1. 검색 증강 생성(RAG, Retrieval-Augmented Generation)이란?
RAG(Retrieval-Augmented Generation)는 대형 언어 모델(LLM)이 가진 한계를 보완하기 위한 핵심 기술로,
정보 검색 + 생성 모델 기반의 자연어 처리(NLP) 기술
RAG는 기술(개념)을 의미하고, Langchain은 RAG를 구현할 수 있는 AI 어플리케이션 개발 프레임워크를 의미
2. Why use: LLM의 한계
대형 언어 모델은 매우 뛰어난 자연어 처리 능력을 가지고 있지만,
아래와 같은 문제를 피할 수 없음:
- 답이 없을 때 허위 정보를 생성함
- 최신 정보 반영 불가 (훈련 시점 이후의 데이터 미포함)
- 신뢰할 수 없는 출처 기반의 응답 가능성
- 동일 용어의 중의적 사용으로 인한 개념 혼동
따라서, RAG는
대답하기 전에 새로운 최신 데이터를 한번 훑어본 다음에 답하라고 지시하는 것
3. RAG의 핵심 개념
검색기(Search)과 생성기(Generation)를 결합한 아키텍처 사용
- 검색기: 입력이 주어지면 관련 문서 검색
- 기존의 검색 시스템 주로 사용(BM25, DPR)
- 생성기: 검색된 문서를 기반으로 응답 생성
- 주로 Transformer 기반 언어 모델(BART, T5)
구분 BM25 DPR 방식 통계 기반 (단어 일치) 딥러닝 기반 (의미 유사도) 입력 단위 단어 (bag-of-words) 문장/문서 임베딩 (vector) 장점 빠르고 가벼움, 해석 용이 의미 기반 검색, 유연한 매칭 단점 동의어/문맥 이해 불가 모델 학습 필요, 계산량 큼 활용 예 뉴스·키워드 검색, 고전 IR 시스템 RAG, QA 챗봇, 시맨틱 검색
4. RAG Flow
- 사용자 질문 입력
- 질문을 벡터(임베딩)로 변환 후 벡터 데이터베이스 검색(인코딩 & 유사도 계산)
- 관련 문서·지식 조각(Retrieved Documents) 획득
- 검색된 정보를 LLM 입력 프롬프트에 추가 (Context Expansion)
- LLM이 최신 정보 기반으로 응답 생성
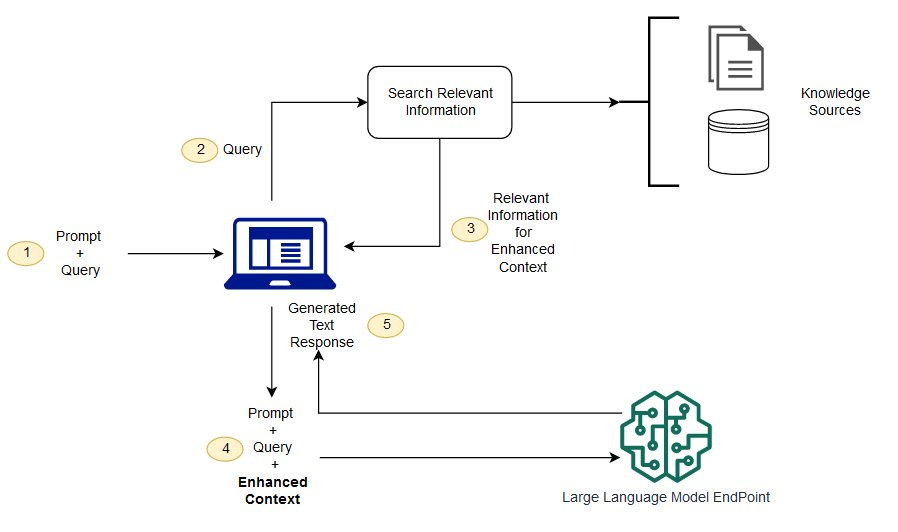
5. RAG의 주요 이점
1. 비용 효율성
- 파운데이션 모델(FM)을 다시 학습시키는 것은 막대한 비용이 듦
- RAG는 LLM을 재학습하지 않고도 새 데이터를 연결할 수 있어 훨씬 경제적
2. 최신성
- 모델이 과거 학습 데이터만으로 답하지 않고,
실시간으로 외부 소스(API, DB, 문서 저장소 등)를 조회하여 최신 정보를 반영할 수 있음
3. 신뢰성
- LLM이 응답 시 출처(Source) 또는 인용(Reference)을 함께 제공할 수 있음
- “왜 이런 답을 했는가?”에 대한 투명성을 확보해 사용자의 신뢰를 높임
- 개발자 제어 강화
- LLM이 사용할 지식 소스를 조직 내부 데이터로 제한하거나 변경할 수 있음
- 또한, 특정 인증 수준에 따라 정보 접근을 제어하는 것도 가능함
- LLM이 참고하는 지식의 품질과 범위를 개발자가 직접 통제할 수 있음
6. 최소 예시 (LangChain 기준, 개념 맛보기)
# ✅ 0. 패키지 설치
# pip install langchain openai faiss-cpu tiktoken
# ✅ 1. 문서 → 청크 분리
from langchain.text_splitter import RecursiveCharacterTextSplitter
docs = [
"사내 휴가 규정: 연차는 입사 월 기준으로 발생함.",
"경조사 휴가 규정: 결혼 시 5일, 부모상 7일, 자녀 출산 3일."
]
splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=50)
chunks = splitter.create_documents(docs)
print(f"✅ 생성된 청크 수: {len(chunks)}")
print(chunks[0].page_content)
# ✅ 2. 임베딩 & 벡터DB 구축 (FAISS)
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
vdb = FAISS.from_documents(chunks, embeddings)
# ✅ 3. 리트리버 & 생성 체인 구성
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vdb.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
# ✅ 4. 질의 수행
query = "결혼하면 며칠 휴가임?"
res = qa_chain({"query": query})
print("🧾 질문:", query)
print("💬 답변:", res["result"])
print("📚 근거 문서:")
for doc in res["source_documents"]:
print("-", doc.page_content)
실제 서비스에서는 PDF/웹/DB 로더, 권한 필터, 하이브리드 검색 등을 덧붙이면 됨

만두는 목말라