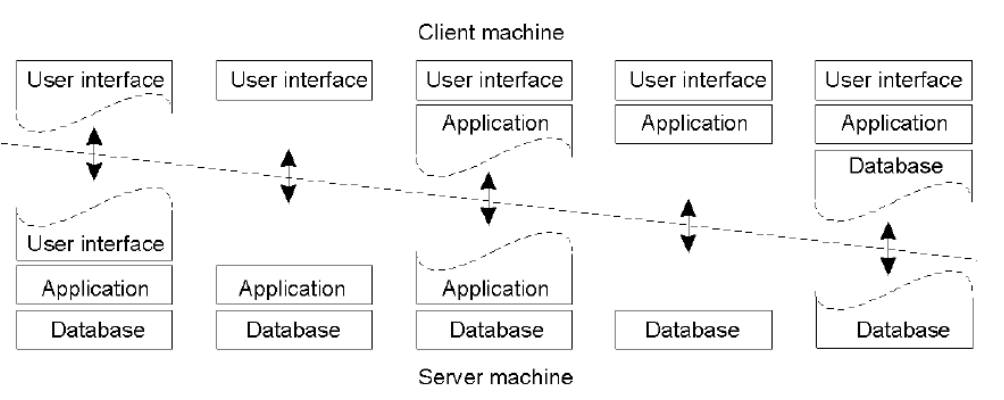
- Thin vs. Thick Client
Broker Architecture Style
| 항목 | 내용 |
|---|---|
| 정의 | 클라이언트(Client)와 서버(Server) 간 통신을 중재자(Broker)가 중간에서 조정하는 분산 컴퓨팅용 미들웨어 아키텍처. 컴포넌트 간 직접 연결 없이 브로커를 통해 메시지 전달이 이루어짐. |
| Elements (구성 요소) | - Client: 서버 메서드를 호출하려는 컴포넌트. 브로커를 통해 요청을 보냄 - Server: 브로커에 등록되어 메서드 인터페이스를 제공하고 실제 로직을 수행 - Broker: 클라이언트 요청을 받아 적절한 서버로 전달하고 응답을 되돌려주는 중재자 역할 수행 - Bridge (옵션): 서로 다른 프로토콜을 가진 브로커 시스템 간 통신을 가능케 하는 다리 역할 |
| Relations (관계) | - 클라이언트는 브로커를 통해 서버 메서드를 호출함 - 브로커는 요청을 적절한 서버에 전달하고, 결과를 다시 클라이언트에 반환 - 브리지(Bridge)는 다른 네트워크나 브로커 간 통신을 중개 |
| Constraints (제약 조건) | - 서버는 브로커에 등록되어야 하며, 인터페이스는 동일 형식 유지 - 클라이언트와 서버 간 직접 상호작용 없음 |
| 장점 | - 위치 투명성(Location Transparency): 클라이언트는 서버의 실제 위치를 알 필요 없음 - 변경 용이성(Changeability): 서버 내부 변경이 인터페이스에 영향을 주지 않으면 클라이언트 영향 없음 - 재사용성 및 확장성: 기존 서비스 재활용, 서버 동적 추가/제거 가능 - 이식성 및 상호 운용성: 브로커가 클라이언트와 서버의 operating 및 network system의 detail을 숨겨주는 기능을 하고, 브리지를 통해 이질적인 시스템도 간접적으로 연동 가능 |
| 단점 | - 비효율성: 프록시/브로커를 거치는 간접 경로로 인해 성능 저하 가능 - 낮은 장애 허용성(Fault Tolerance): 브로커나 서버 장애 시 전체 시스템 영향 가능 - 테스트 및 디버깅 어려움: 다수 컴포넌트 간 연계로 문제 추적 어려움 |
| 예시 | CORBA, Java RMI, .NET Remoting, Apache Camel, gRPC with Service Registry |
| 그림 | 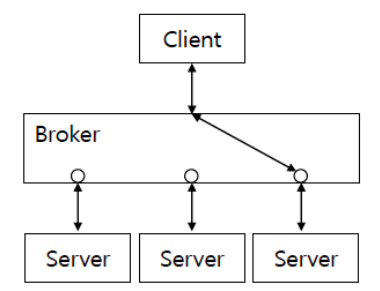 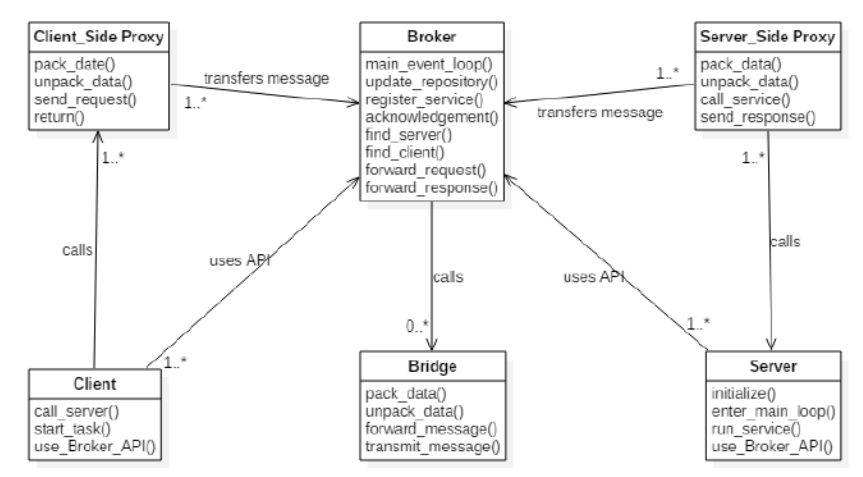 |
Dispatcher Style
| 항목 | 내용 |
|---|---|
| 정의 | 클라이언트(Client)와 서버(Server) 사이에 디스패처(Dispatcher)라는 intermediate layer를 두어, 클라이언트가 원하는 서버와 연결을 수립하게 해주는 구조. 일종의 단순화된 브로커 스타일로, 서버의 위치를 찾고 연결을 도와주는 데 중점을 둠. |
| Elements (구성 요소) | - Client: Dispatcher에게 서버 연결을 요청하고, 해당 서버의 서비스를 이용함 - Server: Dispatcher에 등록된 후, 서비스를 제공함 - Dispatcher: 서버 등록 및 위치 매핑 유지, 클라이언트 요청에 따라 통신 채널 설정 |
| Relations (관계) | 클라이언트는 Dispatcher에게 서버 연결을 요청하고, Dispatcher는 해당 서버를 찾아 연결을 설정함. 서버는 Dispatcher에 자신을 등록하고, Dispatcher는 서버 위치를 관리 |
| Constraints (제약 조건) | - Dispatcher는 서버와 클라이언트 사이의 중계자로서 경량화되어야 함 - 서버 인터페이스의 변경은 Dispatcher와 클라이언트에 영향을 줄 수 있음 |
| 장점 | - 서버 교체 및 확장 용이성: Dispatcher나 클라이언트를 수정하지 않고도 서버 추가/변경 가능 - 위치 및 이동 투명성: 서버를 다른 머신으로 동적으로 마이그레이션 가능 - 유연한 재구성: 시스템 구성 시점이나 실행 중에도 서버 설정 가능 - 장애 허용성(Fault Tolerance): 서버 장애 시 다른 머신에서 대체 서버 활성화 가능 |
| 단점 | - Dispatcher 자체의 오버헤드 발생 가능 - Dispatcher 인터페이스 변경 시 전체 구조에 민감한 영향을 줄 수 있음 |
| 예시 | RPC with Dispatcher, Lightweight Naming Service, Custom Service Router |
| 그림 | 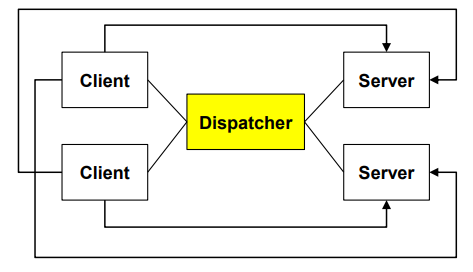 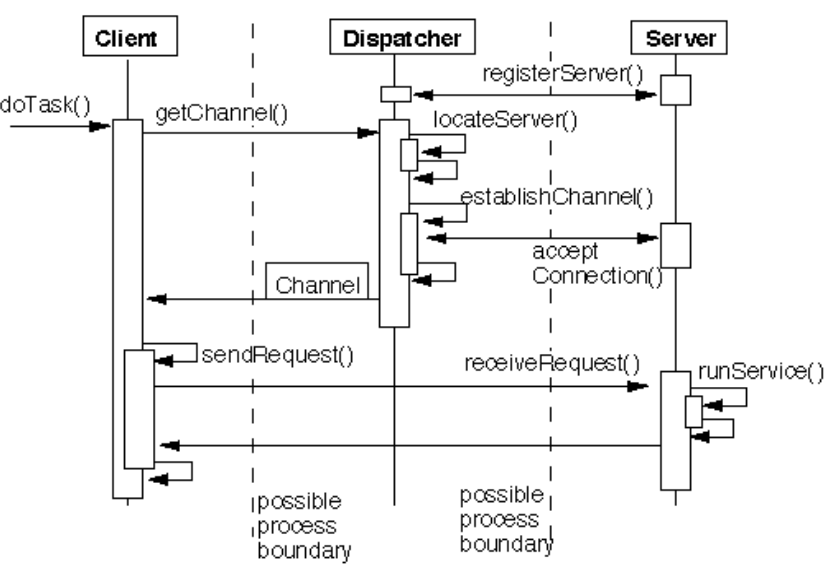 |
Service-Oriented Architecture (SOA) Style
| 항목 | 내용 |
|---|---|
| 정의 | 서로 독립적인 서비스들이 네트워크를 통해 상호작용하며, 표준화된 인터페이스를 통해 서비스가 제공되는 아키텍처 스타일. 서비스는 명확하게 정의되고, 독립적이며, 재사용 가능한 비즈니스 기능 단위로 구성됨. |
| Elements (구성 요소) | - Service Provider: 서비스 기능을 제공하며, 인터페이스를 통해 외부에 공개함. 서비스 정보는 intermediary component(Service Registry)에 등록됨 - Service Consumer: 필요 시 서비스를 호출하여 사용함. 직접 또는 중재자를 통해 접근 가능 - Intermediary Component (Service Registry or Middleware): Potential service consumer들이 서비스를 이용 가능하게 함과 동시에, 서비스 정보를 저장하고, 소비자에게 제공하며, 메시지를 라우팅하고 변환하는 역할 |
| Relations (관계) | Service Provider는 서비스를 정의하고 Intermediary에 등록함. Service Consumer는 Intermediary를 통해 서비스 정보를 탐색하고, 직접 또는 간접적으로 서비스를 호출함. |
| Constraints (제약 조건) | - 서비스는 stateless 하게 설계되어야 함 - 공개된 인터페이스를 통해 접근 가능해야 함 - 플랫폼/언어/기술에 독립적이어야 함 |
| 장점 | - 모듈성 및 진화 용이성: 서비스 구현 변경이 인터페이스를 유지하는 한 다른 시스템에 영향 없음 - 상호운용성(Interoperability): 플랫폼, 언어, 기술에 상관없이 서비스 간 통신 가능 - 재사용성: 하나의 서비스를 다양한 소비자가 재사용 가능 - 확장성 및 부하 분산: 서비스별로 다른 프로세스나 머신에서 실행 가능하여 수평 확장 가능 |
| 단점 | - 구현 복잡성: 시스템 간 연계가 많아 설계 및 구현이 복잡해짐 - 성능 오버헤드: 미들웨어 통신, 서비스 탐색 등으로 인한 지연 발생 - 제어 불가능한 외부 서비스 진화: 외부 서비스 변경이 전체 시스템에 영향 줄 수 있음 |
| 예시 | Web Services (SOAP, WSDL), XML/JSON 기반 인터페이스, Enterprise Service Bus (ESB) |
| 그림 | 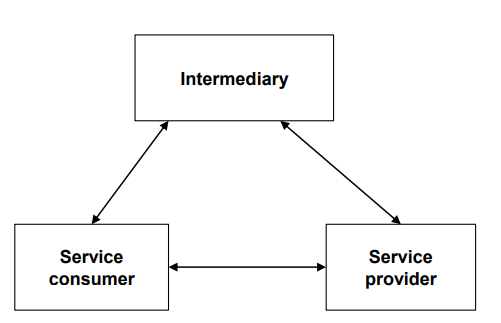 |
Microservice Architecture Style
| 항목 | 내용 |
|---|---|
| 정의 | 작고 자율적인 서비스들로 구성된 아키텍처로, 각 서비스는 하나의 비즈니스 기능을 독립적으로 수행하고, 명확하게 정의된 API를 통해 상호작용함. 서비스 간 결합을 최소화하고, 독립 배포 및 확장성을 강조함. |
| Elements (구성 요소) | - Microservice: 각각 독립적인 코드베이스와 데이터 저장소를 가지며, 독립 배포 및 기술 스택 사용이 가능함. 단일 기능에 집중하며 내부 구현은 외부에 노출되지 않음 - API Gateway: 클라이언트의 진입점으로, 내부 마이크로서비스로 요청을 전달하고 응답을 집계 - Management/Orchestration: 서비스 배치, 장애 감지, 리밸런싱 등의 시스템 전반을 관리 |
| Relations (관계) | - 클라이언트는 API Gateway를 통해 요청하고, Gateway는 적절한 Microservice에 라우팅 - Microservice는 서로 독립적이지만, 명시적 API를 통해 통신하며 상태와 데이터는 각 서비스가 자체 관리 |
| Constraints (제약 조건) | - 서비스는 작고 자율적이어야 하며, 단일 책임 원칙을 따름 - 각 서비스는 자체 데이터 저장소를 가지며, 다른 서비스와 공유하지 않음 - 서비스 간 느슨한 결합과 명확한 API 계약 유지 필요 |
| 장점 | - Agility: 서비스 단위로 빠르게 배포 및 롤백 가능 - 확장성: 성능 병목 서비스만 개별 확장 가능 - Fault Isolation: 특정 서비스 오류가 전체 시스템에 영향 미치지 않음 - 기술 다양성 허용: 서비스마다 기술 스택 자유롭게 선택 가능 - 데이터 격리: 스키마 변경 시 다른 서비스에 영향 없음 |
| 단점 | - 복잡성 증가: 전체 시스템 관점에서는 구성과 통신 복잡도가 커짐 - 테스트 어려움: 서비스 간 의존성으로 인해 통합 테스트 어려움 - 거버넌스 부족: 기술 스택 다양성으로 관리 및 유지보수 복잡해질 수 있음 - 네트워크 비용: 서비스 간 통신이 증가하며, 지연(latency) 및 병목 발생 가능 - 데이터 무결성: 분산 데이터 관리로 인해 일관성 유지 어려움 - 버전 관리: 여러 서비스 동시 업데이트 시 하위 호환성 문제 발생 가능 |
| 예시 | RESTful Web Service, Netflix, Amazon, Uber, Spotify, Spring Cloud 기반 MSA 시스템 |
| 그림 | 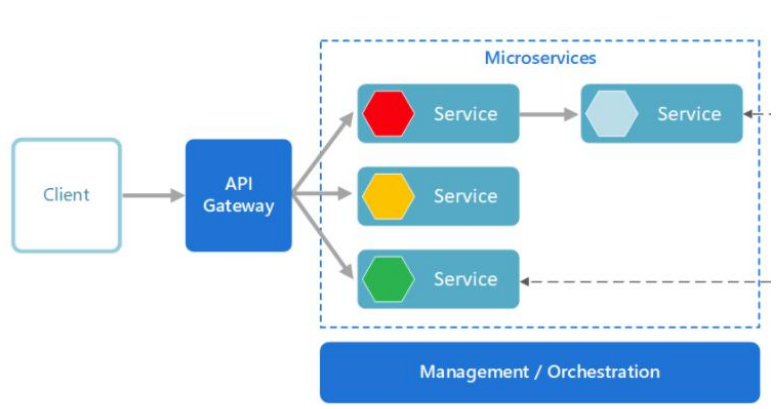 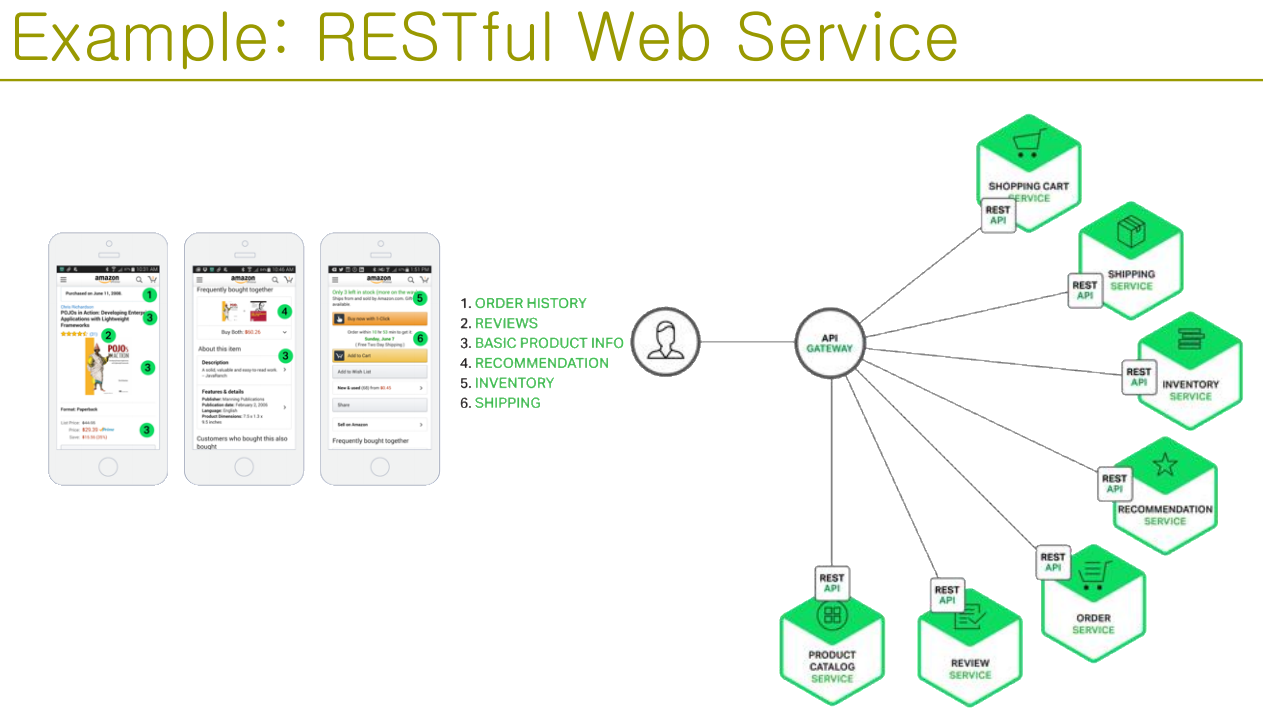 |
- SOA vs Microservice Architecture
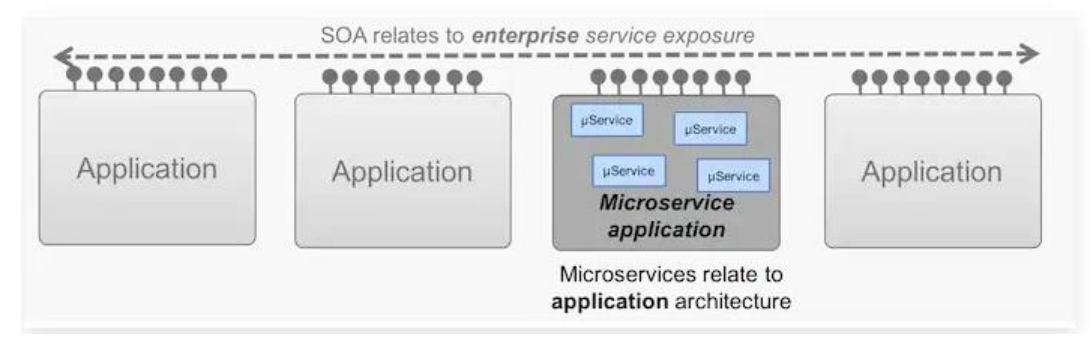
| 항목 | SOA (서비스 지향 아키텍처) | Microservice Architecture (마이크로서비스 아키텍처) |
|---|---|---|
| 적용 범위(Scope) | 엔터프라이즈(Enterprise) 전체 수준 | 개별 애플리케이션(Application) 수준 |
| 구조 | 각기 다른 애플리케이션들이 서비스를 노출하고 이를 통합함 | 하나의 애플리케이션 내부가 여러 마이크로서비스로 구성됨 |
| 서비스 노출 | 서비스들이 기업 전반에서 외부 또는 내부로 노출됨 | 애플리케이션 내부 컴포넌트들이 작은 단위 서비스로 나뉘어 있음 |
| 목표 | 시스템 간의 재사용성과 통합성 향상 | 애플리케이션의 유연성, 확장성, 독립 배포 지원 |
→ SOA는 기업 전체의 여러 애플리케이션 간 서비스 통합과 공유에 중점을 두는 반면,
Microservice Architecture는 단일 애플리케이션을 작고 독립적인 서비스로 분할에 중점
Edge Computing Architecture Style
| 항목 | 내용 |
|---|---|
| 정의 | 데이터를 생성하는 현장(Edge)에서 가까운 위치에서 처리 및 분석을 수행하는 분산 아키텍처 스타일. 클라우드에 의존하지 않고, 로컬 장치 또는 네트워크 경계에서 처리함으로써 속도, 프라이버시, 자율성을 확보할 수 있음. ↔ Cloud computing |
| Elements (구성 요소) | - Edge Devices: 센서, 카메라 등 데이터를 수집하거나 사용자와 상호작용하는 실제 장치 - Edge Nodes: 엣지 네트워크에서 실행되는 on-premises 시스템. 데이터 전처리, 필터링, 응답 등을 담당 - Cloud / Remote Data Centers: 중앙 데이터 저장, 고성능 처리, 백업 및 전체 서비스 제공 |
| Relations (관계) | - Edge Device는 데이터를 수집하고 Edge Node에 전달 - Edge Node는 데이터를 실시간 처리하거나 필터링 후 일부만 클라우드로 전송 - 클라우드는 중장기 저장, 고급 분석, 중앙 관리를 수행 |
| Constraints (제약 조건) | - 실시간 또는 준실시간 처리를 위해 Edge Node의 컴퓨팅 성능 필요 - 시스템은 중앙 장애 없이도 로컬에서 독립 동작 가능해야 함 |
| 장점 | - 속도 향상: 사용자와 가까운 위치에서 연산 수행 → 지연(Latency) 최소화 - 프라이버시 보장: 민감한 데이터를 클라우드로 전송하지 않고 로컬 처리 가능 - 가용성 확보: 중앙 장애 발생 시에도 로컬에서 시스템 유지 가능 |
| 단점 | - 보안 취약성: 분산된 여러 장치에서 데이터 처리 → 해킹/유출 위험 증가 - 도입 비용: 엣지 인프라 구축에 따른 초기 하드웨어 및 네트워크 비용 부담 - 운영 복잡성: 많은 엣지 장치에 대한 배포, 업데이트, 모니터링 필요 |
| 예시 | AWS Greengrass, 스마트 팩토리, 자율주행차, 스마트시티, 산업 IoT 시스템 |
| 그림 | 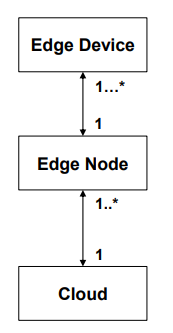 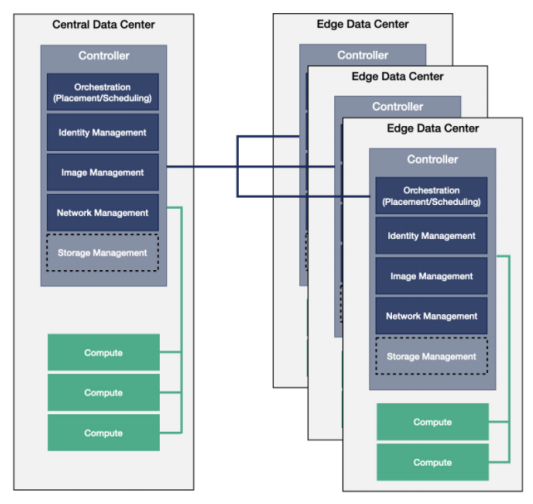 |
3. Pattern vs Style
3.1 패턴(Pattern)이란?
- 정의: 반복적으로 발생하는 문제에 대해 반복적으로 사용되는 해결책
- 구성:
- Context: 문제가 발생하는 상황
- Problem: 반복적으로 발생하는 문제 (요구사항, 제약 조건 등)
- Solution: 문제 해결 방법 (구조 및 동작)
- Structure (구조): 구성 요소와 이들의 역할 및 관계를 명시
- Dynamics (동작): 구성 요소들이 어떻게 협력하는지 설명
- 패턴의 분류:
- Architectural Pattern: 아키텍처 수준의 설계 패턴 (예: Layered Architecture)
- Design Pattern: 컴포넌트 수준의 설계 패턴 (예: MVC, Observer 등)
- Idioms: 코드 구현 수준의 반복되는 관용적 표현 (예: RAII, Resource Acquisition Is Initialization: 자원 관리를 객체 생명주기에 묶는 방식)
3.2 스타일(Style)이란?
- 정의: 유사한 소프트웨어 아키텍처들의 구조적 특성을 추상화한 것
- 구성:
- 특정한 아키텍처 구성 요소 유형
- 요소 간의 관계
- 토폴로지와 동작에 대한 제약 조건
- 예시: Layered, Pipe-and-Filter, Client-Server 등
3.3 Pattern과 Style의 차이점
| 항목 | Pattern (패턴) | Style (스타일) |
|---|---|---|
| 중심 개념 | 문제 중심의 해결 방식 | 아키텍처의 구조적·행위적 특성 |
| 목적 | 반복되는 문제에 대한 효과적인 솔루션 제공 | 아키텍처 구조를 분류하고 이해를 돕기 위함 |
| 표현 요소 | Context, Problem, Solution(Structure + Dynamics) | 구성 요소 + 관계 + 제약 조건 |
| 예시 | MVC, Broker Pattern 등 | Layered, Client-Server, Blackboard 등 |
| 적용 시점 | 특정 문제 해결이 필요한 상황 기반 | 구조적 특성 정의를 위한 전체 시스템 수준 설계 시점 |
| 관계 | 종종 스타일과 혼용되어 사용되기도 함 | 패턴과 유사한 개념으로 간주되기도 함 |
즉,
- 패턴은 문제 해결 중심,
- 스타일은 구조 정의 중심
- 하지만 소프트웨어 아키텍처 스타일의 개념은 패턴의 개념과 매우 유사하기 때문에, 아키텍처 분야에서는 "스타일"과 "패턴"이라는 용어를 서로 바꿔 사용할 수 있음.
→ 스타일을 그냥 아키텍쳐 판 디자인 패턴이라고 이해해도 될 듯
