서브쿼리
하나의 SQL문 안에 포함되어 있는 또 다른 SQL문, 알려지지 않은 기준을 이용한 검색에 사용
- 괄호를 감싸서 사용
- 단일행 또는 복수행 비교연산자와 함께 사용 가능
- ORDER BY 사용 불가
- WHERE 구에 SELECT 문을 사용하면 서브쿼리
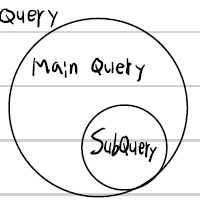
스칼라 서브쿼리 -> SELECT절
컬럼을 반환하는 서브쿼리, 주로 SELECT에서 사용 -> FROM절에는 올 수 없다.
인라인뷰(다이나믹뷰) -> FROM 절
FROM절에서 사용되는 서브쿼리 -> 메인쿼리에서 사용 가능 ORDER BY를 사용 가능
중첩서브쿼리 -> WHERE, HAVING 절
WHERE, HAVING
동작 방식
㉠. 비연관 서브쿼리 : 서브쿼리 내에 메인쿼리의 컬럼이 존재하지 않는다.
㉡. 연관 서브쿼리 : 서브쿼리 내에 메인쿼리의 컬럼이 존재
반환 데이터
㉠. 단일행 서브쿼리 : 실행결과 1건 이하
-> 단일행 비교연산자 : =, <, >, <> 등
㉡. 다중행 서브쿼리 : 실행결과 2건 이상
㉡-1 IN : 반환되는 여러 개의 행 중 하나만 참 이여도 참
-> WHERE COL1 IN('A', 'B')는 COL1 = 'A' or COL1 = 'B'를 의미
-> IN 안에 NULL이 와도 무시
-> WHERE COL1 NOT IN(a, b)은 COL1 ≠ a and COL1 ≠ b의미 그래서 NULL 포함이면 항상 거짓
㉡-2 ALL : 메인 서브 쿼리의 결과가 모두 동일하면 참
-> '<ALL:최솟값 반환','>ALL:최댓값 반환'
-> WHERE COL1 = ALL(서브쿼리)
㉡-3 ANY : 메인쿼리의 비교조건이 서브 쿼리 결과 중 하나 이상 동일하면 참
-> '<ANY:하나라도 크만 참','>ANI=Y:하나라도 작으면 참'
㉡-4 EXISTS : 서브쿼리로 어떤 데이터의 존재 여부를 확인
-> 메인/서브 쿼리의 결과가 하나라도 존재한다면 참
-> TRUE/FALSE -> WHERE EXIST(서브쿼리)
㉢. 다중 컬럼 서브쿼리 : 실행결과 컬럼 여러 개 -> SQL Server에서는 X
뷰
테이블로부터 유도된 가상의 테이블로 실제 데이터를 가지고 있지 않고 테이블을 참조해서 원하는 컬럼만 조회
장점
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용프로그램은 변경하지 않아도 된다.
- 편리성 : 복잡한 질의를 뷰로 생성하여 질의 단순하게 가능. 또한 해당 SQL 자주 사용 시 뷰를 이용하면 편히
- 보안성 : 복잡한 쿼리 구문을 뷰명으로 단축시킴으로써 가독성을 높이고 편리하게 사용
집합 연산자
조인을 사용하지 않고 연관 데이터를 조회하는 방법 중 하나로 2개 이상의 질의 결과를 하나로 만들어줌
- UNION ALL(합집합) : 중복된 행도 그대로 출력
- UNION(합집합) : 중복된 행은 한 줄로 출력
- INTERSECT(교집합) : 중복된 행은 한 줄로 출력
- MINUS/EXCEPT(차집합) : 중복된 행은 한 줄로 출력

그룹함수
특정 그룹에 대해 작업을 수행하고 결과를 반환하는 함수로 관계형
- 집계함수 : COUNT, SUM, AVG, MAX, MIN 등
- 소계(총계)합수 : ROLLUP, CUBE, GROUPING SETS 등
ROLL UP : 소계와 총계 생성, 인수의 순서가 바뀌면 다른 결과를 출력
- ROLLUP(COL1) : COL1 별 그룹핑 + 총계
- ROLLUP(COL1, COL2) :
COL1, COL2별 그룹핑
+ COL1
+ 총계
- ROLLUP((COL1, COL2), COL3) :
COL1, COL2, COL3별 그룹핑
+ COL1, COL2별 그룹핑
+ 총계
- ROLLUP(COL1, (COL2, COL3)) :
COL1, COL2, COL3별 그룹핑
+ COL1
+ 총계
- ROLLUP(COL1, COL2, COL3) :
COL1, COL2, COL3별 그룹핑
+ COL1, COL2별 그룹핑
+ COL1
+ 총계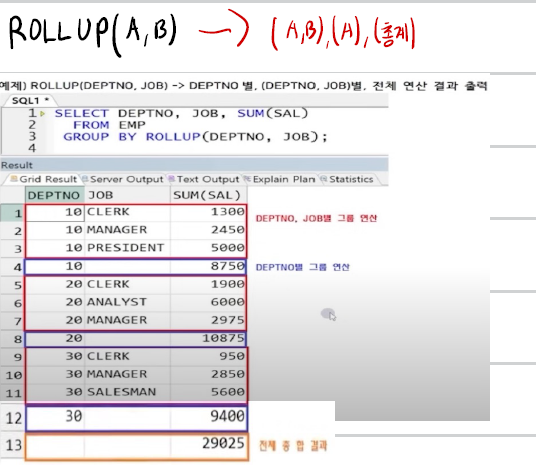
CUBE : 모든 경우의 수에 대해 소계와 총계 생성, ROLL UP에 비해 시스템에 부하 심함
- CUBE(COL1) : COL1별 그룹핑 + 총계
- CUBE(COL1, COL2) :
COL1, COL2별 그룹핑
+ COL1 + COL2
+ 총계
- CUBE((COL1, COL2), COL3) :
COL1, COL2, COL3별 그룹핑
+ COL1, COL2별 그룹핑
+ COL3
+ 총계
- CUBE(COL1, (COL2, COL3)) :
COL1, COL2, COL3별 그룹핑
+ COL1
+ COL2, COL3별 그룹핑
+ 총계
- CUBE(COL1, COL2, COL3) :
COL1, COL2, COL3별 그룹핑
+ COL1, COL2별 그룹핑 + COL1, COL3별 그룹핑 + COL2, COL3별 그룹핑
+ COL1 + COL2 + COL3
+ 총계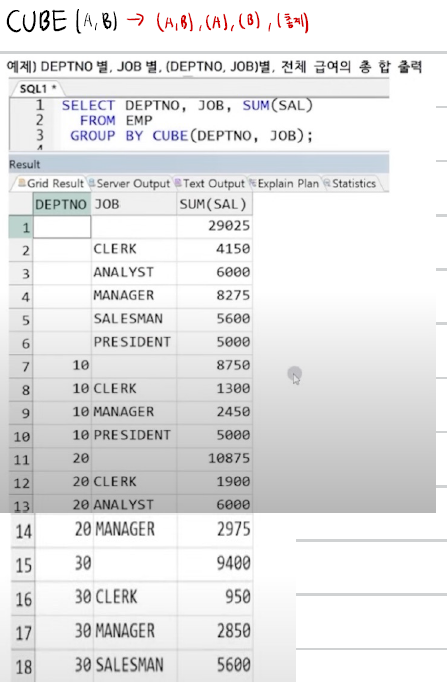
GROUPING SETS : ROLLUP, CUBE와 다르게 계층이 나타나지 않고 그룹핑된 결과값만 보여줌 -> 총계 X
- GROUPING SETS(COL1) : GROUP BY COL1과 동일
- GROUPING SETS(COL1, COL2) : COL1 + COL2
- GROUPING SETS(COL1, COL2, ()) : COL1 + COL2 + 총계
- GROUPING SETS(COL1, ROLLUP(COL2)) : COL1 + COL2 + 총계
- GROUPING SETS(COL1, COL2, COL3) : COL1 + COL2 + COL3
- GROUPING SETS(COL1, COL2, ROLLUP(COL3)) : COL1 + COL2 + COL3 + 총계
- GROUPING SETS(COL1, ROLLUP(COL2, COL3)) :
COL1
+ COL2, COL3
+ COL2
+ 총계
- GROUPING SETS(ROLLUP(COL1, COL2), COL3) :
COL1, COL2
+ COL1 + COL3
+ 총계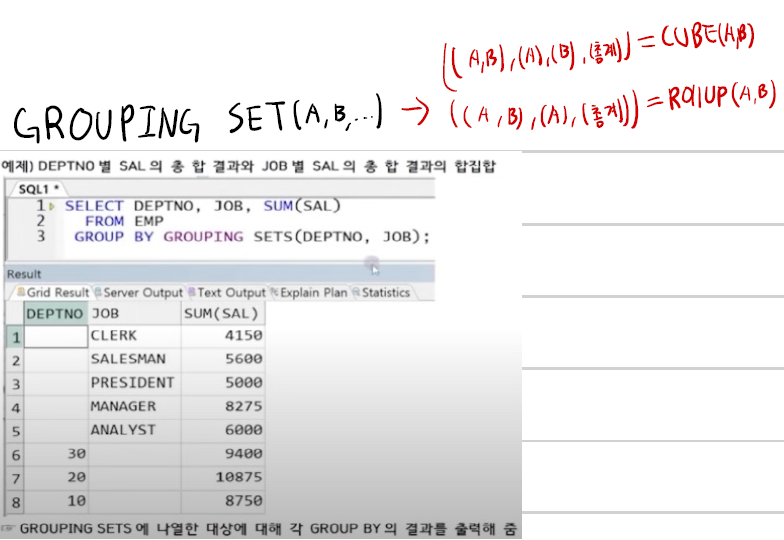
GROUPING : 집계 표시면 1, 아니면 0 -> NULL 같은 것이 1로 표시되는데 이를 다른 문자로 바꿀 때 주로 사용
- OVER, PARTITION BY는 분석함수와 함께 사용
- SELECT SUM(SAL) OVER(PARTITION BY DEPT)
윈도우 함수
OVER 구문 필수, PARTITION BY 구문 이용하여 집계의 대상이 되는 레코드 범위를 지정
순위함수
- RANK : 동일한 값에 대해서는 동일한 순위를 부여(1,2,2,4,5,5,7...)
- DENSE_RANK : 동일한 순위를 하나의 등수로 간주(1,2,2,3,4,4,5...)
- ROW_NUMBER : 그냥 처음~마지막까지 고유한 순위 부여, 중복 X
집계함수
- SUM/AVG : 파티션 별로 합계/평균을 계산
- COUNT : 파티션 별로 행 수를 계산
- MAX/MIN : 파티션 별로 최댓값/최솟값 계산
행 순서 함수
- FIRST_VALUE : 파티션별 윈도우의 처음 값
- LAST_VALUE : 파티션별 윈도우의 마지막 값
- LAG : 파티션별 윈도우에서 이전 몇번째 행의 값
- LEAD : 파티션별 윈도우에서 이후 몇번째 행의 값
비율함수
- RATIO_ID_REPORT : 파티션 내 전체 SUM에 대한 행별 컬럼 값의 백분율을 소수점까지 조회
-> 컬럼 값/ 전체 합한 값을 백분율로- PERCENT_RANK : 파티션에서 제일 먼저 나온 것은 0, 제일 늦게 나온 것은 1로 하여 값이 아닌 행의 순서 별 백분율 조회
-> (현재 행 순위 -1)/ (전체 행 순위 -1)- CUBE_DIST : 현재 행보다 작거나 같은 건수에 대한 누적 백분율로 구한다. 결과 값이 0보다 크고 1보다 작은 값을 가지는 함수
-> 그룹 1개 행 -> 1
그룹 2개 행 -> 0.5,1
그룹 3개 행 -> 0.333, 0.666, 1- NTILE : 파티션 별로 전체 건수를 인자 값으로 N등분한 결과를 조회
- CURRENT ROW : 현재 행
- UNBOUNDED PRECEDING : 첫번째 행, end point에서 사용 불가
- UNBOUNDED FOLLOWING : 마지막 행, start point에서 사용 불가
- n PRECEDING : 현재 행에서 위로 n만큼 이동
- n FOLLOWING : 현재 행에서 아래로 n만큼 이동
TOP-N 쿼리
- ROWNUM : 조회되는 행 수를 제한할 때 많이 사용(페이지 단위 출력은 인라인 뷰)
셀프조인
나 자신과의 조인
계층 쿼리
테이블에 계층 구조를 이루는 컬럼이 존재할경우 계층 쿼리를 이용해서 데이터를 출력
- LEVEL : 현재의 DEPTH를 반환. 루트 노드는 1이 된다.
- SYS_CONNECT_BY_PATH(컬럼, 구분자) : 루드 노드부터 현재노드까지의 경로를 출력해주는 함수
- START WITH : 경로가 시작되는 루드 노드를 생성해주는 절
- CONNECT BY : 루드로부터 자식노드를 생성해주는 절, 조건에 만족하는 데이터가 없을 때 노드를 생성
- PRIOR : 바로 앞에 있는 부모 노드의 값을 반환
- CONNECT_BY_ROOT 컬럼 : 루드노드의 주어진 컬럼 값을 반환
- CONNECT_BY_ISLEAF : 가장 하위 노드인 경우 1을 반환하고 그 외에는 0을 반환
