- 내용
- k8s 클러스터의 기본적인 아키텍쳐를 다룬다.
- 읽기 전에
k8s는 기본적으로 Current State, Desired State 라는 개념을 알아야 동작을 이해하기 쉽다.
Current State는 현재 상태
Desired State는 원하는 상태 또는 바라는 상태라고 표현한다.
아래의 내용을 반드시 기억하자.
k8s는 개발자가 원하는 상태(desired state)를 선언하면 그 상태로 만들고
그 상태를 현재 상태(current state)로 유지하기 위해
(클러스터 아키텍쳐의) 여러 컴포넌트들이 상호작용한다.
이제, 저 내용을 기억하고 클러스터 아키텍쳐의 구성요소를 살펴보자.
- k8s 클러스터 아키텍쳐
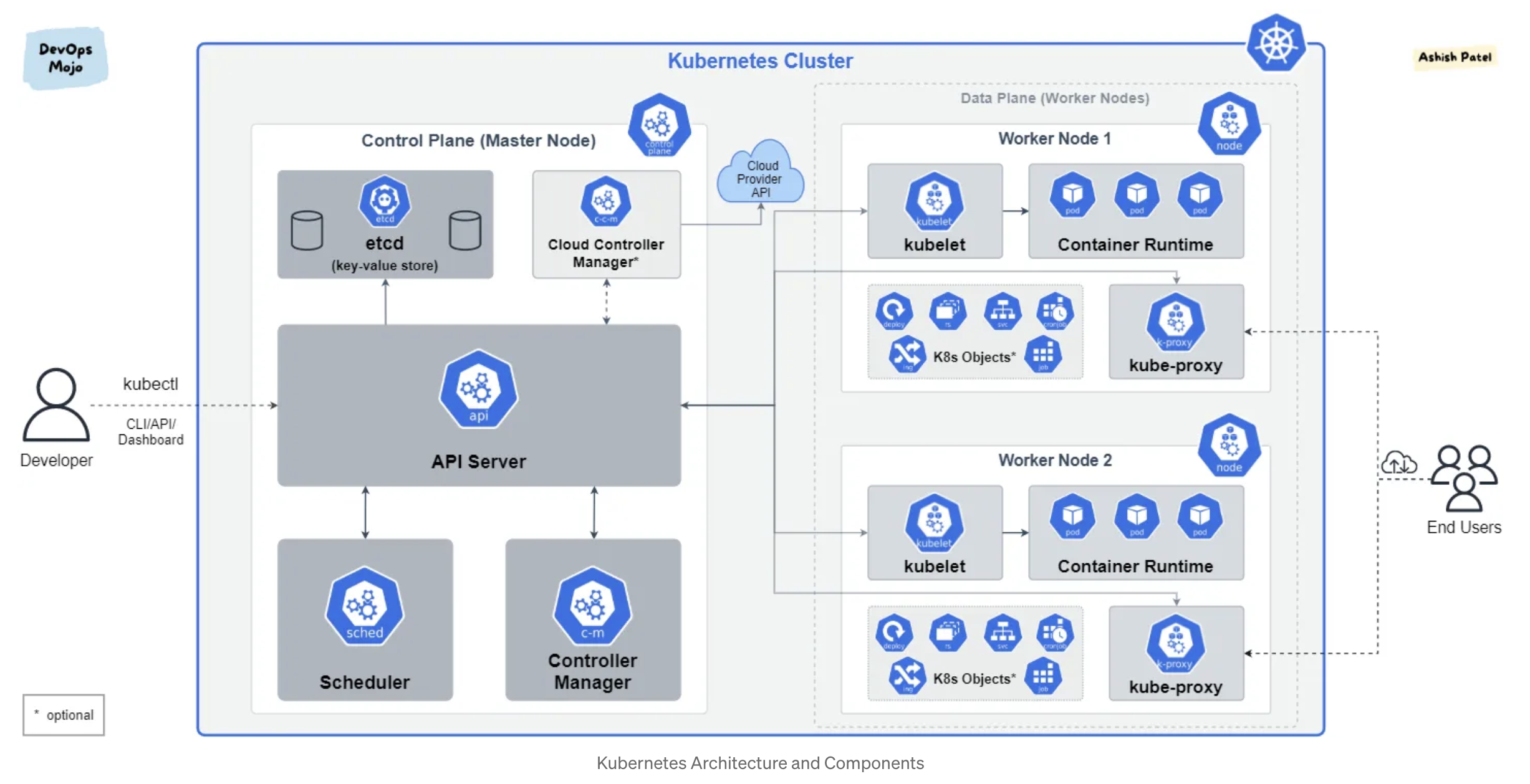
아키텍쳐는 크게 두 부분(Control Plane, Data Plane)으로 구분된다.
- Control Plane (Master Node)
- API Server (kube-apiserver)
- Controller Manager (kube-controlelr-manager)
- Scheduler (kube-scheduler)
- etcd
- Cloud Controller Manager (cloud-controller-manager)
- Data Plane = Worker Node
- kubelet
- kube-proxy
- container runtime
- 클러스터 아키텍쳐의 구성 요소들에 대하여.
k8s도 일반적인 클러스터 시스템과 마찬가지로 마스터와 워커로 구분된다.
마스터 노드(Master Node)를 컨트롤 플레인(Control Plane)이라고도 하고,
워커 노드(Worker Node)를 데이터 플레인(Data Plane)이라고도 한다.
클러스터는 k8s를 실행하면 생기는 영역이고,
모든 클러스터는 최소 한 개 이상의 Master Node와 Worker Node를 가진다.
1. Master Node (Control Plane)
제어 영역에 해당하며 크게 5개의 컴포넌트로 구성된다.
1) kube-apiserver
- 마스터로 전달되는 모든 요청을 받아들이는 API Server.
- 요청을 받아들이는 것 외에 다른 컴포넌트에게 요청을 보내는 역할도 수행한다. (
k8s 클러스터 아키텍쳐이미지 참고) - 사용자도 kubectl을 이용하여 API Server에 명령을 보내고 응답을 받는다.
2) etcd
- 클러스터 내의 모든 메타 정보를 저장하는 저장소.
- 클러스터에 필요한 모든 데이터를 저장하는 DB 역할을 수행한다.
- 일반적인 RDB가 아닌 분산형 key-value 저장소이다.
- 운영 환경에서 클러스터는 마스터 노드를 최소 3개 이상으로 구성하는 걸 권장한다.
이 경우, 마스터 노드마다 ETCD 복제본을 유지함으로써 고가용성을 확보한다.
이러한 것을고가용성을 위해 ETCD Cluster를 구성하여 안정성을 높일 수 있다라고 할 수 있다.
- 운영 환경에서 클러스터는 마스터 노드를 최소 3개 이상으로 구성하는 걸 권장한다.
3) kube-controller-manager
- 현재 상태(Current State)와 바라는 상태(Desired State)를 지속적으로 확인하며 특정 이벤트에 따라 특정한 동작을 수행하는 컨트롤러.
- kube-controller-manager는 다양한 컨트롤러들을 관리한다.
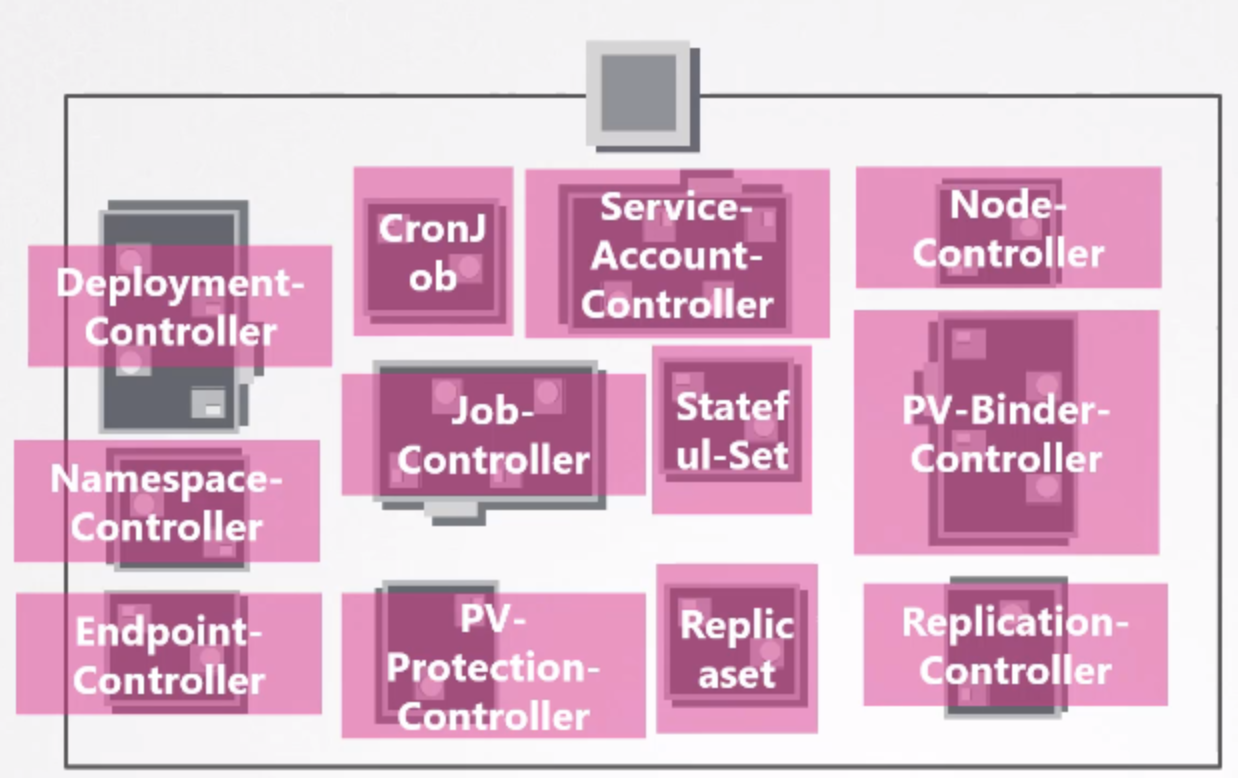 (참고로, 위 이미지에 나온 것보다 많은 컨트롤러를 관리한다.)
(참고로, 위 이미지에 나온 것보다 많은 컨트롤러를 관리한다.) - kube-controller-manager에서 제공하는 설정과 그에 따른 동작들.
--node-monitor-period = 5s: 5초 간격으로 Node의 상태를 모니터링한다.--node-monitor-grace-period = 40s: Node가 실제로 장애로 판단되었을 때NotReady상태를 40초간 유지합니다.
이 시간 내에 Node가 다시Ready상태로 전환되지 않으면 해당 Node는 클러스터에서 제거되거나 문제가 있는 것으로 판단될 수 있다.
* 이 옵션을 설정함으로써, 클러스터 운영자는 Node의 장애 감지 및 장애 처리에 대한 정책을 조정하고 클러스터의 안정성을 높일 수 있다.--pod-eviction-timeout = 5m0s: Pod를 다른 Node로 옮길 때 최대 대기 시간을 의미하며,
노드가 제거되기로 결정된 후 해당 노드에 있는 파드들은 이 시간 내에 다른 노드로 이동해야 한다.--pod-eviction-budget = 5: 노드가 제거되기로 결정된 후 클러스터를 기준으로 동시에 몇 개의 파드가 옮겨질 수 있는지에 대한 제한 설정이다.
- 실질적으로 Node에 배치되지 않은 Pod를 생성하는 것은 Controller 이다!
4) kube-scheduler
- kube-scheduler는 kube-controller-manager가 어떤 POD를 띄워야 한다고 했을 때, 어떤 Node에 띄워야 하는지 결정한다.
- kube-scheduler는 POD를 띄울 Node를 결정하기 위해 클러스터 내의 리소스를 관리합니다.
- kube-scheduler는 리소스 활용과 성능을 최적화하고, 클러스터의 안정성과 가용성을 높이는 역할을 한다.
노드 선택: 파드가 생성될 적절한 노드를 선택한다.리소스 관리: 각 노드의 리소스량을 고려하여 파드를 배치할 수 있도록 한다.균형 유지: 노드의 리소스 사용량을 균형있게 유지한다.어피니티, 안티 어피니티 설정: 파드와 노드 간에 배치를 근접하게 하거나, 피하도록 한다.
즉, 노드와 관련성있는 파드를 배치하거나 분리할 수 있다.
5) cloud-controller-manager
- 클라우드 플랫폼에 특화된 리소스를 제어하는 클라우드 컨트롤러.
2. Worker Node (Data Plane)
Master Node의 API Server로 부터 명령을 전달 받아 수행한다.
1) kubelet
- 마스터의 명령에 따라 컨테이너의 라이프 사이클을 관리하는 노드 관리자.
- 컨테이너를 실행하기 위해 상세 명세(spec)을 받아 실행시키고, 해당 컨테이너가 정상적으로 동작하는지 모니터링한다.
- Master Node의 API Server와 주기적으로 통신하여 필요한 정보를 주고 받는다.
ex) 노드의 상태 정보, 리소스 사용량 등.
2) kube-proxy
- 각 노드에 위치하며 컨테이너의 네트워킹을 책임지는 컴포넌트.
- 서비스마다 개별 IP를 가질 수 있게 만들어준다.
- 클러스터 내/외부의 트래픽을 POD로 전달할 수 있도록 패킷을 라우팅한다.
3) container runtime
- 실제 컨테이너를 실행하는 컨테이너 실행 환경.
- 도커 뿐 아니라, CRI(Container Runtime Interface) 규약을 따른다면 어떠한 런타임도 k8s의 컨테이너 실행 환경으로 사용할 수 있다.
- 참고

개발 관련 내용을 가끔 쓰고 싶어서 만든 블로그입니다.