정규화
ERD내에서 중복요소를 찾아 제거해 나가는 과정
데이터베이스 정규화 절차
함수 종속성을 이용해 릴레이션을 연관성이 있는 속성들로만 구성되도록 분해해서 이상현상이 발생하지 않도록 Step By Step Approach로 수행
제 1 정규화
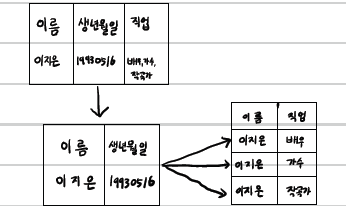
같은 성격과 내용의 컬럼이 연속적으로 나타내는 컬럼이 존재할 때, 해당 컬럼을 제거하고 기본테이블의 PK를 추가해 새로운 테이블을 생성하고, 기존의 테이블과 1:N 관계를 형성하는 것
-> 모든 속성은 반드시 하나의 값만 가져야됨 => 원자값
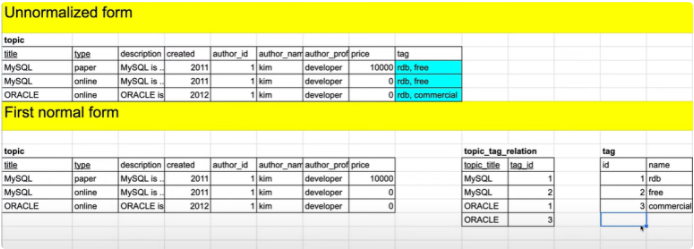
tag 필드를 보면, 값들이 여러개가 있다 하나의 필드에 값들이 여러개 있으며 안된다.
이를 정규화 시키면
1. 우선 하나의 title과 여러개의 tag를 갖는다. 또한 하나의 tag(rdb)는 여러개의 title(MySQL, Oracle)을 갖는다.
2. 그러면 title과 tag를 테이블 두 개로 분리했을 때 이들의 관계는 M:N이 된다.
3. M:N을 표현하기 위해선 테이블 3개를 만들어야 한다.
4. title과 topic 테이블을 분단시키고, 그 중간경로 테이블인 topic_tag_relation을 만든다. 그리고 각 테이블을 이어올 새로운 태그 tag_id 속성을 만든다.
5. 각각 1:N 관계를 연결해주면 정규화가 완료한 것.
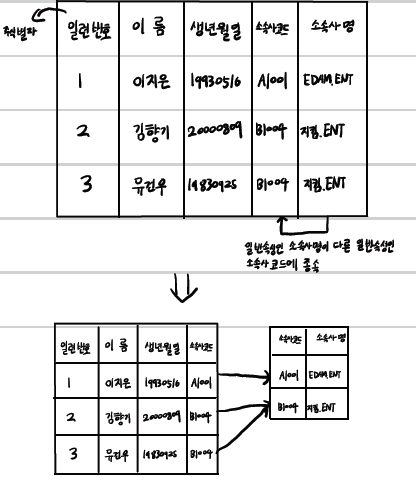
제 2 정규화
PK가 여러 키로 구성된 복합키로 구성된 경우가 2차 정규화의 대상이 되며, 복합키 전체에 의존하지 않고 복합키의 일부분에만 종속되는 속성들이 존재할 경우 (즉, 부분적 함수 종속 관계) 이를 분리 하는 것
-> 엔티티의 일반속성은 주식별자 전체에 종속 > 완전 종속 => 부분 함수 종속 제거
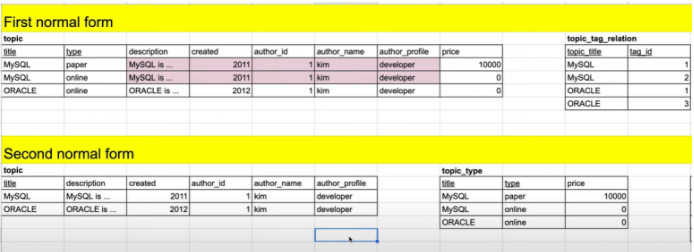
1. 제 1정규화를 마친 테이블을 보면, 중복되는 레코드(적갈색)가 보인다.
2. 저 부분이 중복되어 나타나는 이유는 type와 price 필드 값이 각기 다르기 때문이다.
3. 그러면 각기 다른 부분을 테이블로 나누고 중복부분을 하나로 표현 되게 해보자
4. 먼저 중복이 나타나게 한 원인 필드인 type와 price 필드를 따로 빼서 topic_type 테이블을 만든다.
5. 그러고 topic_type에서 식별 할 수 있는 외래키 title을 등록
6. 이렇게 하면, 중복되는 것이 없이 title이 MySQL이냐 아니냐에 따라 topic 테이블에선 저자정보, topic_type 테이블에선 가격과 타입을 각각 나타낼 수 있게 된다.
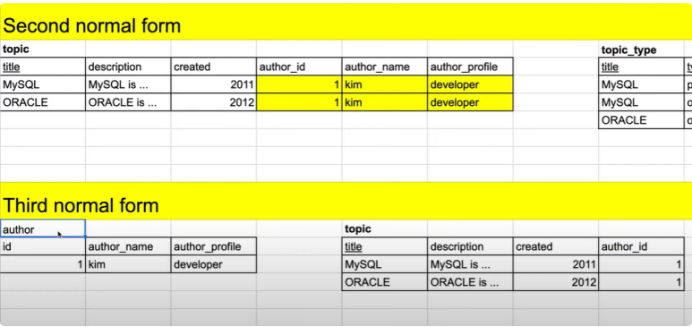
제 3 정규화
테이블의 키가 아닌 컬럼들은 기본키에 의존해야 하는데 겉으로는 그런 것처럼 보이지만 실제로는 기본키가 아닌 다른 일반 컬럼에 의존하는 컬럼들이 있을 수 있다.
이를 이전적 함수 종속 관계 라고 한다.
제 3정규화는 PK에 의존하지 않고 일반 컬럼에 의존하는 컬럼들을 분리한다.
-> 엔티티의 일반속성 간에는 서로 종속 X => 이행 종속 제거
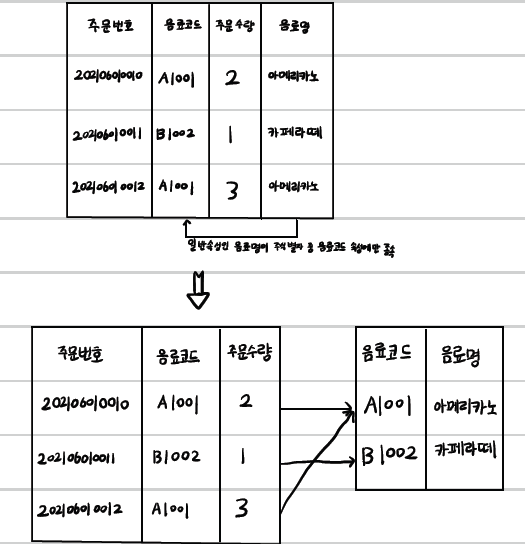
1. 제 2정규화를 마쳤지만 여전히 중복된 값(노란색)이 보인다.
2. 저 레코드는 author_id에 의존하는 컬럼들이다. 언뜻보면 title에 의존하는 것처럼 보이지만 아닌 것이다.
3. 그럼 PK(title)에 의존하지 않는 컬럼들을 분단
4. author라는 테이블을 만들고 중복되는 컬럼들 3개를 그대로 따온다. 그리고 topic 테이블과 author_id로 외래키 관계를 맺어준다. 그러면 중복이 사라지는 것을 볼 수 있다.
반정규화
- 정규화 된 데이터 모델(엔티티, 속성, 관계)에 대해 성능 향상, 개발, 운영의 단순화를 위해 데이터를 중복, 통합, 분리하는 기법
- 정규화 시 엔티티의 갯수 증가 -> 여러 조인 요구 -> 이런 경우 디스크 I/O 양이 많아져 성능이 저하되거나 경로가 멀어서 조인으로 인한 성능 저하가 예상
특징
- 조회(SELECT) 속도 향상
- -> 입력/수정/삭제 성능 저하
테이블 반정규화
테이블 병합 테이블 분할 테이블 추가 1:1 관계 테이블 병합 테이블 수직 분할(속성 분할) 중복 테이블 추가 1:M 관계 테이블 병합 테이블 수평 분할(인스턴스 분할, 파티셔닝 통계 테이블 추가 슈퍼 서브 타입 테이블 병합 이력 테이블 추가 -> 공통 속성과 개별 속성을 별도로 관리하는 설계 타입 부분 테이블 추가
컬럼 반정규화
- 중복 컬럼 추가 : 조회 감소를 위해 중복 컬럼 추가 ex) 최근 상품 가격
- 파생 컬럼 추가 : 미리 값을 계산하여 컬럼에 보관
- 이력 테이블 컬럼 추가 : 대량의 이력 데이터를 처리할 때 가능성 컬럼(최근값 여부, 시작 & 종료일 등)을 추가
관계 반정규화
- 중복 관계 추가 : 여러 경로를 거쳐 조인을 할 수 있찌만, 성능 저하를 예방하기 위해 추가적인 관계를 맺음
-> 데이터무결성은 깨뜨릴 위험성이 없음.
트랜잭션
데이터를 조작하기 위한 논리적인 작업 단위
NULL
- NULL은 존재하지 않음, 즉 값이 없음을 의미
- Not Null, PK로 정의되지 않은 데이터 유형은 Null 값 포함가능
- Null 연산 결과 -> Null
- Null 비교 결과 -> Unknown or False
- NVL/ISNULL 비교 => null 0이나 x 등으로 치환
- NVL(a,0) : a가 null이면 0을 반환
- NVL2(a,1,0) : a가 null이 아니면 1을 반환, null이면 0을 반환
- NULLIF(a,b) : a와 b가 일치하면 null을 반환, 일치하지 않으면 a를 반환
- COALESE(a,b,c,d) : NULL이 아닌 최초의 인자 값을 반환
이상
- 삽입 이상 : 데이터 삽입 시 의도했던 데이터 외에 다른 값들도 삽입됨
- 갱신 이상 : 속성 값 변경 시 일부 레코드만 변경되어 일관성이 깨짐
- 삭제 이상 : 데이터 삭제 시 의도했던 데이터 외에 다른 값들도 연쇄 삭제됨.
참고문헌
